https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-172-performance-engineering-of-software-systems-fall-2018/
https://www.bilibili.com/video/BV1wA411h7N7?spm_id_from=333.999.0.0
摘要
- 介绍我们为什么需要学习性能工程 (Performance Performance Engineering)
- 以矩阵乘法为例,展示性能工程是如何工作的
为什么需要性能工程
Q:性能是我们在编写软件时最关注的内容吗?
A:不是的,程序员往往有着更关心的特性
Q:但为什么我们依旧需要学习性能工程?
A:性能是相当于系统中的货币,我们可以通过牺牲性能的方法来获取上述的特性
就像水是生命不可离开的部分,但我宁愿要100元而不是一瓶水:钱本身没有价值,但我可以用钱来买水
曾经,货币是免费的,由于 Moore’s Law and the scaling of clock frequency,性能如同印钞机一样源源不断的产生。无需改变软件,随着硬件的提升而提升。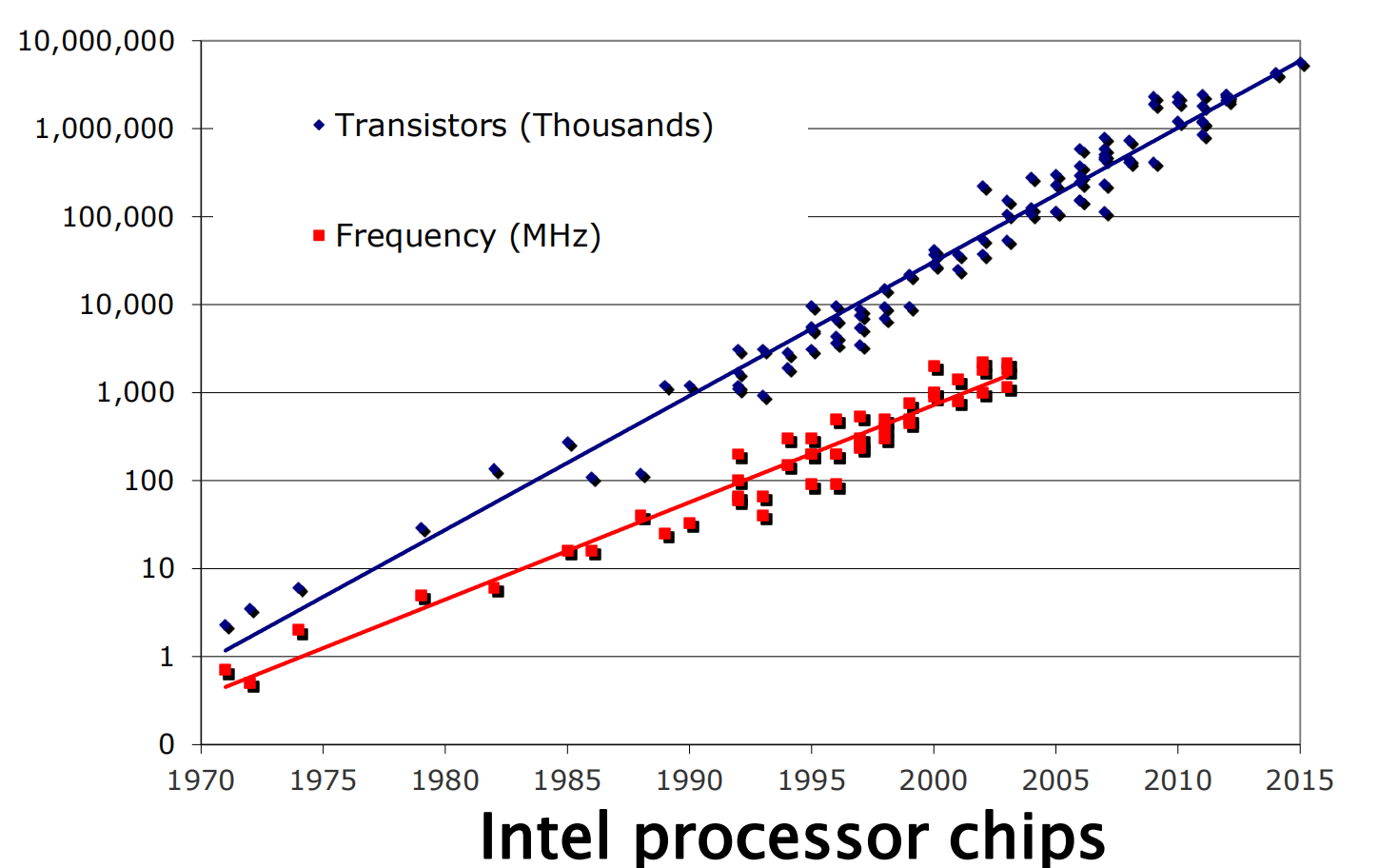
如果你觉得你的程序太慢了,等几个月就好了
然而,Moore’s Law 是有极限的
- 晶体管的大小无法无限制的缩小
- 时钟周期受到散热的限制
现代的解决方案: 多核
现在几乎无法找到单核的芯片
(更多的解决方案:分布式,GPU,都需要软件的支持)
然而,并非所有程序员都可能胜任并行的编程。
No Free Lunch!
性能工程也愈发地受到重视
案例分析:矩阵乘法
- 以矩阵乘法为例,展示性能工程是如何工作的
不考虑算法上的优化 (这是性能工程以外的内容),考虑简单的矩阵乘法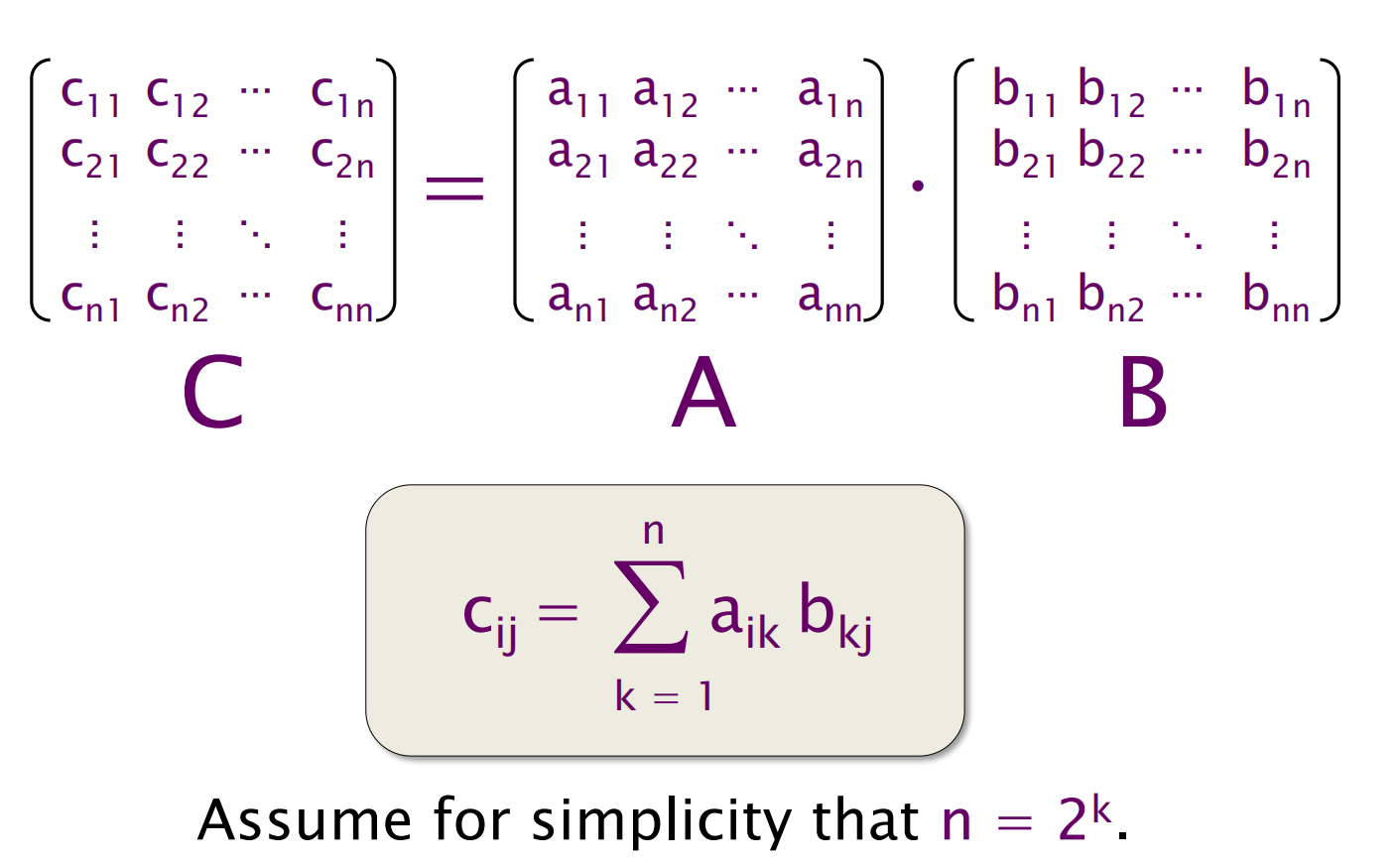
考虑 n 是 2 的幂的严格情况
如何评价一个算法是否是快的?
以浮点数计算的次数为例,思考到达了峰值的多少
编程语言
使用Python,Java,C 分别执行对应程序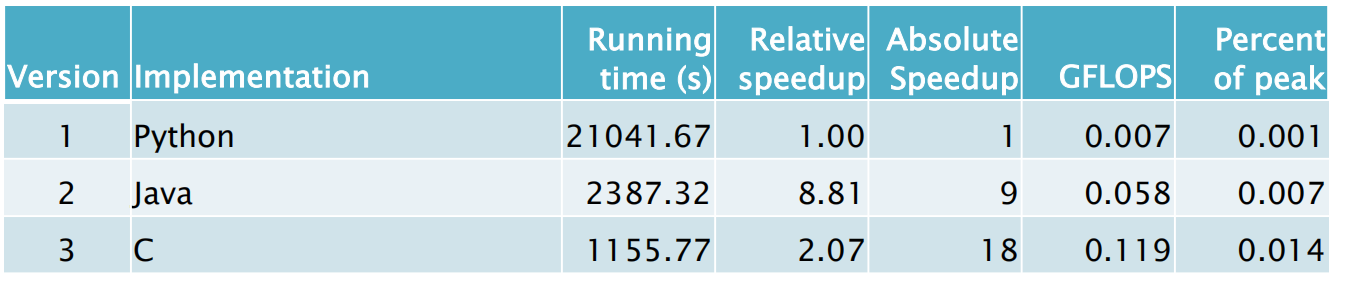
编程语言是如何造成速度的差异的?
- Python is interpreted.
解释语言 - 支持动态的代码变动,但代价是性能
- C is compiled directly to machine code.
- Java is compiled to byte-code, which is then interpreted and just in-time (JIT) compiled to machine code.
JIT complier 介于两者之间,如果一段代码被频繁地运行,系统将会编译其为机器码,以避免过多的性能损失
循环顺序
对于矩阵乘法的三重循环,可以更换顺序
以 i,k,j 的顺序更多地利用了空间局部性
矩阵乘法是非常容易分析的算法;使用Cachegrind工具可以对 Cache Miss 进行分析,以提升算法的空间局部性
Compiler Optimization
编译器优化选项,Clang
(P.S. 在2016年的Slide中,使用的是GCC,十分佩服教学团队的更新)
一般来说,-O3 会提供更多的优化以及更好的性能。
由于矩阵乘法是十分简单的算法,事实上 -O2 的表现已经是最好的
Multicore Parallelism
多核并行计算
we have 18 cores, and 17 of them are just sitting and watching!

Comment:
- k 循环是不可并行的,否则将导致 WAW
- 并行内层循环 j,反而会导致性能的下降。(原则是,并行执行外层循环)
- 并非所有算法都能如此进行
Tiling + Devide & conquer
重新考虑 Cache 以及 Memory access 的问题
以 Block 进行 Memory access 会在进行相同运算时,使用相对更少的 Memory access
【注意:如何分析 Memory Access 的情况】
因此,将原矩阵分解为若干个block进行运算 (像铺地砖一样, tiling),而 block 的大小一般与 Cache size 相关。通过测试(在性能工程中,往往需要通过批量的测试来选定最优参数)选择最合适的 size。
当下的缓存机制存在三层Cache
- 如果使用三层 tiling,将有12层循环,代码可读性大大下降
- 最优参数的调整也十分困难
Devide & Conquer
Devide & Conquer 不仅仅是重要的算法思想,还能提供空间局部性
使用并行化的 Devide & Conquer 算法
使用 cilk_spawn 和 cilk_sync 来控制多进程的分治算法
尽管 Cache Miss 下降了,但时间依旧变慢了,为什么?
(频繁地传参本身是有代价的,需要为分治设置停止的 threshold)
并为 base 状况编写对应的代码
Comment:
- 此处已经由二级寻址改为了一级寻址
- 小tips: restrict是 c99 标准引入的,它只可以用于限定和约束 <指针> ,并表明指针是访问一个 <数据对象> 的唯一且初始的方式。这可以帮助编译器更好地加速程序。
Compiler Vectorization
现代微处理器往往提供向量元件以支持 多数据单运算 single-instruction stream, multiple-data stream (SIMD)
操作
Clang/LLVM 在 -O2 及以上的选项中,支持向量化操作,我们可以使用内置的操作来打印相关的内容
但由于不同机器对于向量化操作的支持程度不同,默认往往只使用保守的设置
我们可以通过 complier-flag 来指定更加高级的向量化操作。
【此处出现了SIGMOD’20 综述中的 AVX2 选项】
使用 –march=native –ffast-math 得到了将近一倍的提升。
AVX Intrinsics
Can we be smarter than the compiler?
微软提供了 intrinsic instructions 来让用户显式的使用向量操作
更多优化
• Preprocessing
• Matrix transposition
• Data alignment
• Memory-management optimizations
• A clever algorithm for the base case that uses AVX
intrinsic instructions explicitly
Conclusion
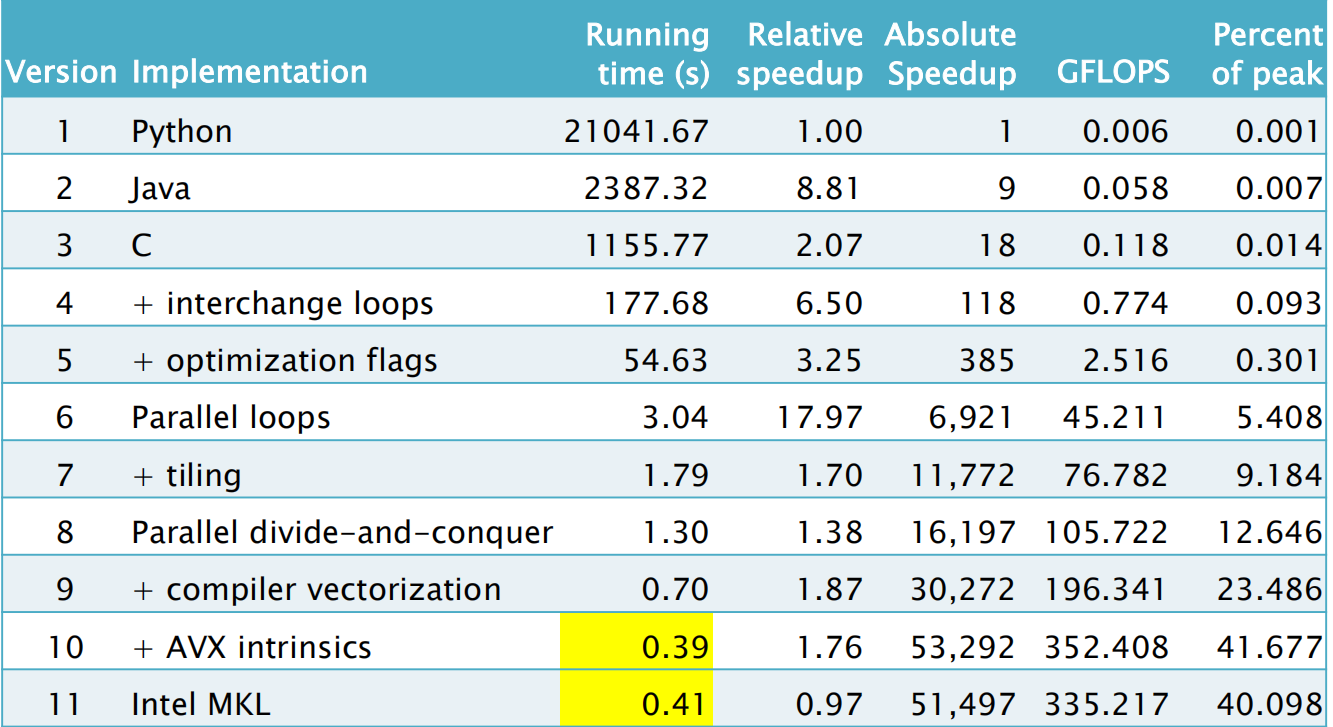
通过这个例子,我们可以看到性能工程是如何工作的,以及如何的有效。

若有收获,就点个赞吧
0 人点赞
