数据只有被看见,真相才有机会浮出水面。
对于任何一家公司,数据未必是充分条件,但一定是必要条件,如果连数据都看不到,做任何决策都只能基于经验算命,风险极高。
数据如此重要,但数据往往不容易被看到,更别提更及时的看到,现在也的确很多公司成立所谓大数据团队,在业务场景中没有找到有价值的发力点之前,很多大数据团队也会沦落为公司的报表取数器,这一方面反映出数据价值透出的紧迫性,也一方面看出公司为了快速获取数据而不惜动用大数据团队的窘迫局面。
而这个问题的本质特别简单:如何让数据库里的 dbs/tables 的成千上万个字段,快速的呈现在 HTML 的网页上?本文写于 2019 年初,介绍的是项目中前期的技术架构方式,希望能给大家一些启发。
数据价值逐步呈现的链路
但呈现只是一个小小的环节,在它的前后有更多可以做的事情,在我的视角里,数据从冰冷的库表到最终对公司有更大决策价值,可以分为这几个大的阶段:
- 收集阶段: 依赖各种业务场景的端载体和基建支撑来把数据回流汇总到线上数据库;
- 加工阶段: 把业务数据库/表同步到一个独立的数据仓库;
- 制作阶段: 从 SQL 到 HTML 展示报表的整个制作上线过程;
- 整理阶段: 基于公司的业务域和行业特征梳理更严谨的数据定义;
- 聚合阶段: 针对公司/事业部/部门/产品线来把数据结果聚合成看板和大盘反映业务健康;
- 趋势阶段: 在大盘基础上增加时间和更细化的业务观测维度来把周期内数据趋势呈现出来;
- 分析阶段: 从产品上线/技术优化/运营玩法/业务打法等节点上把关键事件集成到趋势中给出变化原因;
- 决策阶段: 更自动化智能化的依托于算法和规则来做业务预警/目标管理来直接驱动业务。

每一个阶段都更进一步,更深一层,一二三阶段是很多公司都做了的,是数据价值更大化的基础,没有一二三的基建准备,再往后会很艰难,我们今天要关注的是第三个阶段,也就是制作,这一道坎儿已经成为很多公司的痛点,而解决这个痛点就要深入到过程中分析。
传统数据报表的开发流程
在给出我们的解决方案之前,我们先看下传统方式让数据可见的两个步骤,这也是小菜早些年的做法:
所有数据从各个端/源流入数据库持久化成一张张表
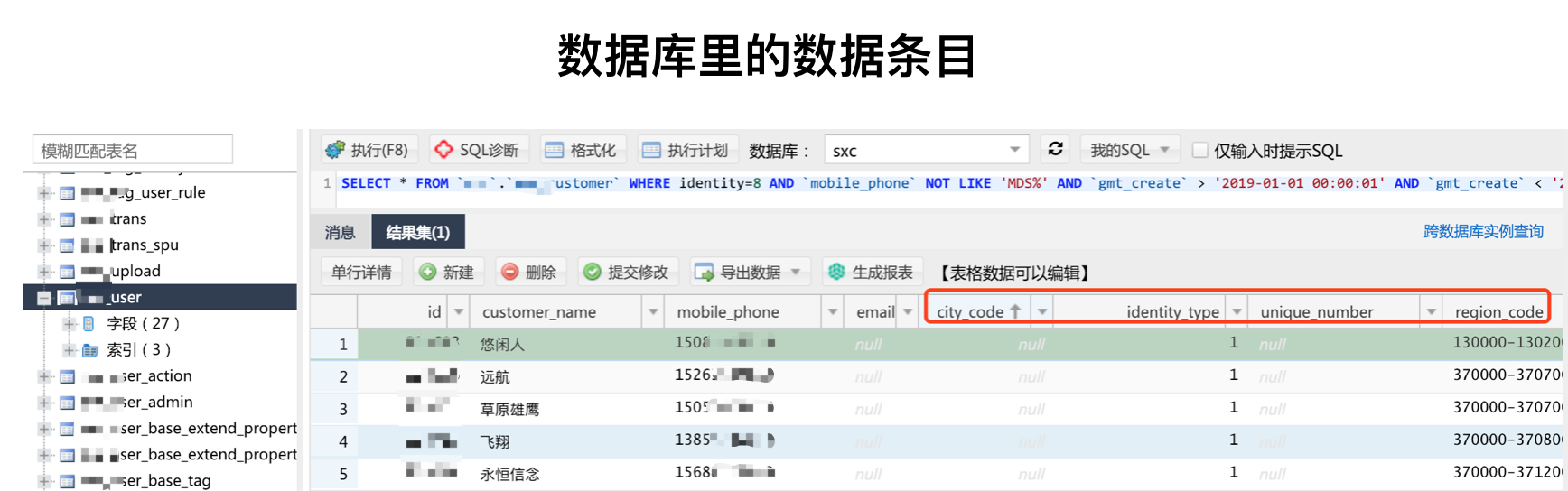
这时候我们往往可以从数据库的管理界面,或者命令行来用 SQL 命令筛选一些数据,也可以导出成 Excel 做一些数据分析,这是最原始的阶段,优点是一句 SQL 就能搞定一张报表,快速导出分析,缺点是必须懂 SQL 语法,还得理解所有字段的具体业务含义,同时本地要维护几十上百个 SQL 语句,来随时登上去执行,并且数据库和数据库表的权限管理会逐渐放开,最终变成运营和产品经理都上来人肉执行 SQL 的混乱局面。
后端的 API 与前端 HTML 结合
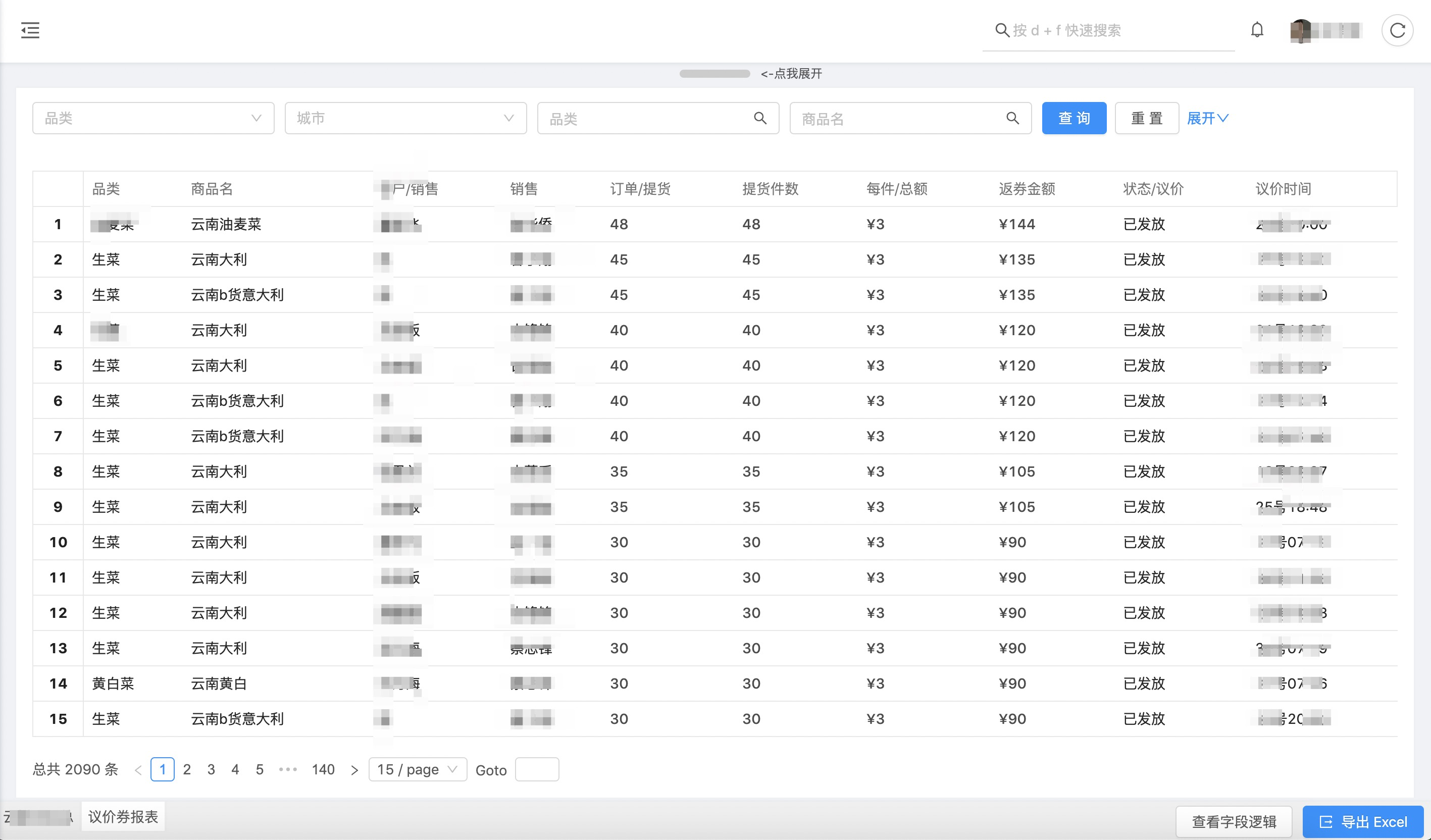
SQL 线上直接查太过于暴力,而且无非很好的维护,所以往往需要动用前端工程师和后端工程师,来共同实现一个报表,让销售/运营/产品经理等各个角色都可以打开网页看数据,既然是前后端合作,就必然存在接口约定,字段约定,筛选条件约定,翻页数量约定配置,各自开发,前端写静态页面、接口调用和占位符填充,后端工程里写 SQL,包装专门一个接口注册到网关上,前端后端联调测试后,最终各自发布上线。无论报表是简单还是复杂,几乎都要遵循这样的一个流程,最终展示这样的一个报表页面:
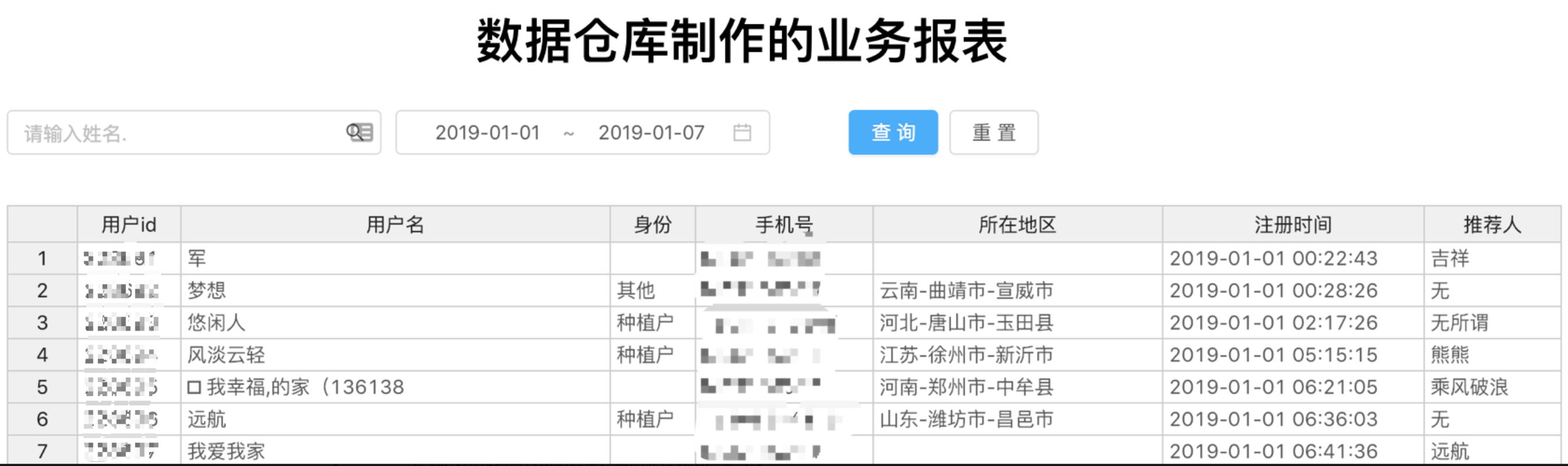
在这个基础之上,才有可能基于 Excel 或者接口数据做一些简单的可视化的过程展示,比如:
现实是,很多人对上面流程是无感的,取数据不就应该这样么,无论是一二十个页面的一二十个报表,还是三四百个页面的三四百个报表,自然不会有人对参与这个过程的工程师投以关注,而这样的一个 SQL 转接口的后端工程师和一个接口转 Table 的前端工程师的职业成长却会收到很大影响,一年要花好多时间来机械式的做数据报表,更要命的是,由于开发资源和工期的紧张,往往数据报表的优先级会低于业务需求,这意味着业务上线后还需要等一段时间的开发排期才能看到业务数据,这对于快速迭代的业务是非常致命的,无法敏捷的根据数据做及时调整,后知后觉。
要打破这样的一个魔咒,工程师可以有真正的成长,看数据的童鞋可以更快更舒服的看到数据,就必须从技术上找到突破点,拿到对所有人都友好的结果,就必须通过技术的升级来驱动业务,让决策更高效。
数据仓库是报表量产的必要基础
所有的数据都有它的决策时效性和整理周期,比如当我们看过往周维度的数据,这些数据可以是昨日之前甚至是本周之前的数据,如果我们想要看实时成交大盘,那么可能就要有小时表或者分钟表,能实时有数据获取,无论是实时数据还是非实时数据,我们都希望不要连接线上的生产数据库,而是一个更稳定又不那么敏感的数据库,这个角色往往是数据仓库。
要建设一个存储历史数据的数据仓库,唯一要做的事情,就是从生产数据库按照分钟,小时,天的规则往数据库搬砖,搬的时候也可以有一些简单的必要计算规则或者收敛规则,比如把一些用户表进行合并处理等等,而搬的动作,往往用 Python 脚本搬砖就行。
而对应到上图,就是第二个步骤,小菜经过几年的迭代,刚好也沉淀了一个可用的数据仓库,我们从这里开始出发。
数据报表的 SQL 拼接工具开发
既然 SQL 到 HTML 展示是痛点,需要多人参与,那么如果开发一款工具,通过它可以把 SQL 自动执行,然后自动渲染为 HTML 页面,痛点不就解决了么。
我们最初也是有这种思路,但后来发现,除展示,还有一个更大的痛点,那就是 SQL 里面大量的字段英文名,实际上它要对应到一个具体的业务中文名,而这个字段有可能是经过 SQL 的多个字段计算而来,它实际的中文名只存在于运营的脑海中,开发并不清楚,所以只是丢一个 SQL 不能解决问题,另外就是有很多字段的中文名其实是可以复用的,但每次都重新去找人问效率很低,最好是有一个中英文的字段名称池,每张报表都沉淀一些字段下来,下次再制作进去挑就好了。
所以我们让设计师设计了一个版本,长这样子:
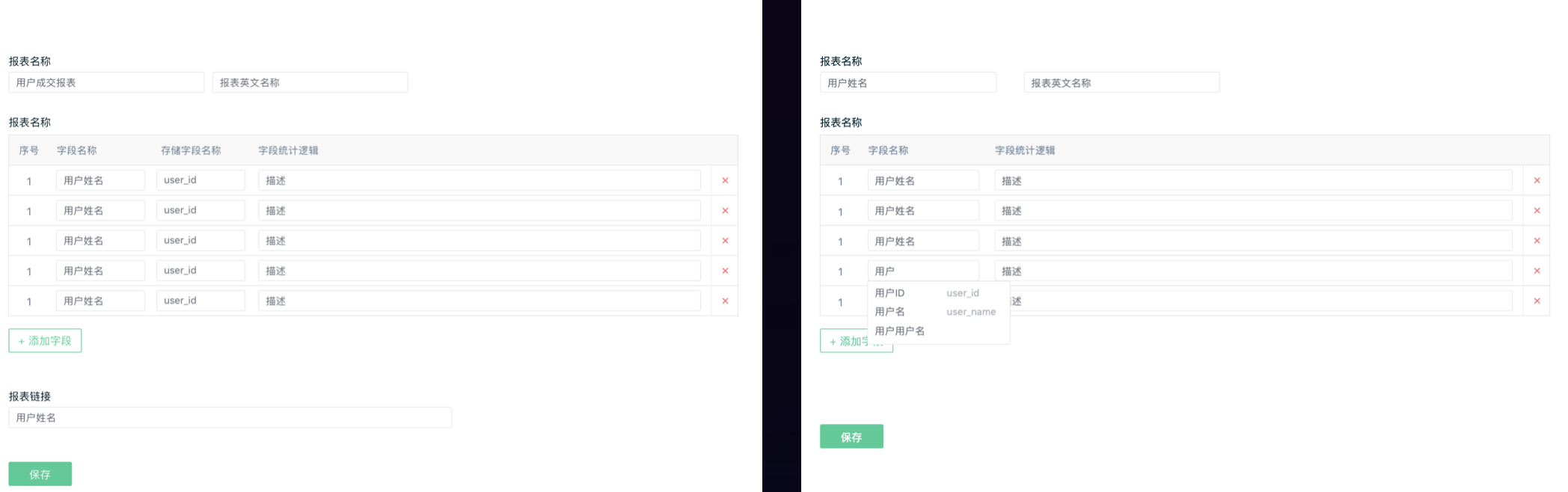
显然这完全是无法满足报表的制作和量产的,原因是设计师是很难很难理解 SQL 这样一个查询语言打散再组装在一个工具里面应该是怎样的流程,所以我们就完全摒弃了设计稿,完全由前端工程师来驱动,边学习 SQL 边开发持续迭代。
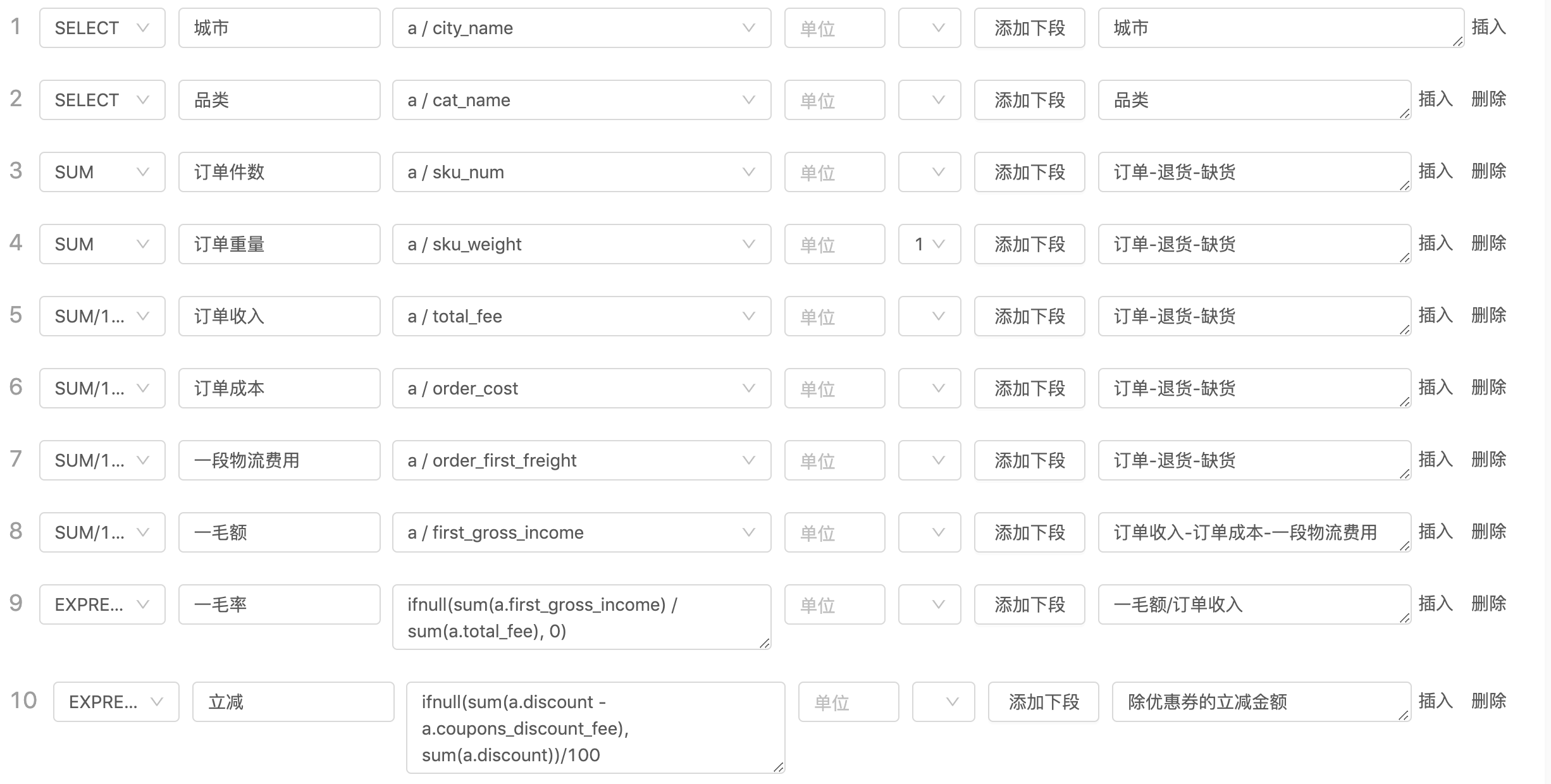
具体实现的时候,我们把思路倒换过来,在 SQL 执行之前,还应该有一个 SQL 拼接的过程,或者说制作 SQL 的过程,这个工具就是让后端工程师和懂 SQL 语法的产品经理,直接在工具的可视化界面中跨库跨表拼 SQL,同时把英文字段名和中文名称对应起来,然后执行制作后的 SQL 就可以了。
先看拼接后的 SQL 长的样子:
SELECTa.city_name as `城市`,a.cat_name as `品类`,sum( a.sku_num ) as `订单件数`,sum( a.sku_weight ) as `订单重量`,( sum(a.total_fee)/100 ) as `订单收入`,( sum(a.order_cost)/100 ) as `订单成本`,( sum(a.order_first_freight)/100 ) as `一段物流费用`,( sum(a.first_gross_income)/100 ) as `一毛额`,( ifnull(sum(a.first_gross_income) / sum(a.total_fee), 0) ) as `一毛率`,( ifnull(sum(a.discount - a.coupons_discount_fee), sum(a.discount))/100 ) as `立减`,( ifnull(sum(a.first_gross_income - a.discount + a.coupons_discount_fee),sum(a.first_gross_income - a.discount))/100 ) as `一毛净额`,( ifnull(sum(a.first_gross_income - a.discount + a.coupons_discount_fee) / sum(a.total_fee),sum(a.first_gross_income - a.discount) / sum(a.total_fee)) ) as `一毛净率`,( sum(a.coupons_discount_fee)/100 ) as `优惠券`,( sum(a.first_gross_income - a.discount)/100 ) as `二毛毛利额`,( ifnull(sum(a.first_gross_income - a.discount) / sum(a.total_fee), 0) ) as `二毛毛利率`,( sum(a.subsidy_fee)/100 ) as `红包消耗`,( sum(a.second_gross_income)/100 ) as `二毛额`,( ifnull(sum(a.second_gross_income) / sum(a.total_fee), 0) ) as `二毛率`,( sum(a.pickhouse_taking_wastage)/100 ) as `周转仓盘点报损额`,( sum(a.allhouse_taking_wastage)/100 ) as `综合仓损耗额`,( sum(a.indemnity_fee)/100 ) as `赔款额`,( sum(a.third_gross_income)/100 ) as `三毛额`,( ifnull(sum(a.third_gross_income) / sum(a.total_fee), 0) ) as `三毛率`,( sum(a.second_freight)/100 ) as `二段物流运费`,( sum(a.forth_gross_income)/100 ) as `四毛额`,( ifnull(sum(a.forth_gross_income) / sum(a.total_fee), 0) ) as `四毛率`FROM db1.tables1 aGROUP BY a.city_name, a.cat_nameLIMIT 50
而 SQL 的拼接重点是两个:
- 字段中文名的映射,无论是具体的字段还是公式计算后的值
- SQL 计算符和条件的支持,比如 sum/ifnul/Group By/OrderBy/HAVING 等等
字段名映射和计算符的支持,这个过程的编辑是在这样的界面上完成的:
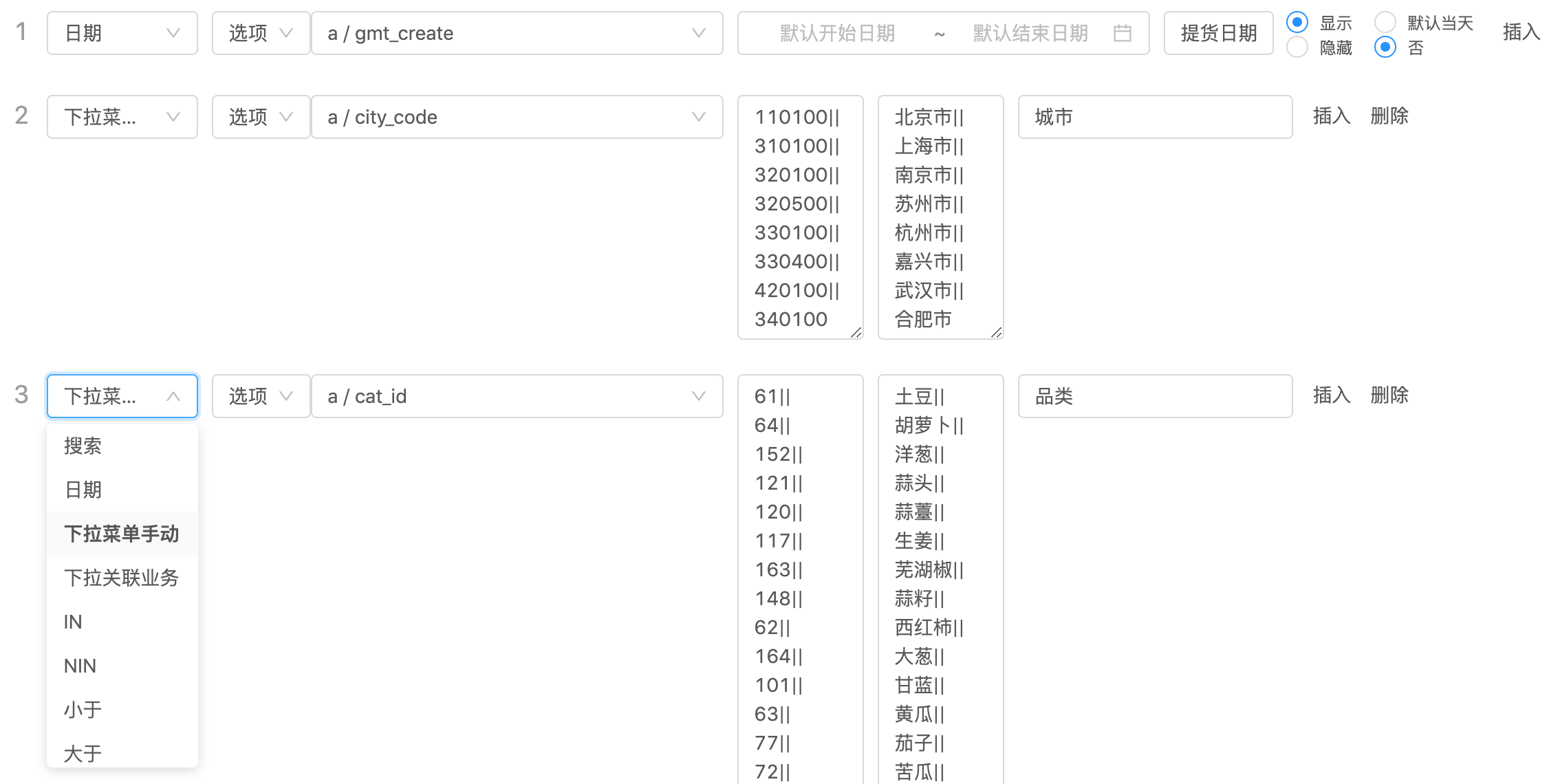
除此以外,还有各种查询条件的支持,比如小于等于大于等于等等:
有了 SQL 就等于有了数据获取能力了,就可以通过 NodeJS 去链接数据仓库查询到响应的数据了,接下来要解决的问题是如何展示。
数据报表在页面的自动展示
在解释页面展示之前需要先了解一下这个服务中 Graphql 的 Schema 里面和这个页面有关的 Type 结构关系:
user 挂在根请求下面,report 挂在 User Type 下面,表头和数据还有数据统计的都挂在 Report Type 下面,展示页的页面大致是长这样的
整个加载分为三部分
- user 请求加载地址菜单
- 报表页加载报表基本信息(表名,表头等)
- 报表页面加载数据(tbody 和 pagination)
第一步在刚进入任何页面时已经加载了,这里就不提了。下面这图主要概述进入一个报表页面的加载逻辑,与服务端的 Resolver 的执行顺序。
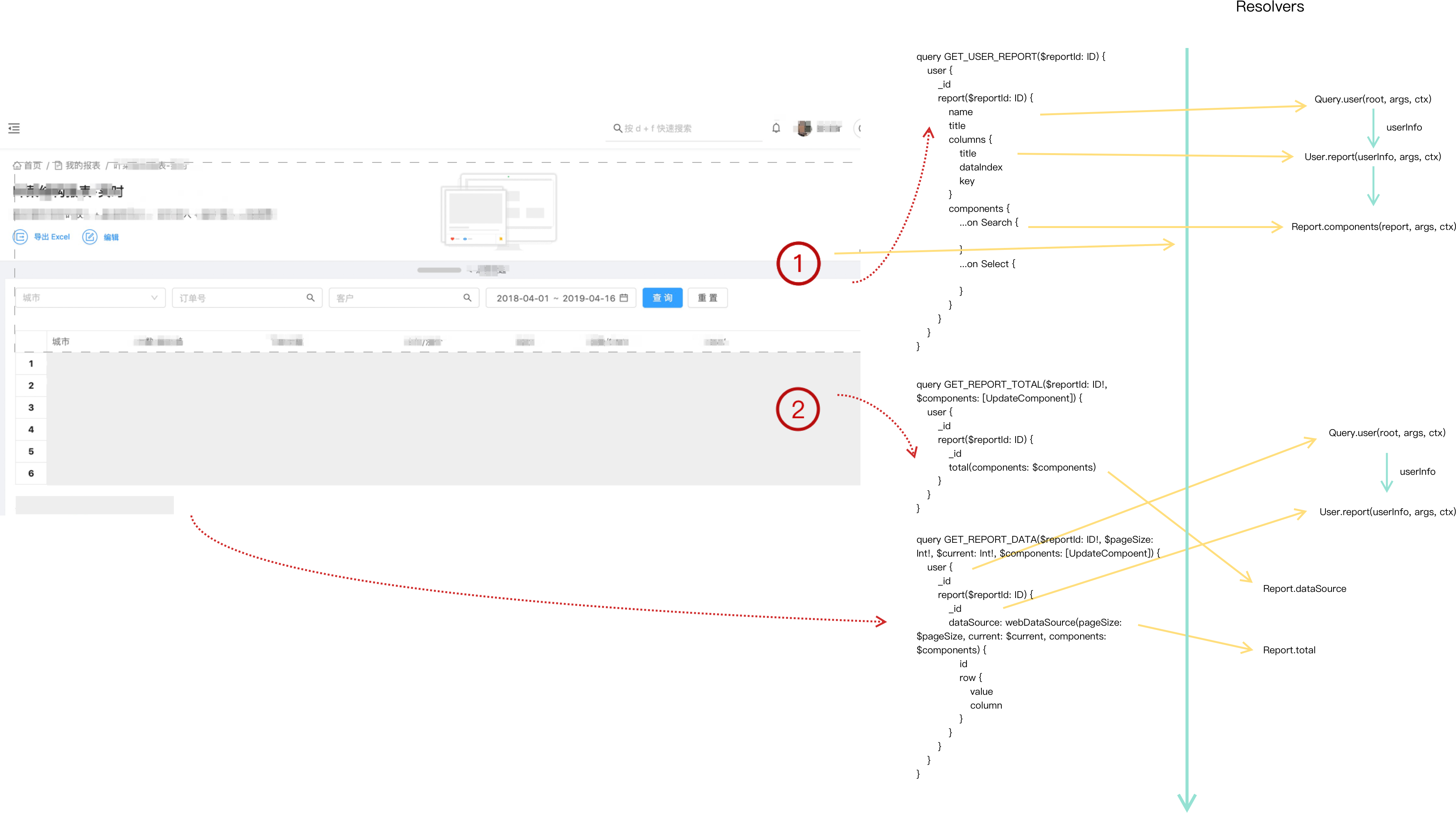
可能你会发现在请求页面 pagination 和 tbody 的时候依旧会经过 Query.user -> User.report 这两个 resolver,为什么不直接把 report 的 resolver 挂到 Query 下面呢?这么做的原因很简单,为了有效的控制权限,并且不需要写太多额外的代码。也就是说和用户权限相关的东西直接挂到 User 这个 Type 下面,那么下面的的 resolver 的 parent 就是 user,方便获取 user 权限的信息。
另外,我们希望报表可以适配到多端,这里我们也花费了大量的心力,封装了很多种比较复杂的移动端报表组件,比如下面几个图是数移动端的尝试
数据权限的处理
数据是一家公司最隐私的资产,那么作为一个数据产品,权限必然是一个需要建设的领域,我们目前的权限是这样的流程:
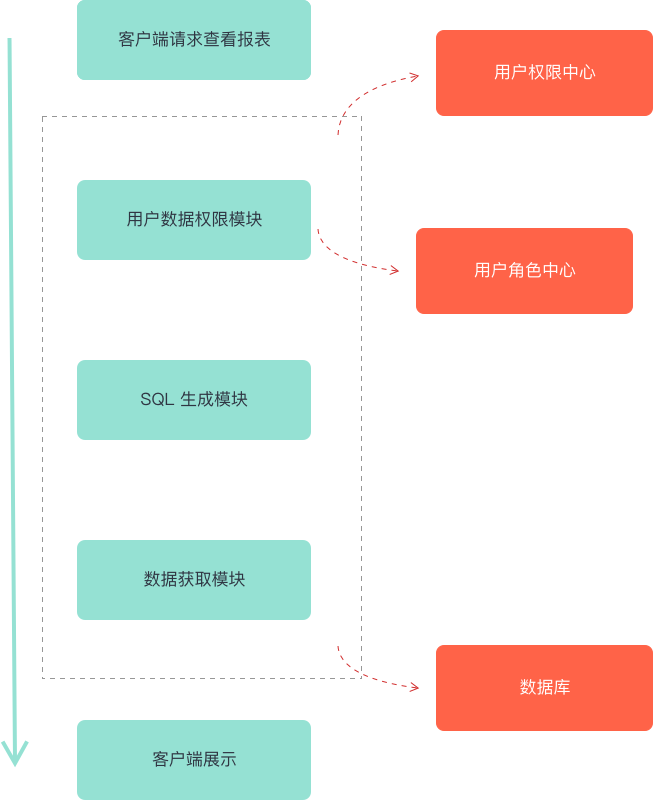
这里权限分为了两类,菜单权限以及数据权限。所谓的菜单权限就是最通俗的该账号是否有权限访问这个页面,而数据权限则是该账号访问这个页面之后可以查看的数据维度。举例就是现在有一张运营效果的全数据表,那么首先只有能看这张报表的运营账号才能查看,其次就是假如这个运营账号是北京的,那么他便不该看到上海的运营数据。
要实现这个,需要一个基本的用户权限中心,通过报表的 ID 以及账号 ID 校验该账号是否可以进入该页面,比较复杂就是用户数据维度的权限控制,但是实际实现只需要在最终的 SQL 中加入一条 WHERE 条件,通过结果反推,那么只要一个动态的 WHERE 条件生成模块,该模块需要关联用户或角色,利用传入的用户或角色信息,生成对应的条件(请求其他权限或者通过数据库查询或直接返回等)。
如上述的运营例子,那么先通过 userId,查询该用户 ID 下的运营账号管理的城市 ID,返回生成一条类似
a.cityCode in (3,2,1)
这样的 SQL,替换或插入到最终查询的 SQL 之中去就可以了。
量产后的报表价值
在我们实现这个报表系统后,短短一年多,几百张报表迅猛上线,成为了整个公司非常核心的一个产品
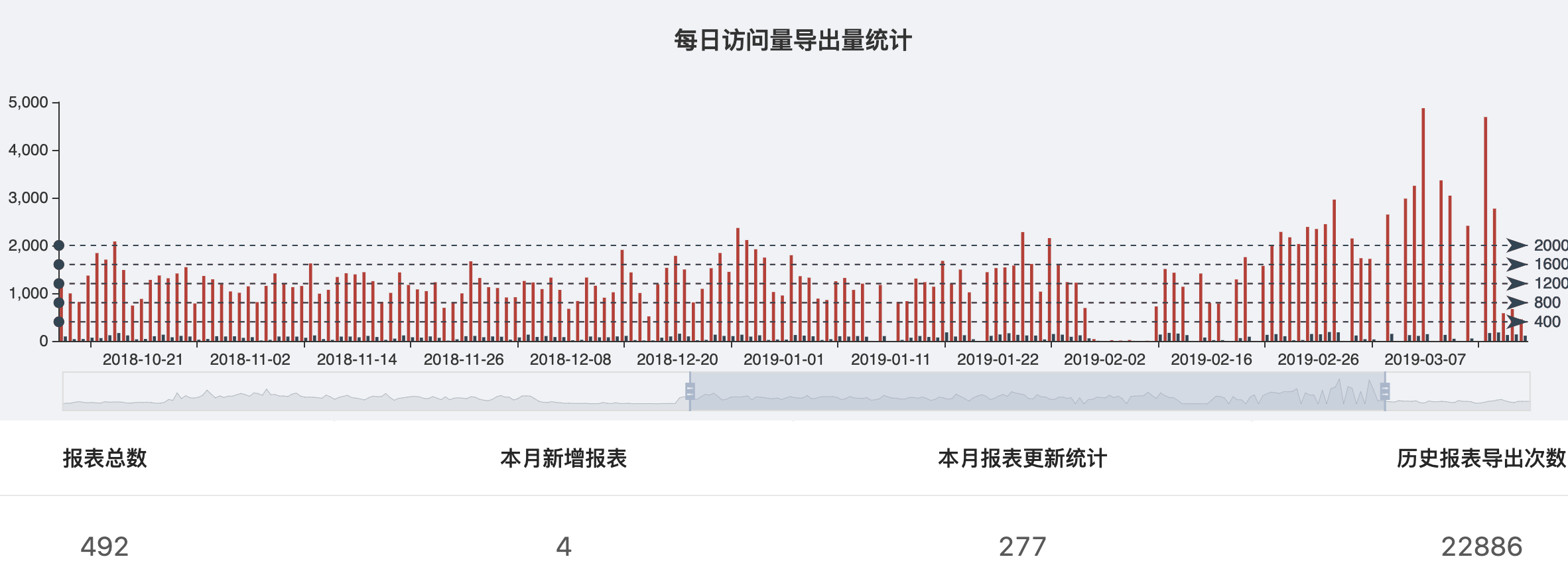
同时我们也遇到了一些报表查询相关的一些性能瓶颈和挑战,关于这一块我们后面会推出一篇文章来详谈,先看下一个一些比较慢的查询监控:
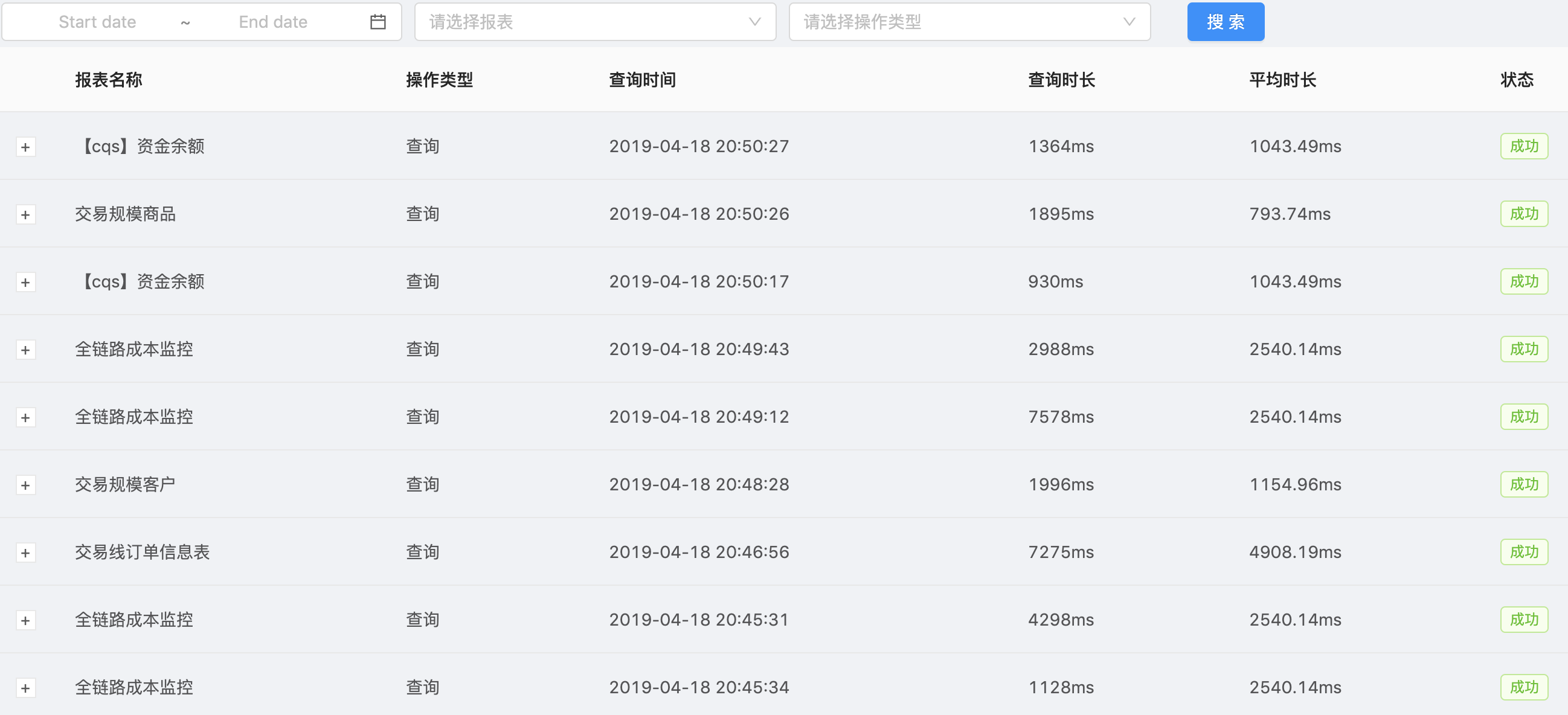
如果查询这么慢到了好几秒甚至十几秒的时候,我们想要在上面做进一步的可视化展示,就会遇到更大的技术挑战,这个挑战我们下一篇来谈谈如何对数据做计算方案的技术选型。
总结
这一篇我们花费了大量笔墨讨论了数据报表工程化和规模化量产的必要性,是为了向大家展示一种纯技术驱动的理念,就是没有什么繁重的开发模式是天经地义的,一定有可以突破它量产它的办法,只不过需要在技术实现和产品路子上打开想象力,那么通过这样的建设,我们也拿到了非常漂亮的业务结果,也在技术上找到了很大的成就感。
送个稻谷,支持我写下去👇

若有收获,就点个赞吧
0 人点赞
