- 1. 集群安装
- 2. 示例
- 1. 获取执行环境
- 2. 定义数据源
- 3. 设置数据处理
- 4. 定义数据保存
- 5. 开始执行
- 3. 连接器
- 4. 数据转换(Transformation)
- 5. 时间和窗口
- 6. 状态和检查点
- 每 1000ms 开始一次 checkpoint
- 高级选项:
- 设置模式为精确一次 (这是默认值)
- 确认 checkpoints 之间的时间会进行 500 ms
- Checkpoint 必须在一分钟内完成,否则就会被抛弃
- 允许两个连续的 checkpoint 错误
- 同一时间只允许一个 checkpoint 进行
- 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
- 开启实验性的 unaligned checkpoints
- 使用流模式 TableEnvironment
 0. 概述
0. 概述
Flink(https://flink.apache.org/zh/) 是主流的流批一体处理框架,高吞吐、低延迟、高性能以及支持exactly-once语义。相比于 Spark 更强调流处理,速度更快,操作更简单。
Flink中提供了3个组件,包括 DataSource(获取数据)、Transformation(数据处理)和 DataSink(保存数据)。获取数据,支持文本、Socket 数据流、Kafka、数据库、以及一些自定义的数据源等。对于数据库(MySQL、PostgreSQL、MongoDB、Oracle),支持通过 CDC(change data capture,https://github.com/ververica/flink-cdc-connectors)来获取数据变更。数据处理,表示算子,主要用来对数据进行处理,比如Map、FlatMap、Filter、Reduce、Aggregation等。保存数据,把计算的结果输出到其他存储介质中,比如 writeAsText 以及 Kafka、Redis、Elasticsearch 等第三方Sink组件。
对于 Python 环境,推荐使用 pip 安装 numpy 等依赖,否则会导致以来冲突的问题。另外由于 python 支持库 apache-flink 从 1.9 版本(2020/02)才开始,而且 1.12 版本有较大的变更。导致现在 Java 依赖以及相关文档不是很好,以及部分 API 不支持(比如文档中经常能看到 “This feature is not yet supported in Python”https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/overview/#interval-join)。不过现在可用性已经比较高了,API 和 java/scala 版本比较一致。已经有一些互联网公司开始使用 Python 编写 Flink 相关项目(比如聚美优品)。推荐阅读(https://www.infoq.cn/article/ybP6zTBbyXuV3NOvtZyX)。
也许是由于阿里巴巴收购了 flink 背后的公司 Data Artisans,Flink 有中文官方文档。阅读起来比较方便。但是,这里有一个天坑,中文版往往会简略翻译内容,导致难以理解。如果阅读英文文档有压力,可以对照中文版阅读。
1. 集群安装
1.1 Flink 安装(Standalone)
Flink 支持多种部署方式。这里为了方便使用,使用 standalone 的方式部署,在生产环节推荐使用 Flink on yarn,或者购买云计算平台提供的服务([https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/overview/#vendor-solutions](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/overview/#vendor-solutions))。<br /> 假设现在有三台服务器,192.168.3.43、192.168.3.50、192.168.3.51。而且这几台机器上都安装了 Java11,Python3.8,并且相互之间可以相互访问(配置好 ssh key)。这里 3.34 作为主服务器,3.50、3.51 作为从服务器。
准备文件
在 3.43 服务器上,下载官网最新的文件(https://flink.apache.org/downloads.html),并且解压缩。
$ wget https://www.apache.org/dyn/closer.lua/flink/flink-1.14.0/flink-1.14.0-bin-scala_2.12.tgz$ tar zxvf flink-1.14.0-bin-scala_2.12.tgz$ cd flink-1.14.0
配置服务器
打开 conf/flink-conf.yaml,设置 jobmanager.rpc.address 为 192.168.3.43。打开 conf/masters,内容设置为 192.168.3.43。打开 conf/workers,内容这是为 192.168.3.43、192.168.3.50、192.168.3.50(分三行,每行一个 IP)。
启动集群
$ ./bin/start-cluster.sh
1.2 Kafka 安装
Flink 支持多种数据源,这里使用 Kafka。官网(http://kafka.apache.org/)下载 文件,解压缩,启动,配置 topic。Kakfa 依赖 zookeeper,需要先启动 zookeeper。
$ wget https://www.apache.org/dyn/closer.cgi?path=/kafka/3.0.0/kafka_2.13-3.0.0.tgz$ tar -xzf kafka_2.13-3.0.0.tgz$ cd kafka_2.13-3.0.0$ bin/zookeeper-server-start.sh config/zookeeper.properties$ bin/kafka-server-start.sh config/server.properties
配置 Topic。
$ ./bin/kafka-topics.sh --bootstrap-server 192.168.3.43:9092 --create --topic flinkstreaming --partitions 2 --replication-factor 1$ ./bin/kafka-topics.sh --bootstrap-server 192.168.3.43:9092 --listflinkstreaming
打开消费者终端。
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.3.43:9092 --topic flinkstreaming
在另一个终端页面,打开生产者,并输入 “hello kafka”。
$ ./bin/kafka-console-producer.sh --bootstrap-server 192.168.3.43:9092 --topic flinkstreaming> hello kafka
在消费者终端会实时显示出生产者端接收到的消息。
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.3.43:9092 --topic flinkstreaminghello kafka
zookeeper 地址:192.168.3.43:2181
kafka 地址:192.168.3.43:90922. 示例
一个基础的 Flink 程序包括五个步骤:获取环境、获取数据、操作数据、设置输出、开始执行。
2.1 程序
下面创建文件 flink_kafka_example.py。注意修改 kafka 的地址和 Python 执行文件的地址。 ```python from pyflink.common import SimpleStringSchema, Row, Types from pyflink.datastream import StreamExecutionEnvironment from pyflink.datastream.connectors import FlinkKafkaConsumer, FlinkKafkaProducer from pyflink.common.serialization import JsonRowSerializationSchema
kafka_topic_source = ‘flinkstreaming’ kafka_topic_fink = ‘flinkstreamingresult’ kafka_server = ‘192.168.3.43:9092’ client_python_path = ‘/root/.pyenv/versions/3.8.12/bin/python’
1. 获取执行环境
s_env = StreamExecutionEnvironment.get_execution_environment() s_env.set_python_executable(client_python_path)
2. 定义数据源
kafka_source = FlinkKafkaConsumer( topics=kafka_topic_source, deserialization_schema=SimpleStringSchema(), properties={‘bootstrap.servers’: kafka_server, ‘group.id’: ‘test_group’} ) kafka_source.set_start_from_latest() ds = s_env.add_source(kafka_source, source_name=’kafka’)
3. 设置数据处理
ds = ds.flat_map(lambda s: s.split(‘ ‘)) \ .map(lambda i: Row(i, 1), output_type=Types.ROW([Types.STRING(), Types.INT()])) \ .key_by(lambda i: i[0]) \ .reduce(lambda i, j: Row(i[0], i[1] + j[1]))
4. 定义数据保存
serialization_schema = JsonRowSerializationSchema.builder().with_type_info( type_info=Types.ROW([Types.STRING(), Types.INT()])).build() kafka_sink = FlinkKafkaProducer( topic=kafka_topic_fink, serialization_schema=serialization_schema, producer_config={‘bootstrap.servers’: kafka_server, ‘group.id’: ‘test_group’} ) ds.add_sink(kafka_sink,)
5. 开始执行
s_env.execute(‘flink kafka’)
<a name="M6mo3"></a>## 2.2 提交任务有两种方式提交任务。1. 执行运行程序。这种方式需要本地安装 Java 环境,并且配置相关 jar 包。适合开始时使用。```bash$ python flink_kafka_example.py
通过 flink 提交程序。
这种方式只需要把依赖的 jar 包下载到 lib 目录下即可,运行环境明确。
$ ./bin/flink run --python examples/flink_kafka_example.pyJob has been submitted with JobID 8974aaeabf35b256e7eef617a2de2ec5
网页打开 “http://192.168.3.43:8081/#/job/8974aaeabf35b256e7eef617a2de2ec5/overview”,可以查看任务执行情况。
 3. 通过网页提交 jar 包
3. 通过网页提交 jar 包
这种方式不支持 Python。2.3 提交数据
打开一个终端,向 kafka 的主题 flinkstreaming 提交数据。
$ ./bin/kafka-console-producer.sh --bootstrap-server 192.168.3.43:9092 --topic flinkstreaming>hello python>hello flink
2.4 获取结果
另外在打开一个终端,监听 kafka 的主题 flinkstreamingresult。
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.3.43:9092 --topic flinkstreamingresult{"f0":"hello","f1":1}{"f0":"python","f1":1}{"f0":"hello","f1":2}{"f0":"flink","f1":1}
3. 连接器
Flink 提供了多种连接方式,用来获取数据(DataSource)和保存数据(DataSink)。
3.1 内置的连接器
详细连接内容,请查看 https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/overview/。
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- FileSystem (Hadoop included) - Streaming and Batch (sink)
- RabbitMQ (source/sink)
- Google PubSub (source/sink)
- Hybrid Source (source)
- Apache NiFi (source/sink)
- Apache Pulsar (source)
- Twitter Streaming API (source)
- JDBC (sink)
以 Kafka 为例:
首选手动下载相关 jar 包,放在 Flink 的 lib 目录下,或者在代码中指定 jar 包的位置。根据下面的 pom.xml 内容,从 https://developer.aliyun.com/mvn/guide 下载。注意:当前版本(1.14.0),kafka 的客户端不支持 3.0 版本,请使用 2.8.1 版本(因为这个问题,莫名的花费了大半天时间)。
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.8.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.14.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_2.12</artifactId><version>1.14.0</version></dependency>
3.2 基于 Apache Bahir 的 连接器
Apache Bahir提供了对多个分布式分析平台的扩展,通过各种流连接器和SQL数据源扩展了它们的覆盖范围。目前,Bahir为Apache Spark和Apache Flink提供了扩展。详细使用方法请参照 [https://bahir.apache.org/docs/flink/current/documentation/](https://bahir.apache.org/docs/flink/current/documentation/)。
- Flink streaming connector for ActiveMQ
- Flink streaming connector for Akka
- Flink streaming connector for Flume
- Flink streaming connector for InfluxDB
- Flink streaming connector for Kudu
- Flink streaming connector for Redis
- Flink streaming connector for Netty
4. 数据转换(Transformation)
Flink的Transformation主要包括4种:单数据流基本转换、基于Key的分组转换、多数据流转换和数据重分布转换。4.1 单数据流基本转换
| map | 把输入数据,根据转换函数,处理成新的数据 | .map(lambda i: Row(i, 1), output_type=Types.ROW([Types.STRING(), Types.INT()])) | | —- | —- | —- | | flat_map | 把输入数据,根据转换函数,处理成新的零个或者多个数据 | flat_map(lambda s: s.split(‘ ‘))
� | | reduce | 把分组的数据,依次处理,获取新的数据 | reduce(lambda i, j: Row(i[0], i[1] + j[1]))
� | | filter | 元素过滤 | .filter(lambda s: len(s) > 5) |
4.2 基于Key的分组转换
| key_by | 根据某个元素分组 | .key_by(lambda i: i[0])� |
|---|---|---|
| sum/min/max等 | 常见的数据聚合处理 |
4.3 多数据流转换
对多个数据流进行转换操作。
| union | 合并多个同类型的数据流 | ds.union() |
|---|---|---|
| connect | 连接两个数据流 | ds.connect() |
注意:
- connect()只能连接两个数据流,union()可以连接多个数据流。
- connect()所连接的两个数据流的数据类型可以不一致,union()所连接的两个或多个数据流的数据类型必须一致。
- 两个DataStream经过connect()之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且两个流之间可以共享状态。
4.4 并行度与数据重分布
4.4.1 并行度
Flink使用并行度来定义某个算子被切分为多少个算子子任务。大部分 Transformation 操作能够形成一个逻辑视图,当实际执行时,逻辑视图中的算子会被并行切分为一到多个算子子任务,每个算子子任务处理一部分数据,各个算子并行地在多个子任务上执行。假如算子的并行度为2,那么它有两个子任务。s_env.get_parallelism()s_env.set_parallelism(10)
4.4.2 数据重分布
在分布式的执行任务时,每台机器上的数据数量时难以确定的。为了保证每台机器的运算量平衡,需要对数据进行重新分配。
| shuffle | 随机分配 | |
|---|---|---|
| rebalance | 数据会轮询式地均匀分布到下游的所有的子任务上 | |
| rescale | 近发送给下游子任务,数据传输更小 | |
| broadcast | broadcast 数据,数据可被复制并广播发送给下游的所有子任务上。 | ds.broadcast() |
| global | 所有数据发送给下游算子的第一个子任务上,使用global()时要小心,以免造成严重的性能问题。 | |
| partitionCustom | 分区自定义 |
4.5 数据类型和序列化
几乎所有的大数据框架都要面临分布式计算、数据传输和持久化问题。所以快速的序列号和反序列号是十分必要的。Flink选择开发了自己的序列化框架,因为序列化和反序列化关乎整个流处理框架各方面的性能,对数据类型了解越多,可以更早地完成数据类型检查,节省数据存储空间。<br /> Flink支持基础类型、数组、复合类型、辅助类型、泛型和其他类型。<br />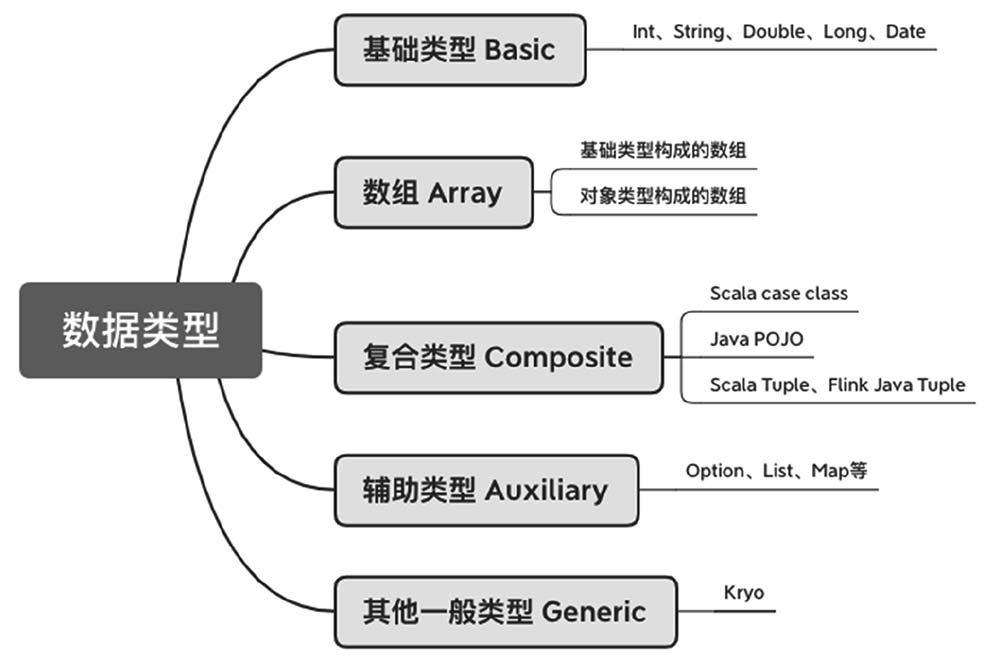<br /> Python 类型和 Java 类型相似,具体内容请参考 [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/python/datastream/data_types/](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/python/datastream/data_types/) 和 [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/python/table/python_types/](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/python/table/python_types/)。以 DataStream API 支持的类型为例(Table API 内容后面会独立说明)。支持的数据类型在 pyflink.common.typeinfo.Types 文件中。
| PyFlink Type | Python Type | Java Type |
|---|---|---|
| Types.BOOLEAN() | bool | java.lang.Boolean |
| Types.BYTE() | int | java.lang.Byte |
| Types.SHORT() | int | java.lang.Short |
| Types.INT() | int | java.lang.Integer |
| Types.LONG() | int | java.lang.Long |
| Types.FLOAT() | float | java.lang.Float |
| Types.DOUBLE() | float | java.lang.Double |
| Types.CHAR() | str | java.lang.Character |
| Types.STRING() | str | java.lang.String |
| Types.BIG_INT() | int | java.math.BigInteger |
| Types.BIG_DEC() | decimal.Decimal | java.math.BigDecimal |
| Types.INSTANT() | pyflink.common.time.Instant | java.time.Instant |
| Types.TUPLE() | tuple | org.apache.flink.api.java.tuple.Tuple0 ~ org.apache.flink.api.java.tuple.Tuple25 |
| Types.ROW() | pyflink.common.Row | org.apache.flink.types.Row |
| Types.ROW_NAMED() | pyflink.common.Row | org.apache.flink.types.Row |
| Types.MAP() | dict | java.util.Map |
| Types.PICKLED_BYTE_ARRAY() | The actual unpickled Python object | byte[] |
| Types.SQL_DATE() | datetime.date | java.sql.Date |
| Types.SQL_TIME() | datetime.time | java.sql.Time |
| Types.SQL_TIMESTAMP() | datetime.datetime | java.sql.Timestamp |
| Types.LIST() | list of Python object | java.util.List |
数组类型。注意:实际执行的代码是 Java/Scala 编写的,所以这里不能把数据直接理解为 list 或者 collection 模块。
| PyFlink Array Type | Python Type | Java Type |
|---|---|---|
| Types.PRIMITIVE_ARRAY(Types.BYTE()) | bytes | byte[] |
| Types.PRIMITIVE_ARRAY(Types.BOOLEAN()) | list of bool | boolean[] |
| Types.PRIMITIVE_ARRAY(Types.SHORT()) | list of int | short[] |
| Types.PRIMITIVE_ARRAY(Types.INT()) | list of int | int[] |
| Types.PRIMITIVE_ARRAY(Types.LONG()) | list of int | long[] |
| Types.PRIMITIVE_ARRAY(Types.FLOAT()) | list of float | float[] |
| Types.PRIMITIVE_ARRAY(Types.DOUBLE()) | list of float | double[] |
| Types.PRIMITIVE_ARRAY(Types.CHAR()) | list of str | char[] |
| Types.BASIC_ARRAY(Types.BYTE()) | list of int | java.lang.Byte[] |
| Types.BASIC_ARRAY(Types.BOOLEAN()) | list of bool | java.lang.Boolean[] |
| Types.BASIC_ARRAY(Types.SHORT()) | list of int | java.lang.Short[] |
| Types.BASIC_ARRAY(Types.INT()) | list of int | java.lang.Integer[] |
| Types.BASIC_ARRAY(Types.LONG()) | list of int | java.lang.Long[] |
| Types.BASIC_ARRAY(Types.FLOAT()) | list of float | java.lang.Float[] |
| Types.BASIC_ARRAY(Types.DOUBLE()) | list of float | java.lang.Double[] |
| Types.BASIC_ARRAY(Types.CHAR()) | list of str | java.lang.Character[] |
| Types.BASIC_ARRAY(Types.STRING()) | list of str | java.lang.String[] |
| Types.OBJECT_ARRAY() | list of Python object | Array |
5. 时间和窗口
对于数据库的处理,没有结束时间,需要给定一个时间窗口,比如一个小时,统计时间窗口内的数据指标。
5.1 时间
Flink 将时间 分为 Event Time(事件发生时间)、Processing Time(开始处理事件)和 IngestionTime(系统接收数据事件) 3种时间语义。<br />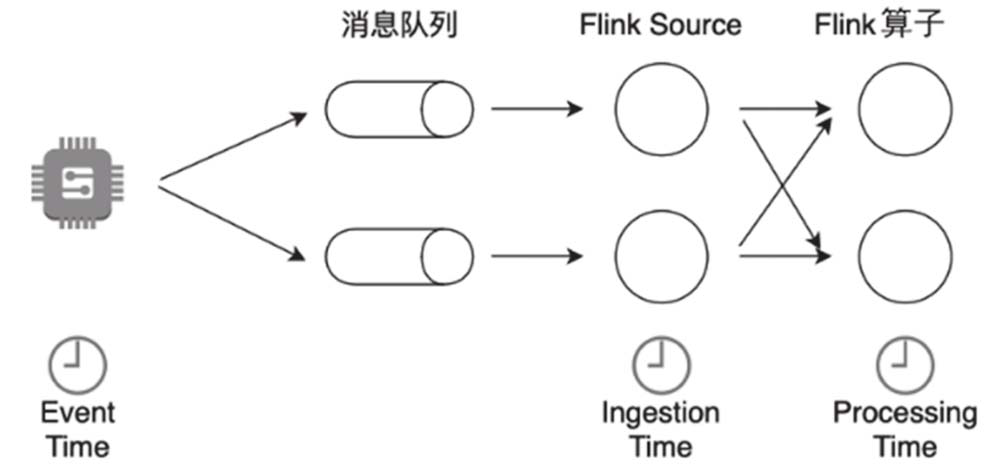<br /> Event Time 是最准确的时间,但是由于实际环境中不可能达到要求,Flink会将窗口内的事件缓存下来,直到接收到一个Watermark,Watermark假设不会有更晚到达的事件。
from pyflink.datastream.time_characteristic import TimeCharacteristics_env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
5.2 水印(watermark)
EventTime 是事件的元数据,如果不设置 Flink 就不能获取到,所以来自 Kafka 等数据源的数据需要添加时间戳。但是由于网络传输等因素,数据可能不会立即到达系统,即会存在一定的延迟,这是就需要系统等待数据到达。通过设置 水印 来表示,当时时间窗口不会有更晚的数据到达了。<br /> 用法请参考 [https://github.com/apache/flink/blob/master/flink-end-to-end-tests/flink-python-test/python/datastream/data_stream_job.py](https://github.com/apache/flink/blob/master/flink-end-to-end-tests/flink-python-test/python/datastream/data_stream_job.py)。
5.3 ProcessFunction 系列函数
ProcessFunction 系列函数提供了对数据流进行更细粒度操作的权限。能够获取数据流中 Watermark 的时间戳,或者使用定时器。这个系列函数主要包括 pyflink.datastream.functions 文件下的 KeyedProcessFunction、ProcessFunction、CoProcessFunction、KeyedCoProcessFunction、ProcessJoinFunction和ProcessWindowFunction等多种函数,这些函数各有侧重,但核心功能比较相似,主要包括如下两点。
- 状态:我们可以在这些函数中访问和更新Keyed State。
定时器:像定闹钟一样设置定时器,我们可以在时间维度上设计更复杂的业务逻辑。
5.3.1 Timer
Timer 定时器是一个设置未来时间的工具,当设置的时间到了的时候,程序会执行一个回调函数。使用Timer的方法主要逻辑如下。
在processElement()方法中通过Context注册一个未来的时间戳t。这个时间戳的语义可以是Processing Time,也可以是Event Time,根据业务需求来选择。
在onTimer()方法中实现一些逻辑,到达t时刻,onTimer()方法被自动调用。
class MyProcessFunction(KeyedProcessFunction):def process_element(self, value, ctx: 'KeyedProcessFunction.Context'):result = "Current key: {}, orderId: {}, payAmount: {}, timestamp: {}".format(str(ctx.get_current_key()), str(value[1]), str(value[2]), str(ctx.timestamp()))yield resultcurrent_watermark = ctx.timer_service().current_watermark()ctx.timer_service().register_event_time_timer(current_watermark + 1500)def on_timer(self, timestamp, ctx: 'KeyedProcessFunction.OnTimerContext'):yield "On timer timestamp: " + str(timestamp)
5.3.2 在两个数据流上使用 ProcessFunction
CoProcessFunction、KeyedCoProcessFunction 等类支持定义 process_element1 和 process_element2,分别处理两个流获取到的数据。
5.4 窗口
在流处理场景下,数据以源源不断的流的形式存在,数据一直在产生,没有始末。我们要对数据进行处理时,往往需要明确一个时间窗口,比如数据在“每秒”“每小时”“每天”的维度下的一些特性。在一个时间窗口维度上对数据进行聚合,划分窗口是流处理需要解决的问题。
通常会对数据组分组,之后下游算子的多个子任务可以并行计算。然后使用窗口函数。使用窗口分配器(WindowAssigner)将数据流中的元素分配到对应的窗口。当满足窗口触发条件后,对窗口内的数据使用窗口处理函数进行处理,常用的窗口处理函数有reduce()、aggregate()、process()。其他的Trigger、Evictor则是窗口的触发和销毁过程中的附加选项,主要面向需要更多自定义内容的编程者,如果不设置则会使用默认的配置。
Flink 支持根据时间的 TimeWindow,以及根据数量的CountWindow,这里主要使用 TimeWindow。 Flink为我们提供了一些内置的WindowAssigner,即滚动窗口、滑动窗口和会话窗口。

5.4.1 滚动窗口
滚动窗口模式下,窗口之间不重叠,且窗口长度(Window Size)是固定的。我们可以用TumblingEventTimeWindows 和 TumblingProcessingTimeWindows创建一个基于 Event Time 或Processing Time的滚动窗口。窗口的长度可以用org.apache.flink.streaming.api.windowing.time.Time中的seconds、minutes、hours和days来设置。

5.4.2 滑动窗口
滑动窗口以一个步长(Slide)不断向前滑动,窗口的Size固定。使用时,我们要设置Slide和Size。Slide的大小决定了Flink以多快的速度来创建新的窗口。

5.4.3 会话窗口
会话窗口模式下,两个窗口之间有一个间隙,称为Session Gap。当一个窗口在大于Session Gap的时间内没有接收到新数据时,窗口将关闭。在这种模式下,窗口的Size是可变的,每个窗口的开始和结束时间并不是确定的。

6. 状态和检查点
作为一个计算框架,Flink提供了有状态的计算,封装了一些底层的实现,比如状态的高效存储、Checkpoint 和 Savepoint 持久化备份机制、计算资源扩/缩容算法等。因为Flink接管了这些实现,开发者只需调用Flink API,可以更加专注于业务逻辑。
6.1 状态
Flink有两种基本类型的状态:
托管状态(Managed State),由Flink管理的,Flink负责存储、恢复和优化。它又有两种类型的状态。
- KeyedState,KeyedStream上的状态,
- Operator State,可以用在所有算子上,每个算子子任务共享一个状态,流入这个算子子任务的所有数据都可以访问和更新这个状态。
- 原生状态(Raw State),开发者管理的,需要自己进行序列化。
6.1.1 KeyedState 使用方法
State主要有3种实现,分别为ValueState、MapState和AppendingState,AppendingState又可以细分为ListState、ReducingState和AggregatingState。
- ValueState
: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过 update(T) 进行更新,通过 T value() 进行检索。 - MapState
) 添加映射。 使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。你还可以通过 isEmpty() 来判断是否包含任何键值对。 - ListState
: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List ) 进行添加元素,通过 Iterable get() 获得整个列表。还可以通过 update(List ) 覆盖当前的列表。 - ReducingState
: 保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。 AggregatingState
以 ValueState 为例。先设置 ValueStateDescriptor,然后 update 或者 clear 数据。 ```python from pyflink.common.typeinfo import Types from pyflink.datastream import StreamExecutionEnvironment, FlatMapFunction, RuntimeContext from pyflink.datastream.state import ValueStateDescriptor
class CountWindowAverage(FlatMapFunction):
def __init__(self):self.sum = Nonedef open(self, runtime_context: RuntimeContext):descriptor = ValueStateDescriptor("average", # the state nameTypes.PICKLED_BYTE_ARRAY() # type information)self.sum = runtime_context.get_state(descriptor)def flat_map(self, value):# access the state valuecurrent_sum = self.sum.value()if current_sum is None:current_sum = (0, 0)# update the countcurrent_sum = (current_sum[0] + 1, current_sum[1] + value[1])# update the stateself.sum.update(current_sum)# if the count reaches 2, emit the average and clear the stateif current_sum[0] >= 2:self.sum.clear()yield value[0], int(current_sum[1] / current_sum[0])
env = StreamExecutionEnvironment.get_execution_environment() env.from_collection([(1, 3), (1, 5), (1, 7), (1, 4), (1, 2)]) \ .key_by(lambda row: row[0]) \ .flat_map(CountWindowAverage()) \ .print()
env.execute()
<a name="FwDNJ"></a>### 6.1.2 状态有效期 (TTL)任何类型的 keyed state 都可以有 _有效期_ (TTL)。如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值,这会在后面详述。所有状态类型都支持单元素的 TTL。 这意味着列表元素和映射元素将独立到期。在使用状态 TTL 前,需要先构建一个StateTtlConfig 配置对象。 然后把配置传递到 state descriptor 中启用 TTL 功能。```pythonfrom pyflink.common.time import Timefrom pyflink.common.typeinfo import Typesfrom pyflink.datastream.state import ValueStateDescriptor, StateTtlConfigttl_config = StateTtlConfig \.new_builder(Time.seconds(1)) \.set_update_type(StateTtlConfig.UpdateType.OnCreateAndWrite) \.set_state_visibility(StateTtlConfig.StateVisibility.NeverReturnExpired) \.build()state_descriptor = ValueStateDescriptor("text state", Types.STRING())state_descriptor.enable_time_to_live(ttl_config)
6.1.3 BroadcastState
BroadcastState 将部分数据同步到所有子任务上。<br />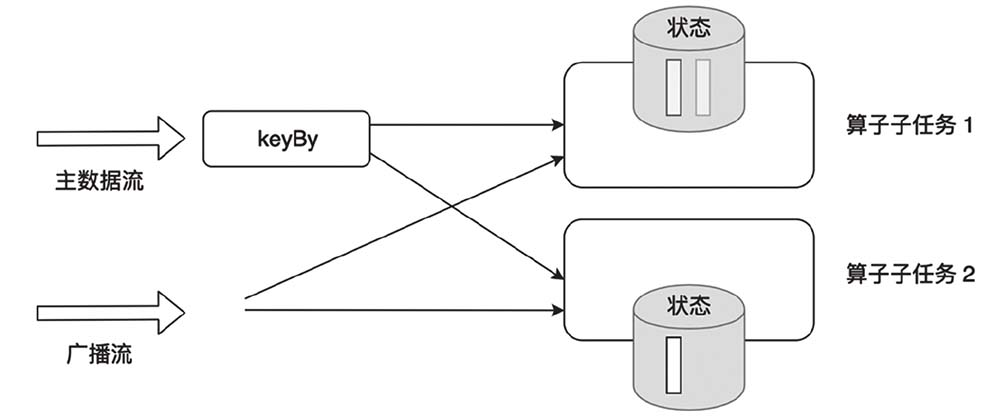
6.2 Checkpoint
Flink 定期保存状态数据到存储空间上,故障发生后从之前的备份中恢复,这个过程被称为 Checkpoint 机制。Checkpoint 为 Flink 提供了 Exactly-Once 的投递保障。<br /> 默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 _n_ 是进行 checkpoint 的间隔,单位毫秒。
- 暂停处理新流入数据,将新数据缓存起来。
- 将算子子任务的本地状态数据复制到一个远程的持久化存储空间上。
继续处理新流入的数据,包括刚才缓存起来的数据。
第一,Checkpoint过程是轻量级的,尽量不影响正常数据处理;第二,故障恢复越快越好。 ```python env = StreamExecutionEnvironment.get_execution_environment()
每 1000ms 开始一次 checkpoint
env.enable_checkpointing(1000)
高级选项:
设置模式为精确一次 (这是默认值)
env.get_checkpoint_config().set_checkpointing_mode(CheckpointingMode.EXACTLY_ONCE)
确认 checkpoints 之间的时间会进行 500 ms
env.get_checkpoint_config().set_min_pause_between_checkpoints(500)
Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.get_checkpoint_config().set_checkpoint_timeout(60000)
允许两个连续的 checkpoint 错误
env.get_checkpoint_config().set_tolerable_checkpoint_failure_number(2)
同一时间只允许一个 checkpoint 进行
env.get_checkpoint_config().set_max_concurrent_checkpoints(1)
使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.get_checkpoint_config().enable_externalized_checkpoints( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
开启实验性的 unaligned checkpoints
env.get_checkpoint_config().enable_unaligned_checkpoints()
<a name="SQdRg"></a>## 6.3 SavepointCheckpoint 机制的目的是为了故障重启,使得作业中的状态数据与故障重启之前的保持一致,是一种应对意外情况的有力保障。Savepoint 机制的目的是手动备份数据,以便进行调试、迁移、迭代等,是一种协助开发者的支持功能。<br /> 第一,刻意备份;第二,支持修改状态数据或业务逻辑。<a name="FyXc5"></a># 7. Table API & SQLFlink 使用一个名为执行计划器(Planner)的组件将 Table API 或 SQL 语句中的关系型查询转换为可执行的Flink 作业,并对作业进行优化。<br /> 这一块官方中文文档写的很好,请多阅读 [https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/python/table/intro_to_table_api/](https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/python/table/intro_to_table_api/)。```pythonfrom pyflink.table import EnvironmentSettings, TableEnvironment# 1. 创建 TableEnvironmentenv_settings = EnvironmentSettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)# 2. 创建 source 表table_env.execute_sql("""CREATE TABLE datagen (id INT,data STRING) WITH ('connector' = 'datagen','fields.id.kind' = 'sequence','fields.id.start' = '1','fields.id.end' = '10')""")# 3. 创建 sink 表table_env.execute_sql("""CREATE TABLE print (id INT,data STRING) WITH ('connector' = 'print')""")# 4. 查询 source 表,同时执行计算# 通过 Table API 创建一张表:source_table = table_env.from_path("datagen")# 或者通过 SQL 查询语句创建一张表:source_table = table_env.sql_query("SELECT * FROM datagen")result_table = source_table.select(source_table.id + 1, source_table.data)# 5. 将计算结果写入给 sink 表# 将 Table API 结果表数据写入 sink 表:result_table.execute_insert("print").wait()# 或者通过 SQL 查询语句来写入 sink 表:table_env.execute_sql("INSERT INTO print SELECT * FROM datagen").wait()
7.1 TableEnvironment
from pyflink.table import EnvironmentSettings, TableEnvironment# create a streaming TableEnvironmentenv_settings = EnvironmentSettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)
这些 APIs 用来创建或者删除 Table API/SQL 表和写查询:
| APIs | 描述 |
|---|---|
| from_elements(elements, schema=None, verify_schema=True) | 通过元素集合来创建表。 |
| from_pandas(pdf, schema=None, split_num=1) | 通过 pandas DataFrame 来创建表。 |
| from_path(path) | 通过指定路径下已注册的表来创建一个表,例如通过 create_temporary_view 注册表。 |
| sql_query(query) | 执行一条 SQL 查询,并将查询的结果作为一个 Table 对象。 |
| create_temporary_view(view_path, table) | 将一个 Table 对象注册为一张临时表,类似于 SQL 的临时表。 |
| drop_temporary_view(view_path) | 删除指定路径下已注册的临时表。 |
| drop_temporary_table(table_path) | 删除指定路径下已注册的临时表。 你可以使用这个接口来删除临时 source 表和临时 sink 表。 |
| execute_sql(stmt) | 执行指定的语句并返回执行结果。 执行语句可以是 DDL/DML/DQL/SHOW/DESCRIBE/EXPLAIN/USE。 |
注意,对于 “INSERT INTO” 语句,这是一个异步操作,通常在向远程集群提交作业时才需要使用。 但是,如果在本地集群或者 IDE 中执行作业时,你需要等待作业执行完成,这时你可以查阅 这里
来获取更多细节。
更多关于 SQL 语句的细节,可查阅 SQL
文档。 |
7.2 Table
Table 是 Python Table API 的核心组件。Table 是 Table API 作业中间结果的逻辑表示。<br />一个 Table 实例总是与一个特定的 TableEnvironment 相绑定。不支持在同一个查询中合并来自不同 TableEnvironments 的表,例如 join 或者 union 它们。<br />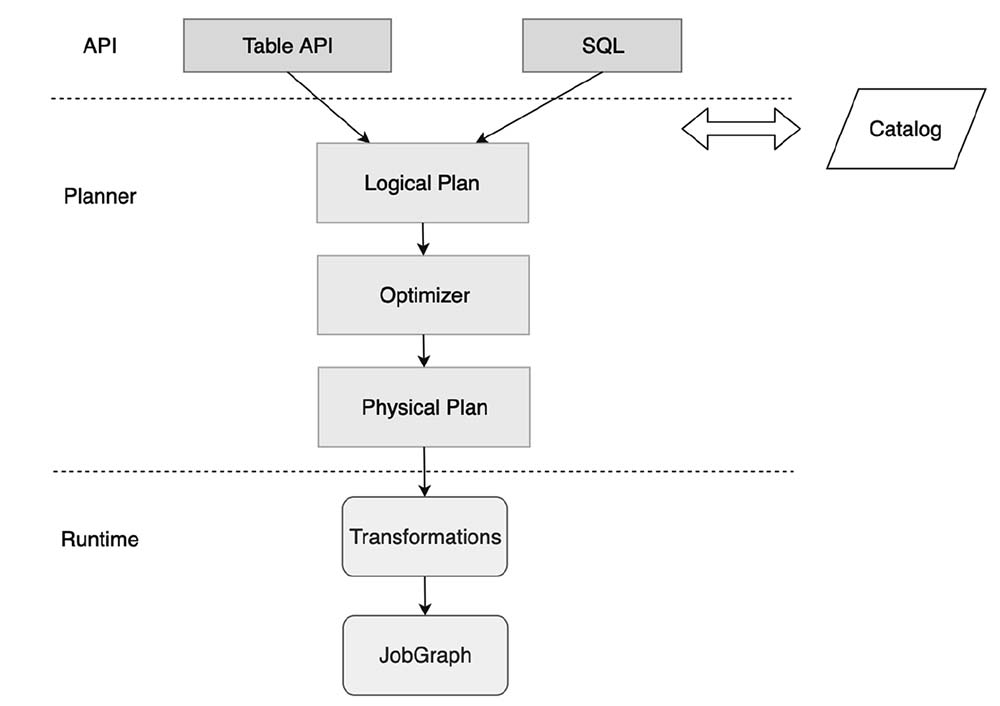
7.2.1 通过列表类型的对象创建
from pyflink.table import EnvironmentSettings, TableEnvironment# 创建 批 TableEnvironmentenv_settings = EnvironmentSettings.in_batch_mode()table_env = TableEnvironment.create(env_settings)table1 = table_env.from_elements([(1, 'Hi'), (2, 'Hello')])table1.to_pandas()# 你也可以创建具有指定列名的表table2 = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])table2.to_pandas()
7.2.2 通过 DDL 创建
支持直接使用 数据库定义语言 创建表结构,并且指定数据源。
from pyflink.table import EnvironmentSettings, TableEnvironment# 创建 流 TableEnvironmentenv_settings = EnvironmentSettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)table_env.execute_sql("""CREATE TABLE random_source (id BIGINT,data TINYINT) WITH ('connector' = 'datagen','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='3','fields.data.kind'='sequence','fields.data.start'='4','fields.data.end'='6')""")table = table_env.from_path("random_source")table.to_pandas()
7.3 查询
Table 对象有许多方法,可以用于进行关系操作。 这些方法返回新的 Table 对象,表示对输入 Table 应用关系操作之后的结果。 这些关系操作可以由多个方法调用组成,例如 table.group_by(...).select(...)。
7.3.1 Table API 查询
from pyflink.table import EnvironmentSettings, TableEnvironment# 通过 batch table environment 来执行查询env_settings = EnvironmentSettings.in_batch_mode()table_env = TableEnvironment.create(env_settings)orders = table_env.from_elements([('Jack', 'FRANCE', 10), ('Rose', 'ENGLAND', 30), ('Jack', 'FRANCE', 20)],['name', 'country', 'revenue'])# 计算所有来自法国客户的收入revenue = orders \.select(orders.name, orders.country, orders.revenue) \.where(orders.country == 'FRANCE') \.group_by(orders.name) \.select(orders.name, orders.revenue.sum.alias('rev_sum'))revenue.to_pandas()
7.3.2 SQL 查询
Flink 的 SQL 基于 [Apache Calcite](https://calcite.apache.org),它实现了标准的 SQL。SQL 查询语句使用字符串来表达。[SQL](https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/sql/overview/) 文档描述了 Flink 对流和批处理所支持的 SQL。<br /> 下面示例展示了一个简单的 SQL 聚合查询:
from pyflink.table import EnvironmentSettings, TableEnvironment# 通过 stream table environment 来执行查询env_settings = EnvironmentSettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)table_env.execute_sql("""CREATE TABLE random_source (id BIGINT,data TINYINT) WITH ('connector' = 'datagen','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='8','fields.data.kind'='sequence','fields.data.start'='4','fields.data.end'='11')""")table_env.execute_sql("""CREATE TABLE print_sink (id BIGINT,data_sum TINYINT) WITH ('connector' = 'print')""")table_env.execute_sql("""INSERT INTO print_sinkSELECT id, sum(data) as data_sum FROM(SELECT id / 2 as id, data FROM random_source)WHERE id > 1GROUP BY id""").wait()
7.3.3 Explain 表
Table API 提供了一种机制来查看 Table 的逻辑查询计划和优化后的查询计划。 这是通过 Table.explain() 或者 StatementSet.explain() 方法来完成的。Table.explain() 可以返回一个 Table 的执行计划。 <br /> StatementSet.explain() 则可以返回含有多个 sink 的作业的执行计划。这些方法会返回一个字符串,字符串描述了以下三个方面的信息:
- 关系查询的抽象语法树,即未经优化的逻辑查询计划,
- 优化后的逻辑查询计划,
- 物理执行计划。
```python
使用流模式 TableEnvironment
from pyflink.table import EnvironmentSettings, TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode() table_env = TableEnvironment.create(env_settings)
table1 = table_env.from_elements([(1, ‘Hi’), (2, ‘Hello’)], [‘id’, ‘data’]) table2 = table_env.from_elements([(1, ‘Hi’), (2, ‘Hello’)], [‘id’, ‘data’]) table = table1 \ .where(table1.data.like(‘H%’)) \ .union_all(table2) print(table.explain())
<a name="DE97H"></a>## 7.4 连接器由于 Flink 是一个基于 Java/Scala 的项目,连接器(connector)和格式(format)的实现是作为 jar 包存在的, 要在 PyFlink 作业中使用,首先需要将其指定为作业的依赖。通常放在 PyFlink 的 lib 目录下,或者指定 jar 包位置。```pythontable_env.get_config().get_configuration().set_string("pipeline.jars", "file:///my/jar/path/connector.jar;file:///my/jar/path/json.jar")
比如 Kafka 的操作。
source_ddl = """CREATE TABLE source_table(a VARCHAR,b INT) WITH ('connector' =' = 'kafka','topic' = 'source_topic','properties.bootstrap.servers' = 'kafka:9092','properties.group.id' = 'test_3','scan.startup.mode' = 'latest-offset','format' = 'json')"""sink_ddl = """CREATE TABLE sink_table(a VARCHAR) WITH ('connector' = 'kafka','topic' = 'sink_topic','properties.bootstrap.servers' = 'kafka:9092','format' = 'json')"""t_env.execute_sql(source_ddl)t_env.execute_sql(sink_ddl)t_env.sql_query("SELECT a FROM source_table") \.execute_insert("sink_table").wait()

若有收获,就点个赞吧
0 人点赞
