分段机制的原理
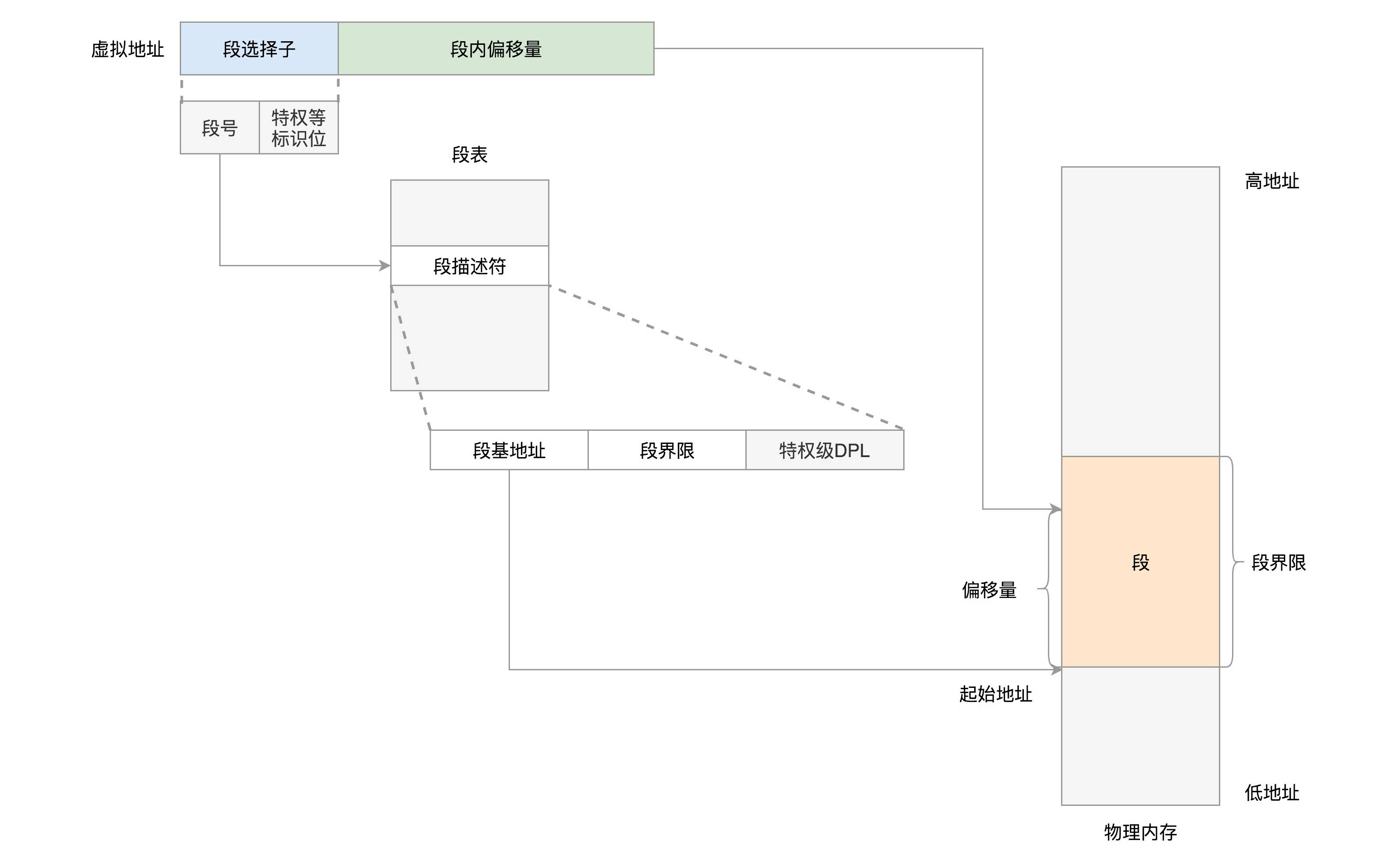
分段机制下的虚拟地址由两部分组成
- 段选择子. 段寄存器中
- 段内偏移量。
段表:
- 基地址
- 段的界限
- 特权等级
段基地址加上段内偏移量得到物理内存地址:
**
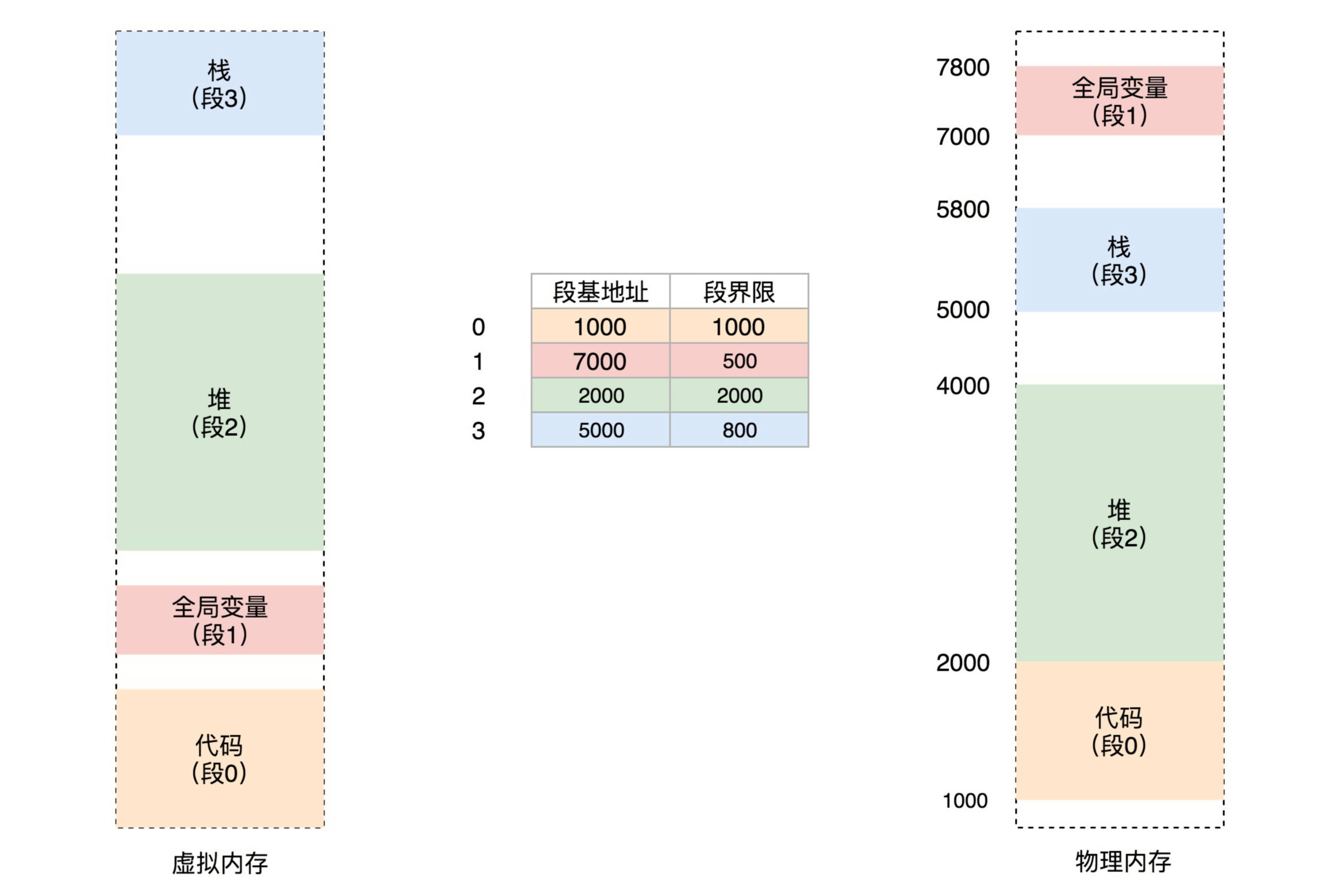
例如,我们将上面的虚拟空间分成以下 4 个段,用 0~3 来编号。每个段在段表中有一个项,在物理空间中,段的排列如下图的右边所示。
在 Linux 里面,段表全称段描述符表(segment descriptors),放在全局描述符表 GDT(Global Descriptor Table)里面,
- 一个段表项由段基地址 base、段界限 limit,还有一些标识符组成。
- 选择子指向段表中的一项
其实 Linux 倾向于另外一种从虚拟地址到物理地址的转换方式,称为分页(Paging)。
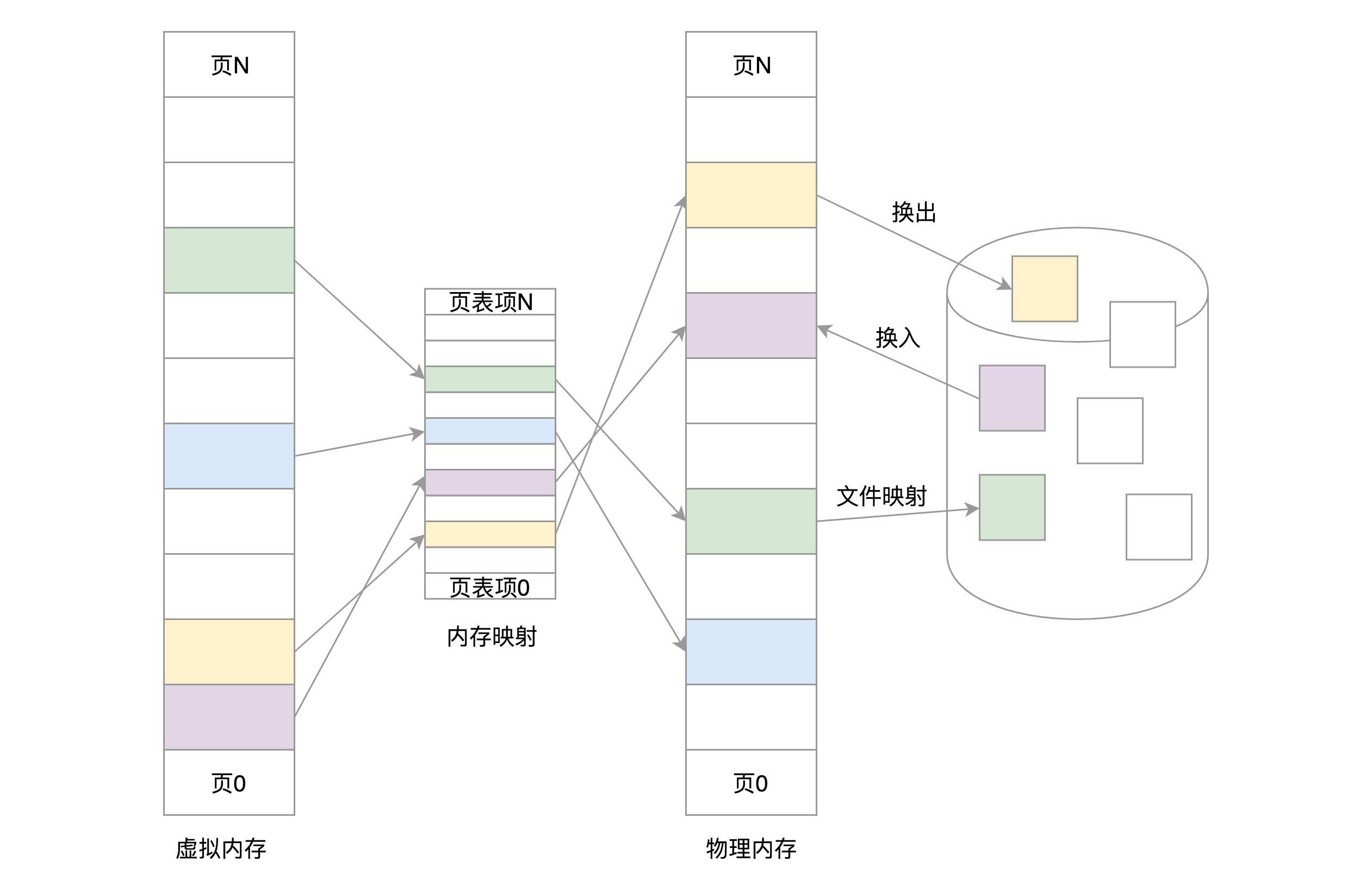
对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫做换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。
这个换入和换出都是以页为单位的。页面的大小一般为 4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址,就能对于内存中的每个位置进行访问了。
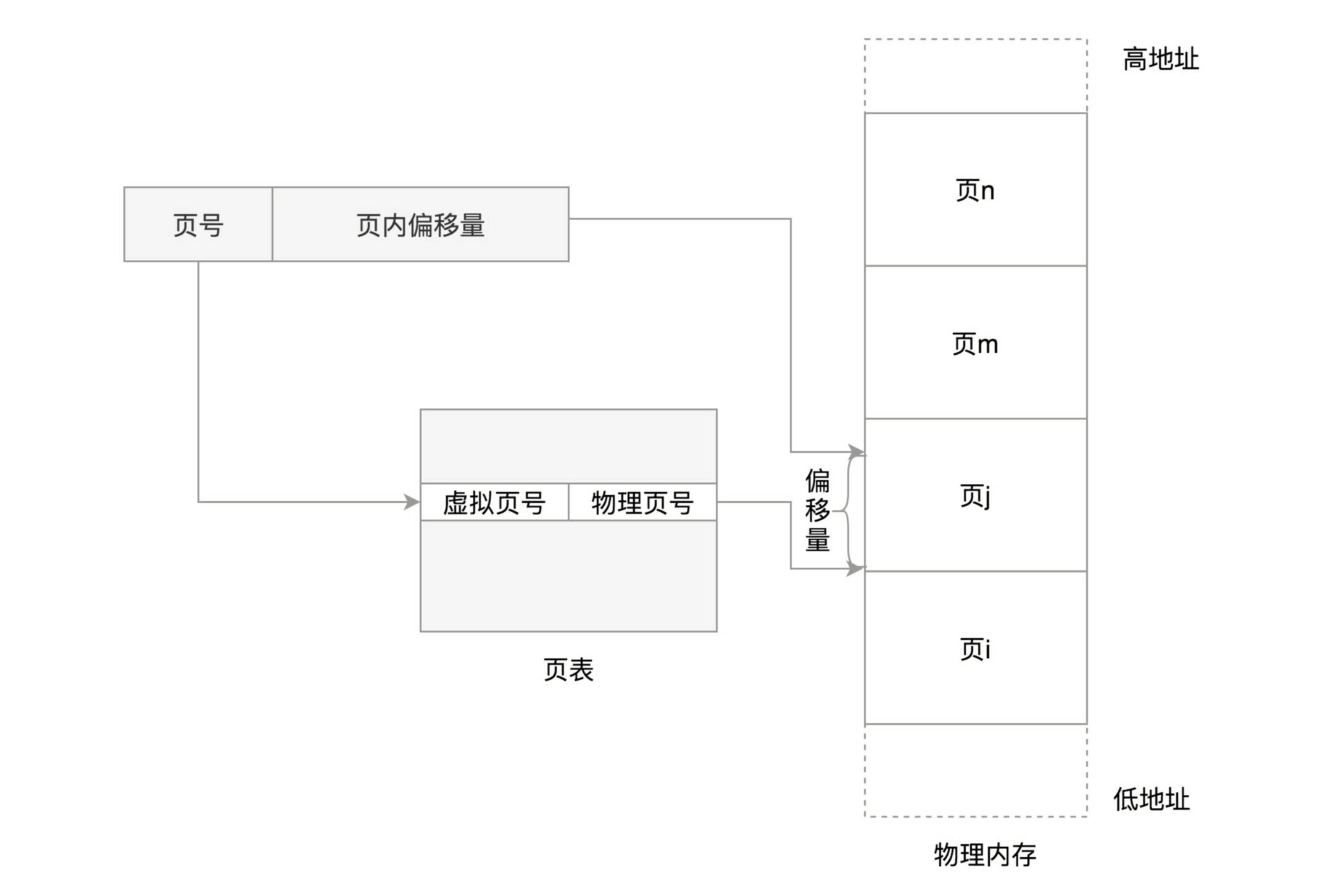
虚拟地址分为两部分:
- 页号
- 页内偏移
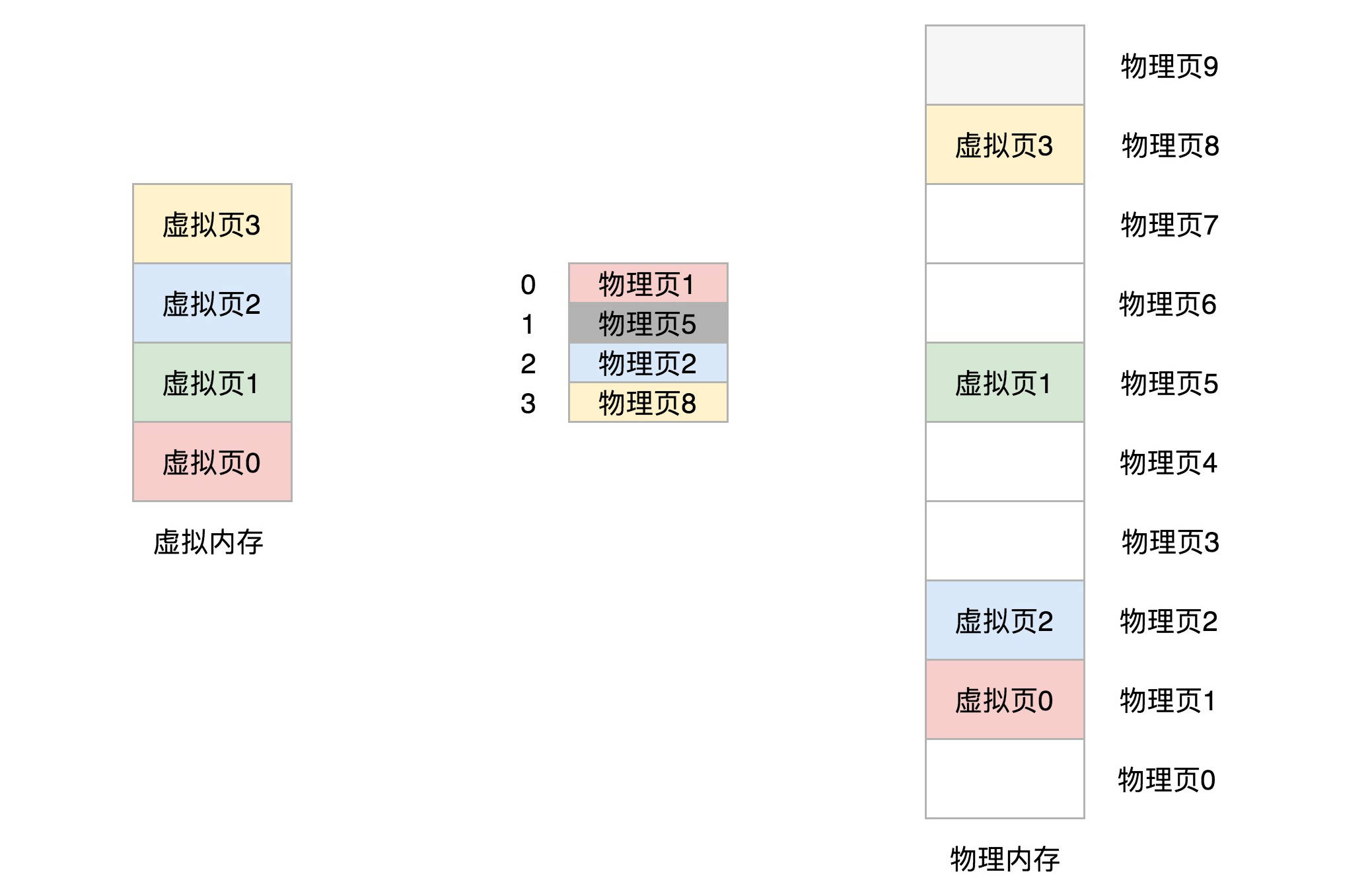
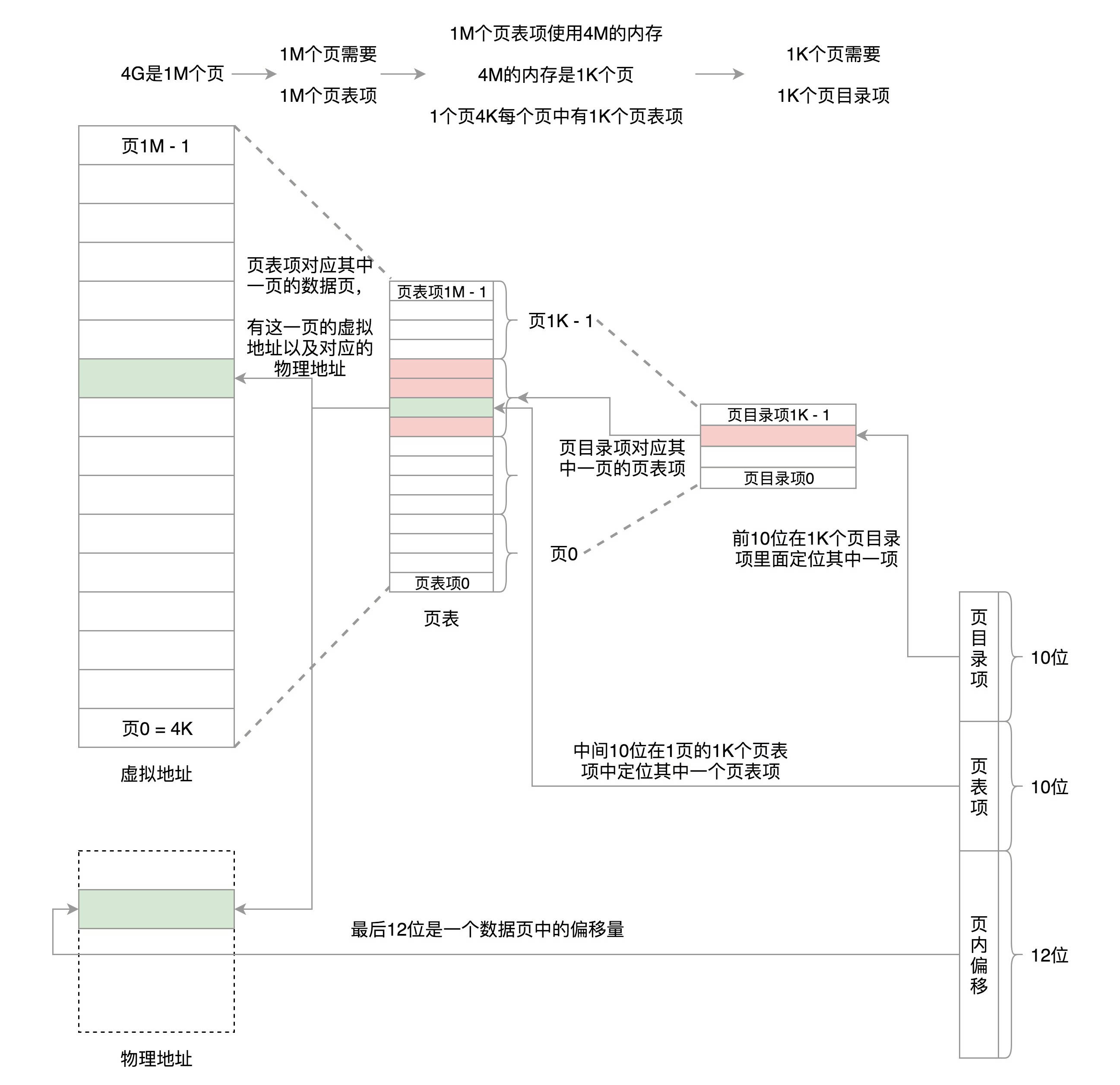
32 位环境下,虚拟地址空间共 4GB。如果分成 4KB 一个页,那就是 1M 个页。每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储映射表。如果每个进程都有自己的映射表,100 个进程就需要 400MB 的内存。对于内核来讲,有点大了 。
按照上面的计算, 一个进程需要 4MB 内存存储页表.
4MB+4KB 的内存
对页表再划分的理由 (实现可以不连续? 利用数组的随机访问?):
- 页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。
一些计算:
- 4GB 内存中, 4KB 为一页时有 1M 个页映射关系 (页表)
- 存储页映射 (页号 - > 物理地址) 需要
1M * 4B = 4MB - 再次将页表进行划分, 建立页表目录
- 将 4MB 中每 4KB 存储到一页, 需要 1K 个页
- 每个页表目录项需要 4B, 总共需要
1K * 4B = 4KB
对页表再划分的理由 (根本解释, 不用完全分配 4MB 的页表, 只完全分配 4KB 的页表目录):
我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的 1M 个页表项共 4M 的内存,但是如果使用了页目录,页目录需要 1K 个全部分配,占用内存 4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多 4K,这样内存就节省多了。
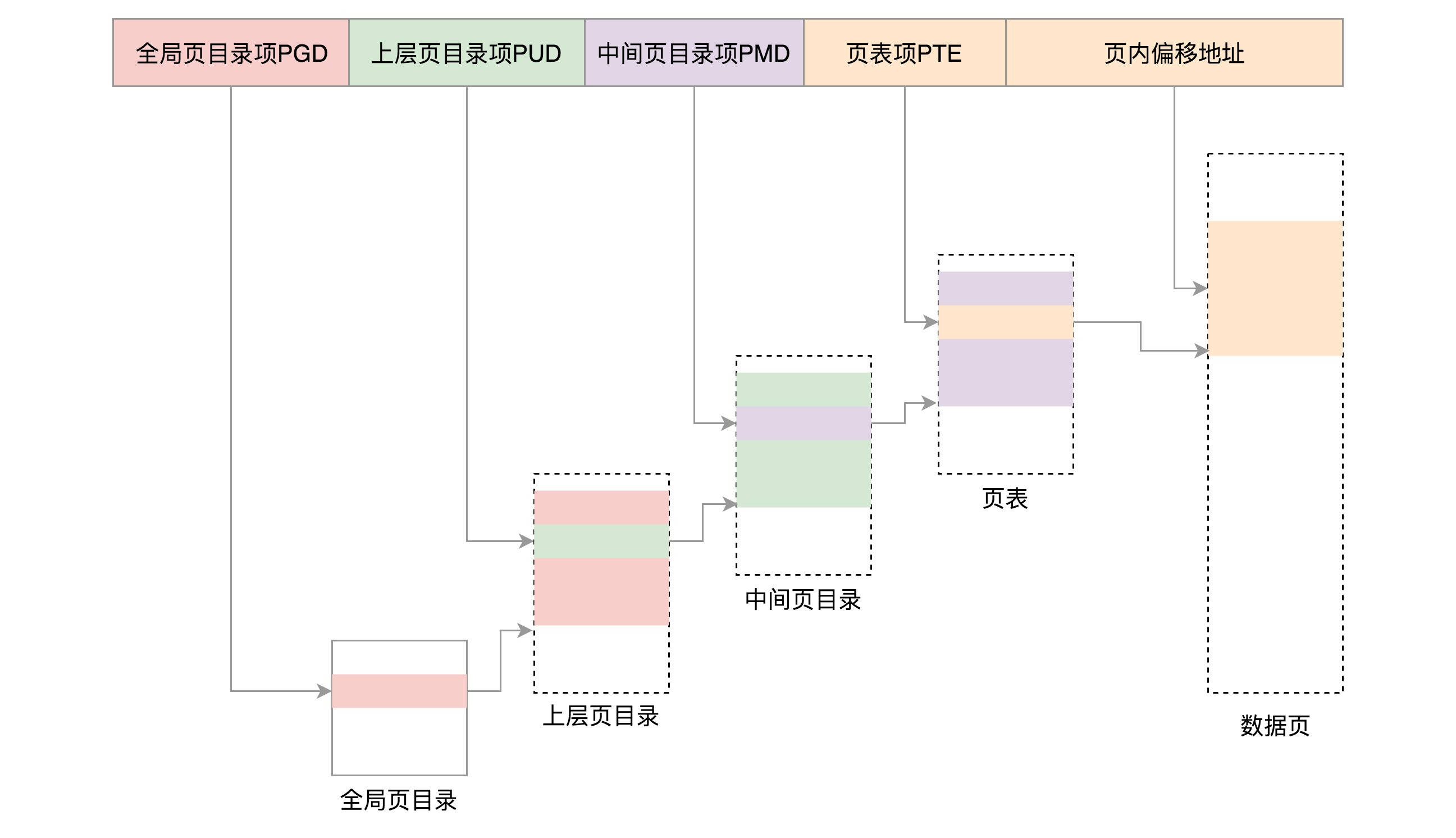
当然对于 64 位的系统,两级肯定不够了,就变成了四级目录,分别是:
- 全局页目录项 PGD(Page Global Directory)
- 上层页目录项 PUD(Page Upper Directory)
- 中间页目录项 PMD(Page Middle Directory)
- 页表项 PTE(Page Table Entry)
总结
我们可以把内存管理系统精细化为下面三件事情:
- 第一,虚拟内存空间的管理,将虚拟内存分成大小相等的页;
- 第二,物理内存的管理,将物理内存分成大小相等的页;
- 第三,内存映射,将虚拟内存页和物理内存页映射起来,并且在内存紧张的时候可以换出到硬盘中。

若有收获,就点个赞吧
0 人点赞
