这些术语通常可以互换使用,但是使它们成为唯一技术的区别是什么?
技术已经越来越紧密地嵌入到我们的日常生活中,并且为了跟上消费者期望的步伐,公司越来越依赖于学习算法来使事情变得更轻松。您可以在社交媒体(通过照片中的对象识别)或直接与设备(如Alexa或Siri)交谈中看到其应用。
这些技术通常与人工智能,机器学习,深度学习和神经网络相关联,尽管它们都发挥了作用,但是这些术语在对话中往往可以互换使用,从而导致它们之间细微差别的混淆。希望我们可以使用此博客文章来澄清此处的一些歧义。
人工智能,机器学习,神经网络和深度学习之间的关系如何?
考虑人工智能,机器学习,神经网络和深度学习的最简单方法也许就是像俄罗斯嵌套娃娃那样考虑它们。每个元素实质上都是上一个学期的组成部分。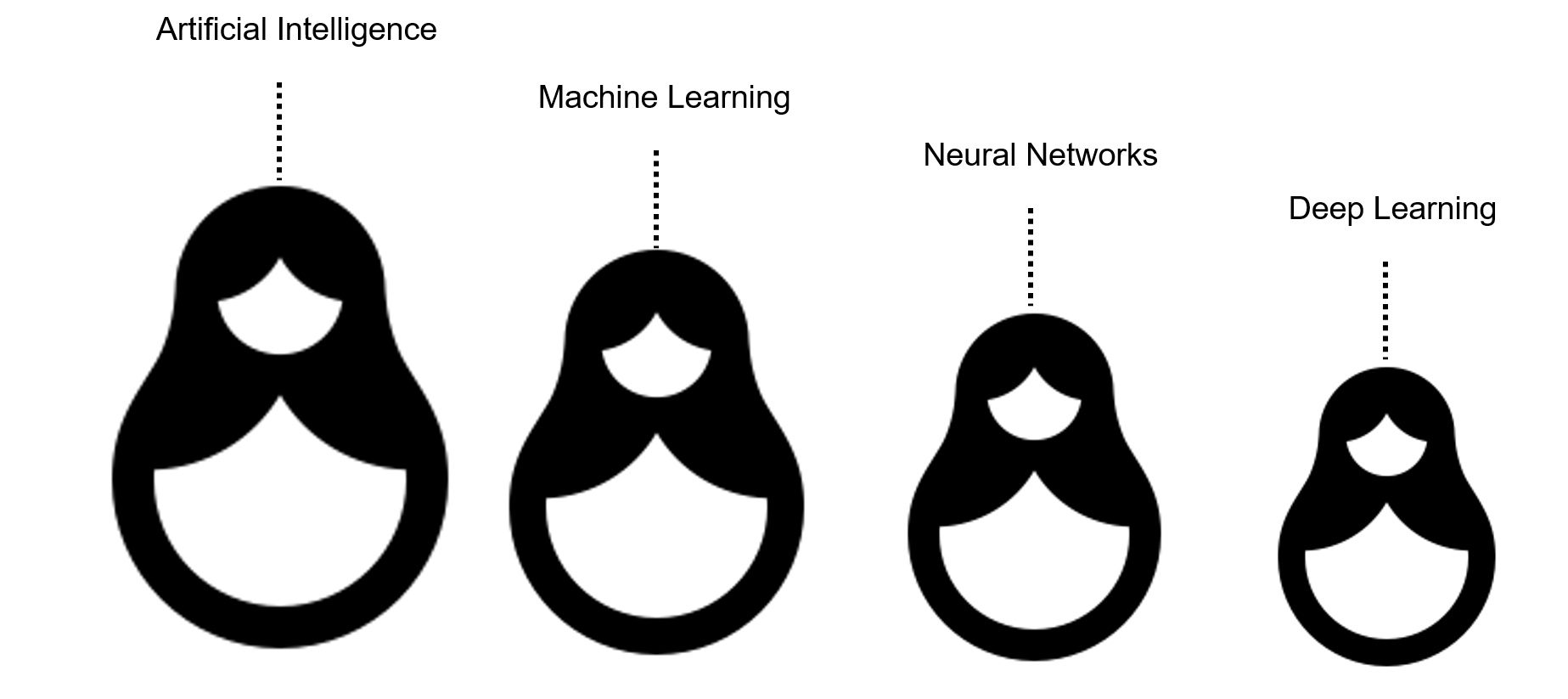
也就是说,机器学习是人工智能的一个子领域。深度学习是机器学习的一个子领域,而神经网络构成了深度学习算法的骨干。实际上,正是神经网络的节点层数或深度将单个神经网络与深度学习算法区分开,深度学习算法必须具有三个以上。
什么是神经网络?
神经网络,更具体地说是人工神经网络(ANN),通过一组算法来模仿人的大脑。在基本层次上,神经网络由四个主要部分组成:输入,权重,偏差或阈值和输出。类似于线性回归,代数公式如下所示: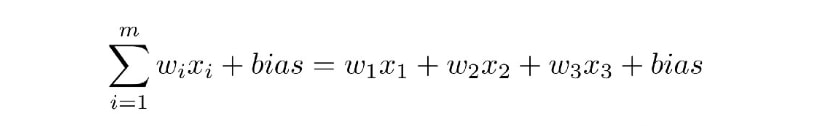
从那里开始,让我们将其应用于一个更具体的示例,例如是否应在晚餐时订购比萨饼。这将是我们的预期结果,即y-hat。假设有三个主要因素会影响您的决定:
- 如果您可以通过订购节省时间(是:1;否:0)
- 如果您要订购披萨来减肥(是:1;否:0)
- 如果您可以省钱(是:1;否:0)
然后,让我们假设以下内容,并提供以下输入:
- X 1 = 1,因为您不做晚餐
- X2 = 0,因为我们得到了所有的浇头
- X 3 = 1,因为我们只得到2个切片
为简单起见,我们的输入将具有0或1的二进制值。这在技术上将其定义为感知器,因为神经网络主要利用S型神经元,它表示从负无穷大到正无穷大的值。这种区分很重要,因为大多数现实世界中的问题都是非线性的,因此我们需要减少所有单个输入对结果的影响程度的值。但是,以这种方式进行汇总将有助于您了解此处的基本数学原理。
继续,我们现在需要分配一些权重以确定重要性。权重越大,与其他输入相比,单个输入对输出的贡献就越显着。
- W 1 = 5,因为您珍惜时间
- W 2 = 3,因为您重视保持身材
- W 3 = 2,因为您在银行中有钱
最后,我们还将假设阈值为5,这将转换为–5的偏差值。
由于我们为求和建立了所有相关的值,因此我们现在可以将它们插入此公式中。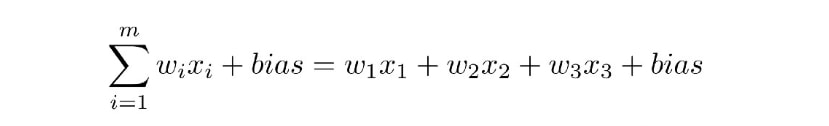
使用以下激活函数,我们现在可以计算输出(即,我们决定订购披萨):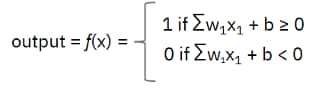
总之:
Y形帽子(我们的预期结果)=决定是否订购披萨
Y帽子=(1 5)+(0 3)+(1 2)-5
Y帽= 5 + 0 + 2 – 5
Y帽= 2,大于零。
由于Y-hat为2,因此激活函数的输出将为1,这意味着我们*将订购披萨(我的意思是,谁不喜欢披萨)。
如果任何单个节点的输出都超过指定的阈值,则该节点将被激活,将数据发送到网络的下一层。否则,不会将任何数据传递到网络的下一层。现在,想象一下,由于神经网络倾向于具有多个“隐藏”层作为深度学习算法的一部分,因此对于单个决策,上述过程将重复多次。每个隐藏层都有其自己的激活功能,可能会将信息从上一层传递到下一层。一旦隐藏层的所有输出都生成,然后将它们用作输入以计算神经网络的最终输出。同样,以上示例只是神经网络的最基本示例;大多数现实世界中的例子都是非线性的,而且要复杂得多。
回归和神经网络之间的主要区别是变化对单个权重的影响。在回归中,您可以更改权重而不会影响函数中的其他输入。但是,神经网络不是这种情况。由于一层的输出传递到网络的下一层,因此单个更改可能会对网络中的其他神经元产生级联效应。
请参阅此IBM Developer文章,以更深入地解释神经网络中涉及的定量概念。
深度学习与神经网络有何不同?
尽管在神经网络的解释中暗含了它,但值得更明确地指出。深度学习中的“深度”是指神经网络中各层的深度。包含三层以上(包括输入和输出)的神经网络可以被视为深度学习算法。通常使用下图来表示: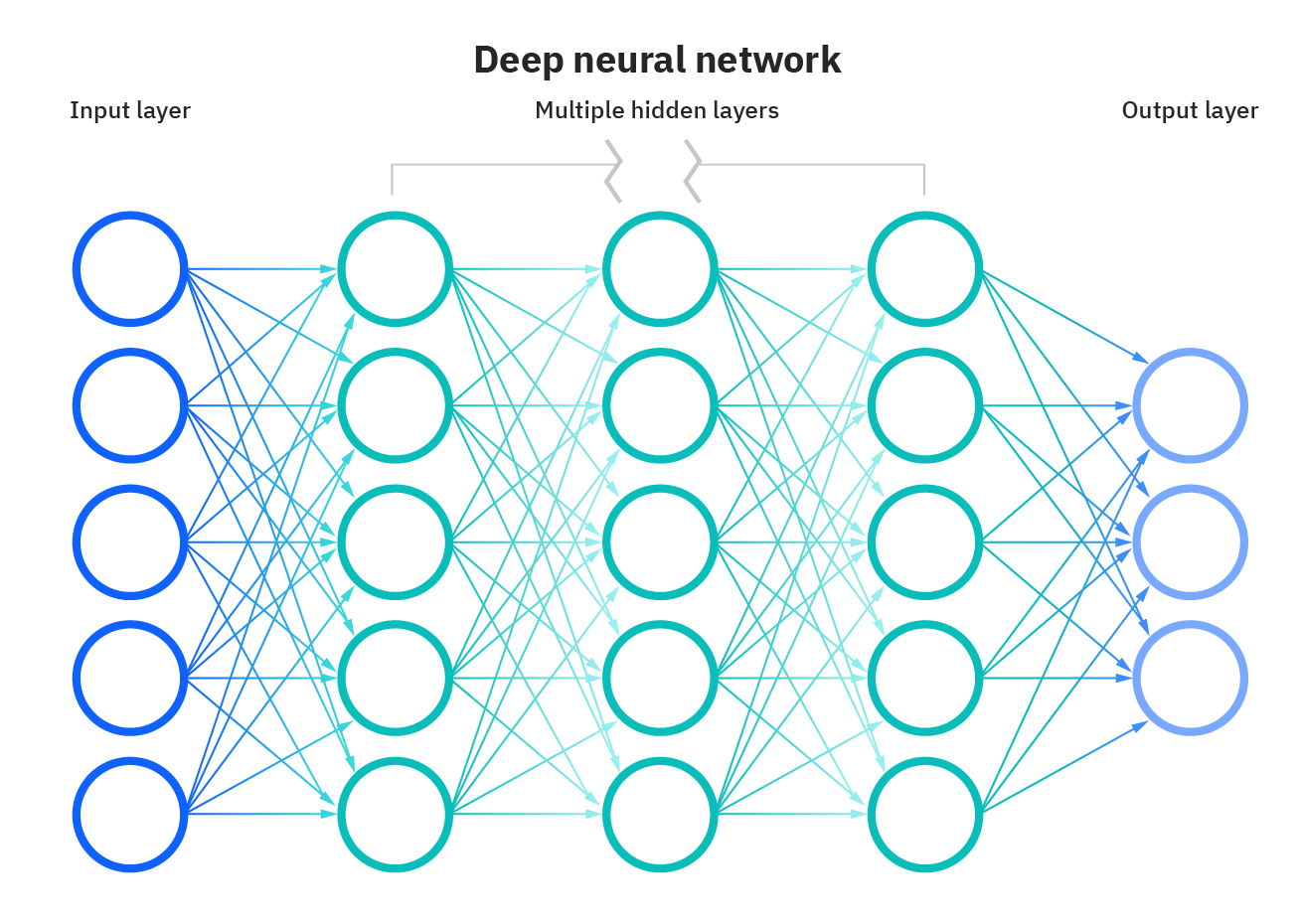
大多数深度神经网络都是前馈的,这意味着它们仅在一个方向上从输入流向输出。但是,您也可以通过反向传播训练模型。也就是说,从输出到输入方向相反。反向传播使我们能够计算和归因于每个神经元的误差,从而使我们能够适当地调整和拟合算法。
深度学习与机器学习有何不同?
正如我们在有关深度学习的学习中心文章中所解释的那样,深度学习只是机器学习的一个子集。它们的区别在于每种算法的学习方式。深度学习可自动执行过程中的大部分特征提取过程,从而消除了一些所需的人工干预,并允许使用更大的数据集。如MIT讲座所述,您可以将深度学习视为“可扩展的机器学习”。
经典的或“非深度”机器学习更依赖于人工干预来学习。人类专家确定功能的层次结构以了解数据输入之间的差异,通常需要学习更多的结构化数据。例如,假设我要向您展示一系列不同类型的快餐(“比萨饼”,“汉堡”或“炸玉米饼”)的图像。这些图像的人类专家将确定将每张图片区分为特定快餐类型的特征。例如,每种食物的面包可能是每张图片上的一个显着特征。另外,我可能只使用“比萨饼”,“汉堡”或“炸玉米饼”之类的标签通过监督学习来简化学习过程。
“深度”机器学习可以利用标记的数据集(也称为监督学习)来告知其算法,但不一定需要标记的数据集。它可以以其原始格式(例如,文本,图像)提取非结构化数据,并且可以自动确定将“比萨饼”,“汉堡”和“炸玉米饼”彼此区分开的功能层次。与机器学习不同,它不需要人工干预即可处理数据,从而使我们能够以更有趣的方式扩展机器学习。要深入了解这些方法之间的差异,请查看“有监督与无监督学习:有什么区别? ”
通过观察数据中的模式,深度学习模型可以适当地对输入进行聚类。以前面的相同示例为例,我们可以根据图像中标识的相似性或差异将比萨饼,汉堡和炸玉米饼的图片分为各自的类别。话虽如此,深度学习模型将需要更多的数据点来提高其准确性,而机器学习模型在给定基础数据结构的情况下依赖于更少的数据。深度学习主要用于更复杂的用例,例如虚拟助手或欺诈检测。
什么是人工智能(AI)?
最后,人工智能(AI)是用于对模仿人类智能的机器进行分类的最广泛的术语。它用于预测,自动化和优化人类历史上已经完成的任务,例如语音和面部识别,决策和翻译。
AI主要分为三类:
- 人工智能(ANI)
- 人工智能(AGI)
- 人工智能(ASI)
ANI被认为是“弱” AI,而其他两种类型则被归类为“强” AI。弱AI是由其完成非常特定任务的能力定义的,例如赢得国际象棋比赛或在一系列照片中识别特定个人的能力。随着我们进入更强大的AI形式(例如AGI和ASI),更多人类行为的整合变得更加突出,例如解释语气和情感的能力。聊天机器人和虚拟助手(例如Siri)正在摸索这方面的内容,但它们仍然是ANI的示例。
强大的AI由其与人类相比的能力来定义。人工智能(AGI)的表现将与其他人类相当,而人工智能(ASI)(也称为超级智能)将超越人类的智力和能力。目前还没有两种形式的Strong AI,但是该领域的持续研究仍在继续。由于AI的这一领域仍在快速发展,因此我可以提供的最好的例子是HBO节目Westworld上的角色Dolores 。

若有收获,就点个赞吧
0 人点赞
