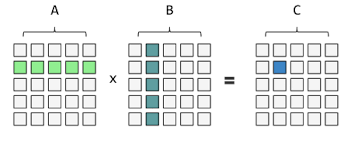
机器学习中,数据的形态转变十分频繁,今天我们就来看看如何做数据的变换
改变形态
改变形态,其实是针对与多维度空间上的数据,要改变它的维度信息,和每个维度中的数据格式。所以第一点你就要清楚,如何添加维度。 其实在 多维数据教程中 中我们就提到过添加维度的方法,我这里在总结括展一下。
import numpy as npa = np.array([1,2,3,4,5,6])### np.newaxisa_2d = a[np.newaxis, :]print( a_2d)[[1 2 3 4 5 6]]print(a.shape, a_2d.shape)(6,) (1, 6)### None 和 np.expand_dims(),a = np.array([1,2,3,4,5,6])a_none = a[:, None]a_expand = np.expand_dims(a, axis=1)print( a_none)[[1][2][3][4][5][6]]print(a_none.shape, a_expand.shape)(6, 1) (6, 1)
a_squeeze = np.squeeze(a_expand)a_squeeze_axis = a_expand.squeeze(axis=1)print(a_expand)print(a_squeeze)print(a_squeeze.shape)print(a_squeeze_axis)print(a_squeeze_axis.shape)[[1][2][3][4][5][6]][1 2 3 4 5 6](6,)[1 2 3 4 5 6](6,)
矩阵点积运算 dot()
a = np.array([[1, 2],[3, 4]])b = np.array([[5, 6],[7, 8]])print(a.dot(b))[[19 22] [43 50]]print(np.dot(a, b))[[19 22] [43 50]]
从上面可以看出,你有两种写法。1)直接用一个矩阵 dot 另一个;2)用 np.dot(a, b) 把两个矩阵包起来。
数据统计分析
用 Numpy 做数据分析理所应当,但是如果数据的种类多样的话,推荐用 Pandas 来做分析的. 不过,在数据量比较大的时候,我更喜欢直接 Numpy 来搞,因为 Numpy 的速度还是要比 Pandas 快上不少。
那么什么是数据分析呢?其实也就是在数据中找到你想要的一些变量,总结数据的规律。最简单的当属找到最大值最小值了。 比如上面的身高数据,你想找全班最高和最矮的。
a = np.array([150, 166, 183, 170])print("最大:", np.max(a))print("最小:", a.min())最大: 183最小: 150print("总共:", a.sum())总共: 669print("累乘:", a.prod())print("总数:", a.size)累乘: 774639000总数: 4print("平均身高:", np.mean(a))print("身高中位数:", np.median(a))平均身高: 167.25身高中位数: 168.0print("标准差:", np.std(a))标准差: 11.776565713313877
特殊运算符号
# 天花板的值 地板的值a = np.array([150.1, 166.4, 183.7, 170.8])print("ceil:", np.ceil(a)) #取天花板的值print("floor:", np.floor(a)) #还是地板的值ceil: [151. 167. 184. 171.]floor: [150. 166. 183. 170.]## 上限下限a = np.array([150.1, 166.4, 183.7, 170.8])print("clip:", a.clip(160, 180))clip: [160. 166.4 180. 170.8]

若有收获,就点个赞吧
0 人点赞
