简介
-
广度优先搜索
解决哪些问题
节点A有到节点B的路径吗
-
实现方式
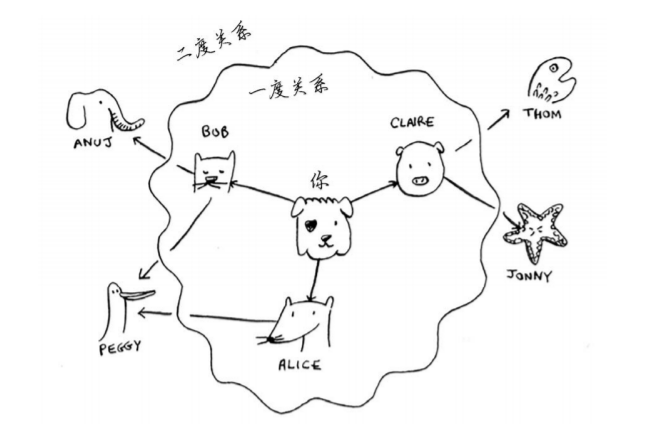
使用队列实现广度优先搜索。先检查和自己关系最近的,然后是朋友的朋友
算法实现
创建一个集合来存放所有检测的节点,防止下图的无限循环。创建一个队列,然后将开始节点入队,开始节点入集合。从队列中取出一个数据,判断是否是要找的。是就返回,不是就把它的没有被检测过的邻居入队…..直到找到或者没找到为止。
运行时间
如果你在你的整个人际关系网中搜索芒果销售商,就意味着你将沿每条边前行(记住,边是从一个人到另一个人的箭头或连接),因此运行时间至少为O(边数)。你还使用了一个队列,其中包含要检查的每个人。将一个人添加到队列需要的时间是固定的,即为O(1),因此对每个人都这样做需要的总时间为O(人数)。所以,广度优先搜索的运行时间为O(人数 + 边数),这通常写作O(V + E),其中V为顶点(vertice)数,E为边数。
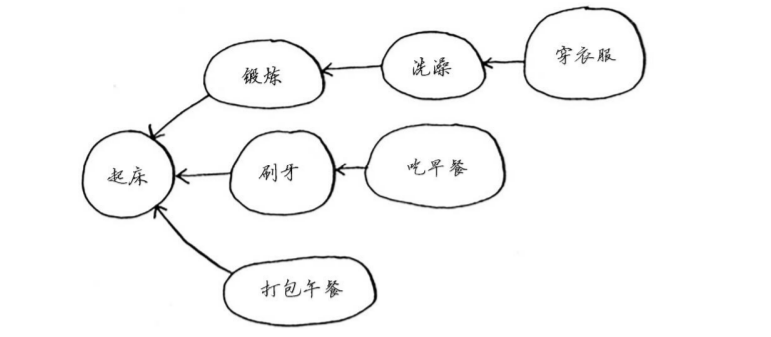
拓扑排序
- A任务必须发生在B之前。如下图的刷牙在吃早餐之前
狄克斯特拉算法
算法思想
- 找出最便宜的节点(相邻节点之间权重最小)
- 对于这个最便宜节点的邻居,检查是否有前往他邻居节点的最短路径,如果有,就更新他们的开销(最短路径)。并将计算过邻居节点的去除(判定为此节点已经找到了起始点到他的最短路径)
- 重复1、2过程,直到对图中的每个节点都计算了它的邻居节点
- 计算最终路径
算法特点
- 不能计算负权边。因为此算法认为找过邻居节点的节点,没有前往此节点的最短路径了。
- 是计算起始节点到其它节点最短路径的算法
- 计算加权图中最短路径
- 贝尔曼 福德算法 用于计算负权边

若有收获,就点个赞吧
0 人点赞
