创建好的索引,必须配合对应的查询语句才能发挥其真正的威力。
三星索引得分标准:
- 索引将相关记录放到一起,一星
- 索引中的数据顺序和查找中的排列顺序一致,二星
- 索引中的列表包含了查询中的需要的全部列,三星(现象称为方
覆盖扫描,对应的索引称为全覆盖索引)
独立的列
查询列不能是表达式的一部分,或函数的参数,应始终将所有列单独放在比较符号的一侧。
错误使用示例:
where num + 1 = 5where to_days(date_col) <= 10
前缀索引和索引选择性
对于字符串类的字段,通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。但这样也会降低索引的选择性。拿出前几位做前缀索引是有学问的。
前缀索引
优点:使得索引更快,更小的
缺点:无法做 order by 、group by,无法做到 覆盖扫描
主要用在对 varchar char 字段创建索引,如 md5 值,对定义varchar (255) 创建一个索引,不使用前缀索引时,索引长度是:255 * 3 + 2。
后缀索引:mysql并不支持后缀索引,但是可以通过反转字符串,使用前缀索引的方式实现。使用在 邮箱后缀查询等地方。
索引的选择性
计算方式:索引选择性(c) = 列取值基数(不重复的值)(dn) / 表记录总数 n ,取值范围是 1 ~ n。
索引的选择性越高则查询的效率越高,因为选择性高的索引可以让 MYSQL在查找时过滤掉更多的行。
唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的;
列的选择性计算方式: SELECT COUNT(DISTINCT col_1)/COUNT(*) FROM table;
个人理解:
一共 100 w行数据量,每行的值都是英文字母的随机值。
如果只去第一个字符作为前缀索引。
那么这个索引的选择性为 24 / 1000w, 命中一个索引所对应的行数为 100w / 24;
如果那拿出前2个字母作为前缀索引。
那么这个索引的选择性为 24 * 24 / 1000w, 命中一个索引所对应的行数为 100w / 24 * 24;
随着索引选择的提高,每次命中索引后对应的行数量将会变少,之后的查询或过滤将会更快。
id 主键就是行一个索引,选择性为 1,快速定位一行数据。
但是字符串类型的列表不能将整列值都作为索引,因为btree 索引会将列值也放入索引,所有索引体积将会很大,从而影响索引的查询。
通过计算每个位的选择性,找出合适的能代表整个数据及的才算合适的前缀索引长度。
找出合适索引长度的方法
出现次数对比
-- 查询出现次数最多的类型和其次数分布
select count(1) as cnt,type from table_name group by type order by cnt desc limit 50;
-- 查询每个长度出现次数的变化, 通过N不断自增,所对应的重复次数将不断下降,当降到与上个查询大致一样时就是合适的长度。
select count(1) as cnt,left(type, N) as pre from table_name group by pre order by cnt desc limit 50;
计算完整列的选择性
-- 查询type目前的选择性
select count(distinct type)/ count(1) from table_name;
-- 查询每个长度选择性,选择性更接近上面的选择性就是合适的长度。
select
count(distinct left(type,1))/ count(1)
count(distinct left(type,2))/ count(1)
count(distinct left(type,3))/ count(1)
count(distinct left(type,N))/ count(1)
from table_name;
多列索引
在每个字段上都创建一个索引是不明智的选择。
- 每列创建索引会导致索引空间增大。
- 大多数的查询都是多个字段进行数据查找,但索引只能使用一个。(5.0版本后引入“索引合并”type : index_merge策略,一定程度上解决改问题,好像只出现在 or 查询中,出现 索引合并 从侧面说明了目前的索引很糟糕)
不想进行索引合并的处理方法
- 通过参数 optimizer_switch 关闭索引合并功能
- 通过 force index() 语句让优化器忽略掉某些索引
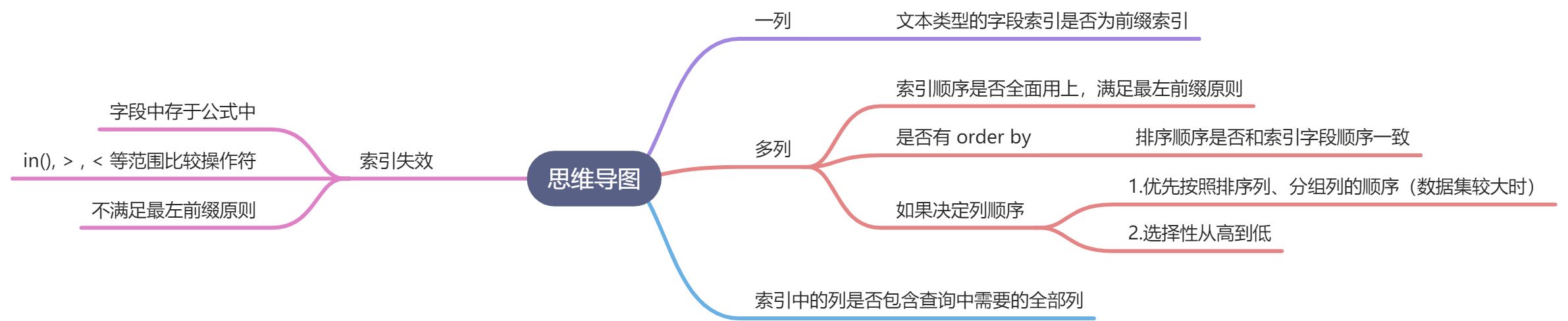
索引列顺序
索引列顺序只适用于 btree 类型索引,hash 或其他类型索引并没有按照一定顺序存储数据。
影响索引顺序的要素:
- 最左前列原则
- 排序语句
- 分组语句
如果决定索引列顺序:
- 当语句中存在排序语句时,且数据量较大时,应该按照排序列的顺序决定索引列顺序,这可以避免排序时的随机IO。
- 当语句中不存在排序语句时,应将选择性最高的列放到最左列,这样可以在索引查询阶段尽可能减少后续的数据集的大小。
选择列的示例与注意点:

聚簇索引
todo 太复杂,没看懂
覆盖索引
查询的列全被包含在索引的列中,被称为 “覆盖索引”。达到这种状态的查询执行速度很快,只需扫描索引数据,无需回表查询,有以下几方面的好处:
- 索引条目通常原小于数据行大小,极大减少了数据访问量,减少了数据拷贝,更容易将数据放入内存中计算(当数据量太大时,mysql会放入硬盘上)
- 索引的列的顺序存储特性对io密集型的方位查询会比随机从磁盘读取没一行数据的io少很多。
哪些索引类型支持覆盖索引:
- 支持:B-Tree
- 不支持:哈希索引、空间索引、全文索引
如何判断是否达到覆盖索引:
explain 的 extra 列显示:Using index
select 无法使用索引覆盖,最好不要 select
使用索引扫描来做排序
只有当索引的列顺序和ORDER BY子句的顺序完全一致,并且所有列的排序方向都一样时,MySQL才能使用索引对结果做排序。
如果查询关联了多张表,则只有当ORDER BY子句引用的字段全部为第一个表时,才能使用索引做排序。
indx(fd_1,fd_2,fd_3) 使用索引排序的几种情况:
where fd_1 = 1 order by fd_2,fd_3索引全部匹配,最左列为常量值时,后续的列课视为一个索引。where fd_1 =1 order by fd_2最左前缀列原则。where fd_1 > 2 order by fd_1,fd_2,fd_3fd_1 虽然是范围查询也支持。
使用不上的几种情况:
where fd_1 = 1 order by fd_2 desc, fd_3使用的两种排序方式,与索引列的正序排序不同。where fd_1 = 1 order by fd_2,fd_9排序引用了一个不再索引中的列where fd_1 = 1 order by fd_3无法形成最左前缀where fd_1 > 2 order by fd_2,fd_3 fd_1第一列是范围查询,且不再 order by 第一列,无法组成最左前缀
如何判断是否达到索引排序:
explain 的 type 列显示:index
冗余和重复索引
对于B-tree 索引
idx_1(a,b) 后 再创建, idx_2(a) 就是冗余索引
一般建议在已有索引上添加字段,除非像是在 int 索引上添加 varchar 列这样的不推荐。(会使原来的索引变的巨大)
未使用索引
为使用到的索引建议删除。
如何找出未使用的索引:
- 打开 userstates 服务器变量,运行一段时间后,查询 Information_schema.index_statustics 查看每个索引的使用频率。
查语句对索引的影响
or 改 union all
select fd_1,fd_2 from tab where fd_1 = 1 or fd_2 = 2;
-- 修改为 union 查询,使得用上索引
select fd_1,fd_2 from tab where fd_1 = 1
union all
select fd_1,fd_2 from tab where fd_1 <> 1 and fd_2 = 2;

若有收获,就点个赞吧
0 人点赞
