DeepAR 是 Amazon 于 2017 年提出的基于深度学习的时间序列预测方法,目前已集成到 Amazon SageMaker 和 GluonTS 中。前者是 AWS 的机器学习云平台,后者是 Amazon 开源的时序预测工具库。
排除开源工具,当我们自己根据原理手动实现DeepAR算法的时候,可以知道DeepAR有的优势是:输出概率分布,比起点预测,容错率高,在有风险,误差比较大的的领域尤其重要。
比起LSTM,DeepAR改进的地方主要是输入的协变量和输出的概率分布了,而概率分布,主要由高斯分布和负二项分布来实现。这篇文章主要是高斯分布来实现
训练模型和预测模型如下: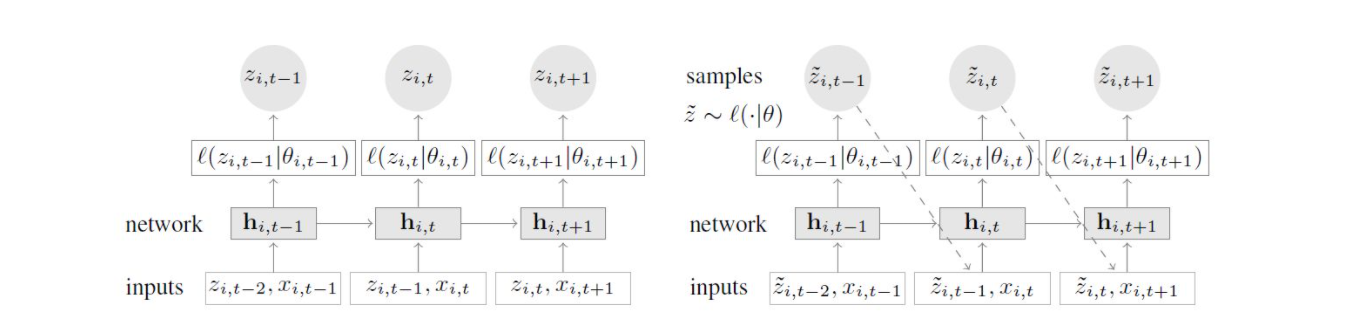
 为已有的数据,
为已有的数据,  是新传入的协变量,目的是得到
是新传入的协变量,目的是得到  ,即根据的有的数据
,即根据的有的数据  和
和  ,对未来的序列
,对未来的序列  进行概率预测,假设在这里我们使用高斯分布,我们将两个参数inputs进networks的时候,DeepAR采用的network是自回归时间序列模型LSTM,我们可以进行转换:
进行概率预测,假设在这里我们使用高斯分布,我们将两个参数inputs进networks的时候,DeepAR采用的network是自回归时间序列模型LSTM,我们可以进行转换:
**
self.input_embed = nn.Linear(1, embedding_size)self.encoder = nn.LSTM(embedding_size+input_size, hidden_size, \num_layers, bias=True, batch_first=True)if likelihood == "g":self.likelihood_layer = Gaussian(hidden_size, 1)elif likelihood == "nb":self.likelihood_layer = NegativeBinomial(hidden_size, 1)self.likelihood = likelihood


第一个等号是将联合的概率分解为自回归概率的乘积,第二个等号表明每个自然回归的概率用似然函数来表示,  代表一个RNN,我们输入上一时刻的隐层
代表一个RNN,我们输入上一时刻的隐层  和数据
和数据  、以及当前时刻的已知信息
、以及当前时刻的已知信息  ,可以得到该时刻的隐层(即输出)
,可以得到该时刻的隐层(即输出)  ,然后通过神经网络
,然后通过神经网络  将
将  转化为给定分布的参数,分布确定了之后,就可以计算出似然
转化为给定分布的参数,分布确定了之后,就可以计算出似然 ,继续假设我们是高斯分布,我们就可将这个似然函数近似于下面这个格式:
,继续假设我们是高斯分布,我们就可将这个似然函数近似于下面这个格式:
#高斯函数的损失函数,用于模型的训练,不作为构建def gaussian_likelihood_loss(z, mu, sigma):negative_likelihood = torch.log(sigma + 1) + (z - mu) ** 2 / (2 * sigma ** 2) + 6return negative_likelihood.mean()
对于这些似然函数中的参数,我们直接通过对decoder输出  做映射到,比如高斯似然函数中的
做映射到,比如高斯似然函数中的  可以写做:
可以写做:

#高斯神经网络,用于生成mu和sigmaclass Gaussian(nn.Module):def __init__(self, hidden_size, output_size):super(Gaussian, self).__init__()self.mu_layer = nn.Linear(hidden_size, output_size)self.sigma_layer = nn.Linear(hidden_size, output_size)def forward(self, h):_, hidden_size = h.size()sigma_t = torch.log(1 + torch.exp(self.sigma_layer(h))) + 1e-6sigma_t = sigma_t.squeeze(0)mu_t = self.mu_layer(h).squeeze(0)return mu_t, sigma_t
值得注意的是:prediction range的数据是未知的,因此不能像训练时那样直接给decoder输入上一时刻的真实值,只能通过抽样来得到一个估计值  ,将估计值
,将估计值  输入到下一时刻的RNN当中,这样不断迭代以得到prediction range的预测结果。估计
输入到下一时刻的RNN当中,这样不断迭代以得到prediction range的预测结果。估计 的具体步骤如下:
的具体步骤如下:
for s in range(seq_len + output_horizon): #seq_len + output_horizon是训练集和测试集的长度和if s < seq_len: #训练时不断传入真实值ynext = y[:, s].view(-1, 1)yembed = self.input_embed(ynext).view(num_ts, -1)x = X[:, s, :].view(num_ts, -1)else:yembed = self.input_embed(ynext).view(num_ts, -1) #训练时迭代上次传入的zx = Xf[:, s-seq_len, :].view(num_ts, -1)
最后,模型进行测试的时候,DeepAR 产生一个可选时间跨度的多步预测结果,单时间节点的预测为概率预测,默认输出P10,P50和P90三个值。这里的P10指的是概率分布,即10%的可能性会小于P10这个值。
#result为每次抽取ypredict的集合,采用numpy的quantile进行百分比切割p50 = np.quantile(result, 0.5, axis=1)p90 = np.quantile(result, 0.9, axis=1)p10 = np.quantile(result, 0.1, axis=1)
参考文献:
概率自回归预测—DeepAR模型浅析:https://zhuanlan.zhihu.com/p/201030350 AWS DeepAR网址:https://arxiv.org/abs/1704.04110

若有收获,就点个赞吧
0 人点赞
