脏数据
不完美的数据
Numpy 的一切都是和数据打交道,但是在世纪情况下数据其实是不完整,不完美的。比如下面这张图里面, 你会发现,这份数据显然有些不完整的地方,city有数据缺失,duration 虽然是时间上的数据,但是时间单位不统一,时间格式不统一, 这都给后面我们让机器使用这份数据增加难度。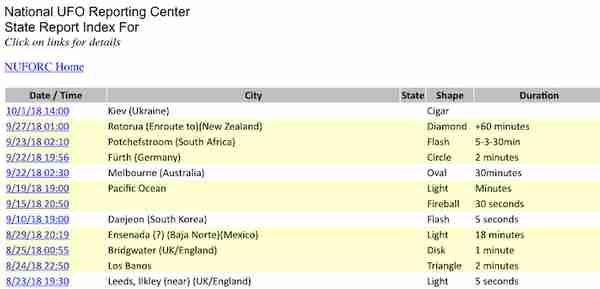
脏数据类型
其实如果你真有做过数据分析,当你拿到一份数据的时候,是十分期望这份数据没什么问题的,但是事与愿违,通常这份数据都多多少少有些问题。 常见的脏数据种类有:
raw_data = [
[“Name”, “StudentID”, “Age”, “AttendClass”, “Score”],
[“小明”, 20131, 10, 1, 67],
[“小花”, 20132, 11, 1, 88],
[“小菜”, 20133, None, 1, “98”],
[“小七”, 20134, 8, 1, 110],
[“花菜”, 20134, 98, 0, None],
[“刘欣”, 20136, 12, 0, 12]
]
data = np.array(raw_data) data array([[‘Name’, ‘StudentID’, ‘Age’, ‘AttendClass’, ‘Score’], [‘小明’, 20131, 10, 1, 67], [‘小花’, 20132, 11, 1, 88], [‘小菜’, 20133, None, 1, ‘98’], [‘小七’, 20134, 8, 1, 110], [‘花菜’, 20134, 98, 0, None], [‘刘欣’, 20136, 12, 0, 12]], dtype=object)
这时的 array 输出的结果,结尾处有一个标识。dtype=object,这种 dtype 会对后续数据处理带来很多麻烦,Python list 直接转换过来的 data 是无法参与诸多 Numpy 计算的。 而只有 dtype 为 int,float 这样的数值形式,才能参与运算。<a name="goFBZ"></a>## 数据清洗流程<a name="xTMZW"></a>### 1 数据预处理去掉行首列首,筛选过滤string```pythondata_process = []for i in range(len(raw_data)):if i == 0:continue # 不要首行字符串# 去掉首列名字data_process.append(raw_data[i][1:])data = np.array(data_process, dtype=np.float) # 字符转化为数字,缺失值转化为nan,因为这份数据中存在 None,而只有 np.float 能转换 Noneprint("data.dtype", data.dtype)print(data)data.dtype float64[[2.0131e+04 1.0000e+01 1.0000e+00 6.7000e+01][2.0132e+04 1.1000e+01 1.0000e+00 8.8000e+01][2.0133e+04 nan 1.0000e+00 9.8000e+01][2.0134e+04 8.0000e+00 1.0000e+00 1.1000e+02][2.0134e+04 9.8000e+01 0.0000e+00 nan][2.0136e+04 1.2000e+01 0.0000e+00 1.2000e+01]]
2 清洗数据
1,索引号重复检查和修改
我们要看看有没有什么数据是不合逻辑的。比如我发现学号有重复,可能是在输入学生信息的时候手误输错了。
sid = data[:, 0]unique, counts = np.unique(sid, return_counts=True)print(unique)print(counts)[20131. 20132. 20133. 20134. 20136.][1 1 1 2 1]
我们可以看到有一个数据 20134 重复出现了 2 次。然后综合判断,我们的数据中少了一个 20135,可能就是把某个同学的学号输错了,我们将错误的同学修改过来。
data[4, 0] = 20135print(data)[[2.0131e+04 1.0000e+01 1.0000e+00 6.7000e+01][2.0132e+04 1.1000e+01 1.0000e+00 8.8000e+01][2.0133e+04 nan 1.0000e+00 9.8000e+01][2.0134e+04 8.0000e+00 1.0000e+00 1.1000e+02][2.0135e+04 9.8000e+01 0.0000e+00 nan][2.0136e+04 1.2000e+01 0.0000e+00 1.2000e+01]]
2,缺失的信息补全
查看缺失值,计算有数据的平均数
is_nan = np.isnan(data[:,1])print("is_nan:", is_nan)nan_idx = np.argwhere(is_nan) # 查看缺失值is_nan: [False False True False False False]# 计算有数据的平均年龄,用 ~ 符号可以 True/False 对调mean_age = data[~np.isnan(data[:,1]), 1].mean()print("有数据的平均年龄:", mean_age)有数据的平均年龄: 27.8
3, 处理异常值
我们可以看到有一个 98 岁的学生,这不太正常,所以把这个 98 岁的当异常数据看待。然后用平均值代替。根据项目调整
# ~ 表示 True/False 对调,& 就是逐个做 Python and 的运算normal_age_mask = ~np.isnan(data[:,1]) & (data[:,1] < 20)print("normal_age_mask:", normal_age_mask)normal_age_mask: [ True True False True False True]normal_age_mean = data[normal_age_mask, 1].mean()print("normal_age_mean:", normal_age_mean)normal_age_mean: 10.25data[~normal_age_mask, 1] = normal_age_meanprint("ages:", data[:, 1])ages: [10. 11. 10.25 8. 10.25 12. ]
4, 数据值异常大或小
因为没上课,就没成绩,但是倒数第一行,没上课,怎么还有成绩?还有倒数第三行,成绩居然超出了满分 100 分。这些情况都是我们要处理的情况。
# 没上课的转成 nandata[data[:,2] == 0, 3] = np.nan# 超过 100 分和低于 0 分的都处理一下data[:, 3] = np.clip(data[:, 3], 0, 100)print(data[:, 2:])[[ 1. 67.][ 1. 88.][ 1. 98.][ 1. 100.][ 0. nan][ 0. nan]]print(data)[[2.0131e+04 1.0000e+01 1.0000e+00 6.7000e+01][2.0132e+04 1.1000e+01 1.0000e+00 8.8000e+01][2.0133e+04 1.0250e+01 1.0000e+00 9.8000e+01][2.0134e+04 8.0000e+00 1.0000e+00 1.0000e+02][2.0135e+04 1.0250e+01 0.0000e+00 nan][2.0136e+04 1.2000e+01 0.0000e+00 nan]]

若有收获,就点个赞吧
0 人点赞
