什么是机器学习(ML)
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
Machine learning focuses on applications that learn from experience and improve their decision-making or predictive accuracy over time. 机器学习专注于从经验中学习并随着时间的推移提高其决策或预测准确性的应用程序。
机器学习方法
监督学习
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。也就是说,在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
通俗一点,可以把机器学习理解为我们教机器如何做事情。
监督学习的分类:回归(Regression)、分类(Classification)
**
回归(Regression)
回归问题是针对于连续型变量的。
举个栗子:预测房屋价格
假设想要预测房屋价格,绘制了下面这样的数据集。水平轴上,不同房屋的尺寸是平方英尺,在竖直轴上,是不同房子的价格,单位时(千万$)。给定数据,假设一个人有一栋房子,750平方英尺,他要卖掉这栋房子,想知道能卖多少钱。
这个时候,监督学习中的回归算法就能派上用场了,我们可以根据数据集来画直线或者二阶函数等来拟合数据。
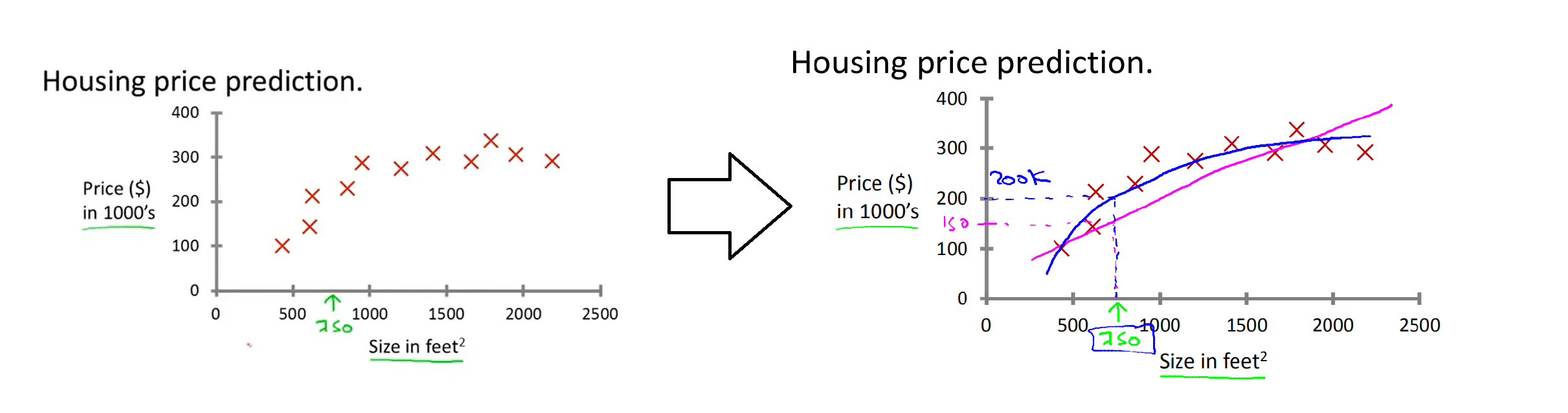
通过图像,我们可以看出直线拟合出来的150k,曲线拟合出来是200k,所以要不断训练学习,找到最合适的模型得到拟合数据(房价)。
回归通俗一点就是,对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。
**
分类(Classification)
和回归最大的区别在于,分类是针对离散型的,输出的结果是有限的。
举个栗子:估计肿瘤性质
假设某人发现了一个乳腺瘤,在乳腺上有个z肿块,恶性瘤是危险的、有害的;良性瘤是无害的。
假设在数据集中,水平轴是瘤的尺寸,竖直轴是1或0,也可以是Y或N。在已知肿瘤样例中,恶性的标为1,良性的标为0。那么,如下,蓝色的样例便是良性的,红色的是恶性的。
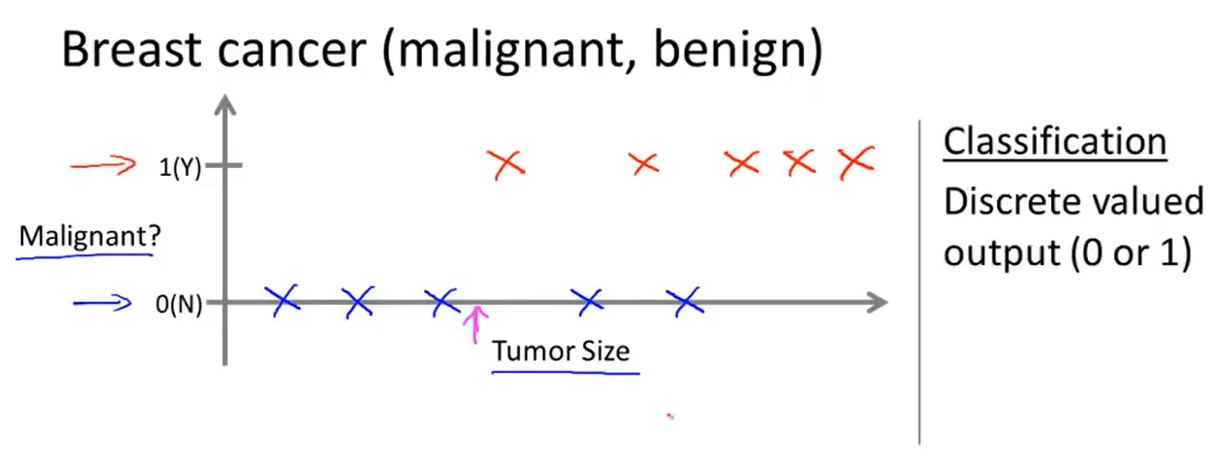
这个时候,机器学习的任务就是估计该肿瘤的性质,是恶性的还是良性的。
那么分类就派上了用场,在这个例子中就是向模型输入人的各种数据的训练样本(这里是肿瘤的尺寸,当然现实生活里会用更多的数据,如年龄等),产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。
所以简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。
无监督学习
定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。
可以这么说,比起监督学习,无监督学习更像是自学,让机器学会自己做事情,是没有标签(label)的。
**
接刚刚上面机器学习解释时用到的例子来更好理解一下二者的区别:
对于平时的考试来说,监督学习相当于我们做了很多题目都知道它的标准答案,所以在学习的过程中,我们可以通过对照答案,来分析问题找出方法,下一次在面对没有答案的问题时,往往也可以正确地解决。 而无监督学习,是我们不知道任何的答案,也不知道自己做得对不对,但是做题的过程中,就算不知道答案,我们还是可以大致的将语文,数学,英语这些题目分开,因为这些问题内在还是具有一定的联系。
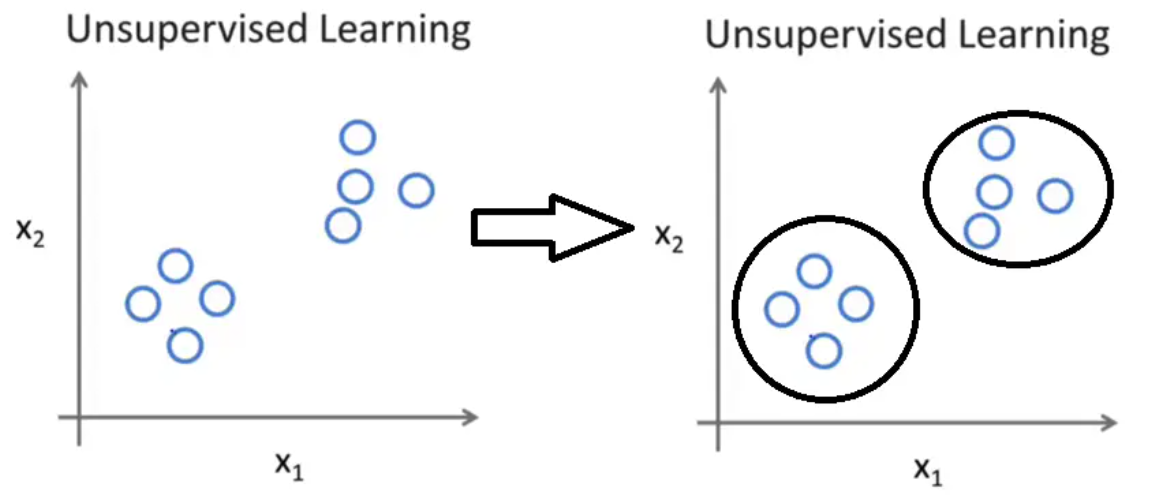
如下图所示,在无监督学习中,我们只是给定了一组数据,我们的目标是发现这组数据中的特殊结构。例如我们使用无监督学习算法会将这组数据分成两个不同的簇,,这样的算法就叫聚类算法。
深度学习
深度学习是机器学习的子集(所有深度学习都是机器学习,但并非所有机器学习都是深度学习)。深度学习算法定义了一个人工神经网络,旨在学习人脑的学习方式。深度学习模型需要通过多层计算的大量数据,并在每个连续的层中应用权重和偏差以不断调整和改善结果。
深度学习模型通常是无监督或半监督的。强化学习模型也可以是深度学习模型。某些类型的深度学习模型-包括卷积神经网络(CNN)和递归神经网络(RNN)-在诸如计算机视觉,自然语言处理(包括语音识别)和自动驾驶汽车等领域推动着进步。

若有收获,就点个赞吧
0 人点赞
