这里主要介绍 Spark 集群搭建,以及各个功能组件的基本用法。
1. Spark 介绍
用于大规模数据分析的统一引擎。 Spark 分为核心 Spark Core、用SQL进行结构化数据处理的 Spark SQL、用于实时流处理 Spark Streaming、以及(暂时不考虑的)用于机器学习的MLlib、用于图处理的GraphX。官方提供了Java、Scala、Python和R的高级API。
Spark 分为核心 Spark Core、用SQL进行结构化数据处理的 Spark SQL、用于实时流处理 Spark Streaming、以及(暂时不考虑的)用于机器学习的MLlib、用于图处理的GraphX。官方提供了Java、Scala、Python和R的高级API。
Spark 能够从 HDFS、Cassandra、HBase、Hive等数百个数据源中的获取数据。能够运行在独立服务器、集群、K8S 上。
2. Spark 集群搭建
出于演示的目的,这里使用 [Standalone](https://spark.apache.org/docs/latest/spark-standalone.html) 模式。这将会使用 Spark 自带的管理工具,实现资源调度。在生产环境应该使用 Spark on yarn 模式部署。
2.1 准备服务器
首先准备三台服务器,这里是 192.168.3.43(master)、192.168.3.50(worker1)、192.168.3.51(worker2)。在三台服务器上生成 ssh 密钥对,并且把43、50、51 三台机器的公钥添加到 ~/.ssh/authorized_keys 下,注意每台机器都要添加三个公钥,保证机器之间能够相互连接。<br /> 在三台机器上都安装好 java1.8+、Python3.8+ 环境。假设每天机器的数据盘,都在 /data/ 目录下。
2.2 下载 Spark
进入 [下载](https://spark.apache.org/downloads.html) 页面,获取最新版的下载地址。以 3.2 版本为例,地址是 [https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz](https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz)。<br /> 进入 master 服务器,在/data/ 目录下,下载文件,并且解压缩。
wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgztar zxvf spark-3.2.0-bin-hadoop3.2.tgz
2.3 配置文件
进入 spark-3.2.0-bin-hadoop3.2 文件夹,编辑 config 目录下的 spark-env.sh。
cd spark-3.2.0-bin-hadoop3.2vim conf/spark-env.sh
在文件后添加命令。
export SPARK_MASTER_HOST=192.168.3.43export SPARK_MASTER_PORT=7077export PYSPARK_PYTHON=/root/.pyenv/versions/3.9.7/bin/pythonexport PYSPARK_DRIVER_PYTHON=/root/.pyenv/versions/3.9.7/bin/python
在 workers 文件中添加 worker 节点。
192.168.3.50192.168.3.51
2.4 同步文件到 worker 服务器
scp -r /data/spark-3.2.0-bin-hadoop3.2 root@192.168.3.50:/data/scp -r /data/spark-3.2.0-bin-hadoop3.2 root@192.168.3.51:/data/
2.5 启动集群
bash sbin/start-all.sh
2.6 测试集群
执行 ./bin/pyspark ,测试集群是否启动成功。<br /> pyspark 中会自动创建两个对象,sc(SparkContext) 和 spark(SparkSession )。其中sc 用来操作 rdd, spark 用来操作 dataframe 和 dataset。
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//__ / .__/\_,_/_/ /_/\_\ version 3.2.0/_/Using Python version 3.9.7 (default, Oct 26 2021 11:29:51)Spark context Web UI available at http://192.168.3.43:4040Spark context available as 'sc' (master = local[*], app id = local-1635925482175).SparkSession available as 'spark'.>>> textFile = spark.read.text("README.md")>>> textFile.count()109>>> textFile.first()Row(value='# Apache Spark')>>> textFile.filter(textFile.value.contains("Spark")).count()19
3. 数据源
Spark 支持本地文件(txt)、二进制文件、Hadoop 文件、保存的 RDD 文件(saveAsPickleFile),Sequence文件、Python 数据(list、range、dict)等。<br /> SparkContext 是 PySpark 的核心工具,一定要阅读这个类的源码,至少要了解 SparkContext 的方法,包括数据读取、操作、保存。
3.1 本地文件
本地文件需要能够被 Spark 集群的所有节点访问。假设现在使用 README.md 文件,在所有 Spark 节点上的路径都是 /data/spark-3.2.0-bin-hadoop3.2/README.md。那么就可以直接读取到。
>>> textFile = sc.textFile("/data/spark-3.2.0-bin-hadoop3.2/README.md")>>> textFile.count()
3.2 Hadoop 文件
后面的文章会介绍 Hadoop 集群的搭建,这里暂时假设已经完成了,地址是 hdfs://192.168.3.43:9000<br />�。通过下面的操作上传一个文件。
$ ./bin/hdfs dfs -ls /$ ./bin/hdfs dfs -put /data/spark-3.2.0-bin-hadoop3.2/README.md /$ ./bin/hdfs dfs -ls /Found 1 items-rw-r--r-- 3 bigdata supergroup 2214 2021-11-03 16:43 /README.md
然后,还是通过 textFile 来读取文件。
>>> hdf = sc.textFile('hdfs://192.168.3.43:9000/README.md')>>> hdf.count()109
3.3 Python 数据
直接传递 Python 数据也是可以的。
>>> sc.parallelize([0, 2, 3, 4, 6], 5).count()5>>> sc.range(5).collect()[0, 1, 2, 3, 4]>>> sc.range(1, 7, 2).collect()[1, 3, 5]>>>
3.4 PySpark 读取数据相关方法
这些都是 SparkContext 类下的方法。
| emptyRDD | 创建空的 RDD |
|---|---|
| range | 类似 Python range 的用法,创建一个包含从start 到 end 的 RDD。 |
| parallelize | 把本地 Python 序列转换为 RDD |
| pickleFile | 加载通过 “RDD.saveAsPickleFile” 保存的 RDD |
| textFile | 读取文本,可以是 本地文件、HDFS 文件、或者 HDFS 支持的文件系统 |
| wholeTextFiles | 读取文件夹,同 textFile |
| binaryFiles | 读取二进制文件夹,同 textFile |
| binaryRecords | 从二进制文件加载数据,假设每条记录都是一组数字。具有指定的数字格式(请参见ByteBuffer),并且。每条记录的字节数是恒定的。 |
| sequenceFile | 读取 sequence 文件(sequence 是 hadoop 提供的一种 key,value 形式的不可变的数据结构) |
| union | 多个数据源,取并集。 |
4. Spark RDD 弹性分布式数据集
RDD 其实就是一个分布在多个节点上的数据集合。 这个数据集的全部或部分可以缓存在内存中,并且可以在多次计算时重用。RDD 的弹性主要是指:当内存不够时,数据可以持久化到磁盘,并且RDD具有高效的容错能力。分布式数据集是指一个数据集存储在不同的节点上,每个节点存储数据集的一部分。<br /> 可以把 RDD 看作是一个数据操作的基本单位,而不必关心数据的分布式特性,Spark会自动将RDD的数据分发到集群的各个节点。Spark中对数据的操作主要是对RDD的操作(创建、转化、求值)。<br /> RDD 分布在多个节点上,每个节点上的数据称为一个分区(partition)。
4.1 单词统计程序
假设 README.md 文件中有,三行数据。
aa bbcc aadd
>>> distFile = sc.textFile('README.md')>>> counts = distFile.flatMap(lambda line: line.split(" ")) \... .map(lambda word: (word, 1)) \... .reduceByKey(lambda a, b: a + b)>>> counts.collect()
第一行,从文件中读取 README.md,并且创建一个 RDD。理论结果是 ['aa bb', 'cc aa', 'dd'].<br /> 第二行,在 RDD 的基础上调用 flatMap,把每一行的数据,按照空格分割,生成单词。理论结果是['aa', 'bb', 'cc', 'aa', 'dd']。<br /> 第三行,对每个单词,转换成 tmple,(key,vulue)。理论结果是 [('aa', 1), ('bb', 1), ('cc', 1), ('aa', 1), ('dd', 1)]。<br /> 第四行,对 tmple 集合,根据 key 做reduce 计算。理论结果是 [('aa', 2), ('bb', 1), ('cc', 1), ('dd', 1)]。<br /> 第五行,开始计算,输出结果。<br /> 注意,每一步都会创建一个新的 RDD,而且这里计算是惰性的,只有用到结果的时候,才会执行计算。
4.2 RDD 操作方法
这里的操作一定要用 pyspark 的方法,不要解析成 Python 集合,用 Python 的函数操作。
| map | 对每个元素,进行指定 funcation 的运算,并且保存结果。 >>> rdd = sc.parallelize([“b”, “a”, “c”]) >>> rdd.map(lambda x: (x, 1)).collect() [(‘b’, 1), (‘a’, 1), (‘c’, 1)] |
|---|---|
| flatMap | 和 map 类似,但是返回多个数据。 >>> rdd = sc.parallelize([“b”, “a”, “c”]) >>> rdd.flatMap(lambda s: [s, s + s]).collect() [‘b’, ‘bb’, ‘a’, ‘aa’, ‘c’, ‘cc’] |
| mapPartitions | 映射分区,对每个节点的数据进行迭代处理。 >>> rdd = sc.parallelize([1, 2, 3, 4, 5], 2) >>> def f(iterator): yield sum(iterator) >>> rdd.mapPartitions(f).collect() [3, 12] |
| filter | 对每个元素进行过滤,只有返回 true 的才保留。 >>> rdd = sc.parallelize([1, 2, 3, 4, 5]) >>> rdd.filter(lambda x: x % 2 == 0).collect() [2, 4] |
| distinct | 去重。 >>> sc.parallelize([1, 1, 2, 3]).distinct().collect() [1, 2, 3] |
| sample | 根据概率取样。第一个参数是取样之后,是否放回原来 RDD;第二个参数是取样的概率。 >>> rdd = sc.parallelize(range(100), 4) >>> rdd.sample(False, 0.1).collect() [12, 36, 48, 79, 84, 86, 89] |
| randomSplit | 按照权重随机分割成多个 RDD。 >>> rdd = sc.parallelize(range(10), 4) >>> rdd1, rdd2 = rdd.randomSplit([2, 3]) >>> rdd1.collect() [1, 3, 8, 9] >>> rdd2.collect() [0, 2, 4, 5, 6, 7] |
| takeSample | 获取固定个数的样本。 >>> rdd = sc.parallelize(range(0, 10)) >>> rdd.takeSample(False, 5) [0, 9, 1, 4, 3] >>> rdd.takeSample(False, 5) [5, 3, 9, 1, 8] |
| union | 合并RDD |
| intersection | 交集 |
| add(+) | 并集 |
| sortByKey | 根据 key 排序。 >>> rdd = sc.parallelize([(‘a’, 1), (‘b’, 2), (‘1’, 3), (‘d’, 4), (‘2’, 5)]) >>> rdd.collect() [(‘a’, 1), (‘b’, 2), (‘1’, 3), (‘d’, 4), (‘2’, 5)] >>> rdd.sortByKey().collect() [(‘1’, 3), (‘2’, 5), (‘a’, 1), (‘b’, 2), (‘d’, 4)] |
| sortBy | 根据函数返回的元素排序。 >>> rdd = sc.parallelize([(‘a’, 1), (‘b’, 2), (‘1’, 3), (‘d’, 4), (‘2’, 5)]) >>> rdd.sortBy(lambda x: x[1]).collect() [(‘a’, 1), (‘b’, 2), (‘1’, 3), (‘d’, 4), (‘2’, 5)] |
| glom | 把每个分区的数据,转化成一个列表。 >>> rdd = sc.parallelize([1, 2, 3, 4], 2) >>> rdd.glom().collect() [[1, 2], [3, 4]] |
| cartesian � |
笛卡儿积。 >>> rdd = sc.parallelize([1, 2]) >>> rdd.cartesian(rdd).collect() [(1, 1), (1, 2), (2, 1), (2, 2)] |
| groupBy | 分组,返回的是分组的 RDD。 >>> rdd = sc.range(10) >>> result = rdd.groupBy(lambda s: s % 3).collect() >>> result [(0, >>> [(x, list(y)) for x, y in result] [(0, [0, 3, 6, 9]), (1, [1, 4, 7]), (2, [2, 5, 8])] |
| pipe | 管道,对每个元素 fork 一个进程,执行命令,返回结果的 RDD。 >>> sc.parallelize([‘1’, ‘2’, ‘’, ‘3’]).pipe(‘cat’).collect() [‘1’, ‘2’, ‘’, ‘3’] |
| foreach | 遍历元素,但是不创建新的 RDD >>> def f(x): print(x) >>> sc.parallelize([1, 2, 3]).foreach(f) 1 3 2 |
| foreachPartition | 遍历分区。 |
| collect | 收集元素。返回 RDD 中包含的元素。 |
| reduce | reduce 计算。依次便利元素,同 python 中的 reduce。 >>> from operator import add >>> sc.parallelize([1, 2, 3, 4, 5]).reduce(add) 15 |
| treeReduce | 同 reduce,使用多级树操作。 |
| fold | |
| aggregate/treeAggregate | |
| countByValue | 根据 值 分组。 >>> sc.parallelize([1, 2, 1, 2, 2], 2).countByValue().items() dict_items([(1, 2), (2, 3)]) |
| take/takeOrdered | 根据规则排序,然后返回 num 个元素。 |
其他常用的方法,max、min、sum、count、mean(平均数)、variance(方差)、stdev(标准差)、top、first等,都是常用的数学操作。
4.3 checkpoint(检查点)
将经常使用的RDD快照到指定的文件系统中,在需要的时候读取出来,可以减少运算量,提高效率。不同于 cache/persist,检查点保存的数据可以恢复。<br /> 首先,在 hadoop 中创建保存点目录。
$ ./bin/hdfs dfs -mkdir /checkpoint/$ ./bin/hdfs dfs -ls /Found 1 itemsdrwxr-xr-x - bigdata supergroup 0 2021-11-04 16:18 /checkpoint
在 pyspark 中,保存检查点。
>>> sc.setCheckpointDir('hdfs://192.168.3.43:9000/checkpoint')>>> rdd = sc.range(100)>>> rdd.checkpoint()>>> rdd.count()100>>> rdd.getCheckpointFile()'hdfs://192.168.3.43:9000/checkpoint/b23e4231-6826-4185-aa83-1f15dff7e085/rdd-6'
4.4 Broadcast(广播)
将数据以广播的形式发送到各个节点,以避免每个节点都保存一份,节省内存。广播变量是只读的。
>>> b = sc.broadcast([1, 2, 3, 4, 5])>>> b.value[1, 2, 3, 4, 5]>>> rdd = sc.parallelize(range(10), 2)>>> rdd.flatMap(lambda x: b.value).collect()[1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
4.5 Accumulator(累加器)
累加器提供了将 Worker 节点的值聚合到 Driver 的功能。
>>> a = sc.accumulator(1)>>> a.value1>>> rdd = sc.parallelize([1,2,3])>>> rdd.foreach(lambda s: a.add(s))>>> a.value7
如果不使用累加器,下面的代码运算会出错。因为每个节点都会创建一个 b,而不会返回计算结果。
>>> b = 1>>> rdd = sc.parallelize([1,2,3])>>> rdd.foreach(lambda s: b + s)>>> b1
5. Spark SQL
对于结构话的数据,比如 MySQL 数据、Json 数据、HBase 数据。有 Schema 信息,知道字段是固定的,知道类型。Spark 提供了结构化查询工具。<br /> Spark SQL 提供了 DataFrame 和 DataSet,简化操作流程,并且提供了一些列的优化。在开发过程中,推荐使用 DataFrame/DataSet。DataFrame 也是分部式的数据集合,在 RDD 的基础上添加了数据描述信息(Schema,即元信息),因此看起来更像是一张数据库表。使用 DataFrame API结合SQL处理结构化数据比RDD更加容易,Spark优化器会自动对其优化,即使你写的程序或SQL不高效,也可以运行得很快。<br /> SparkSession只是在SparkContext基础上的封装,应用程序的入口仍然是SparkContext。SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序,支持从不同的数据源加载数据,并把数据转换成DataFrame,然后使用SQL语句来操作DataFrame数据。<br /> 现有文件 people.json,文件内容如下:
[{"name":"a","age":21},{"name":"b","age":22}]
使用 Spark SQL 读取数据。
>>> df = spark.read.json('hdfs://192.168.3.43:9000/people.json')>>> df.createOrReplaceTempView('people')>>> spark.sql("select * from people order by age desc").show()+---+----+|age|name|+---+----+| 22| b|| 21| a|+---+----+
5.1 数据源
Spark SQL 的 load 方法只加载 Parquet格式的文件(Parquet文件是以二进制方式存储数据的,因此不可以直接读取,文件中包括该文件的实际数据和Schema信息)。<br /> Parquet 是二进制文件,这里使用 json 文件生成一个。
>>> df = spark.read.json('hdfs://192.168.3.43:9000/people.json')>>> df.createOrReplaceTempView('people')>>> result = spark.sql("select * from people order by age desc")>>> result.write.save('hdfs://192.168.3.43:9000/result/person')>>> # 读取保存的记录>>> person = spark.read.load('hdfs://192.168.3.43:9000/result/person')>>> person.show()+---+----+|age|name|+---+----+| 22| b|| 21| a|+---+----+
也可以指定文件格式,支持 csv、json、jdbc等。
>>> spark.read.format('csv').load('hdfs://192.168.3.43:9000/person.csv')>>> spark.read.format('json').load('hdfs://192.168.3.43:9000/people.json')>>> spark.read.format('jdbc').option('url', 'jdbc://192.168.3.43:3306/database').option('driver', 'com.mysql.jdbc.Driver').option('dbtable', 'person').option('user', 'root').option('passowrd', '123456').load()
spark.read 支持的额快速加载操作。
| parquet | Parquet 文件 |
|---|---|
| text | text 文件 |
| csv | csv 文件 |
| orc | orc 文件 |
| jdbc | jdbc 文件 |
从 Python 集合创建 dataframe 。
>>> df = spark.createDataFrame([("a", 1), ("a", 1), ("b", 3), ("c", 4)], ["C1", "C2"])>>> df.show()+---+---+| C1| C2|+---+---+| a| 1|| a| 1|| b| 3|| c| 4|+---+---+
此外还支持,Hive 等数据源,由于没有搭建 Hive 环境,暂时不测试了。
5.2 操纵函数
dataframe 提供了 select、filter 等常用的函数。
>>> df.select(upper('name').alias('name')).show()+----+|name|+----+| A|| B|+----+
| select | 查询 |
|---|---|
| selectExpr | 查询表单式 >>> df.selectExpr(“age 2”, “abs(age)”).show() +————-+————+ |(age 2)|abs(age)| +————-+————+ | 42| 21| | 44| 22| +————-+————+ |
| filter | 过滤 >>> df.filter(df.age > 21).show() +—-+——+ |age|name| +—-+——+ | 22| b| +—-+——+ |
| groupBy | 分组 >>> df.groupBy().avg().show() +————+ |avg(age)| +————+ | 21.5| +————+ |
| rollup | 多位度数据汇总 >>> df.rollup(“name”, df.age).count().show() +——+——+——-+ |name| age|count| +——+——+——-+ | a| 21| 1| | b| 22| 1| | a|null| 1| | b|null| 1| |null|null| 2| +——+——+——-+ |
| cube | 多位立方 >>> df.cube(“name”, df.age).count().show() +——+——+——-+ |name| age|count| +——+——+——-+ | a| 21| 1| | b| 22| 1| | a|null| 1| | b|null| 1| |null|null| 2| |null| 21| 1| |null| 22| 1| +——+——+——-+ |
| agg | 聚合函数,支持 sum、max、min等 >>> df.agg({“age”: “max”}).show() +————+ |max(age)| +————+ | 22| +————+ |
| union/ unionAll |
连接 >>> b = df.filter(df.age > 21) >>> a.show() +—-+——+ |age|name| +—-+——+ | 22| b| | 21| a| +—-+——+ >>> b.show() +—-+——+ |age|name| +—-+——+ | 22| b| +—-+——+ >>> a.union(b) DataFrame[age: bigint, name: string] >>> a.union(b).show() +—-+——+ |age|name| +—-+——+ | 22| b| | 21| a| | 22| b| +—-+——+ |
| unionByName | 根据名称连接 >>> df1 = spark.createDataFrame([[1, 2, 3]], [“col0”, “col1”, “col2”]) >>> df2 = spark.createDataFrame([[4, 5, 6]], [“col1”, “col2”, “col3”]) >>> df1.unionByName(df2, allowMissingColumns=True).show() +——+——+——+——+ |col0|col1|col2|col3| +——+——+——+——+ | 1| 2| 3|null| |null| 4| 5| 6| +——+——+——+——+ |
| intersect/intersectAll | 交点,同 MySQL 的 INTERSECT。 >>> df1 = spark.createDataFrame([(“a”, 1), (“a”, 1), (“b”, 3), (“c”, 4)], [“C1”, “C2”]) >>> df2 = spark.createDataFrame([(“a”, 1), (“a”, 1), (“b”, 3)], [“C1”, “C2”]) >>> df1.intersect(df2).sort(“C1”, “C2”).show() +—-+—-+ | C1| C2| +—-+—-+ | a| 1| | b| 3| +—-+—-+ |
| subtract | 删除/去除 >>> df1.subtract(df2).show() +—-+—-+ | C1| C2| +—-+—-+ | c| 4| +—-+—-+ |
| dropDuplicates | 删除重复 >>> df1.dropDuplicates().show() +—-+—-+ | C1| C2| +—-+—-+ | a| 1| | b| 3| | c| 4| +—-+—-+ |
| dropna | 删除值为空的行。 |
| fillna | 把空值设置为 value。 |
| replace | 替换 |
| drop | 删除列 |
5.3 查询函数
pyspark.sql.functions 中预定义了许多函数,方便查询转换。比如 min、max、lower、sqrt、sum、avg等。
>>> from pyspark.sql.functions import lower, upper>>> df.show()+---+----+|age|name|+---+----+| 21| a|| 22| b|+---+----+>>> df.select(upper('name').alias('name')).show()+----+|name|+----+| A|| B|+----+
6. Spark Streaming
Spark Streaming接收实时输入的数据流,并将数据流以时间片(秒级)为单位拆分成批次,然后将每个批次交给Spark引擎(Spark Core)进行处理,最终生成以批次组成的结果数据流。<br /> 不过,由于在流处理上,Spark 只能提供至多一次,或者至少一次执行,不能提供确定一次执行。而且在执行效率上差距很大,所以现在主流的方案都是基于 Structured Streaming/Flink 的。
7. Structured Streaming
Structured Streaming 是一个可伸缩的、容错的流处理引擎,构建在Spark SQL引擎之上。Structured Streaming 通过使用检查点和预写日志来确保端到端的**只执行一次**(Exactly Once,指每个记录将被精确处理一次,数据不会丢失,并且不会多次处理)保证。<br /> 自Spark 2.3以来,引入了一种新的低延迟处理模式,称为连续处理,它将端到端的延迟进一步降低至1毫秒。Structured Streaming 在底层会自动实现快速、可伸缩、容错等处理。
7.1 Kafka 集群
为了方便测试,这里搭建了 kafka 集群作为中间件,如果没有kafka 环境,可以使用 navcat 代替。测试地址是 192.168.3.43:9092 。<br /> 在终端,先创建主题,然后打开一个 kafka 的生产者程序。
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.3.43:9092 --create --topic sparkstreaming --partitions 2 --replication-factor 2Created topic sparkstreaming.$ ./bin/kafka-console-producer.sh --bootstrap-server 192.168.3.43:9092 --topic sparkstreaming>hello streaming>
安装 kafka-python。<br /> 打开 pyspark,执行消费者。
>>> from kafka import KafkaProducer, KafkaConsumer>>>>>> bootstrap_servers = ['192.168.3.43:9092']>>> topicName = 'sparkstreaming'>>> consumer = KafkaConsumer(bootstrap_servers=bootstrap_servers)>>> consumer.subscribe(topics=[topicName])>>> while 1:... records = consumer.poll()... for topic, rec in records.items():... print(rec)...[ConsumerRecord(topic='sparkstreaming', partition=1, offset=2, timestamp=1636104123717, timestamp_type=0, key=None, value=b'abcd', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=4, serialized_header_size=-1)][ConsumerRecord(topic='sparkstreaming', partition=0, offset=2, timestamp=1636104135526, timestamp_type=0, key=None, value=b'hello spark', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=11, serialized_header_size=-1)]
7.2 单词统计
Structured Streaming 集成 kafka 需要组件 spark-sql-kafka。在运行时会自动下载相关 jar 包。启动 PySpark 时,添加参数 ./bin/pyspark --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0。或者在运行时设置环境 PYSPARK_SUBMIT_ARGS 者为 --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0 pyspark-shell。参考:[kafka integration with Pyspark structured streaming (Windows)](https://stackoverflow.com/questions/68105480/kafka-integration-with-pyspark-structured-streaming-windows)
>>> spark_host = 'spark://192.168.3.43:7077'>>> kafka_servers = '192.168.3.43:9092'>>> lines = spark.readStream.format('kafka') \... .option('kafka.bootstrap.servers', kafka_servers) \... .option('subscribe', 'sparkstreaming') \... .load()>>> from pyspark.sql.functions import explode, split>>> words = lines.select(... explode(... split(lines.value, " ")... ).alias("word")... )>>> wordCounts = words.groupBy("word").count()>>>>>> query = wordCounts \... .writeStream \... .outputMode("complete") \... .format("console") \... .start()
现在向kafka 中写入数据。
# ./bin/kafka-console-producer.sh --bootstrap-server 192.168.3.43:9092 --topic sparkstreaming>abcd 1234>hello world
此时,PySpark 中不断的执行计算,并且输入计算结果。
-------------------------------------------Batch: 0-------------------------------------------+----+-----+|word|count|+----+-----++----+-----+-------------------------------------------Batch: 1-------------------------------------------+----+-----+|word|count|+----+-----+| | 1|+----+-----+-------------------------------------------Batch: 2-------------------------------------------+-----+-----+| word|count|+-----+-----+|hello| 1|| abcd| 1||world| 1|| | 3|+-----+-----+
7.3 执行模型
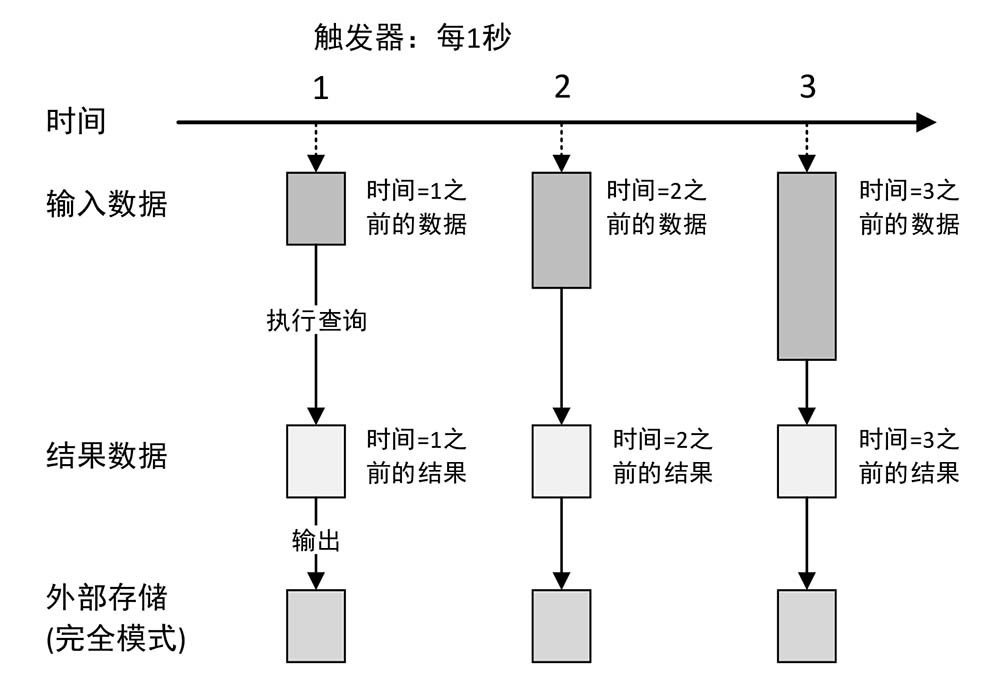
默认条件下,触发器每一秒钟执行一次,对当前时间点之前的数据进行处理。
7.4 处理函数
这里操作的对象是 Dataframe,操作起来和 Spark SQL 是相同的。实际上 Structured Streaming 就是在 Spark SQL 上执行的。
7.5 窗口操作
每条数据都有两个时间,一个是发生时间,也叫事件时间,是指数据生成的时间。另一个是处理时间,是指 Spark 接收到数据的时间。这里相差一个传输时间。一般使用事件事件,但是考虑到数据的延迟,这样数据会不准确。<br /> 操作窗口,是指用来计算数据的开始开始时间到结束时间的时间段。假设统计最近十分钟的单词数,没分钟执行一次,那么时间窗口就是,10:35 ~ 10:45、10:36 ~ 10:46。
def window(timeColumn, windowDuration, slideDuration=None, startTime=None)
窗口函数定义了四个参数:
- timeColumn,时间字段;
- windowDuration,窗口时间,计算时间窗口的持续时间;
- slideDuration,滑动时间,计算的时间间隔,每隔多少时间执行一次;
- startTime,开始时间;
注意这里 words 添加了时间戳字段;在 groupBy 时,先根据时间戳字段创建窗口函数,分组然后在根据单词分组;输出模式是 complete。 ```bash>>> from pyspark.sql.functions import explode, split, window, to_timestamp>>> spark_host = 'spark://192.168.3.43:7077'>>> kafka_servers = '192.168.3.43:9092'>>> lines = spark.readStream.format('kafka') \... .option('kafka.bootstrap.servers', kafka_servers) \... .option('subscribe', 'sparkstreaming') \... .option('includeTimestamp', True) \... .load()>>> words = lines.select(... explode(... split(lines.value, " ")... ).alias("word"),... to_timestamp(lines.timestamp).alias('timestamp')... )>>> wordCounts = words.groupBy(window('timestamp', '5 seconds', '5 seconds'), "word").count()>>>>>> query = wordCounts \... .writeStream \... .outputMode("complete") \... .format("console") \... .option('truncate', 'false') \... .start()
Batch: 0
+———+——+——-+ |window|word|count| +———+——+——-+ +———+——+——-+
Batch: 1
+—————————————————————+——+——-+ |window |word|count| +—————————————————————+——+——-+ |{2021-11-05 14:04:40, 2021-11-05 14:04:45}|abcd|1 | |{2021-11-05 14:04:40, 2021-11-05 14:04:45}|1234|1 | +—————————————————————+——+——-+
Batch: 2
+—————————————————————+——-+——-+ |window |word |count| +—————————————————————+——-+——-+ |{2021-11-05 14:04:40, 2021-11-05 14:04:45}|abcd |1 | |{2021-11-05 14:04:45, 2021-11-05 14:04:50}|hello|1 | |{2021-11-05 14:04:40, 2021-11-05 14:04:45}|1234 |1 | |{2021-11-05 14:04:45, 2021-11-05 14:04:50}|spark|1 | +—————————————————————+——-+——-+
<a name="ALNJa"></a>## 7.6 保存结果Spark 支持三种输出模式。1. complete:每次都输出完整结果。1. update:指数出有变更的数据。1. append:已有的行,不会被改变,只添加新的数据。Spark 支出存储到多种位置。1. 文件:```pythonwriteStream \.outputMode("complete") \.format("parquet") \.option('path', 'pathname')
kafka(常用)
writeStream \.outputMode("complete") \.format('kafka') \.option('kafka.bootstrap.servers', kafka_servers) \.option('topic', 'sparkstreaming')
控制台等。

若有收获,就点个赞吧
0 人点赞
