数据的理解成本和决策价值会经历结果可见、趋势可见、过程可见,实际就是不断把真相显露水面的过程,越友好的数据展示方式,越低的决策成本越短的决策周期,这就是数据可视化的价值。
在小菜,可视化的命题不仅仅是把数据图表化,而是实现很多数据的批量图表化,或者说是业务数据可视化的量产,不是三五个而是几十个,如果我们用传统的服务端 API 来对接几十个大盘里面共几百个图表的特定格式数据,那么前后端基本上可以锁定好几个工程师长期 base 在上面了,任何图表展示维度或者格式发生改变,API 要随之而变,这对于一个崇尚效率的技术团队无异于一场灾难。
量产数据可视化的背景
下图是一个 Demo 阶段的大盘需求汇总,这还是非常粗颗粒度的目标,它们的每一个底下都有更精细化的业务大盘,以及伴随大盘的年月周日这种时间线上的过程叠加,这是一个既有跳转深度也有丰富维度和数量的可视化产品。

我们再回到上一篇,温习下数据的几个阶段(阶段间并非线性先后顺序,往往是并行不断迭代),当几百张报表都可以批量生产后,从管理和决策的视角就要关注更多变化性的趋势而不仅仅是变动的数字,这个阶段也就是数据聚合和数据大盘趋势可视化的这两个阶段之和,前者关注结果后者关注过程。

上文的报表量产我们解决了,接下来就是可视化的量产,这两个刚好是底层和上层堆叠的关系,本文我们探讨下如何实现基于量产化后报表的可视化的量产。
再开始聊技术实现之前,先看下我们的一些可视化的编辑界面和一些展示形式,编辑过程通过在线切换 Tab 的 Excel 快速输出计算规则和公式,可以定制展示形式和展示顺序:
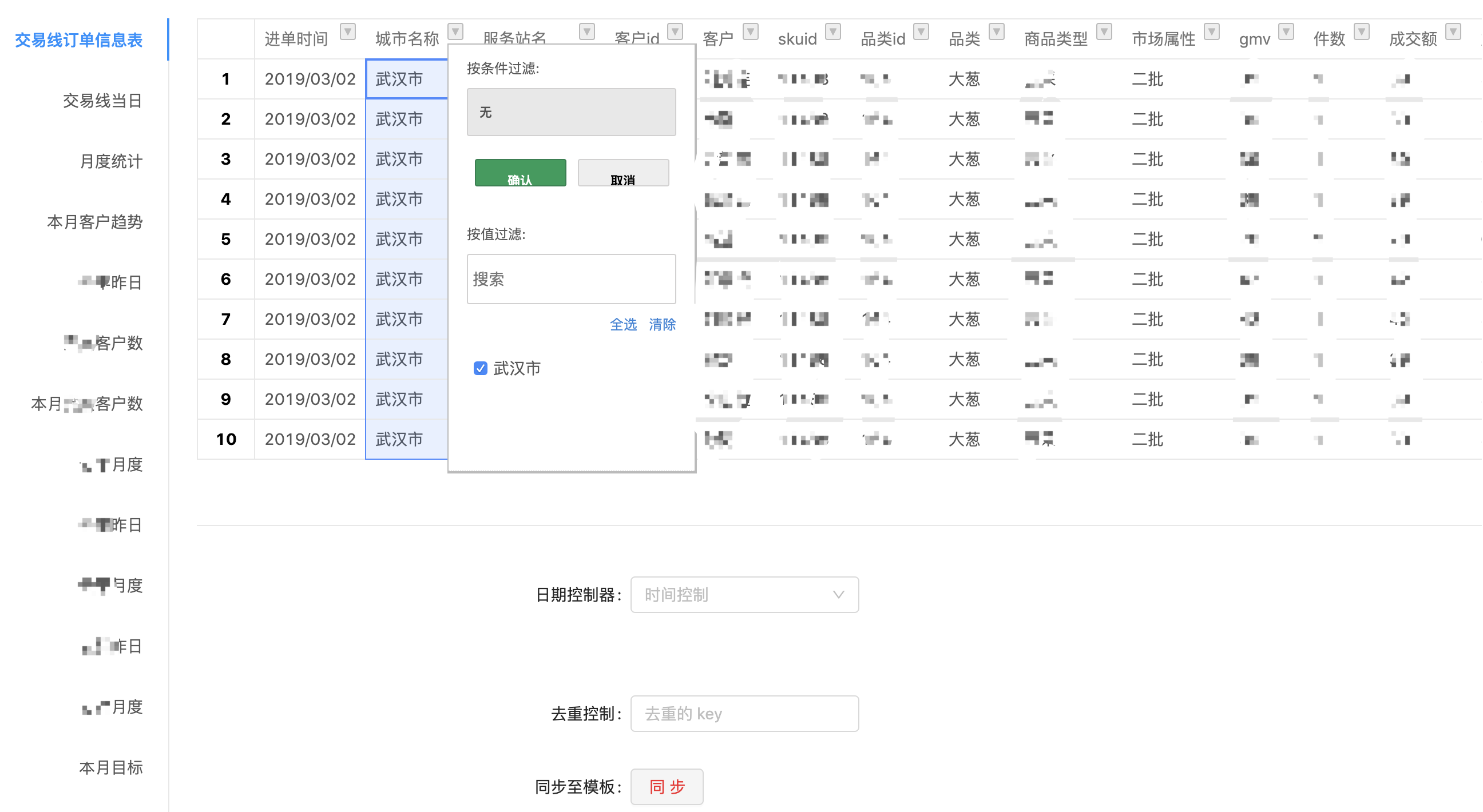
以及一些数据查询条件,包括 Excel 模板的导入等等:
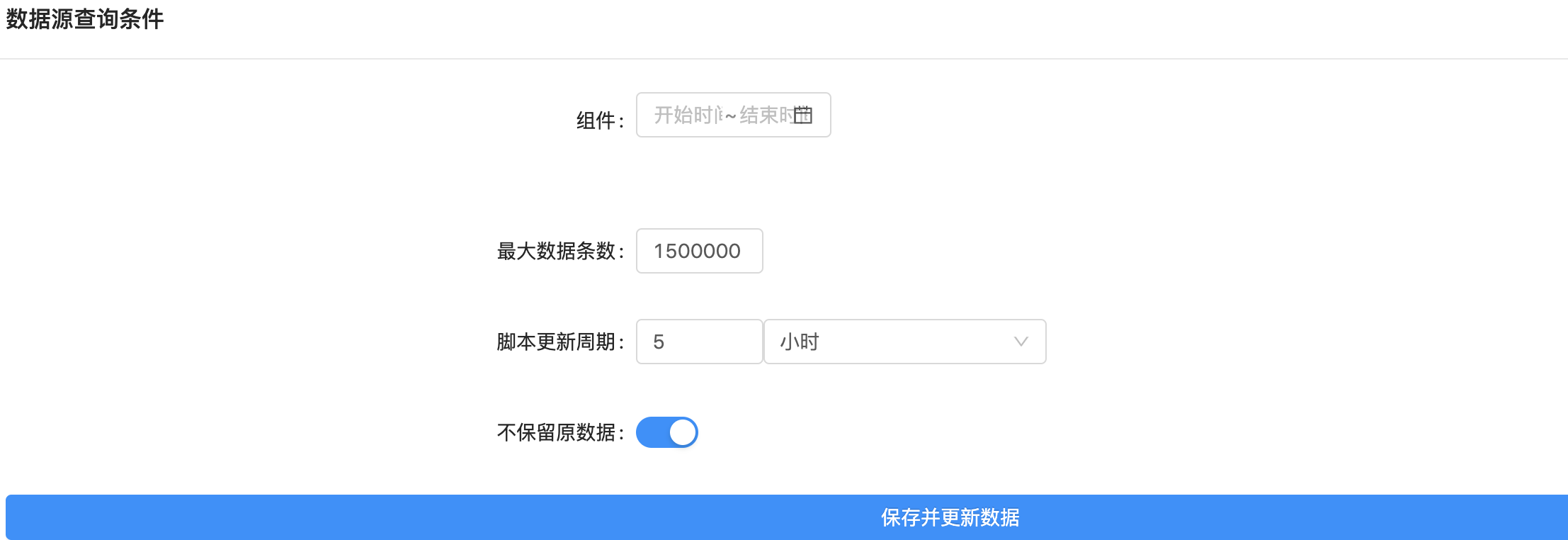
在这些界面上,结合 Excel 模板,就可以快速把一些数据格式化出来作展示,比如一些和完成指标挂钩(可以运营手动录入)完成进度按照一定维度聚合配置的卡片图:
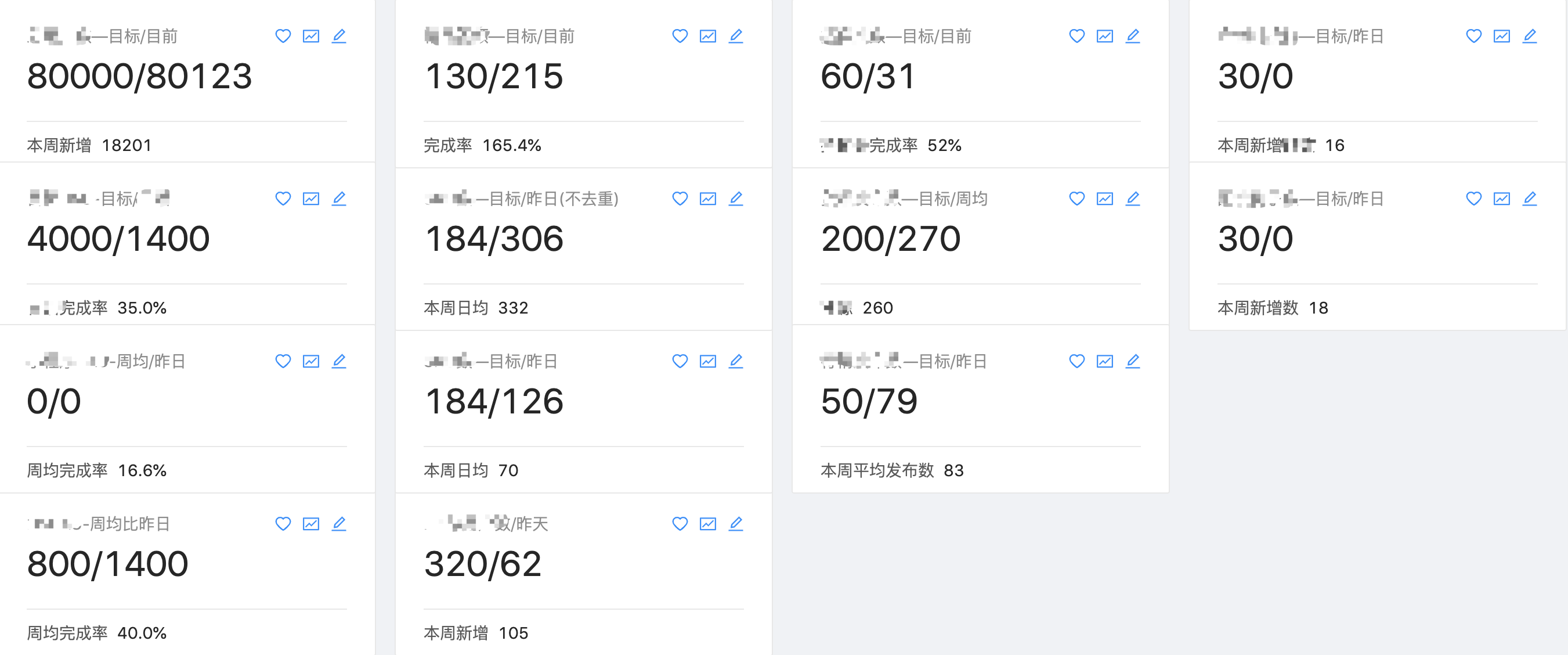
这些卡片就是结果可见,还有曲线图饼状图之类的趋势、过程和组成可见:
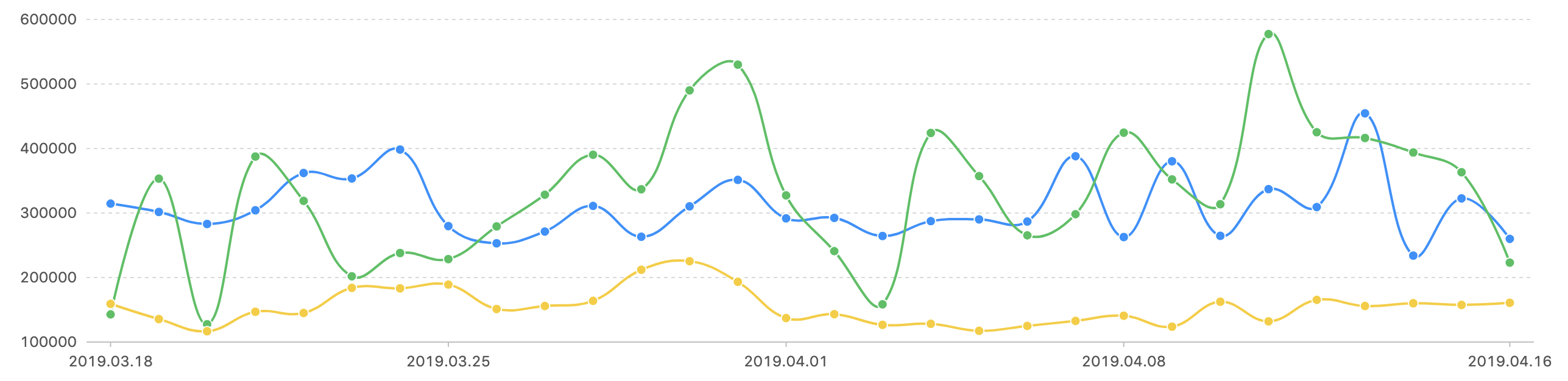
技术实现原理简介
我们已知,目前小菜的报表系统是用 Node + GraphQL + SQL 拼装出来的一个工具界面输出 SQL,SQL 到数据库再到 Table 的配置与渲染工具,而报表系统之上的可视化,目前是借助 Excel 完成数据统计与数据存储的一个实验性系统(未来不排除摒弃 Excel 文件),整个可视化依然是跑在整个报表项目中,除了 Node 处理业务逻辑外(提供给客户端 GraphQL 接口),服务端还涉及 C#(Excel 数据的重算)的使用、Python(数据的获取、过滤、分组等预处理工作),在客户端则是使用 Antd Design 的 Charts 组件与 Bizchart(未来可能会换成 D3)。
整个技术方案中,可视化的制作流程可以分为下面几步:
- 管理员制作 Excel 模版和配置脚本
- 定时任务执行脚本,更新缓存数据
- 前端获取数据用以图表展示
流程非常简单,从数据库到数据再到展示,他们背后的技术栈如下图,其中 grpc 则是在 Egg 与 Python 预处理任务之间的数据流通信: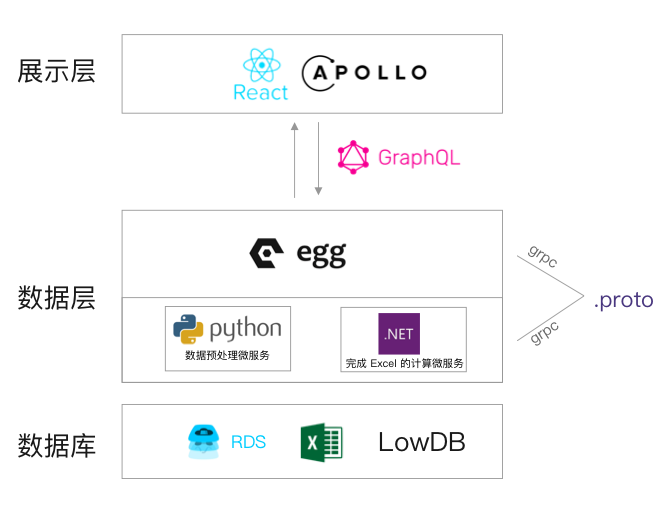
接下来我们把技术栈上的单点概念和实现原理来捋一下。
数据可视化实现过程
Excel 模版
这里主要说明一下为什么使用 Excel,以及遇到的一些问题,现在有一个场景,一个运营需要统计每日各个城市的 GMV,而目前有这么一张全国 GMV 的明细表,以及一张城市分组的表,那么这个运营只要做好一张 Excel 的统计模版(通过 Excel 公式统计各个城市的 GMV),每天这个运营都需要将新的 GMV 数据以及城市的数据复制在模版之中,那么 Excel 会自动计算新的统计数据。可视化系统最初的构思就是将这个过程脚本化。所以先使用 Excel 作为底层的数据处理的方式作为实验方式,先跑跑看。另外当初在设计这个系统的时候是希望这是一个通用的解决方案(这里的通用是指可以应用在之前做的一个量产表报表系统的任意一张或者多张报表上面,再解释一下就是之前做了一个报表系统可以生产很多报表,现在做一个系统可以让里面所有的报表都可以变成可视化报表)。
业务数据的定制
由于设计通用解决方案,让人头疼的自然就是很多报表的统计逻辑都有着自己的业务逻辑在里面。举例就是业务上有可能今天的目标值是1000,明天可能要改成了800,这样经常变动的数据,又或者一些来源与第三方的统计数据且暂时没有进公司的系统之中但是统计时却又要用得到的。
像这样需要变动并且数据源不明确的数据我称为业务定制数据,为了减少开发量,这样的数据源的被划进 Excel 模版数据源里面,再通过提供一个 Web 版 Excel,让管理员(一般都是BI 或者运营)来随时更新数据到 Excel 模版之中。
数据量增大问题
显而易见,随着数据量的增大,Excel 文件也会越来越大,脚本的执行速度也会越来越慢,模版以 Excel 文件的形式物理保存在服务器上也不安全,容易会出现被删除等情况。
数据的预处理
主要使用 Python 中的 Pandas 以及 NumPy 来获取、处理数据,最后写入对应的 Excel 工作表之中。数据预处理目前只有数据分组以及数据过滤,以及一些特定图表需要的数据的计算(如和弦图),选用 Python 是考虑到更快实现,也就是前文技术栈落地的文章中我们秉承的观点 - 最小成本预研落地,这里用 python 开发成本更低(实际是把 python 当作 matlab 来用)。
数据分组
在这个可视化系统中,我们把报表的数据做了一个分类,分为了
- 索引(一般为日期)
- 分类数据(城市,品类等)
- 其他(把索引看做自变量的时候,这些一般看做因变量)
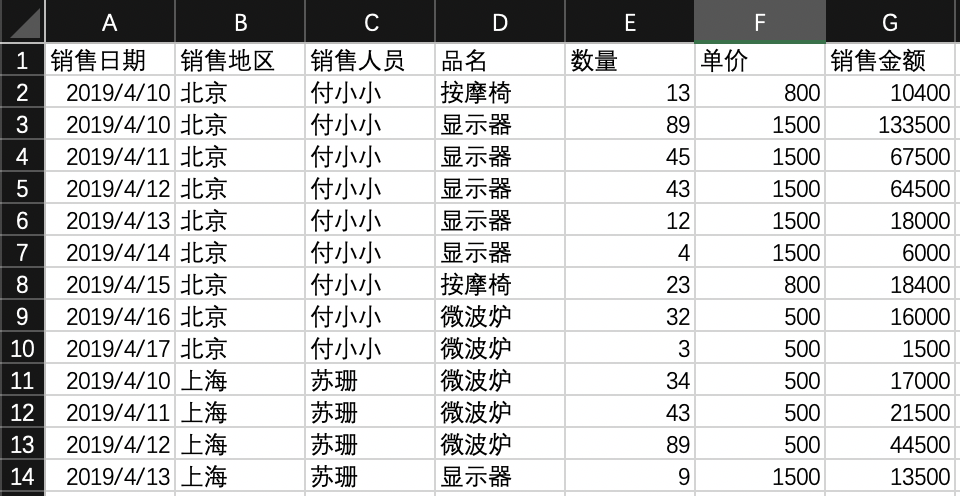
一般情况下,图上的销售日期为索引,销售地区、销售人员和品名为分类数据数量、单价和销售金额为因变量,较多的时候需要统计的都是因变量,每日的数量、单价、销售金额等。
所以当我们接到需求要看销售维度或销售城市维度销售金额的总额以及整体总额的时候,只需要在 Excel 中新建一张透视图就可以完成任务,然后再通过设置日期索引,拉取对应日期范围的数据写入 Excel,最后让这个 Excel 重算一下读取新的数据就可以了。
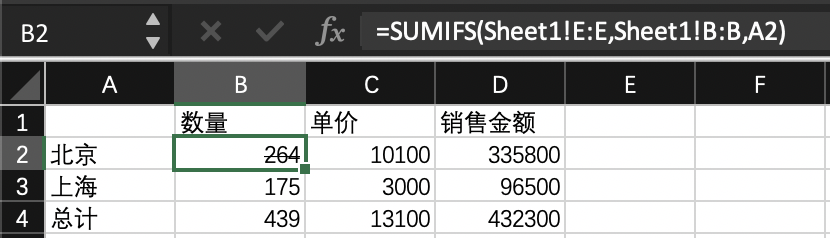
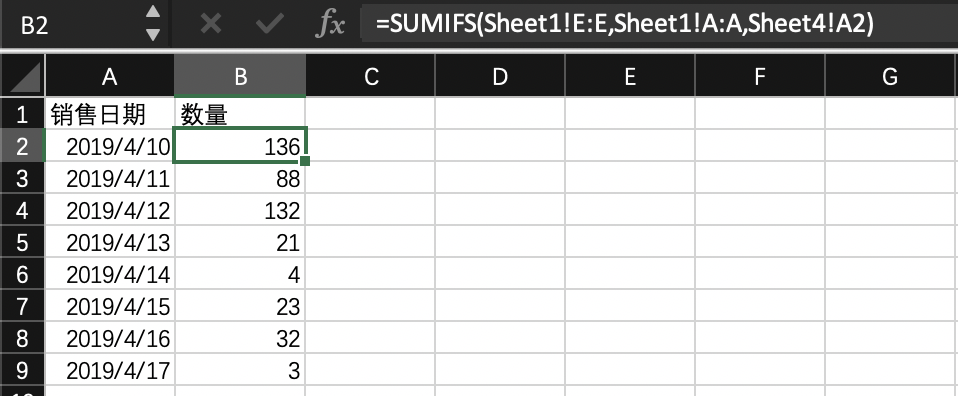
为了完成这个任务,我们需要
- Web 提供配置输入(索引列选择等)
- Python 拉去数据写入 Excel
- C# 重算 Excel,返回新的数据
Web 配置
由于我们一般都是拉取某个日期范围的数据,所以首要的需要配置的是数据源的索引列,再提供一个系统预设的日期选项可以抽象为这样
sysDateRange<近|本, N, DateUnit>DateRange<sysDateRange<近,1,月>>
表现出来这样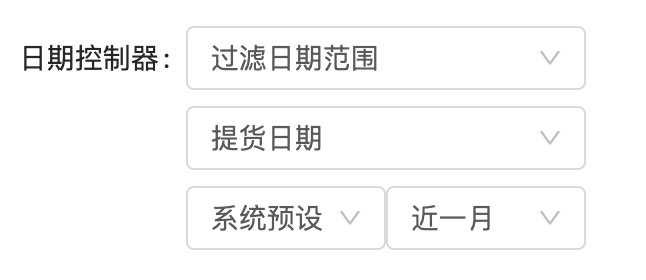
根据这个预设每次拉取对应的数据再写入对应的源表之中就可以了,如果需要复制的需求的时候,如需要对数据去重等 Excel 公式很难完成的任务时,就要提到 Pandas 了。Pandas 是 Python 上的一个开源的数据分析包,专门做各种数据分析与预处理。平常很难的算法,用 Pandas 几行就可以实现。这里列举几个常用的操作:
比如需要过滤出指定日期范围的数据的话,那么用 Pandas 一行就可以了:
(df['销售日期'] > start_date) & (df['销售日期'] <= end_date)
或者对上述表格需要对品类去重,统计品类数,可以这样做:
new_source = source.drop_duplicates(subset='品名')
假如是再复杂点对多个条件进行去重,比如需要每日的品类数,也是一行代码搞定:
new_source = source.drop_duplicates(subset=['品名', '销售日期'])
再回到 Web 端,只要提供对应的配置表单即可。如前面提到的日期过滤条件表单,并且把这样的配置应用到每个工作表之中去,就可以在一个工作簿里面写入各种不同维度的工作表明细了,这样整个数据预处理过程就搞定了。
重算 Excel
所谓的重算 Excel,就是读取预处理之后的 Excel,并且计算里面 Excel 公式,得到新的公式结果。这里我们主要是用 C# 里面的 EEPlus 来完成,可能大家会疑问,为什么需要用一个新的语言来做这件事?
Python 或者 Node 不行吗?这是因为我们的服务器系统是 linux 系统,假如是 Window Server 的话,Python 或者 Node 也确实可以找到可重算 Excel 的库,我们还尝试过 Java 的 POI,虽然可用,但是跑不了太大的数据,并且还很慢,所以就 ban 了,剩下的就只有 C# 了,毕竟都是微软自家的,支持程度比其他的好很多。
Nuget 上可以实现重算的库又很多,NPOI 、Microsoft.Office.Interop.Excel 、和 EPPlus 等。试用下来都有一些 Bug,如 NPOI 对 SUMIFS 公式的支持就不是很好。这三者的速度比较的话,我们小小测试了一下,结果是 NPOI > Microsoft.Office.Interop.Excel > EPPlus ,但是最后选的是 EEPlus,因为看中的就是他提供了自定义函数的这个 API,可以定制自己的 Excel 公式函数,如在 Excel 2019 实验的 Filter 函数,并且还能让我在发现其他函数的时候临时复写(不用 PR 到 git 上)。
再回到前面的重算,用 C# 也是只要一行就好:
package.Workbook.Calculate();
是不是非常的简单!完成接口的代码差不多也就这么几十行:
String[] arguments = GetCommandLineArgs();string filePath = args[0];string outputPath = args[1];FileInfo src = new FileInfo(filePath);FileInfo dest = new FileInfo(outputPath);if (dest.Exists){dest.Delete();}File.Copy(src.FullName, dest.FullName);ExcelPackage package = new ExcelPackage(new FileInfo(dest.FullName));if (package != null){package.Workbook.FormulaParserManager.AddOrReplaceFunction("sumifs", new MySumIfs());package.Workbook.Calculate();package.SaveAs(dest);}
重算之后把工作簿里面每张工作表里面的数据缓存为各个 LowDB 的 DB,Egg 通知每个 Worker 去缓存新的数据。
前端组件
Antd Pro 组件
Ant Design Pro 给我们提供很好的开箱即用的可视化模版组件,如图:
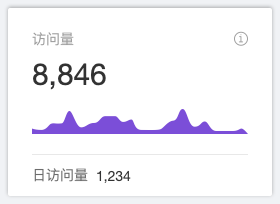
像这样的卡片组件,即可以一眼看到统计数据,又可以大致的看出数据的增长趋势,通用性很强。要做的只是提供一个对应的后台配置,去对应的 LowDB 缓存里面的对于的数据就行了。
复杂图表
为了很好的暂时页面的数据埋点数据以及 PV 流量的流向,需要用到和弦图,这种复杂的图表需要把明细数据集转化成一个 n * n 的二维数据表:
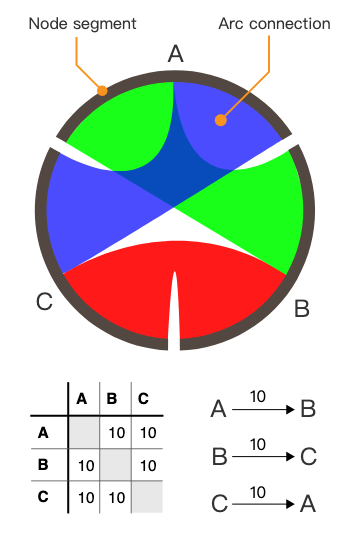
一开始我们尝试把这样的算法放到前端,后来随着数据量的增大,发现 JS 很难完成需求了(虽然可以分批计算,增量统计,不过实现起来繁琐一些),所以就把这样的图表定制算法切到 Python 服务那边去。
订阅服务
这个功能就是钉钉推送,主要是提供一个订阅功能,让用户可以订阅对应的统计卡片数据(图表在开发中),每天特定的时间通过钉钉,对该用户推送卡片数据,属于是爱心关怀的贴心功能,实现很简单,服务端使用的是 Egg,安装 egg-dingtalk 插件,按照文档配置:
exports.dingtalk = {corpid: '',corpsecret: '',host: '',enableContextLogger: '',};
再按照 node-dingtalk 调用就可以了:
message.send({ touser, toparty, msgtype, ... })
关于图表图片,我们目前的想法是借用 quickchart 来实现。
跨语言微服务
我们使用了 Python 和 C# 来提供微服务,那么 Egg 和这两个微服务之间的通信就是要解决的问题,这里选用的是 gRPC
gRPC 一开始由 google 开发,是一款语言中立、平台中立、开源的远程过程调用(RPC)系统。
gRPC 对比其他 RPC 系统最大的优势就是他是跨语言的,基本我们需要的它都覆盖了:
通过一个 .proto 文件,描述出每个服务的下可调用的 API 以及该 API 的入参类型以及响应数据类型,再根据每个语言不同的工具把这个 .proto,文件转化成对应语言所需的文件,这里用一个简单的 .proto 为例
syntax = "proto3";option java_multiple_files = true;option java_package = "io.grpc.examples.helloworld";option java_outer_classname = "HelloWorldProto";option objc_class_prefix = "HLW";package helloworld;// SayHello 方法的入参类型, 这里的意思就是入参数的字段名为 name, 类型为 string,这个字段的标识符为 1message HelloRequest {string name = 1;}// 和入参的逻辑一样message HelloReply {string message = 1;}// 服务描述,声明又一个类名为 greeter 的服务,该类提供 SayHello 与 SayHelloAgain 两个方法service Greeter {rpc SayHello (HelloRequest) returns (HelloReply) {}rpc SayHelloAgain(HelloRequest) returns (HelloReply) {}}
Egg 以及提供可 egg-grpc 插件,我们只要把对应的 proto 文件放如指定的文件夹之中就可以了。比较需要注意的是该插件的默认配置会把类名以及方法换成首字母小写:
const { ctx } = this;const client = ctx.grpc.helloworld.greeter;const result = await client.sayHello({ name: 'Gamelife' });
Python 需要使用命令行来生成对应的服务文件:
python -m grpc_tools.protoc -I../../protos --python_out=. --grpc_python_out=. ../../protos/helloworld.proto
C# 需要在工程描述文件 .csproj 里面加入 .proto 文件的路径:
<ItemGroup><Protobuf Include="../../../app/proto/helloworld.proto" Link="helloworld.proto" /></ItemGroup>
然后在代码中就可以直接作为 nameplace 来使用了:
using System;using System.Threading.Tasks;using Grpc.Core;using Helloworld;namespace GreeterServer{class GreeterImpl : Greeter.GreeterBase{public override Task<HelloReply> SayHello(HelloRequest request, ServerCallContext context){return Task.FromResult(new HelloReply { Message = "Hello " + request.Name });}}class Program{const int Port = 50052;public static void Main(string[] args){Server server = new Server{Services = { Greeter.BindService(new GreeterImpl()) },Ports = { new ServerPort("localhost", Port, ServerCredentials.Insecure) }};server.Start();Console.WriteLine("Greeter server listening on port " + Port);Console.WriteLine("Press any key to stop the server...");Console.ReadKey();server.ShutdownAsync().Wait();}}}
总结
结合上一姐报表量化的技术方案,我们可以把流程整理如下,首先是普通报表展示流程图:
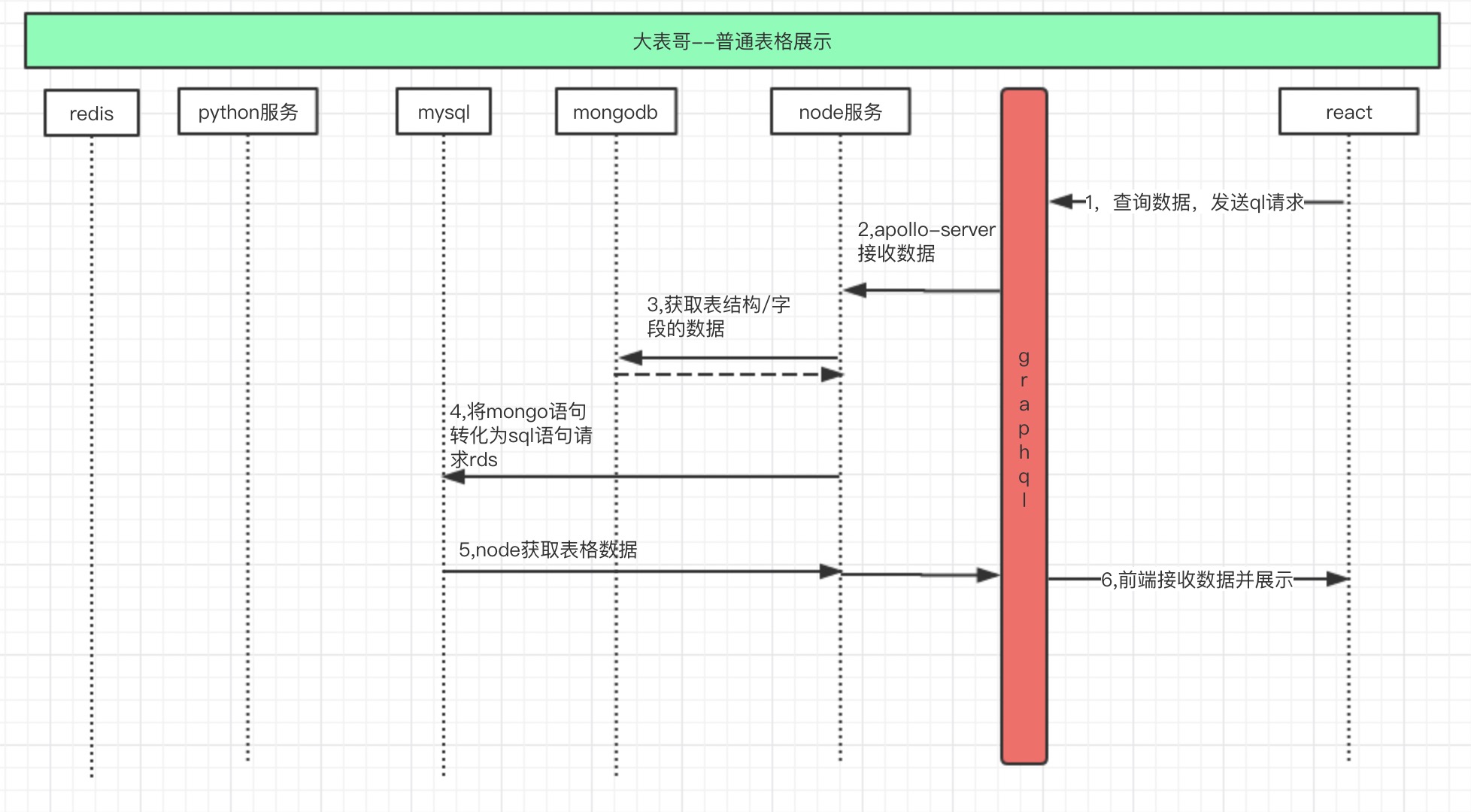
其次是可视化报表展示流程: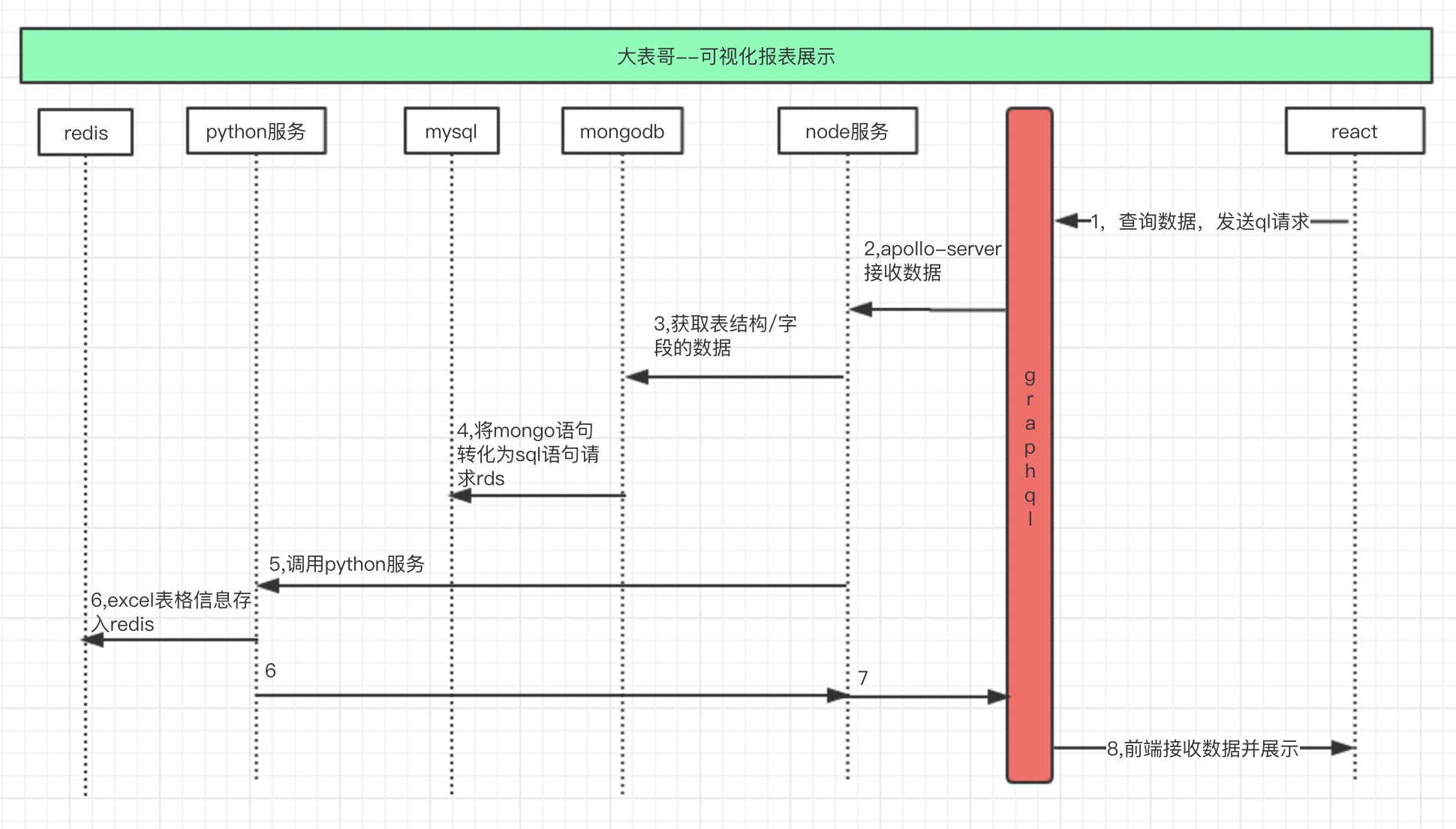
它的缺点很明显,node,python,c# 这几个服务都耦合在一块,python 在处理数据时候容易暂用大量内存,使整个服务挂掉,目前进一步用 gRpc 协议将不同的服务拆分开来, python 也部署到另外一台机器上,但仍需要一个更大的优化重构才能 handle 更多的应用场景和需求。
我们稍微总结下,目前实现的方案是在大表哥这个量产报表的系统上,再额外提供 Web 配置,利用 Pandas 来预处理数据, EEPlus 重算公式(解决定制需求),然后缓存数据展示到前端,整个底层实现后,只要会 Excel 计算公式的运营,就可以根据一些宽表来定制自己业务线的数据看板了,尤其是 BI 的同学,在我们的规划里,会让这里的制作成本越来越低,同时后期当预处理模块的功能逐渐完善之后,我们会希望替换掉 Excel 公式的作用,换一种更轻量级的方案来做。
送个稻谷,支持我写下去👇

若有收获,就点个赞吧
0 人点赞
