第四章 解释模型
实现可解释性的最简单方法是只使用创建可解释模型算法的子集。线性回归、逻辑斯蒂回归和决策树是常用的可解释模型。
在下面的章节中,我们将讨论这些模型。但是不详细展开,只描述基础知识,因为已经有大量的书、视频、教程、论文和其他可用的材料。我们将关注如何解释模型。这本书更加详细地讨论了线性回归,逻辑斯蒂回归,以及其他线性回归的拓展,决策树,决策规则以及ReluFit算法。它同时也列举了其他的一些可解释模型。
除 k-最近邻法外,本书中所有的可解释模型在模块水平上都是可以被解释的。下表概述了可解释的模型类型及其属性。如果特征和目标之间的关联是线性的,那么模型就是线性的。具有单调性约束的模型确保每个特征和目标结果之间的关系在整个特征范围内始终朝着相同的方向前进:特征值的增加要么总是导致目标结果的增加,要么总是导致目标结果的减少。单调性对于模型的解释是有用的,因为它使理解关系变得更容易。一些模型能够自动地包括特征值之间的交互,以达到预测目标结果的目的。通过自己手动地创造交互特征,可以将交互包括在任何类型的模型中。虽然交互可以提高预测性能,但是太多或太复杂的交互可能会损害模型的可解释性。有些模型只处理回归,有些只处理分类,还有一些模型两者都处理。
从这个表中,您可以为您的任务选择一个合适的可解释模型,回归(regr)或分类(class):
| 算法 | 线性 | 单调性 | 交互性 | 任务 |
|---|---|---|---|---|
| 线性回归 | 是 | 是 | 否 | 回归 |
| 逻辑斯蒂回归 | 否 | 是 | 否 | 分类 |
| 决策树 | 否 | 一些是 | 是 | 分类,回归 |
| 规则拟合 | 是 | 否 | 是 | 分类,回归 |
| 朴素贝叶斯 | 否 | 是 | 否 | 分类 |
| K近邻 | 否 | 否 | 否 | 分类,回归 |
4.1 线性回归
线性回归模型将目标预测为特征输入的加权和。所学关系的线性使解释变得容易。长期以来,统计学家、计算机科学家和其他解决定量问题的人都使用线性回归模型。
线性模型可用于模拟回归目标 y 对某些特征 x 的依赖性。所学关系是线性的,可以针对单个实例 i 编写如下:
$$ [Y=β_0+β_1 x1+…+β_px_p+\epsilon] $$ 实例的预测结果是其 p 个特征的加权和。betas(βj)表示学习的特征权重或系数。总和中的第一个权重(β0)称为截距,不与特征相乘。epsilon(ϵ)是我们仍然会产生的误差,即预测与实际结果之间的差异。假设这些误差服从高斯分布,这意味着我们在正、负方向上都会产生误差,并且会产生许多小的误差和很少的大的误差。
可以使用很多方法来估计最佳权重。通常使用普通最小二乘法来找到最小化实际结果和估计结果之间平方差的权重:
$$ \hat{\boldsymbol{\beta}}=\arg!\min{\beta_0,\ldots,\beta_p}\sum{i=1}^n\left(y^{(i)}-\left(\beta0+\sum{j=1}^p\betajx^{(i)}{j}\right)\right)^{2} $$ 我们不会详细讨论如何找到最佳权重,但如果您感兴趣,可以阅读《统计学习要素》(Friedman、Hastie 和 Tibshirani 2009)一书的第 3.2 章或线性回归模型上的其他在线资源。
线性回归模型的最大优点是其线性:它使估计过程简单,最重要的是,这些线性方程在模块化水平(即权重)上具有易于理解的解释。这是线性模型和所有类似模型在医学、社会学、心理学等许多定量研究领域如此广泛的主要原因之一。例如,在医学领域,不仅要预测患者的临床结果,而且要量化药物的影响,同时以可解释的方式考虑性别、年龄和其他特征。
估计的权重带有置信区间。置信区间是权重估计的一个范围,它以一定的置信度覆盖“真实”权重。例如,权重为 2 的 95%置信区间可能在 1 到 3 之间。这个区间的解释是:在线性回归模型是正确的数据模型的情况下,如果我们用新的抽样数据重复估计 100 次,置信区间将包括 100 个案例中 95 个的真实权重。
模型是否为“正确”模型取决于数据中的关系是否满足某些假设,即线性、正态性、同方差性、独立性、固定特征和不存在多重共线性。
线性度
线性回归模型迫使预测成为特征的线性组合,这是其最强大的地方,同时也是最大的限制。线性使模型可解释。线性效应易于量化和描述。它们是添加剂,因此很容易分离效果。如果怀疑特征交互或特征与目标值的非线性关联,可以添加交互项或使用回归样条线。
正态性
假设给定特征的目标结果服从正态分布。如果违反此假设,则特征权重的估计置信区间无效。
同方差(常方差)
假设误差项的方差在整个特征空间内是恒定的。假设你想根据居住面积(平方米)来预测房子的价值。您估计一个线性模型,不管房子大小,预测响应周围的误差具有相同的方差。这种假设在现实中经常被违背。在房屋实例中,对于较大的房屋,预测价格周围的误差项方差可能更高,因为价格更高,价格波动的空间也更大。假设在您的线性回归模型中,平均误差(预测价格和实际价格之间的差异)为 50000 欧元。如果假设同方差,则假设50000的平均误差,对于成本为 100 万的房屋和成本仅为 40000 的房屋是相同的。这是不合理的,因为这意味着我们可以预期负房价。
独立性
假设每个实例独立于任何其他实例。如果您执行重复测量,例如每个患者进行多次血液测试,则数据点不是独立的。对于依赖数据,您需要特殊的线性回归模型,如混合效应模型或 GEE。如果使用“正态”线性回归模型,可能会从模型中得出错误的结论。
固定特征
输入特征被认为是“固定的”。固定意味着它们被视为“给定常数”,而不是统计变量。这意味着它们没有测量误差。这是一个相当不切实际的假设。然而,如果没有这个假设,您必须适应非常复杂的测量误差模型,这些模型解释了输入特征的测量误差。通常你不会想这样做。
不存在多重共线性
您不需要强相关的特征,因为这会扰乱对权重的估计。在两个特征强相关的情况下,由于特征效果是可加的,因此估计权重变得有问题,并且无法确定哪一个相关特征将影响归为属性。
4.1.1 解释
线性回归模型中权重的解释取决于相应特征的类型。
数值特征:增加一个单位的数值特征会改变其权重的估计结果。数字特征的一个例子是房屋的大小。
二进制特征:为每个实例获取两个可能值之一的特征。例如,“房子有花园”。其中一个值被视为引用类别(在某些用 0 编码的编程语言中),例如“没有花园”。将特征从引用类别更改为其他类别会根据特征的权重更改估计结果。
具有多个类别的分类特征:具有固定数量的可能值的特征。例如,“地板类型”特征,可能有“地毯”、“强化木地板”和“拼花地板”等类别。处理多个类别的解决方案是一个热编码,这意味着每个类别都有自己的二进制列。对于具有 L 类别的分类特征,您只需要 L-1 列,因为 L-th 列将具有冗余信息(例如,当一个实例的列 1 到 L-1 的值都为 0 时,我们知道此实例的分类特征具有 L 类别)。然后对每个类别的解释与对二进制特征的解释相同。有些语言,例如 R,允许您以各种方式对分类特征进行编码,在本章后面的章节我们会再进行描述。
- 截距(β0):截距是“常量特征”的特征权重,对于所有实例都是 1。大多数软件包会自动添加这个“1”特征来估计截获。解释是:所有数字特征值在0和分类特征值在参考类别中的实例,模型预测是截距权重。截距的解释通常不相关,因为所有特征值都为零的实例通常没有意义。只有当特征标准化(平均值为0,标准偏差为1)时,解释才有意义。然后,截距反映了一个实例的预测结果,其中所有特征都处于其平均值。
使用以下文本模板可以自动解释线性回归模型中的特征。
数字特征的解释
当所有其他特征值保持不变时,特征值(xk)增加一个单位,Y 的预测值增加一个单位。
分类特征的解释
当所有其他特征保持不变时,将特征(xk)从引用类别更改为其他类别会增加对 y 的预测(βk)。
解释线性模型的另一个重要度量是 R平方度量。R平方告诉你目标结果的总方差中有多少是由模型解释的。R平方越高,模型对数据的解释就越好。计算平方的公式为:
$$ R^2=1-SSE/SST $$ SSE 是误差项的平方和:
$$ SSE=\sum_i=1 ^n(y^(i)-\hat y(i))^2 $$ SST是数据方差的平方和:
$$ SST=\sum_{i=1}^n(y^{(i)}-\bar{y})^2 $$ SSE 告诉你在拟合线性模型后还有多少方差,这是通过预测值和实际目标值之间的平方差来测量的。SST 是目标结果的总方差。R平方告诉你有多少方差可以用线性模型来解释。对于模型根本不能解释数据的模型,R 平方的范围为 0;对于解释数据中所有方差的模型,R 平方的范围为 1。
有一个陷阱,R平方会随模型中的特征数量的增加而增加,即使它们根本不包含任何关于目标值的信息。因此,最好使用调整后的R平方,这就解释了模型中使用的特征数量。其计算如下:
$$ \bar{R}^2=1-(1-R^2)\frac{n-1}{n-p-1} $$ 其中 p 是特征的数量,n 是实例的数s量。
解释一个 R 平方很低(调整后)的模型是没有意义的,因为这样的模型基本上不能解释大部分的方差。对权重的任何解释都没有意义。
特征重要性
一个特征在线性回归模型中的重要性可以用它的 t 统计量的绝对值来衡量。t 统计量是以标准误差为尺度的估计权重。
$$ t_{\hat{\beta}_j}=\frac{\hat{\beta}_j}{SE(\hat{\beta}_j)} $$ 让我们检查一下这个公式告诉我们:特征的重要性随着权重的增加而增加。这是有道理的。估计权重的方差越大(=我们对正确值的确定度越低),特征就越不重要。这也是有道理的。
4.1.2 示例
在这个例子中,我们使用线性回归模型来预测给定天气和日历信息的特定日期。为了便于解释,我们检查了估计的回归权重。这些特征包括数值特征和分类特征。对于每个特征,该表显示估计的权重、估计的标准误差(SE)和 t 统计量的绝对值(|t|)。
| Weight | SE | \ | t\ | ||
|---|---|---|---|---|---|
| (截距) | 2399.4 | 238.3 | 10.1 | ||
| 夏季 | 899.3 | 122.3 | 7.4 | ||
| 秋季 | 138.2 | 161.7 | 0.9 | ||
| 节假日 | -686.1 | 203.2 | 3.4 | ||
| 工作日 | 124.9 | 73.3 | 1.7 | ||
| 天气状况雾天 | -379.4 | 87.6 | 4.3 | ||
| 天气状况雨/雪/风暴天 | -1901.5 | 223.6 | 8.5 | ||
| 温度 | 110.7 | 7.0 | 15.7 | ||
| 湿度 | -17.4 | 3.2 | 5.5 | ||
| 风速 | -42.5 | 6.9 | 6.2 | ||
| 自从2011年之后的日子 | 4.9 | 0.2 | 28.5 |
数值特征(温度)的解释:当所有其他特征保持不变时,温度升高 1 摄氏度,自行车的预测数量增加 110.7 辆。
分类特征(“天气状况”)的解释:与良好天气相比,当下雨、下雪或暴风雨时,自行车的估计数量减少了-1901.5——再次假设所有其他特征不变。当天气有雾时,由于所有其他特征保持不变,自行车的预测数量比好天气低-379.4。
所有的解释总是伴随着脚注,“所有其他特征保持不变”。这是因为线性回归模型的性质。预测目标是加权特征的线性组合。估计的线性方程是特征/目标空间中的超平面(单个特征的简单直线)。权重指定超平面在每个方向上的坡度(渐变)。好的一面是,可加性将单个特征效果的解释与所有其他特征隔离开来。这是可能的,因为方程式中的所有特征效果(=权重乘以特征值)都与加号组合在一起。在事物的坏的一面,解释忽略了特征的联合分布。增加一个特征,但不改变另一个特征,可能导致不现实或至少不太可能的数据点。例如,如果不增加房子的大小,增加房间的数量可能是不现实的。
4.1.3 目视解释
各种各样的可视化使线性回归模型容易和快速地为人类掌握。
4.1.3.1 重量图
权重表的信息(权重和方差估计)可以在权重图中可视化。下图显示了前一个线性回归模型的结果。
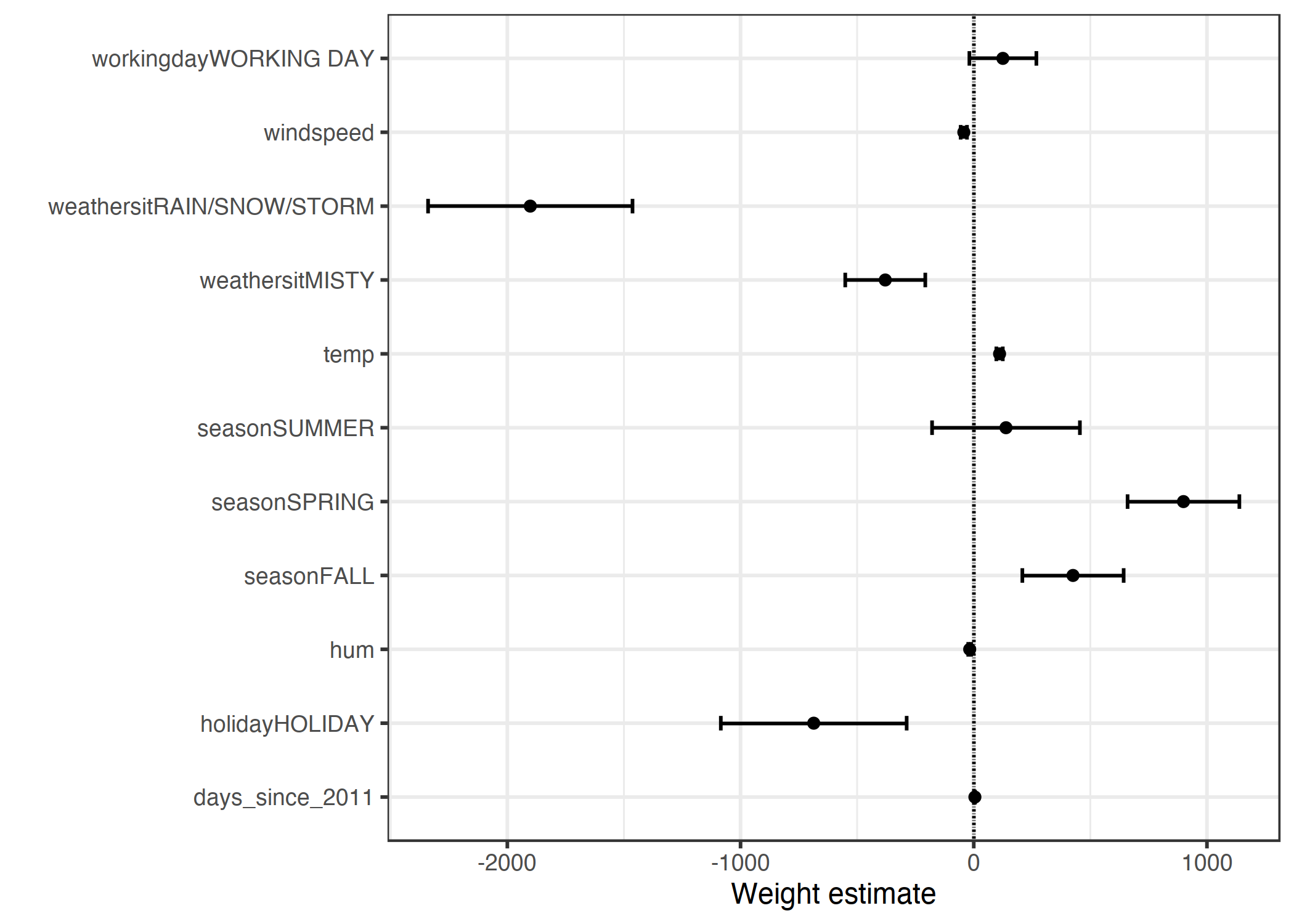
图 4.1:权重显示为点,95%置信区间显示为线。
权重图显示,下雨/下雪/暴风雨天气对预测的自行车数量有很大的负面影响。工作日特征的权重接近于零,95%的区间中包含零,这意味着该影响在统计上不显著。一些置信区间很短,估计值接近于零,但特征效应具有统计学意义。温度就是这样的一个候选者。权重图的问题在于特征是在不同的尺度上测量的。而对于天气来说,估计的重量反映了好天气和下雨/暴风雨/下雪天气之间的差异,因为温度只反映了 1 摄氏度的增加。在拟合线性模型之前,可以通过缩放特征(一个的零平均值和标准偏差),使估计的权重更具可比性。
4.1.3.2 效果图
当线性回归模型的权重与实际特征值相乘时,可以更有意义地进行分析。重量取决于特征的比例,如果你有一个测量人的身高的特征,并且你从米转换到厘米,那么重量会有所不同。权重会改变,但数据中的实际效果不会改变。了解您的特征在数据中的分布也是很重要的,因为如果您的方差非常小,这意味着几乎所有的实例都有类似的贡献。效果图可以帮助您了解权重和特征组合对数据预测的贡献程度。首先计算效果,即每个特征的权重乘以实例的特征值:
$$ \text{effect}{j}^{(i)}=w{j}x_{j}^{(i)} $$ 使用箱线图可以可视化效果。箱线图中的框包含一半数据的效果范围(25%到 75%的效果分位数)。框中的垂直线是中间值效应,即 50%的实例对预测的影响较小,另一半则较高。水平线延伸到\(\pm1.5\text iqr/\sqrt n \),iqr 是四分位数之间的范围(75%分位数减去 25%分位数)。这些点是离群值。与每个类别都有自己的行的权重图相比,分类特征效果可以总结为一个单独的箱线图。
图 4.2:特征效果图显示了每个特征数据的效果分布(=特征值乘以特征权重)。
对预期租用自行车数量的最大贡献来自于温度和天数特征,这反映了自行车租赁的趋势。温度在很大程度上有助于预测。日趋势特征从零变为大的正贡献,因为数据集中的第一天(2011 年 1 月 1 日)具有非常小的趋势效应,并且该特征的估计权重为正(4.93)。这意味着效果会随着每天的增加而增加,并且在数据集中的最后一天(2012 年 12 月 31 日)效果最高。请注意,对于负权重的效果,具有正效果的实例是具有负特征值的实例。例如,风速负效应大的天气就是风速大的天气。
4.1.4 解释个别预测
一个实例的每个特征对预测有多大贡献?这可以通过计算这个实例的效果来回答。对实例特定效果的解释仅与每个特征的效果分布相比较才有意义。我们要从自行车数据集中解释第 6 个实例的线性模型的预测。实例具有以下特征值。
| 特征 | 值 |
|---|---|
| 季节 | 春天 |
| 年 | 2011 年 |
| mnth 公司 | 1月 |
| 假日 | 没有假期 |
| 平常日 | 星期二 |
| 工作日 | 工作日 |
| 天气 | 很好 |
| 温度 | 1.604356 |
| 湿度 | 51.8261 |
| 风速 | 6.000868 年 |
| cnt | 1606 |
| 自从2011年之后的天数 | 5 |
为了获得这个实例的特征效果,我们必须将它的特征值乘以线性回归模型中相应的权重。对于“工作日”特征的值“工作日”,效果为 124.9。对于 1.6 摄氏度的温度,影响是 177.6。我们将这些单独的效果作为交叉点添加到效果图中,这显示了数据中效果的分布。这使我们能够将个体效应与数据中的效应分布进行比较。
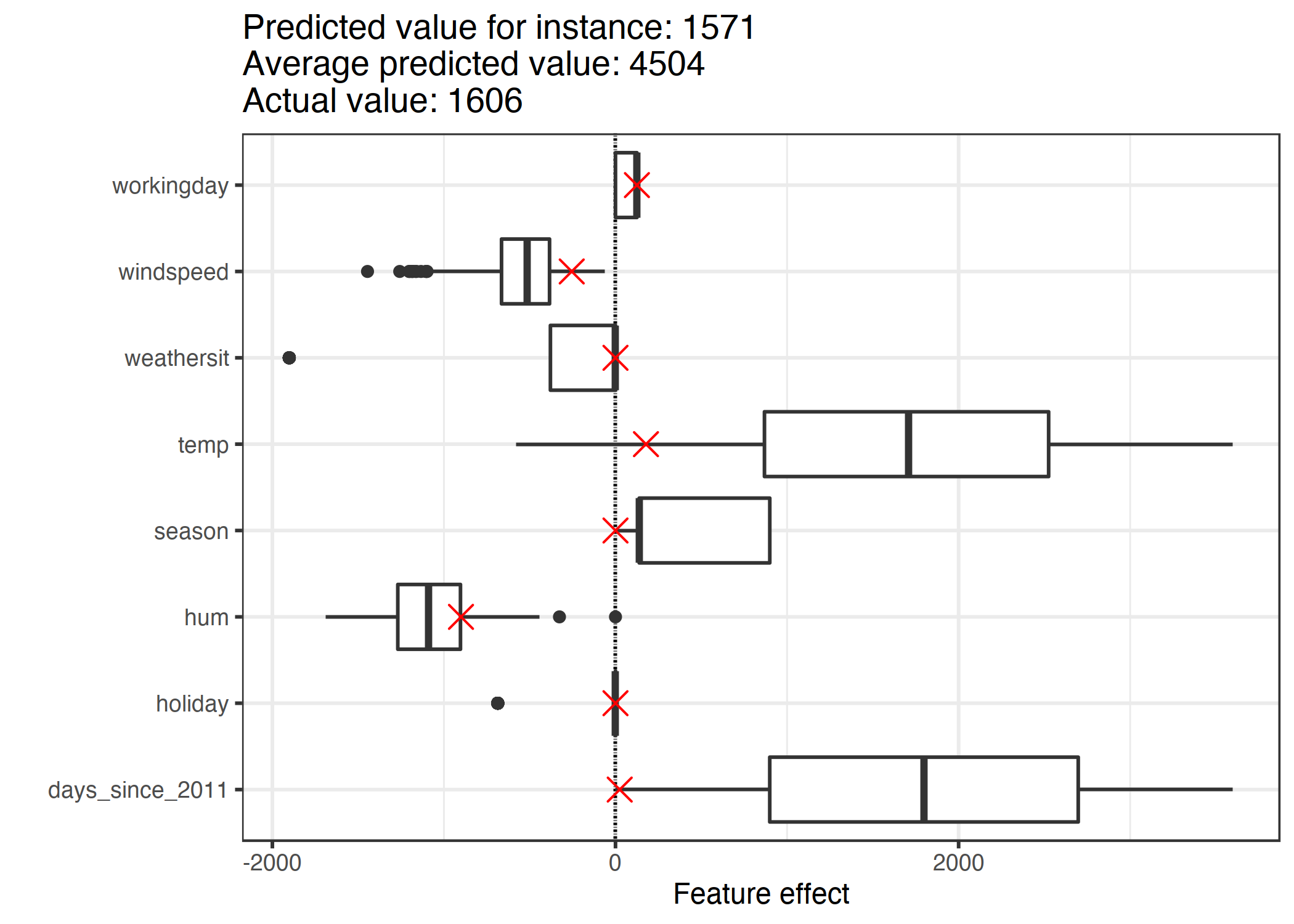
图 4.3:一个实例的效果图显示了效果分布,并突出了感兴趣实例的效果。
如果我们对训练数据实例的预测进行平均,我们得到的平均值是 4504。相比之下,第六个实例的预测很小,因为预测的自行车租金只有 1571 辆。效果图揭示了原因。箱线图显示数据集所有实例的效果分布,交叉显示第 6 个实例的效果。第 6 个实例具有低温效应,因为在这一天,温度为 2 度,与大多数其他日期相比较低(记住温度特征的权重为正)。此外,与其他数据实例相比,趋势特征“自 2011 年以来的天数”的影响较小,因为该实例来自 2011 年初(5 天),并且趋势特征也具有正权重。
4.1.5 分类特征编码
分类特征的编码有几种方法,选择影响权重的解释。
线性回归模型的标准是治疗编码,这在大多数情况下是足够的。使用不同的编码归根结底就是从具有分类特征的单个列创建不同的(设计)矩阵。本节介绍了三种不同的编码,但还有更多。使用的示例有六个实例和三个类别的分类特征。对于前两个实例,该特征采用类别 A;对于实例 3 和 4,采用类别 B;对于后两个实例,采用类别 C。
治疗编码
在治疗编码中,每个类别的权重是对应类别和参考类别之间预测的估计差异。线性模型的截距是参考类别的平均值(当所有其他特征保持不变时)。设计矩阵的第一列是截距,它的值总是 1。第二列表示实例i是否在 B 类中,第三列表示实例i是否在 C 类中,A 类不需要列,因为这样的话,线性方程会被过度指定,并且找不到权重的唯一解。只需知道一个实例既不属于 B 类也不属于 C 类就足够了。
特征矩阵: $$ \begin{pmatrix}1&0&0\1&0&0\1&1&0\1&1&0\1&0&1\1&0&1\\end{pmatrix} $$ 效果编码
每个类别的权重是从相应类别到总体平均值的估计 Y 差(假定所有其他特征为零或参考类别)。第一列用于估计截距。与截距相关联的权重\(\beta 0 \)表示总体平均值,第二列的权重\(\beta 1 \)表示总体平均值与 B 类之间的差异。B 类的总影响为\(\beta 0+β1 \)。C 类的解释是等效的。对于参考类别 A,总体效应与总体平均值和总体效应之间存在差异。
特征矩阵: $$ \begin{pmatrix}1&-1&-1\1&-1&-1\1&1&0\1&1&0\1&0&1\1&0&1\\end{pmatrix} $$ 虚拟编码
每个类别的\(\beta\)是每个类别的估计平均值 y(假定所有其他特征值为零或参考类别)。注意这里省略了截距,这样就可以找到线性模型权重的唯一解。
特征矩阵: $$ \begin{pmatrix}1&0&0\1&0&0\0&1&0\0&1&0\0&0&1\0&0&1\\end{pmatrix} $$ 如果你想深入了解分类特征的不同编码,请查看这个概述网页和博客推送。
4.1.6 线性模型是否有很好的解释?
从构成良好解释的属性来看,线性模型并不能创建最佳解释。正如人类友好型解释章节所展示,线性模型不能最好的进行解释。它们是对比的,但是引用实例是一个数据点,其中所有数字特征都为零,分类特征位于它们的引用类别中。这通常是一个假设的、毫无意义的实例,不太可能出现在您的数据或现实中。有一个例外:如果所有的数字特征都是平均中心(特征减去特征的平均值),并且所有的分类特征都是效果编码的,那么参考实例就是所有特征都接受平均特征值的数据点。这也可能是一个不存在的数据点,但至少可能更有可能或更有意义。在这种情况下,权重乘以特征值(特征效果)解释了与“平均实例”相比,对预测结果的贡献。一个好的解释的另一个方面是选择性,这可以在线性模型中通过使用较少的特征或训练稀疏的线性模型来实现。但默认情况下,线性模型不会创建选择性解释。线性模型创造真实的解释,只要线性方程是一个适当的模型,关系到特征和结果。非线性和相互作用越多,线性模型越不准确,解释越不真实。线性使得解释更为一般和简单。我认为,模型的线性本质是人们使用线性模型解释关系的主要因素。
4.1.7 稀疏线性模型
我选择的线性模型的例子看起来都很漂亮和整洁,不是吗?但实际上,您可能不只是拥有少数几个特征,而是拥有成百上千个特征。你的线性回归模型呢?解释能力下降。您甚至可能会发现自己处于这样一种情况,即特征比实例多,并且根本不适合标准线性模型。好消息是,有很多方法可以将稀疏性(即很少的特征)引入线性模型。
4.1.7.1 套索
套索法(Lasso)是一种将稀疏性引入线性回归模型的自动简便方法。Lasso 代表“最小绝对收缩和选择操作符”,当应用于线性回归模型时,执行特征选择和所选特征权重的正则化。让我们考虑权重优化的最小化问题:
$$ min{\boldsymbol{\beta}}\left(\frac{1}{n}\sum{i=1}^n(y^{(i)}-xi^T\boldsymbol{\beta})^2\right) $$ Lasso 为这个优化问题添加了一个术语。 $$ min{\boldsymbol{\beta}}\left(\frac{1}{n}\sum{i=1}^n(y^{(i)}-x{i}^T\boldsymbol{\beta})^2+\lambda||\boldsymbol{\beta}||_1\right) $$
特征向量的L1范数术语||\boldsymbol{\beta}||_1导致对大权重的惩罚。由于使用了 L1 范数,许多权重的估计值为 0,而其他权重的估计值则缩水。参数 lambda(λ) 控制正则化效果的强度,通常通过交叉验证进行调整。尤其是当 lambda 很大时,许多权重变为 0。特征权重可以可视化为惩罚项 lambda 的函数。每个特征权重由下图中的曲线表示。

图 4.4:随着权重惩罚的增加,越来越少的特征接受非零权重估计。这些曲线也称为正则化路径。图上的数字是非零权重的数目。
我们应该为 lambda 选择什么值?如果您将惩罚项视为一个优化参数,那么您可以找到 lambda,它通过交叉验证将模型错误最小化。还可以将 lambda 视为控制模型可解释性的参数。惩罚越大,模型中出现的特征就越少(因为它们的权重为零),并且模型的解释效果越好。
套索示例
我们将用套索预测自行车的租金。我们预先设置了模型中需要的特征数量。让我们先将数字设置为 2 个特征:
| 权重 | |
|---|---|
| 季节 春季 | 0.00 |
| 季节 夏季 | 0.00 |
| 季节秋季 | 0.00 |
| 季节 冬季 | 0.00 |
| 节假日 | 0.00 |
| 工作日 | 0.00 |
| 天气状况 有雾 | 0.00 |
| 天气状况 有雨/有雪/有风暴 | 0.00 |
| 温度 | 52.33 |
| 湿度 | 0.00 |
| 风速 | 0.00 |
| 自从2011年之后的天数 | 2.15 |
前两个在套索(Lasso)路径中具有非零权重的特征是温度(“温度”)和时间趋势(“自 2011 年以来的天数”)。
现在,让我们选择 5 个特征:
| 权重 | |
|---|---|
| 季节 春季 | -389.99 |
| 季节 夏季 | 0.00 |
| 季节秋季 | 0.00 |
| 季节 冬季 | 0.00 |
| 节假日 | 0.00 |
| 工作日 | 0.00 |
| 天气状况 有雾 | 0.00 |
| 天气状况 有雨/有雪/有风暴 | -862.27 |
| 温度 | 85.58 |
| 湿度 | -3.04 |
| 风速 | 0.00 |
| 自从2011年之后的天数 | 3.82 |
请注意,“温度”和“自 2011 年以来的天数”的权重不同于具有两个特征的模型。原因是,通过减少 lambda,即使是已经“在”模型中的特征也会受到较少的惩罚,并可能获得更大的绝对权重。套索权重的解释与线性回归模型中权重的解释相对应。您只需要注意特征是否标准化,因为这会影响权重。在这个例子中,这些特征被软件标准化了,但是权重被自动转换回来,以便我们匹配原始的特征比例。
线性模型中稀疏性的其他方法
广泛的方法可以用来减少线性模型中的特征数量。
预处理方法:
手动选择特征:您可以始终使用专家知识来选择或放弃某些特征。最大的缺点是它不能被自动化,您需要与理解数据的人取得联系。
单变量选择:一个例子是相关系数。您只考虑超过特征和目标之间相关阈值的特征。缺点是它只单独考虑特征。在线性模型解释了其他一些特征之前,某些特征可能不会显示相关性。那些你会错过的单变量选择方法。
逐步方法:
正向选择:用一个特征拟合线性模型。对每个特征都这样做。选择最有效的模型(例如,最高 r 平方)。现在,对于其余的特征,通过将每个特征添加到当前的最佳模型中来适应模型的不同版本。选择表现最好的一个。继续,直到达到某个条件,例如模型中的最大特征数。
反向选择:类似于正向选择。但是,不要添加特征,从包含所有特征的模型开始,并尝试删除哪些特征以获得最高的性能提高。重复此操作,直到达到某个停止标准。
我建议使用 Lasso,因为它可以自动化,同时考虑所有特征,并且可以通过 lambda 进行控制。它也适用于逻辑斯蒂回归模型的分类。
4.1.8 优势
将预测建模为一个加权和,使预测的生成变得透明。使用Lasso,我们可以确保使用的特征数量仍然很小。
许多人使用线性回归模型。这意味着在许多地方,预测建模和推理都被接受。有很高水平的集体经验和专业知识,包括线性回归模型和软件实现的教材。线性回归可以用于 R, Python, Java, Julia, Scala, JavaScript, …
从数学上讲,估计权重很简单,而且您可以保证找到最佳权重(假设数据满足线性回归模型的所有假设)。
与权重一起,你可以得到置信区间、测试和可靠的统计理论。线性回归模型也有许多扩展(请参见关于GLM, GAM和其他的章节)。
4.1.9 缺点
线性回归模型只能表示线性关系,即输入特征的加权和。每一个非线性或相互作用都必须是手工制作的,并明确地作为输入特征提供给模型。
对于预测性能来说,线性模型通常也不是那么好,因为可以学习的关系是如此有限,而且通常过于简单化了复杂的现实。
一个权重的解释可能是非指导性的,因为它依赖于所有其他特征。在线性模型中,与结果 Y 和另一个特征高度正相关的特征可能会得到负权重,因为在另一个相关特征下,它与高维空间中的 Y 呈负相关。完全相关的特征使得我们甚至不可能找到线性方程的唯一解。一个例子:你有一个模型来预测一个房子的价值,并且有一些特征,比如房间的数量和房子的大小。房子的大小和房间的数量是高度相关的:房子越大,拥有的房间就越多。如果将这两个特征都纳入线性模型中,可能会发生这样的情况:房屋的大小是更好的预测因素,并且会得到很大的正权重。房间的数量最终可能会得到一个负的权重,因为考虑到一个房子的大小相同,增加房间的数量可能会使它的价值降低,或者当相关性太强时,线性方程变得不稳定。
- 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉尼。“统计学习要素”。(2009 年)。↩
4.2 逻辑斯蒂回归
逻辑斯蒂回归模型的概率分类问题有两个可能的结果。它是分类问题线性回归模型的扩展。
4.2.1 线性回归分类有什么问题?
线性回归模型能很好地进行回归,但分类失败。为什么?对于两个类,可以将其中一个类标记为 0,另一个标记为 1,然后使用线性回归。从技术上讲,它是可行的,大多数线性模型程序都会为您提供权重。但这种方法存在一些问题:
线性模型不输出概率,但它将类视为数字(0 和 1),并适合最佳超平面(对于单个特征,它是一条直线),以最小化点和超平面之间的距离。所以它只是在点之间插入,你不能把它解释为概率。
一个线性模型也会外推并给出低于零和高于一的值。这是一个很好的迹象,表明可能有一种更智能的分类方法。
由于预测的结果不是概率,而是点之间的线性插值,因此没有一个有意义的阈值可以用来区分一个类和另一个类。这一问题已在Stackoverflow上得到很好的说明。
线性模型不能扩展到具有多个类的分类问题。您必须开始用 2、3 等标记下一个类。类可能没有任何有意义的顺序,但是线性模型会在特征和类预测之间的关系上强制一个奇怪的结构。具有正权重的特征值越高,它对具有更高数字的类的预测所起的作用就越大,即使恰好获得相似数字的类与其他类的距离不近。
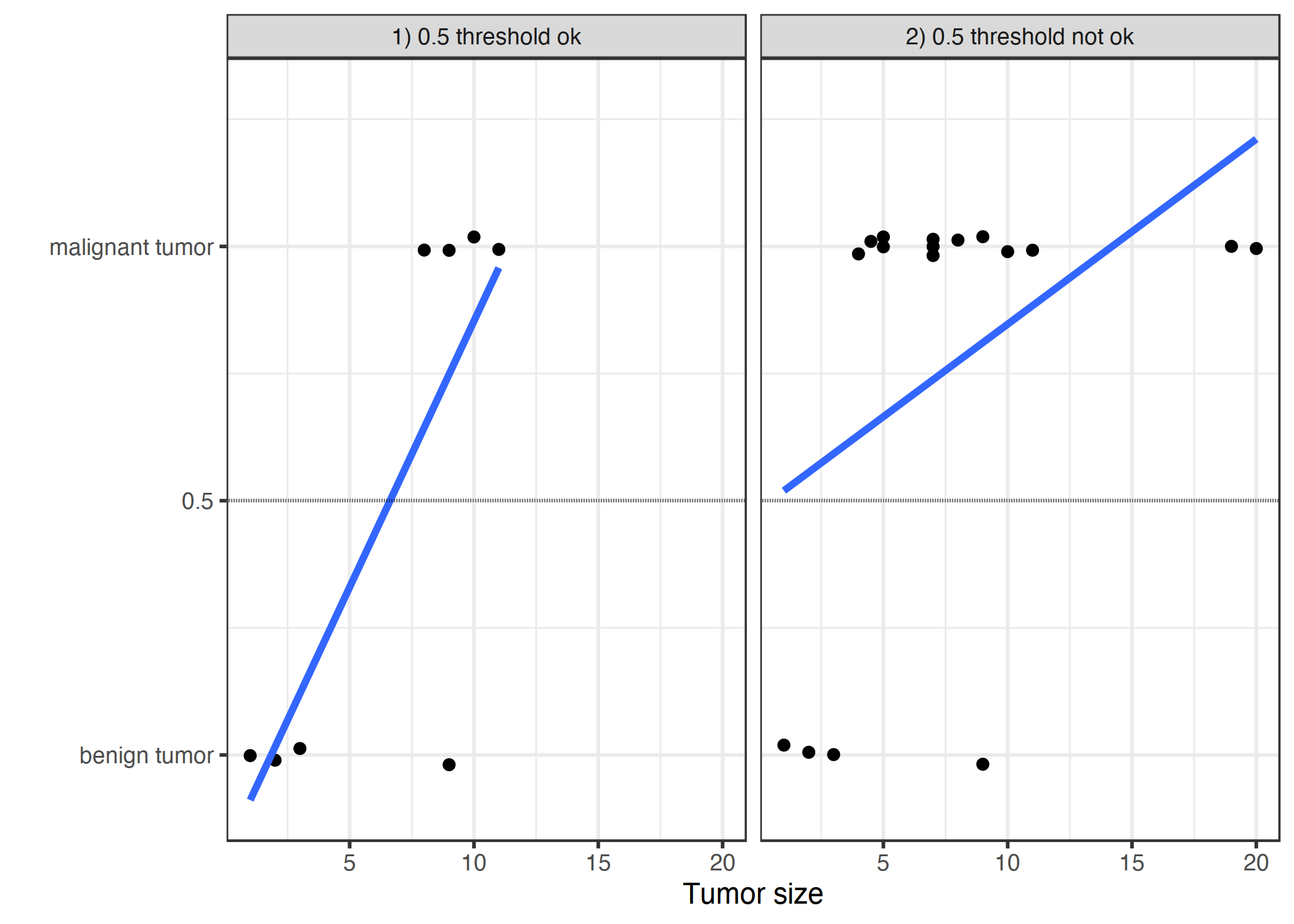
图 4.5:线性模型根据肿瘤的大小将其分类为恶性(1)或良性(0)。
这些线条显示了线性模型的预测。对于左边的数据,我们可以使用 0.5 作为分类阈值。在引入更多的恶性肿瘤病例后,回归线偏移和 0.5 的阈值不再区分这两类。点稍微抖动以减少过度绘制。
4.2.2 理论
分类的解决方案是逻辑斯蒂回归。而不是拟合直线或超平面,逻辑斯蒂回归模型使用逻辑函数挤压 0 到 1 之间的线性方程的输出。
逻辑斯蒂函数定义如下: $$ \text{logistic}(\eta)=\frac{1}{1+exp(-\eta)} $$ 并且它看起来像这样:
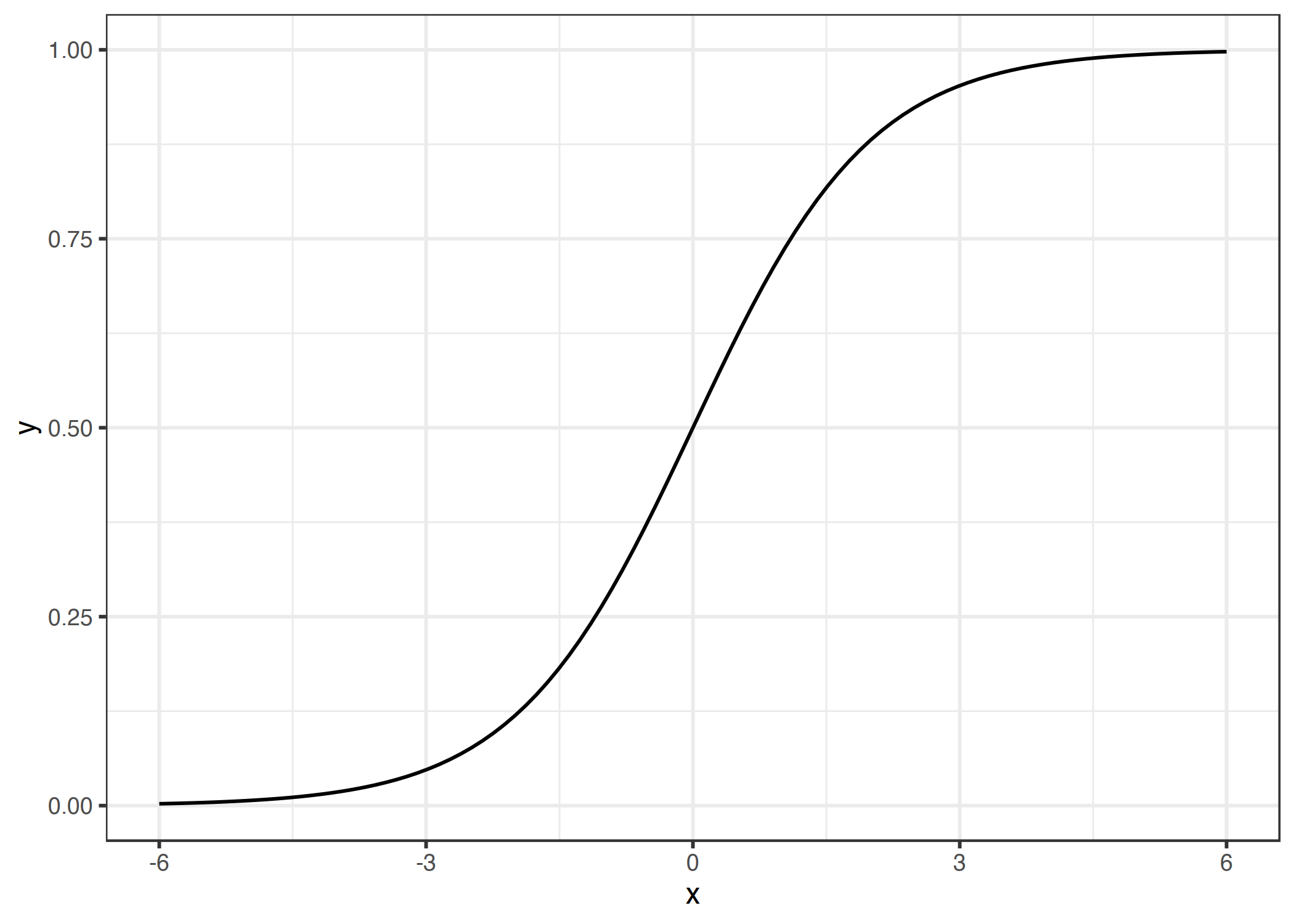
图 4.6:逻辑斯蒂函数。它输出介于 0 和 1 之间的数字。在输入 0 时,输出 0.5。
从线性回归到逻辑斯蒂回归的步骤有点简单。在线性回归模型中,我们用一个线性方程来模拟结果和特征之间的关系:
$$ \hat{y}^{(i)}=\beta{0}+\beta{1}x^{(i)}{1}+\ldots+\beta{p}x^{(i)}_{p} $$
对于分类,我们倾向于 0 到 1 之间的概率,因此我们将方程的右边包装成逻辑函数。这将强制输出仅假定 0 和 1 之间的值。
$$ P(y^{(i)}=1)=\frac{1}{1+exp(-(\beta{0}+\beta{1}x^{(i)}{1}+\ldots+\beta{p}x^{(i)}_{p}))} $$
让我们再次回顾一下肿瘤大小的例子。但我们使用的不是线性回归模型,而是逻辑斯蒂回归模型:
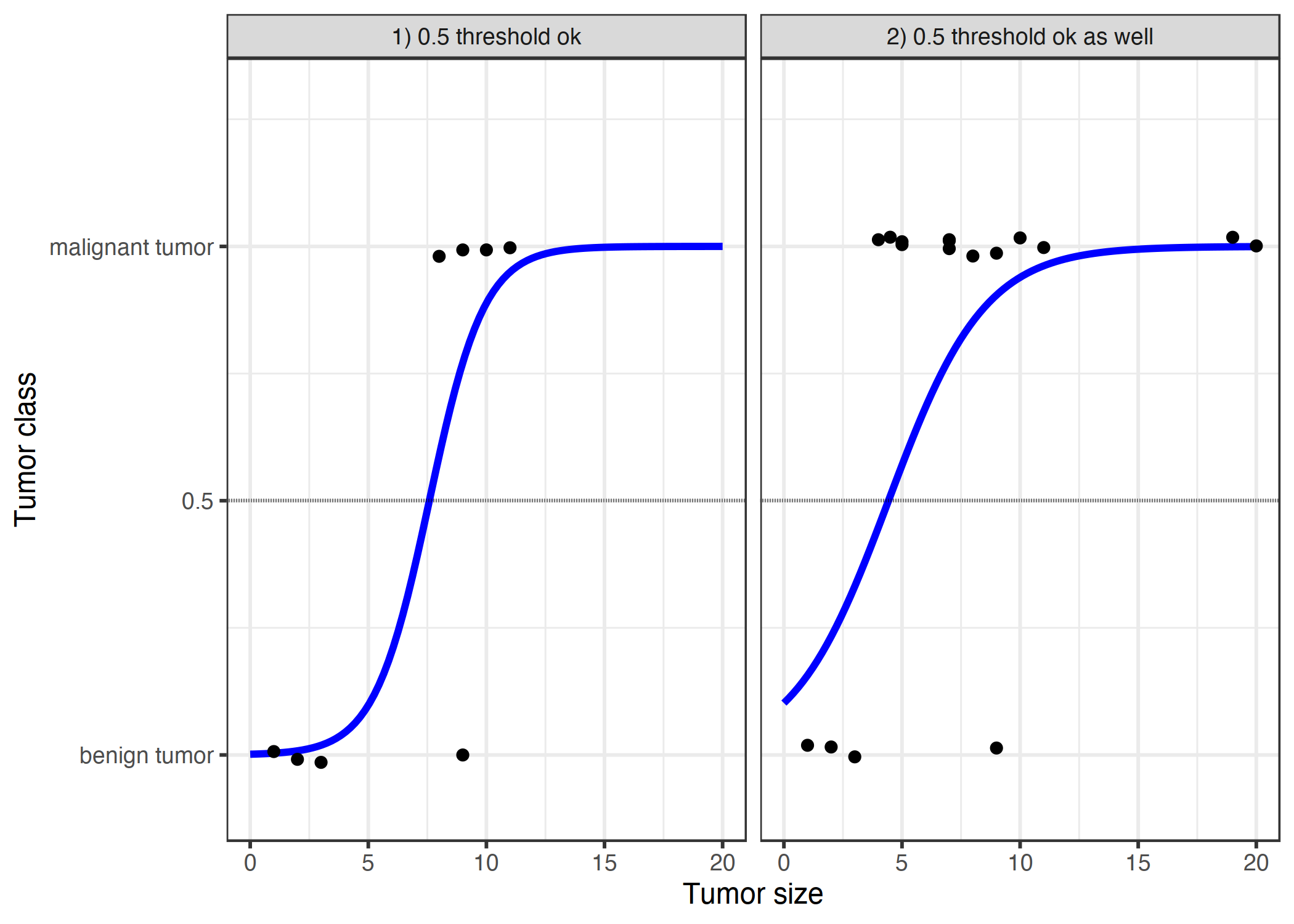
图 4.7:logistic 回归模型根据肿瘤大小找到良恶性之间的正确判定界限。该行是逻辑函数的移位和压缩,以适应数据。
使用逻辑斯蒂回归进行分类更好,在这两种情况下,我们都可以使用 0.5 作为阈值。附加点的包含并不真正影响估计曲线。
4.2.3 解释
逻辑斯蒂回归中权重的解释不同于线性回归中权重的解释,因为逻辑斯蒂回归的结果是 0 到 1 之间的概率。权重不再线性地影响概率。加权和由逻辑函数转换为概率。因此,我们需要为解释重新建立方程,以便只有线性项在公式的右侧。
$$ log\left(\frac{P(y=1)}{1-P(y=1)}\right)=log\left(\frac{P(y=1)}{P(y=0)}\right)=\beta{0}+\beta{1}x{1}+\ldots+\beta{p}x_{p} $$ 我们将 log()函数中的术语称为“odds(可能性)”(事件发生概率除以事件不发生概率),用对数表示,称为 log odds。
该公式表明,逻辑斯蒂回归模型是对数概率的线性模型。太好了家人们!这听起来没什么帮助!只要稍微改变一下这些术语,就可以知道当一个特征(x_j)被 1 个单位改变时,预测是如何变化的。为此,我们首先可以将 exp())函数应用于公式的两边:
$$ \frac{P(y=1)}{1-P(y=1)}=odds=exp\left(\beta{0}+\beta{1}x{1}+\ldots+\beta{p}x_{p}\right) $$
然后我们比较当我们将一个特征值增加 1 时会发生什么。但是,我们不看差异,而是看两个预测的比率:
$$ \frac{odds{x_j+1}}{odds}=\frac{exp\left(\beta{0}+\beta{1}x{1}+\ldots+\beta{j}(x{j}+1)+\ldots+\beta{p}x{p}\right)}{exp\left(\beta{0}+\beta{1}x{1}+\ldots+\beta{j}x{j}+\ldots+\beta{p}x_{p}\right)} $$
我们应用以下规则: $$ \frac{exp(a)}{exp(b)}=exp(a-b) $$ 并删除许多术语: $$ \frac{odds{x_j+1}}{odds}=exp\left(\beta{j}(x{j}+1)-\beta{j}x_{j}\right)=exp\left(\beta_j\right) $$
最后,我们得到了一个简单的特征权重 exp()。一个特征单位的改变会使优势比(乘法)改变一个系数。我们也可以这样解释:一个单位的改变(x_j)会增加相应权重值的对数优势比。大多数人解释比值比是因为人们知道思考某个事物的对数()对大脑来说很困难。解释赔率已经需要一些习惯。例如,如果概率为 2,则表示 y=1 的概率是 y=0 的两倍。如果权重(=log odds ratio)为 0.7,则将相应的特征增加一个单位,将优势乘以 exp(0.7)(约 2),优势变为 4。但通常你不处理赔率,只把权重解释为赔率。因为为了实际计算概率,您需要为每个特征设置一个值,这只有在您想查看数据集的一个特定实例时才有意义。
这些是对具有不同特征类型的逻辑斯蒂回归模型的解释:
数字特征:如果将特征值(x_j)增加一个单位,则估计的零散值将增加一个系数(exp(\beta_j))。
二进制分类特征:特征的两个值之一是引用类别(在某些语言中,是用 0 编码的)。将特征\(x j_ \)从引用类别更改为其他类别会将估计的概率更改为\(\exp(\beta j)系数)。
具有两个以上类别的分类特征:处理多个类别的一个解决方案是一个热编码,这意味着每个类别都有自己的列。对于具有 L 类别的分类特征,您只需要 L-1 列,否则它将被过度包装。第 l 类是参考类。您可以使用线性回归中使用的任何其他编码。每个类别的解释就相当于二进制特征的解释。
截距\(\beta 0 \):当所有数值特征为零且分类特征位于参考类别之外时,估计的概率为\(\exp(\beta 0))。截距权重的解释通常不相关。
4.2.4 示例
我们使用逻辑斯蒂回归模型,根据一些风险因素进行预测。下表显示了估计权重、相关的优势比和估计的标准误差。
表 4.1:在宫颈癌数据集上拟合逻辑斯蒂回归模型的结果。所示为模型中使用的特征、它们的估计权重和相应的优势比,以及估计权重的标准误差。
| 权重(Weight) | 让步比(Odds ratio) | 标准误差(Std. Error) | |
|---|---|---|---|
| 截距 | -2.91 | 0.05 | 0.32 |
| 激素避孕药(Y/N) | -0.12 | 0.89 | 0.30 |
| 吸烟 (Y/N) | 0.26 | 1.29 | 0.37 |
| 怀孕次数 | 0.04 | 1.04 | 0.10 |
| 诊断的性病数量 | 0.82 | 2.26 | 0.33 |
| 宫内节育器 | 0.62 | 1.85 | 0.40 |
数字特征的解释(“诊断的性病数量”):当所有其他特征保持不变时,诊断的性病(性传播疾病)数量的增加改变(减少)癌症与非癌症的几率增加 0.44 倍。记住,相关性并不意味着因果关系。这里没有获得性传播疾病的建议。
分类特征的解释(“激素避孕药 (Y/N)”):对于使用激素避孕药的妇女来说,与没有激素避孕药的妇女相比,癌症与没有癌症的几率高出 1.12 倍,因为所有其他特征保持不变。
就像线性模型一样,解释总是伴随着“所有其他特征保持不变”这一条款。
4.2.5 优缺点
许多线性回归模型的优点和缺点也适用于逻辑斯蒂回归模型。
逻辑斯蒂回归已被许多不同的人广泛使用,但它难以克服其限制性表达(例如,必须手动添加交互),其他模型可能具有更好的预测性能。
逻辑斯蒂回归模型的另一个缺点是解释更困难,因为权重的解释是乘法而不是加法。
逻辑斯蒂回归可能受到完全分离的影响。如果有一个特征能够将两个类完全分开,那么逻辑斯蒂回归模型就不能再被训练了。这是因为该特征的权重不会收敛,因为最佳权重是无限的。这真的有点不幸,因为这样的特征真的很有用。但是如果你有一个简单的规则将两个类分开,你就不需要机器学习了。完全分离问题可以通过引入权的惩罚或定义权的先验概率分布来解决。
从好的方面来说,逻辑斯蒂回归模型不仅是一个分类模型,而且给你概率。与只能提供最终分类的模型相比,这是一个很大的优势。知道一个实例对于一个类来说有 99%的概率,而对于 51%的类来说有很大的不同。
逻辑斯蒂回归也可以从二元分类扩展到多类分类。然后它被称为多项式回归。
4.2.6 软件
我在所有的例子中都使用了 R中的 glm 函数。您可以在任何可用于执行数据分析的编程语言中找到逻辑斯蒂回归,如 Python, Java, Stata, Matlab, …
4.3 GLM、GAM 等
线性回归模型最大的优点也是最大的缺点是预测被建模为特征的加权和。此外,线性模型还有许多其他假设。坏消息是(好吧,不是真正意义上的新闻)所有这些假设在现实中经常被违背:给定特征的结果可能具有非高斯分布,特征可能相互作用,特征和结果之间的关系可能是非线性的。好消息是,统计界已经开发了各种修改,将线性回归模型从一个简单的刀片转变为一把瑞士刀。
这一章绝对不是你扩展线性模型的明确指南。相反,它是一个扩展的概述,如广义线性模型(GLMs)和广义加法模型(GAMs),并给您一些直觉。阅读之后,您应该对如何扩展线性模型有一个坚实的概述。如果您想先了解更多关于线性回归模型的信息,我建议您阅读线性回归模型章节,如果您还没有准备好的话。
让我们记住线性回归模型的公式:
$$ y=\beta{0}+\beta{1}x{1}+\ldots+\beta{p}x_{p}+\epsilon $$ 线性回归模型假设一个实例的结果 y 可以用它的 p 特征的加权和表示,其中一个单独的误差 ϵ(epsilon)遵循高斯分布。通过将数据强制到公式的这个约束中,我们获得了许多模型的可解释性。特征效应是加性的,意味着没有相互作用,并且关系是线性的,意味着一个单位的特征增加可以直接转化为预测结果的增加/减少。线性模型允许我们将特征和预期结果之间的关系压缩成一个单一的数字,即估计的权重。
但对于许多现实世界的预测问题来说,简单的加权和太过严格。在本章中,我们将学习经典线性回归模型的三个问题以及如何解决它们。可能违反的假设还有很多问题,但我们将重点关注下图所示的三个问题:
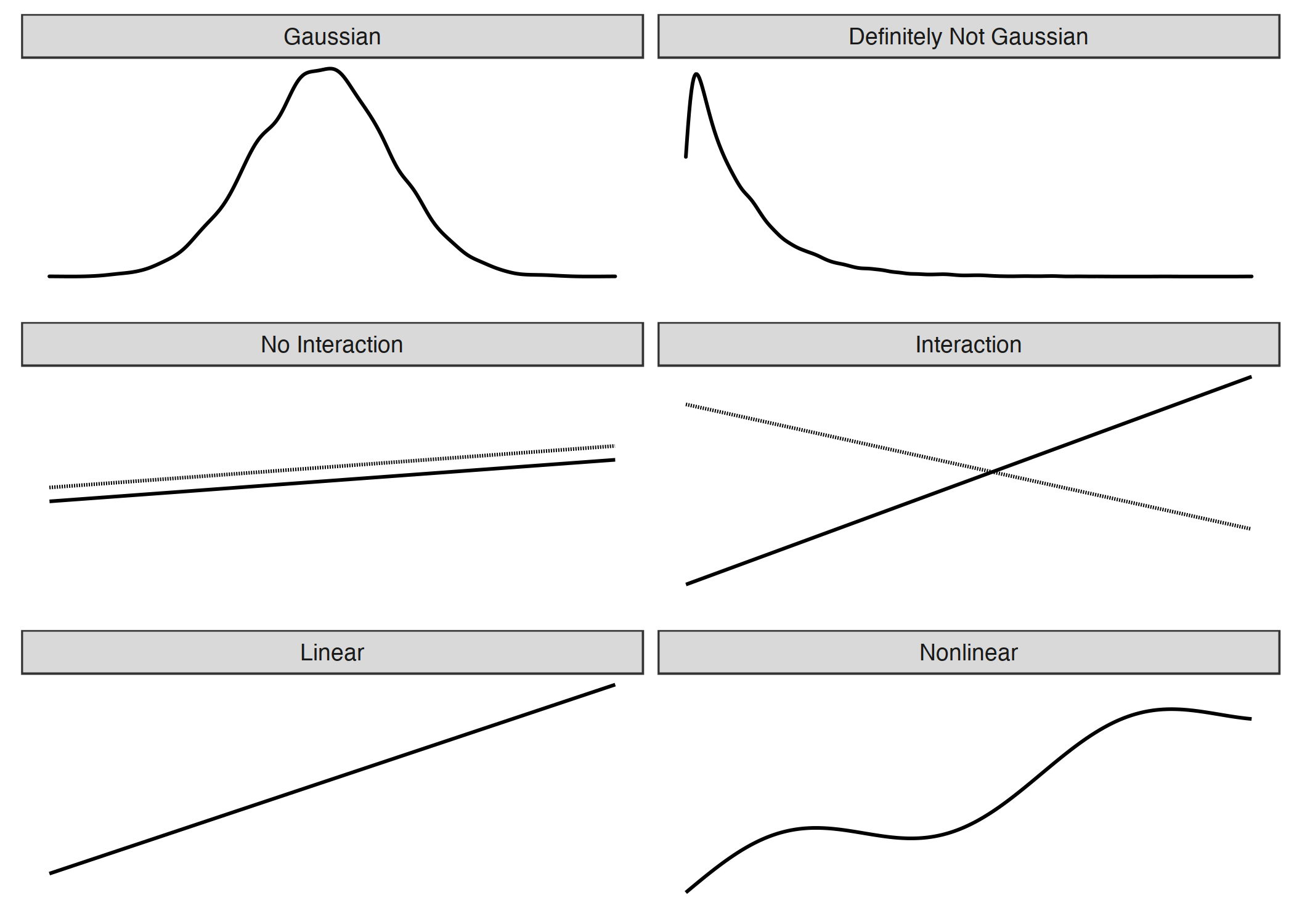
图 4.8:线性模型的三个假设(左侧):给定特征的结果的高斯分布、可加性(=无相互作用)和线性关系。现实通常不符合这些假设(右侧):结果可能具有非高斯分布,特征可能相互作用,关系可能是非线性的。
所有这些问题都有这样一个解决方案:
问题:给定特征的目标结果 y 不遵循高斯分布。
例如:假设我想预测我在给定的一天骑自行车的有多少分钟。作为特征,我有一天的类型,天气等等。如果我使用线性模型,它可以预测负分钟,因为它假设高斯分布,不会在 0 分钟停止。如果我想用线性模型预测概率,我可以得到负的或大于 1 的概率。
解决方案:Generalized Linear Models (GLMs).
问题:特征相互作用。
例如:一般来说,小雨对我骑车的欲望有轻微的负面影响。但是在夏天,在交通高峰期,我欢迎下雨,因为那时所有晴天的自行车手都呆在家里,我自己有自行车道!这是一种时间和天气之间的相互作用,不能由纯加法模型捕获。
解决方案:Adding interactions manually
问题:特征和 y 之间的真实关系不是线性的。
例如:在 0 到 25 摄氏度之间,温度对我骑车欲望的影响可能是线性的,这意味着从 0 到 1 摄氏度的增加导致骑车欲望的增加与从 20 到 21 摄氏度的增加相同。但在较高的温度下,我骑车的动机会减弱甚至降低——我不喜欢在太热的时候骑车。
解决:Generalized Additive Models (GAMs); transformation of features.
本章介绍了这三个问题的解决方案。线性模型的许多进一步扩展被省略了。如果我试图在这里涵盖所有的内容,这一章很快就会变成一本书中的一本书,关于一个已经被许多其他书所涵盖的主题。但是既然您已经在这里了,我已经为线性模型扩展做了一个小问题和解决方案概述,您可以在本章节的末尾中找到。解决方案的名称旨在作为搜索的起点。
4.3.1 非高斯结果-GLMs
线性回归模型假定,给定输入特征的结果遵循高斯分布。这一假设排除了许多情况:结果也可以是一个类别(癌症对健康)、一个计数(儿童数量)、事件发生的时间(机器故障的时间)或具有一些非常高价值(家庭收入)的非常扭曲的结果。线性回归模型可以扩展为所有这些类型的结果的模型。这个扩展称为广义线性模型,简称 GLMs。在本章中,我将对通用框架和该框架中的特定模型使用 GLM 这个名称。任何 GLM 的核心概念都是:保留特征的加权和,但允许非高斯结果分布,并通过可能的非线性函数连接该分布的预期平均值和加权和。例如,逻辑斯蒂 回归模型假设结果为伯努利分布,并使用 逻辑斯蒂函数连接预期平均值和加权和。
GLM 使用链接函数 g 将特征的加权和与假定分布的平均值进行数学链接,根据结果类型可以灵活选择。
$$ g(EY(y|x))=\beta_0+\beta_1{}x{1}+\ldots{}\betap{}x{p} $$ GLMS 由三个部分组成:连接函数 G、加权和(x^t\beta)(有时称为线性预测因子)和定义指数族E_Y的概率分布。
指数族是一组分布,可以用相同的(参数化的)公式编写,其中包括指数、分布的平均值和方差以及一些其他参数。我不会深入研究数学细节,因为这是一个非常大的宇宙,我不想进入它自己。维基百科有一个整洁的指数族分布列表。可以为您的 GLM 选择此列表中的任何分布。根据要预测的结果类型,选择合适的分布。结果是否算数(例如,家庭中的孩子人数)?那么泊松分布可能是一个很好的选择。结果是否总是积极的(例如两个事件之间的时间)?那么指数分布可能是一个很好的选择。
让我们把经典线性模型看作是 GLM 的一个特例。经典线性模型中高斯分布的连接函数是一个简单的恒等函数。高斯分布由均值和方差参数进行参数化。平均值描述了我们平均期望的值,而方差则描述了该平均值周围值的变化程度。在线性模型中,连接函数将特征的加权和连接到高斯分布的平均值。
在 GLM 框架下,这个概念推广到任何分布(指数族)和任意链接函数。如果 y 是某物的计数,例如某一天某人喝的咖啡数量,我们可以用一个带有泊松分布和自然对数的GLM 作为链接函数来建模:
$$ ln(E_Y(y|x))=x^{T}\beta $$ 逻辑斯蒂回归模型也是一个假定伯努利分布并使用逻辑函数作为链接函数的 GLM。逻辑斯蒂回归中使用的二项分布的平均值是 y 为 1 的概率。
$$ x^{T}\beta=ln\left(\frac{E_Y(y|x)}{1-E_Y(y|x)}\right)=ln\left(\frac{P(y=1|x)}{1-P(y=1|x)}\right) $$ 如果我们把这个方程解成 p(y=1)在一边,我们得到逻辑斯蒂回归公式:
$$ P(y=1)=\frac{1}{1+exp(-x^{T}\beta)} $$ 指数族的每一个分布都有一个标准的链接函数,可以从分布中数学地推导出来。GLM 框架使选择链接函数独立于分布成为可能。那么如何选择正确的链接特征?这里没有完美的食谱。你要考虑到关于你的目标分布的知识,同时也要考虑到理论上的考虑,以及模型与你的实际数据的匹配程度。对于某些分布,规范链接函数可能导致对该分布无效的值。在指数分布的情况下,正则连接函数是负的逆函数,这可能导致负的预测超出指数分布的范围。因为您可以选择任何链接函数,所以简单的解决方案是选择另一个尊重分布域的函数。
示例
我模拟了一个关于咖啡饮用行为的数据集,以强调对 GLMs 的需求。假设你收集了关于你每天喝咖啡行为的数据。如果你不喜欢咖啡,就假装是茶。除了杯子的数量,你还记录了你目前的压力水平,从 1 到 10,你前一天晚上睡得有多好,从 1 到 10,以及你那天是否必须工作。其目的是预测咖啡的数量,考虑到特征压力、睡眠和工作。我模拟了 200 天的数据。压力和睡眠在 1 到 10 之间被均匀地吸引,工作是/否被 50/50 的机会吸引(多么美好的生活!).然后,每天从泊松分布中提取咖啡的数量,将强度(也是泊松分布的预期值)建模为睡眠、压力和工作特征的函数。你可以猜到这个故事的结局:“嘿,让我们用一个线性模型来建模这个数据…… 哦,它不起作用…… 让我们用泊松分布来尝试一个 GLM……惊喜!现在它开始工作了!“。我希望对你来说我没有把这个故事搞得太糟。
让我们看看目标变量的分布,即给定日期的咖啡数量:
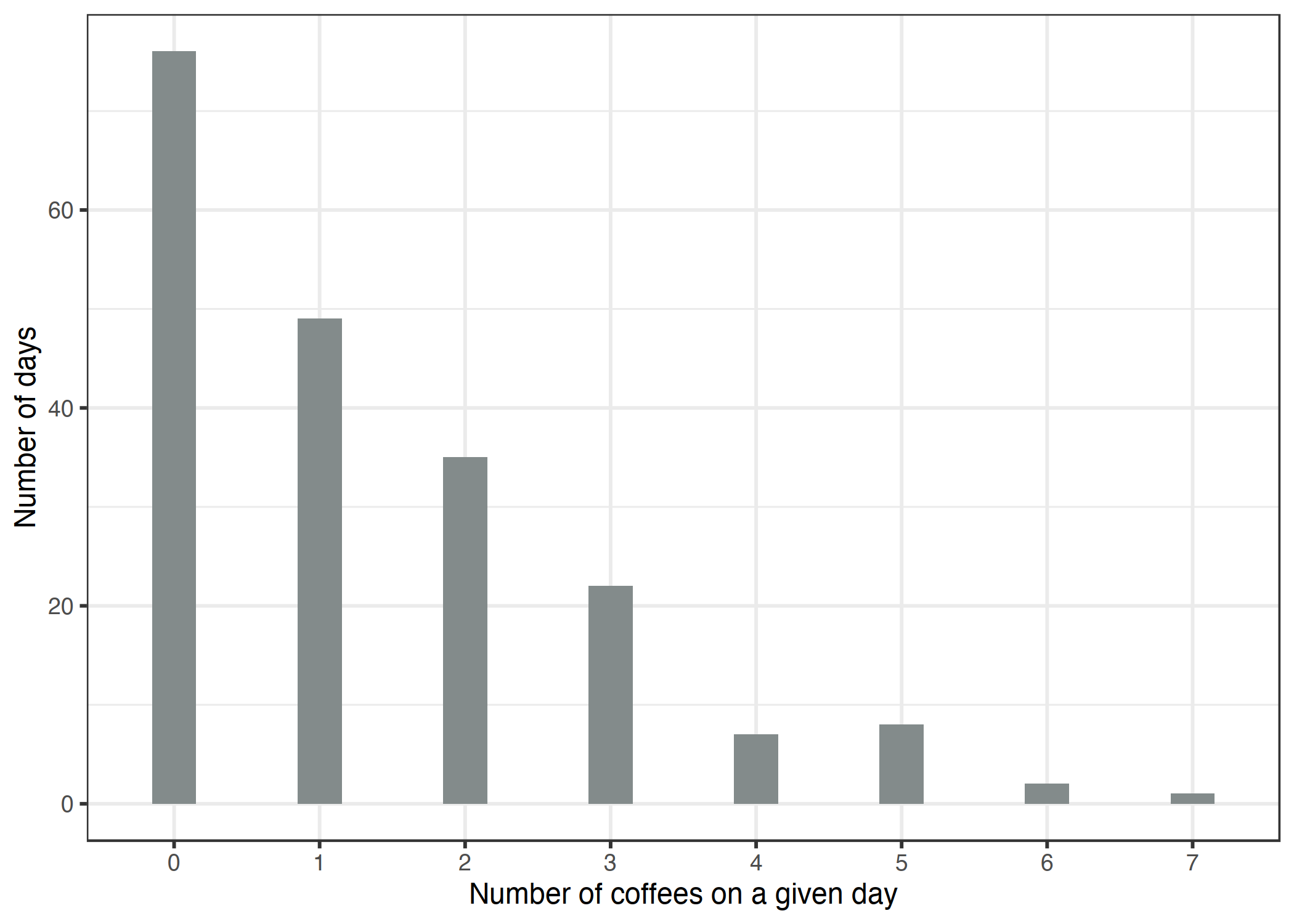
图 4.9:200 天每日咖啡数量的模拟分布。
在 200 天中的 76 天你根本没有喝咖啡,在最极端的一天你喝了 7 杯。让我们天真地使用一个线性模型来预测咖啡的数量,使用睡眠水平、压力水平和工作是/否作为特征。当我们错误地假设高斯分布时,会发生什么错误?错误的假设可能会使估计无效,尤其是权重的置信区间。更明显的问题是预测与真实结果的“允许”域不匹配,如下图所示。
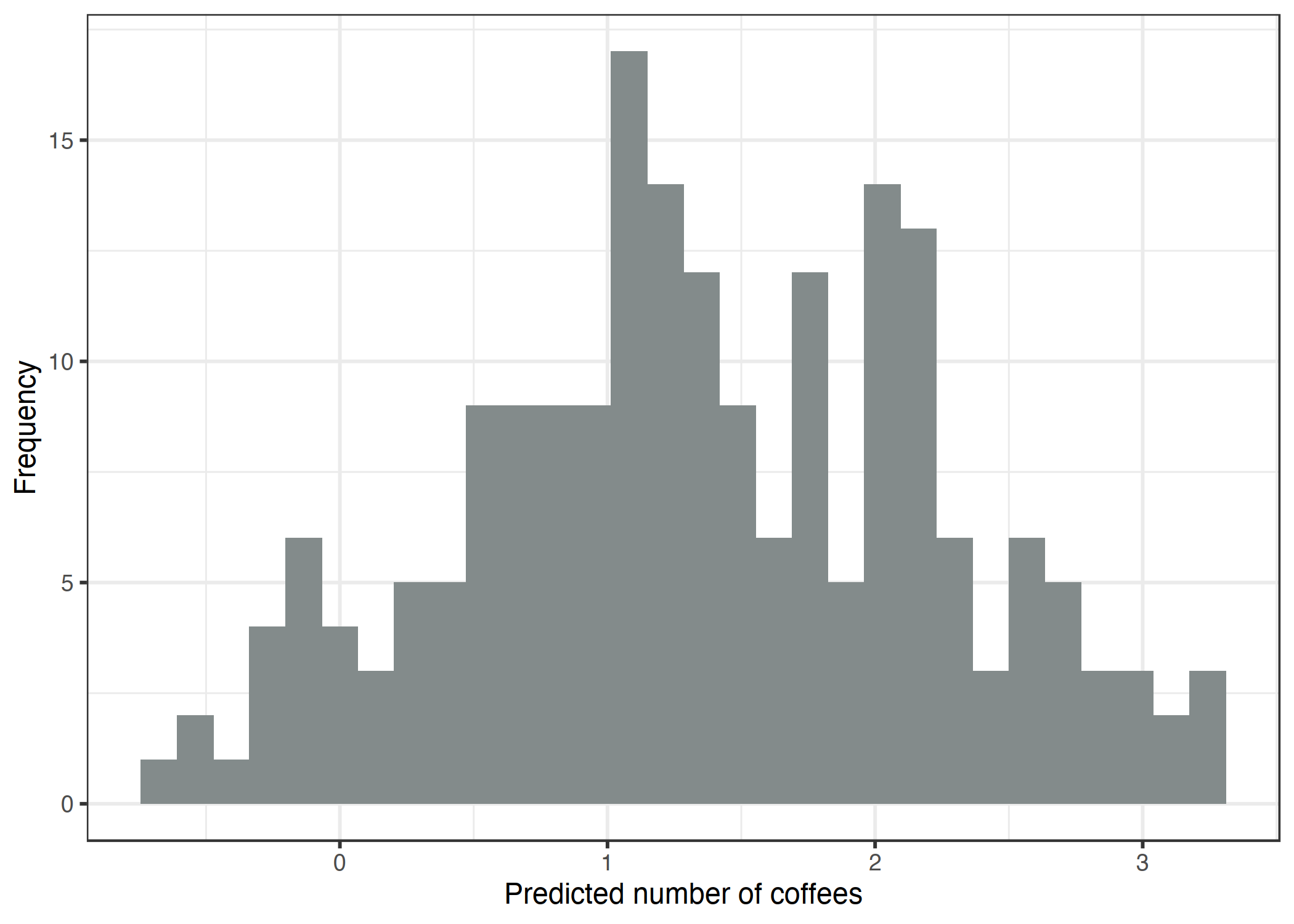
图 4.10:咖啡的预测数量取决于压力、睡眠和工作。线性模型预测负值。
线性模型没有意义,因为它预测咖啡的负数量。这个问题可以用广义线性模型来解决。我们可以改变连接函数和假定的分布。一种可能是保持高斯分布,并使用一个总是导致正预测的链接函数,例如对数链接(逆函数是 exp 函数)而不是恒等函数。更好的是:我们选择一个与数据生成过程相对应的分布和一个适当的链接函数。由于结果是一个计数,泊松分布是一个自然选择,同时对数作为链接函数。在这种情况下,数据甚至是由泊松分布生成的,因此泊松 GLM 是最佳选择。拟合的泊松 GLM 导致预测值的以下分布:
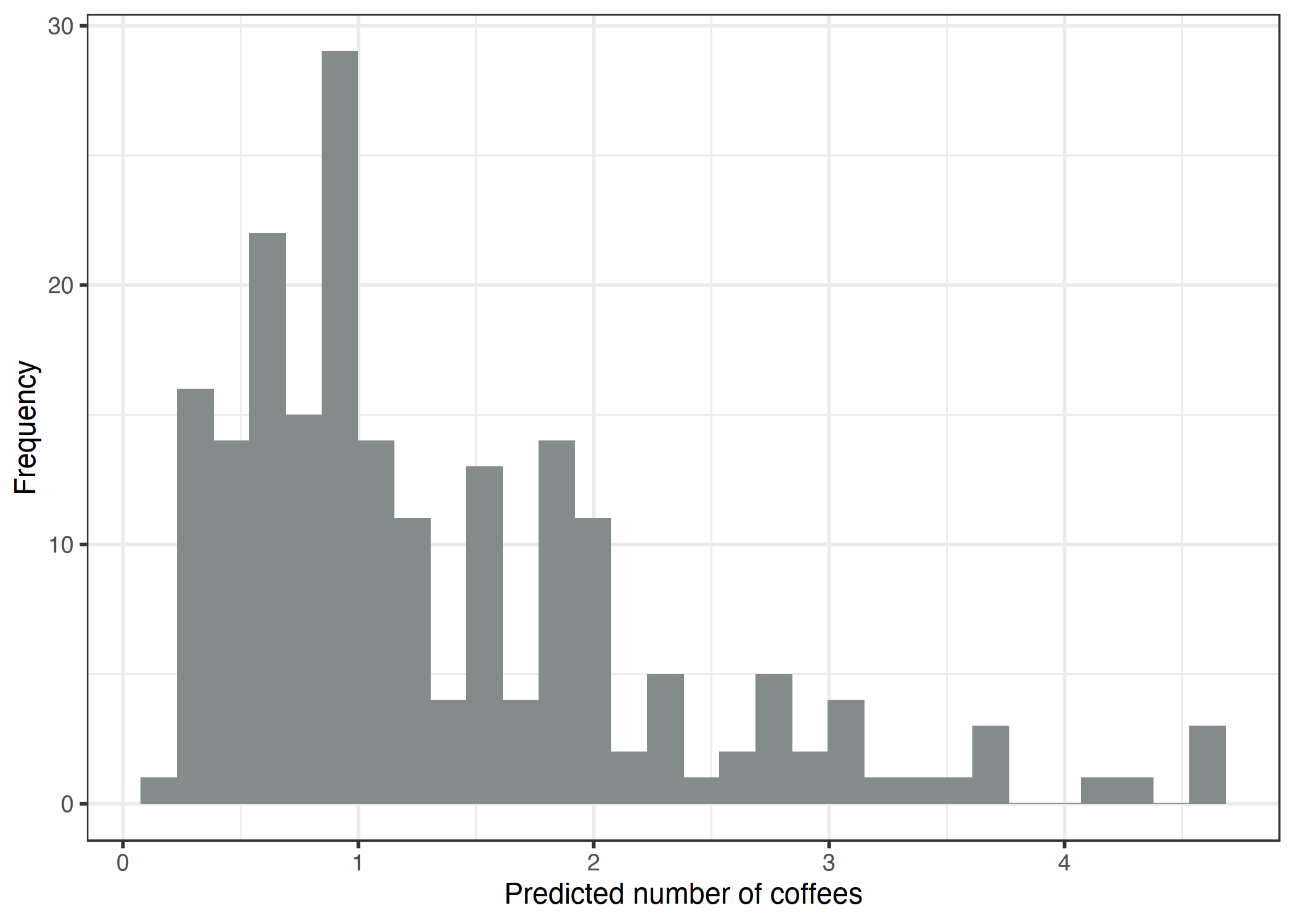
图 4.11:咖啡的预测数量取决于压力、睡眠和工作。具有泊松假设和日志链接的 GLM 是此数据集的适当模型。
没有负数量的咖啡,现在看起来好多了。
GLM 权重的解释
假设分布和链接函数决定了如何解释估计的特征权重。在 Coffee Count 示例中,我使用了一个带有泊松分布和日志链接的 GLM,这意味着特征和预期结果之间存在以下关系。
$$ ln(E(\text{coffees}|\text{stress},\text{sleep},\text{work}))=\beta0+\beta{\text{stress}}x{\text{stress}}+\beta{\text{sleep}}x{\text{sleep}}+\beta{\text{work}}x_{\text{work}} $$ 为了解释权重,我们颠倒了链接函数,这样我们就可以解释特征对预期结果的影响,而不是对预期结果的对数的影响。
$$ E(\text{coffees}|\text{stress},\text{sleep},\text{work})=exp(\beta0+\beta{\text{stress}}x{\text{stress}}+\beta{\text{sleep}}x{\text{sleep}}+\beta{\text{work}}x_{\text{work})} $$ 由于所有权重都在指数函数中,因此效果解释不是加性的,而是乘性的,因为 exp(a+b)是 exp(a)乘以 exp(b)。解释的最后一个要素是玩具例子的实际重量。下表列出了估计的权重和 exp(权重)以及 95%的置信区间:
| 权重(weight) | exp(权重)[2.5%,97.5%] | |
|---|---|---|
| (截距) | -0.16 | 0.85[0.54,1.32] |
| 压力 | 0.12 | 1.12[1.07,1.18] |
| 睡眠 | -0.15 | 0.86[0.82,0.90] |
| 工作 | 0.80 | 2.23[1.72,2.93] |
压力水平提高一点,咖啡的预期数量乘以系数 1.12。
将睡眠质量提高一点,咖啡的预期数量乘以系数 0.86。预计一个工作日的咖啡数量平均是休息日咖啡数量的 2.23 倍。总之,压力越大,睡眠越少,工作越多,咖啡消耗越多。
在本节中,您学习了一些关于当目标不遵循高斯分布时有用的广义线性模型的知识。接下来,我们将研究如何将两个特征之间的交互集成到线性回归模型中。
4.3.2 相互作用
线性回归模型假设一个特征的影响是相同的,而不考虑其他特征的值(=无交互作用)。但数据中经常有交互作用。为了预测租房情况,温度和工作日之间可能存在相互作用。也许,当人们不得不工作时,温度对租用自行车的数量影响不大,因为不管发生什么,人们都会骑着租用的自行车去工作。在休息日,许多人为了享乐而骑车,但只有在天气足够暖和的时候。当涉及到自行车租赁时,你可能期望温度和工作日之间的相互作用。
我们如何才能得到包含交互作用的线性模型?在拟合线性模型之前,请在特征矩阵中添加一列,表示特征之间的交互,并像往常一样拟合模型。该解决方案在某种程度上很优雅,因为它不需要对线性模型进行任何更改,只需要数据中的其他列。在工作日和温度示例中,我们将添加一个新特征,该特征不包含工作日,否则它具有温度特征的值,假设工作日是参考类别。假设我们的数据如下:
| 工作 | 温度 |
|---|---|
| 是 | 25 |
| 否 | 12 |
| 否 | 30 |
| 是 | 5 |
线性模型使用的数据矩阵看起来略有不同。下表显示了如果我们不指定任何交互,为模型准备的数据是什么样子的。通常,这种转换是由任何统计软件自动执行的。
| 截距(Intercept) | 工作Y(workY) | 温度(temp) |
|---|---|---|
| 1 | 1 | 25 |
| 1 | 0 | 12 |
| 1 | 0 | 30 |
| 1 | 1 | 5 |
第一列是截距项。第二列对分类特征进行编码,引用类别为 0,其他类别为 1。第三列包含温度。
如果我们希望线性模型考虑温度和工作日特征之间的相互作用,我们必须为相互作用添加一列:
| 截距(Intercept) | 工作Y(workY) | 温度(temp) | 工作Y.温度(workY.temp) |
|---|---|---|---|
| 1 | 1 | 25 | 25 |
| 1 | 0 | 12 | 0 |
| 1 | 0 | 30 | 0 |
| 1 | 1 | 5 | 5 |
新的列“工作Y.温度(workY.temp)”捕获了特征工作日(Work)和温度(Temp)之间的交互。对于一个实例,如果工作特征处于引用类别(“n”表示无工作日),则此新特征列为零,否则它假定实例温度特征的值。使用这种编码方式,线性模型可以学习两种类型的日的温度的不同线性效应。这是两个特征之间的交互作用。在没有交互项的情况下,分类特征和数值特征的组合效应可以用一条垂直移动的线来描述。如果我们将相互作用包括在内,我们就允许数值特征(斜率)的影响在每个类别中具有不同的值。
两个分类特征的交互作用也有类似的效果。我们创建了表示类别组合的附加特征。以下是一些包含工作日 (work) 和分类天气(wthr)特征的人工数据:
工作时间
| 工作日(work) | 天气(wthr) |
|---|---|
| 是 | 2 |
| 否 | 0 |
| 是 | 1 |
| 否 | 2 |
接下来,我们将包括交互术语:
| Intercept | workY | wthr1 | wthr2 | workY.wthr1 | workY.wthr2 |
|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 | 0 | 1 |
第一列用于估计截距。第二列是编码的工作特征。第三列和第四列用于天气特征,这需要两列,因为您需要两个权重来捕获三个类别的效果,其中一个类别是参考类别。其余的列捕获交互。对于这两个特征的每个类别(引用类别除外),如果两个特征都有一个特定的类别,我们将创建一个新的特征列,即 1,否则为 0。
对于两个数值特征,交互柱更容易构造:我们简单地将两个数值特征相乘。
有一些方法可以自动检测和添加交互术语。其中一个可以在RuleFit chapter中找到。规则拟合算法首先挖掘交互项,然后估计包含交互的线性回归模型。
例子
让我们回到我们已经在中建模的。这一次,我们还考虑了温度和工作日特征之间的相互作用。这将导致以下估计的权重和置信区间。
| 权重Weight | 标准差Std. Error | 2.5% | 97.5% | |
|---|---|---|---|---|
| 截距(Intercept) | 2185.8 | 250.2 | 1694.6 | 2677.1 |
| 季节 夏季 | 893.8 | 121.8 | 654.7 | 1132.9 |
| 季节 秋季 | 137.1 | 161.0 | -179.0 | 453.2 |
| 季节 冬季 | 426.5 | 110.3 | 209.9 | 643.2 |
| 假日 | -674.4 | 202.5 | -1071.9 | -276.9 |
| 弓足总日 | 451.9 | 141.7 | 173.7 | 730.1 |
| 天气状况 有雾 | -382.1 | 87.2 | -553.3 | -211.0 |
| 天气状况 有雨/…. | -1898.2 | 222.7 | -2335.4 | -1461.0 |
| 温度 | 125.4 | 8.9 | 108.0 | 142.9 |
| 湿度 | -17.5 | 3.2 | -23.7 | -11.3 |
| 风速 | -42.1 | 6.9 | -55.5 | -28.6 |
| 自从2011年之后的日子 | 4.9 | 0.2 | 4.6 | 5.3 |
| 工作日: 温度 | -21.8 | 8.1 | -37.7 | -5.9 |
额外的相互作用效应为负(-21.8),与零显著不同,如 95%置信区间所示,不包括零。顺便说一句,数据不是独立同分布(IID),因为彼此接近的日子并不相互独立。置信区间可能会产生误导,就拿它来说吧。交互项改变了相关特征权重的解释。如果是工作日,温度会有负面影响吗?答案是否定的,即使表格建议未经培训的用户使用。我们不能孤立地解释“工作日: 温度”交互权重,因为这样的解释是:“在保持所有其他特征值不变的情况下,增加工作日温度的交互作用会减少预测的自行车数量。”但是,在牵引效应只会增加温度的主要影响。假设这是一个工作日,我们想知道如果今天的温度升高 1 度会发生什么。然后我们需要将“温度”和“工作日: 温度”的权重相加,以确定估计值增加了多少。
从视觉上更容易理解交互。通过引入分类特征和数值特征之间的相互作用项,我们得到了温度的两个斜率,而不是一个。人们不需要工作的天数(“无工作日”)的温度斜率可直接从表(125.4)中读取。人们必须工作的天数的温度斜率(“工作日”)是两个温度权重的总和(125.4-21.8=103.6)。“非工作日”线在温度=0 时的截距由线性模型(2185.8)的截距项确定。“工作日”线在温度=0 时的截距由截距项+工作日的影响(2185.8+451.9=2637.7)确定。
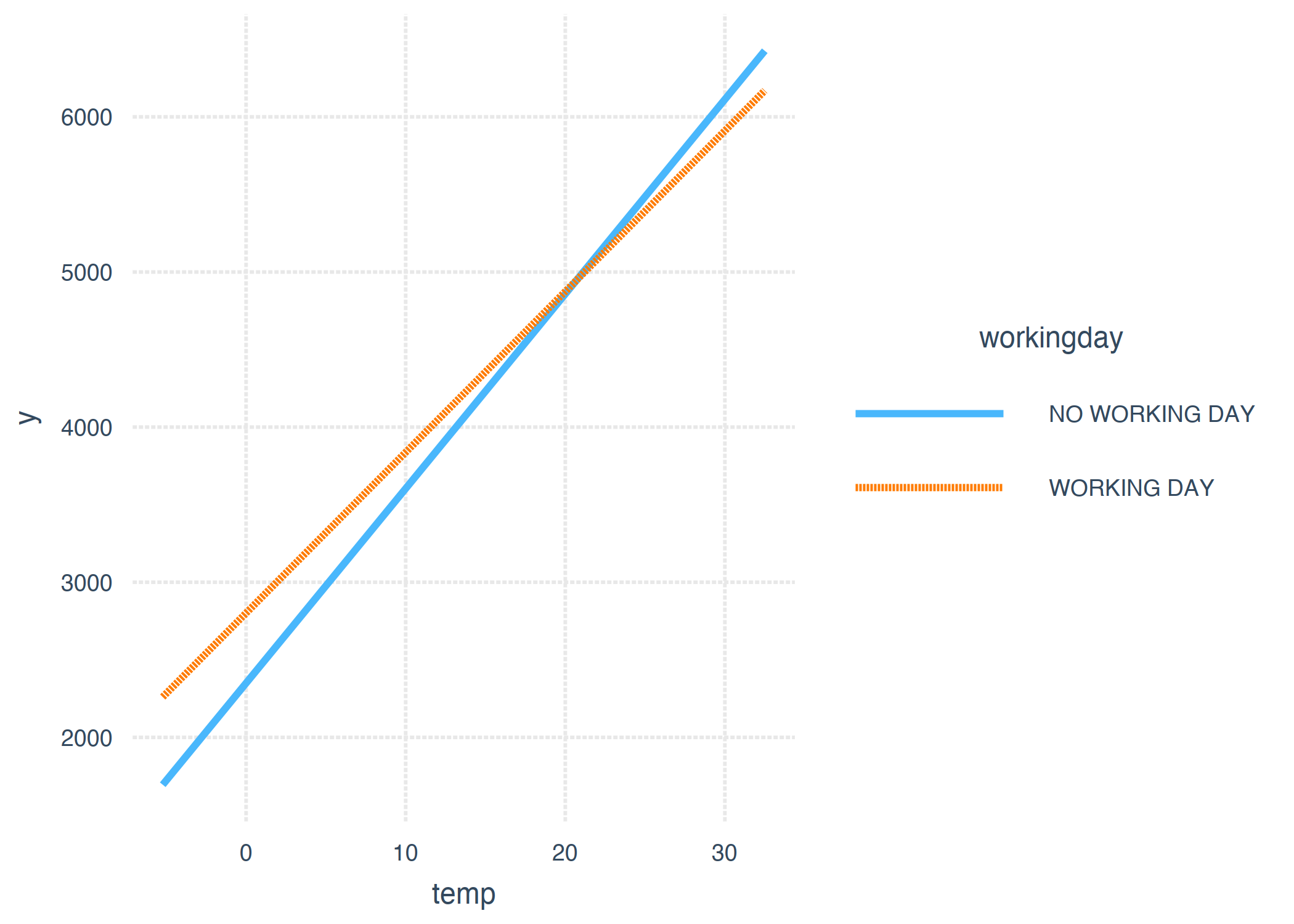
图 4.12:温度和工作日对线性模型预测自行车数量的影响(包括相互作用)。实际上,我们得到了两个温度的斜率,一个对应于工作日特征的每个类别。
4.3.3 非线性效应-GAMs
世界不是线性的。线性模型中的线性意味着,无论一个实例在某个特定特征中具有什么值,将该值增加一个单位对预测结果总是有相同的影响。假设温度在 10 摄氏度时升高 1 度,对租用自行车的数量产生的影响是否与温度在 40 摄氏度时升高相同?直观地说,人们期望把温度从 10 摄氏度提高到 11 摄氏度会对自行车租赁产生积极影响,从 40 摄氏度提高到 41 摄氏度会产生消极影响,正如你在书中的许多例子中看到的那样。温度特征对租用自行车的数量有线性的、积极的影响,但在某些时候它会变平,甚至在高温下也会产生负面影响。线性模型并不关心,它会尽职地找到最佳的线性平面(通过最小化欧几里得距离)。
可以使用以下方法之一对非线性关系建模:
特征的简单转换(例如: 对数)
特征分类
广义加法模型(GAMs)
在详细介绍每种方法之前,让我们先从一个示例开始,说明这三种方法。我使用租赁自行车数据集并训练了一个仅具有温度特征的线性模型来预测出租自行车的数量。下图显示了估算的斜率:标准线性模型、转换温度的线性模型(对数)、将温度视为分类特征并使用回归样条(GAM)的线性模型。
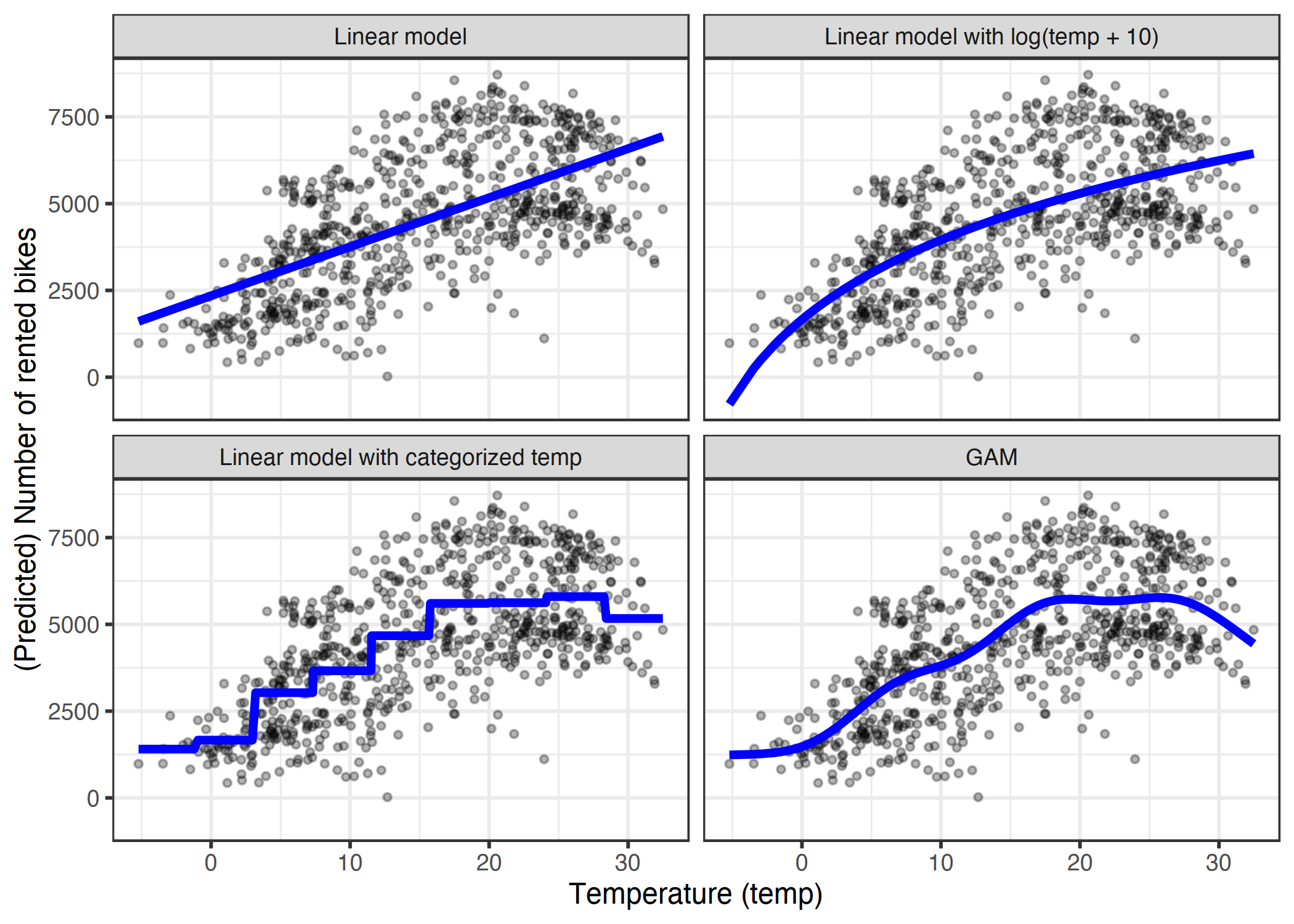
图 4.13:仅使用温度特征预测租用自行车的数量。线性模型(左上角)不适合数据。一种解决方案是用对数(右上)、分类(左下)来转换特征,这通常是一个错误的决定,或者使用可自动拟合平滑温度曲线(右下)的广义加法模型。
特征转换
通常将特征的对数用作转换。使用对数表示,每 10 倍的温度升高对自行车数量有相同的线性影响,因此从 1 摄氏度到 10 摄氏度的变化与从 0.1 到 1(听起来错误)的变化具有相同的效果。特征变换的其他例子有平方根、平方函数和指数函数。使用特征转换意味着用特征的函数(如对数)替换数据中该特征的列,并像往常一样拟合线性模型。一些统计程序还允许您在线性模型调用中指定转换。当您转换特征时,您可以发挥创造力。特征的解释会根据所选转换而变化。如果使用对数转换,线性模型中的解释将变为:“如果特征的对数增加 1,则预测将增加相应的权重。”当使用具有非同一性函数的链接函数的 GLM 时,则解释将得到更复杂的是,因为您必须将这两种转换合并到解释中(除非它们相互抵消,如 log 和 exp,否则解释会更容易)。
特征分类
实现非线性效果的另一种可能性是离散化特征,将其转化为分类特征。例如,您可以将温度特征切割为 20 个间隔,级别为[-10,-5),[-5,0)等等。当使用分类温度而不是连续温度时,线性模型将估计阶跃函数,因为每个级别都有自己的估计。这种方法的问题在于,它需要更多的数据,更容易过拟合,而且不清楚如何有意义地离散特征(等距间隔或分位数)?有多少个间隔?)只有在有很强的理由的情况下,我才会使用离散化。例如,使模型与另一项研究相比较。
广义加法模型(GAMs)
为什么不“简单”地允许(广义)线性模型学习非线性关系呢?这就是GAMs背后的动机。GAM 放宽了这种限制,即关系必须是一个简单的加权和,而假定结果可以由每个特征的任意函数的和建模。在数学上,gam中的关系如下: $$ g(EY(y|x))=\beta_0+f_1(x{1})+f2(x{2})+\ldots+fp(x{p}) $$ 该公式与 GLM 公式类似,不同之处在于线性项 β_jx_j被更灵活的函数f_j(x_j)取代。GAM的核心仍然是特征效果的总和,但是您可以选择允许某些特征和输出之间存在非线性关系。线性效应也包含在框架中,因为对于要线性处理的特征,您可以将它们的形式限制为f_j(x_j)仅采用x_jβ_j。
最大的问题是如何学习非线性函数。答案称为“样条”或“样条函数”。样条函数是可以组合起来以近似任意函数的函数。有点像堆放乐高积木来建造更复杂的东西。定义这些样条函数的方法有很多种,令人困惑。如果您有兴趣了解更多关于定义样条曲线的所有方法,我希望您在旅途中好运。我不想在这里讨论细节,我只想建立一个直觉。对于理解样条曲线,我个人最大的帮助是可视化单个样条函数,并研究如何修改数据矩阵。例如,为了用样条曲线对温度进行建模,我们从数据中删除了温度特征,并将其替换为 4 列,每列表示一个样条曲线函数。通常你会有更多的样条函数,我只是为了说明的目的减少了数量。这些新样条线特征的每个实例的值取决于实例的温度值。加上所有的线性效应,GAM 还可以估计这些样条权重。GAMs 还为权重引入了一个惩罚术语,以使它们接近零。这有效地降低了花键的灵活性,并减少了过拟合。然后通过交叉验证来调整通常用于控制曲线灵活性的平滑度参数。忽略惩罚项,样条曲线非线性建模是一种奇特的特征工程。
在我们仅使用温度预测 GAM 自行车数量的示例中,模型特征矩阵如下所示:
| (Intercept) | s(temp).1 | s(temp).2 | s(temp).3 | s(temp).4 |
|---|---|---|---|---|
| 1 | 0.93 | -0.14 | 0.21 | -0.83 |
| 1 | 0.83 | -0.27 | 0.27 | -0.72 |
| 1 | 1.32 | 0.71 | -0.39 | -1.63 |
| 1 | 1.32 | 0.70 | -0.38 | -1.61 |
| 1 | 1.29 | 0.58 | -0.26 | -1.47 |
| 1 | 1.32 | 0.68 | -0.36 | -1.59 |
每一行表示数据中的单个实例(一天)。每个样条线列包含特定温度值下样条线函数的值。下图显示了这些样条函数的外观:
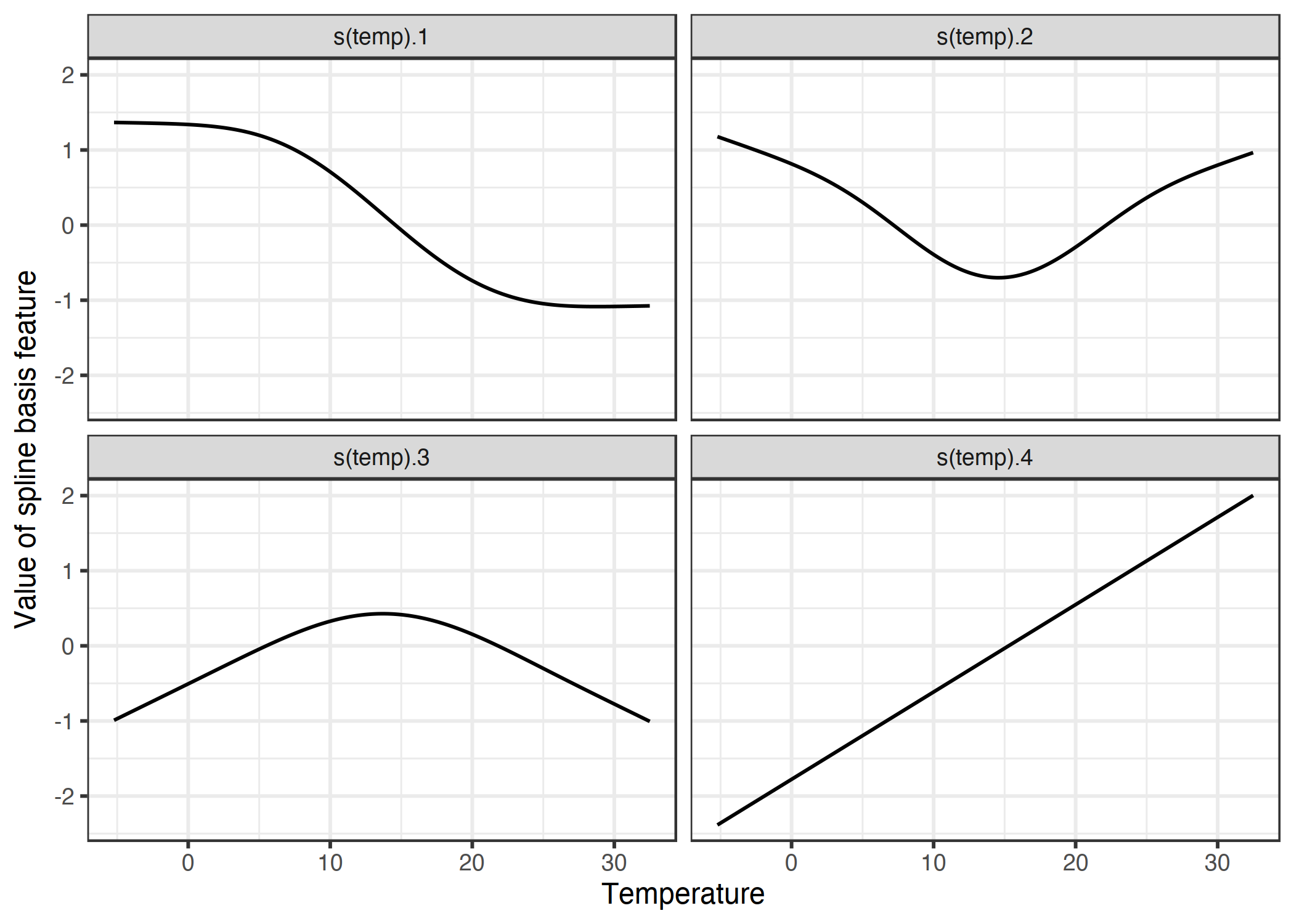
图 4.14:为了平滑地模拟温度效应,我们使用 4 个样条函数。每个温度值映射到(此处)4 个样条曲线值。如果实例的温度为 30°C,则第一个样条曲线特征的值为-1,第二个为 0.7,第三个为-0.8,第四个为 1.7。
GAM 为每个温度样条线特征指定权重:
| weight | |
|---|---|
| (Intercept) | 4504.35 |
| s(temp).1 | -989.34 |
| s(temp).2 | 740.08 |
| s(temp).3 | 2309.84 |
| s(temp).4 | 558.27 |
而实际曲线是由用估计权重加权的样条函数之和得到的,如下所示:
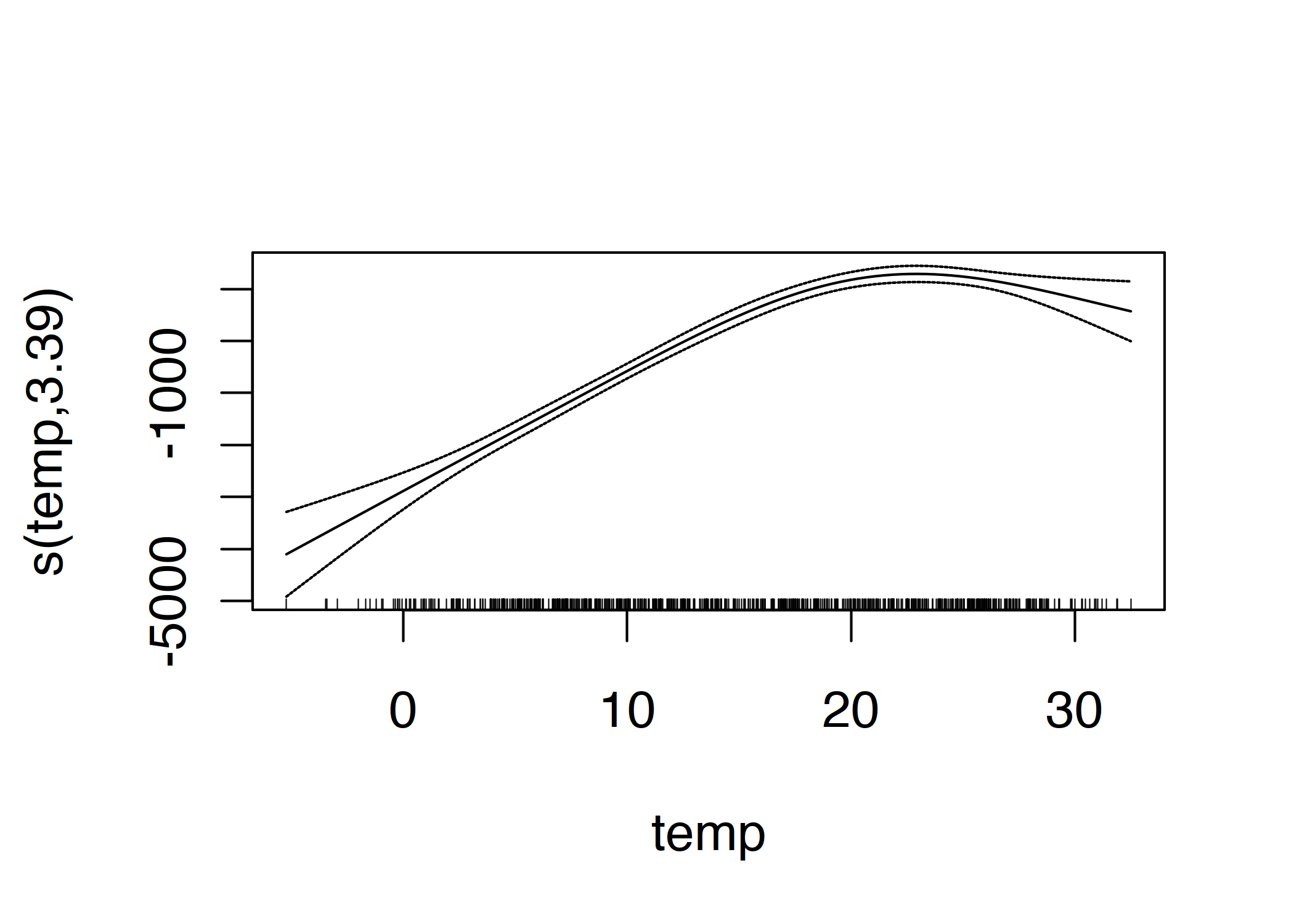
图 4.15:用于预测租用自行车数量的温度的 GAM 特征效应(温度是唯一的特征)。
平滑效果的解释需要对拟合曲线进行目视检查。样条曲线通常以均值预测为中心,因此曲线上的一个点与均值预测是不同的。例如,在 0 摄氏度时,预测的自行车数量比平均预测值低 3000 辆。
4.3.4 优势
线性模型的所有这些扩展本身就是一个宇宙。无论您面对的线性模型问题是什么,您可能会找到一个扩展来修复它。
大多数方法已经使用了几十年。例如,GAM 已经有将近 30 年的历史了。许多来自工业界的研究人员和实践者对线性模型非常有经验,并且这些方法在许多社区被认为是建模的现状。
除了进行预测之外,您还可以使用模型进行推理,得出关于数据的结论——假设模型假设没有违反。你可以得到权重的置信区间,显著性检验,预测区间等等。
统计软件通常有很好的接口来适应 GLMs、GAMs和更特殊的线性模型。
许多机器学习模型的不透明性源于 1)缺乏稀疏性,这意味着使用了许多特征;2)以非线性方式处理的特征,这意味着您需要一个以上的权重来描述效果;3)特征之间交互的建模锿。假设线性模型具有很高的可解释性,但通常是在不真实的情况下,本章所述的扩展提供了一种很好的方法,以实现平稳过渡到更灵活的模型,同时保留一些可解释性。
4.3.5 缺点
作为优势,我说过线性模型生活在自己的宇宙中。扩展简单线性模型的方法太多了,不仅仅是初学者。事实上,有多个平行的宇宙,因为许多研究者和实践者的社区都有他们自己的名字来命名那些或多或少做相同事情的方法,这可能非常令人困惑。
线性模型的大多数修改都会使模型的解释性变差。非同一性函数的任何链接函数(在 GLM 中)都会使解释复杂化;交互也会使解释复杂化;非线性特征效应要么不太直观(如对数转换),要么不能再由单个数字(如样条函数)来概括。
GLMs、GAMs 等依赖于有关数据生成过程的假设。如果违反了这些规定,则对权重的解释将不再有效。
在许多情况下,随机森林或梯度树增强等基于树的集合的性能比最复杂的线性模型要好。这部分是我自己的经验,也部分是来自 kaggle.com 等平台上的获奖模型的观察结果。
4.3.6 软件
本章中的所有示例都是使用 R 语言创建的。对于 GAMs,使用了 gam 包,但还有许多其他包。R 有大量的包来扩展线性回归模型。R 是任何其他分析语言都无法超越的,它是线性回归模型扩展的每一个可想象的扩展的所在。您将发现在 python 中实现 gams(例如: pyGAM),但这些实现还不够成熟。
4.3.7 进一步扩展
如前所述,这里列出了您可能遇到的线性模型问题,以及此问题的解决方案名称,您可以将其复制并粘贴到您最喜爱的搜索引擎中。
我的数据违反了独立同分布(iid)的假设。
例如,对同一患者重复测量。
搜索混合模型或广义估计方程。
我的模型有异方差错误。
例如,在预测房屋价值时,昂贵房屋的模型误差通常较高,这违背了线性模型的同方差性。
寻找稳健回归。
我有强烈影响我的模型的异常值。
寻找稳健回归。
我想预测事件发生前的时间。
事件到事件的数据通常带有经过审查的度量,这意味着在某些情况下没有足够的时间来观察事件。例如,一家公司想预测其制冰机的故障,但只有两年的数据。一些机器两年后仍然完好无损,但可能会在以后失效。
搜索参数生存模型,cox 回归,生存分析。
我要预测的结果是一个类别。
如果结果有两个类别,请使用逻辑斯蒂回归模型](https://christophm.github.io/interpretable-ml-book/logistic.html#logistic),它为类别建模概率。
如果你有更多的类别,搜索多项式回归。
逻辑斯蒂回归和多项式回归都是 GLMs。
我想预测有序的类别。
例如,学校成绩。
搜索比例优势模型。
我的结果是一个计数(就像一个家庭中孩子的数量)。
寻找泊松回归。
泊松模型也是一个 GLM。您可能还遇到一个问题,即 0 的计数值非常频繁。
寻找零膨胀泊松回归,跨栏模型。
我不确定模型中需要包含哪些特征才能得出正确的因果结论。例如,我想知道药物对血压的影响。这种药物对某些血量有直接影响,这种血量会影响结果。我应该将血量纳入回归模型吗?
寻找因果推理,调解分析。
我缺少数据。
寻找多重插补。
我想把先前的知识整合到我的模型中。寻找贝叶斯推理。
我最近有点情绪低落。
搜索“Amazon Alexa Gone Wild!!!! 从头到尾的完整版本”。
4.4 决策树
线性回归和逻辑斯蒂回归模型在特征与结果之间的关系为非线性或特征相互作用的情况下失败。是时候照亮决策树了!基于树的模型根据特征中的某些截止值多次分割数据。通过拆分,可以创建数据集的不同子集,每个实例都属于一个子集。最后的子集称为终端或叶F节点,中间的子集称为内部节点或拆分节点。为了预测每个叶节点的结果,使用该节点中训练数据的平均结果。树木可用于分类和回归。
有多种算法可以生长一棵树。它们在树的可能结构(例如每个节点的拆分数量)、如何查找拆分的标准、何时停止拆分以及如何估计叶节点内的简单模型等方面存在差异。分类和回归树(CART)算法可能是最流行的树归纳算法。我们将关注 Cart,但对于大多数其他树类型来说,解释是类似的。我推荐《统计学习要素》(Friedman、Hastie 和 Tibshirani,2009 年)一书来更详细地介绍CART 。
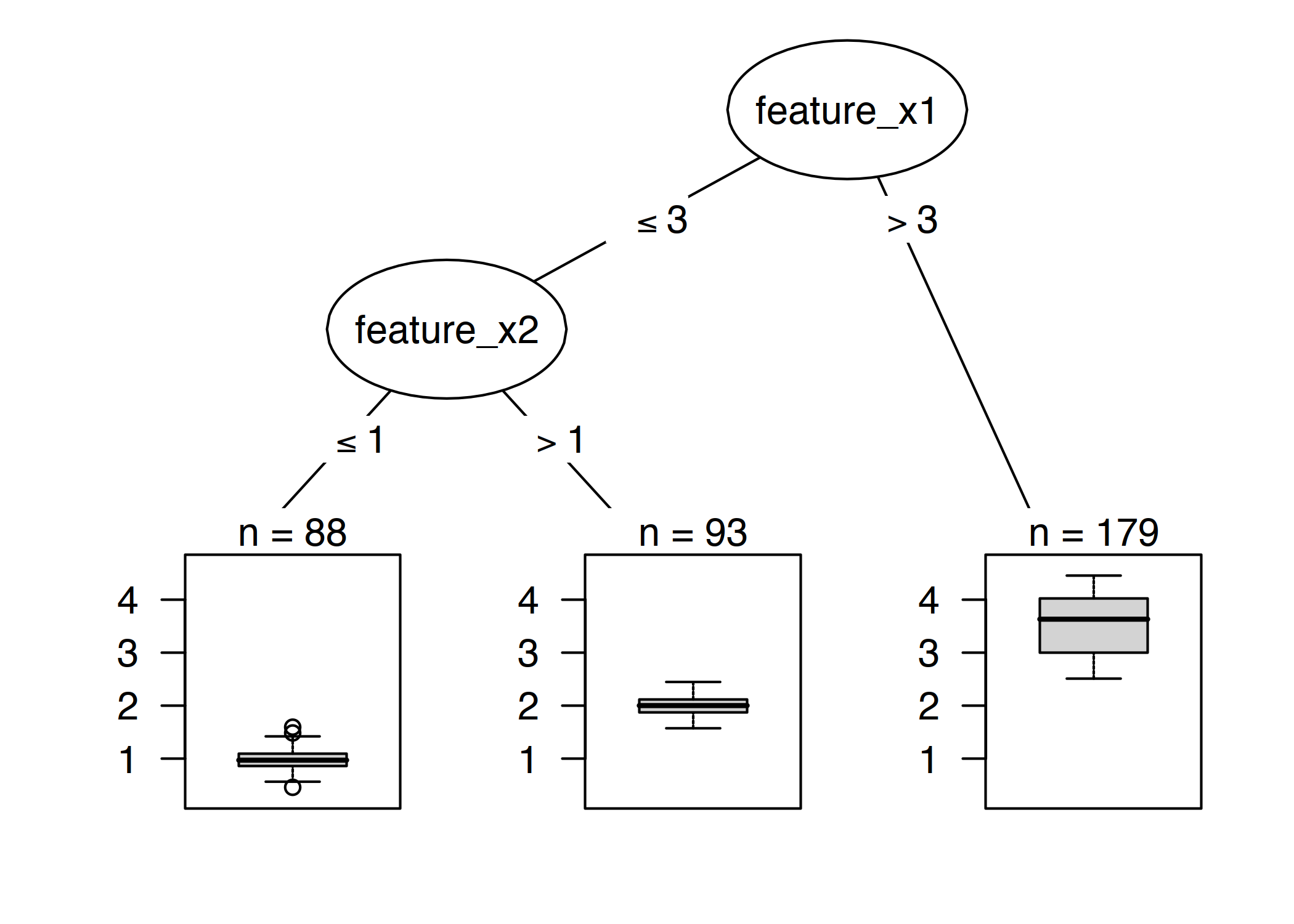
图 4.16:带有人工数据的决策树。特征 x1 的值大于 3 的实例将在节点 5 中结束。所有其他实例都分配给节点 3 或节点 4,这取决于特征 x2 的值是否超过 1。
下面的公式描述了结果 Y 和特征 X 之间的关系。
$$ \hat{y}=\hat{f}(x)=\sum_{m=1}^Mc_m{}I{x\in{}R_m} $$ 每个实例正好属于一个叶节点 (=subset R_m)。I{x∈Rm}是标识函数,如果x在子集R_m 中,如果一个实例属于叶节点R_l,则预测结果为\hat{y}=c_l,其中\(c_l\)是叶节点R_l中所有训练实例的平均值。
但是子集是从哪里来的呢?这很简单:CART采用一个特征,并确定回归任务的哪个临界点将 y 的方差最小化,或者分类任务的 y 类分布的基尼指数最小化。方差告诉我们节点中的 y 值围绕其平均值分布的程度。基尼指数告诉我们一个节点是如何“不纯”的,例如,如果所有的类都有相同的频率,那么这个节点就是不纯的,如果只有一个类存在,那么它就是最大的纯的。当节点中的数据点具有非常相似的 y 值时,方差和基尼指数最小化。因此,最佳截止点使两个结果子集在目标结果方面尽可能不同。对于分类特征,该算法尝试通过尝试不同类别分组来创建子集。在确定每个特征的最佳截止值后,算法选择将导致方差或基尼指数最佳分割的特征,并将此分割添加到树中。该算法继续此搜索并在两个新节点中递归拆分,直到达到停止条件。可能的条件是:拆分前必须在节点中的最小实例数,或必须在终端节点中的最小实例数。
4.4.1 解释
解释很简单:从根节点开始,转到下一个节点,边缘告诉您要查看的子集。一旦到达叶节点,该节点将告诉您预测的结果。所有边缘通过“和”连接。
模板:如果特征 x 比阈值 c 小/大,那么预测结果就是该节点中实例 y 的平均值。
特征重要性
在决策树中,一个特征的总体重要性可以用以下方法计算:通过使用该特征的所有拆分,并测量它相对于父节点减少了多少方差或基尼指数。所有进口货物之和按比例计算为 100。这意味着每个重要性都可以被解释为在整个模型重要性中所占的份额。
树木分解
通过将决策路径分解为每个特征的一个组件,可以解释决策树的单个预测。我们可以通过树跟踪决策,并通过在每个决策节点上添加的贡献来解释预测。
决策树中的根节点是我们的起点。如果我们使用根节点进行预测,它将预测训练数据结果的平均值。根据路径中的下一个节点,在下一个拆分中,我们要么减去这个和,要么添加一个项。为了得到最终的预测,我们必须遵循要解释的数据实例的路径,并不断地添加到公式中。
$$ \hat{f}(x)=\bar{y}+\sum{d=1}^D\text{split.contrib(d,x)}=\bar{y}+\sum{j=1}^p\text{feat.contrib(j,x)} $$ 单个实例的预测是目标结果的平均值加上在根节点和实例结束的终端节点之间发生的 D 拆分的所有贡献的总和。不过,我们对分割贡献不感兴趣,而是对特征贡献感兴趣。一个特征可能用于多个拆分,或者根本不用于。我们可以为每个 P 特征添加贡献,并获得每个特征对预测贡献多少的解释。
4.4.2 示例
让我们再看看租赁自行车数据。我们想用决策树来预测某一天租用自行车的数量。所学的树如下所示:
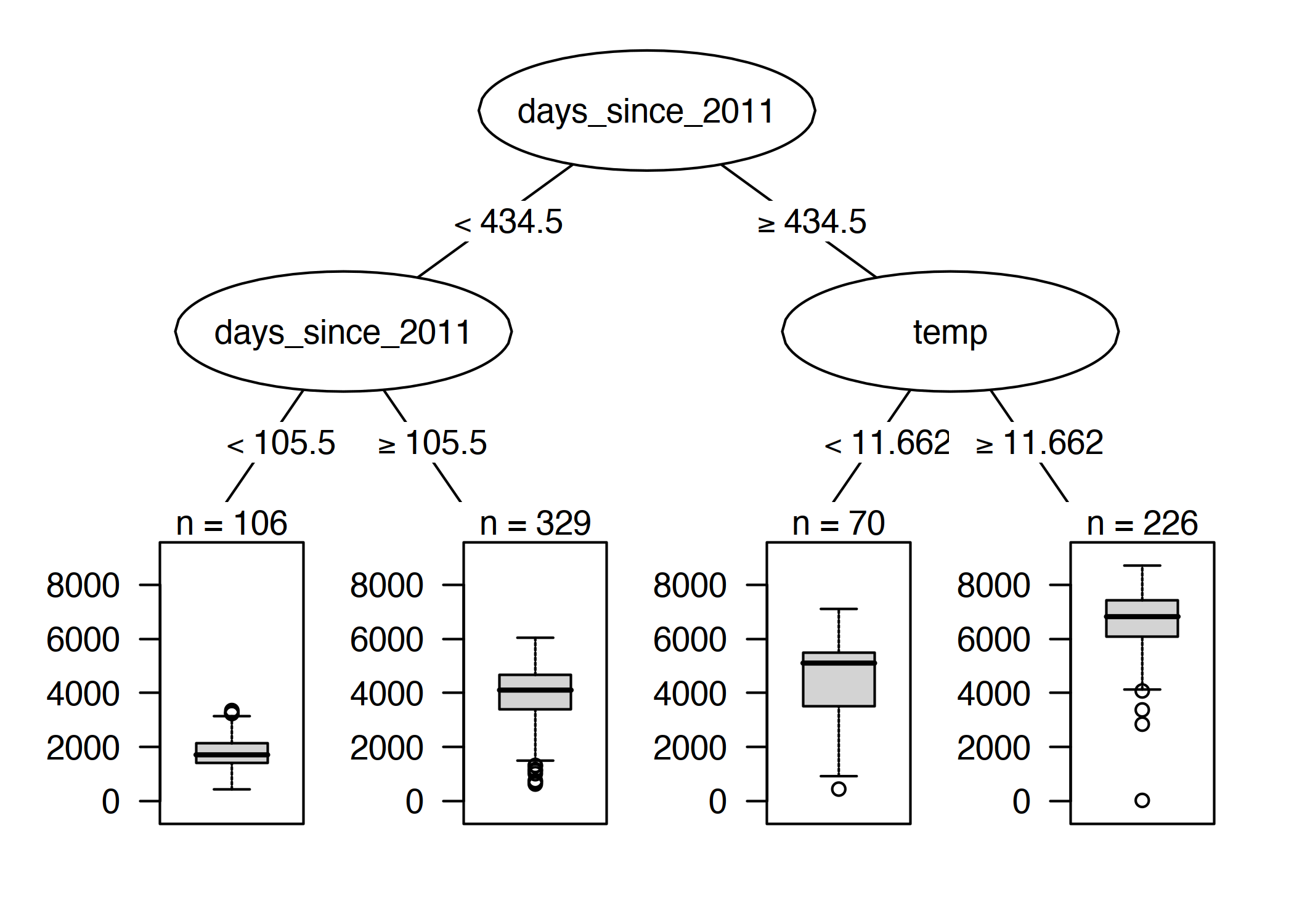
图 4.17:自行车租赁数据上的回归树。树的最大允许深度设置为 2。已为分割选择趋势特征(days since 2011)和温度(temp)。箱线图显示了终端节点中自行车数量的分布。
第一个分割和第二个分割中的一个是使用趋势特征执行的,该特征统计数据收集开始后的天数,并涵盖自行车租赁服务随着时间的推移变得越来越流行的趋势。在第 105 天之前的几天,自行车的预测数量大约是 1800 辆,在第 106 天和第 430 天之间,大约是 3900 辆。对于第 430 天之后的几天,预测值为 4600(如果温度低于 12 度)或 6600(如果温度高于 12 度)。
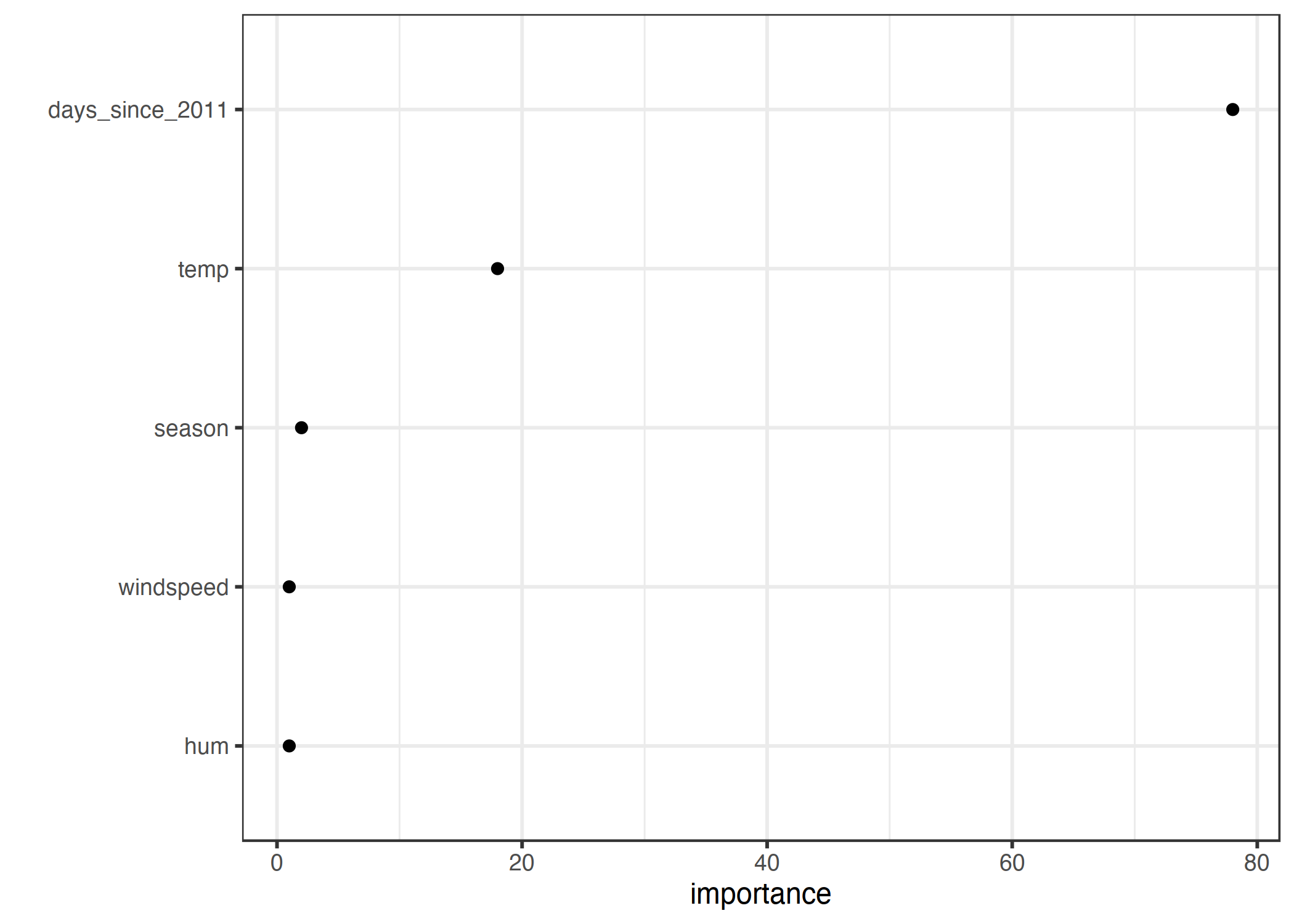
特征的重要性告诉我们特征在多大程度上有助于提高所有节点的纯度。这里使用了方差,因为预测自行车租赁是一个回归任务。
可视化树表明温度和时间趋势都被用于分割,但没有量化哪个特征更重要。特征重要性测度表明时间趋势远比温度重要。
图 4.18:通过平均提高节点纯度来衡量特征的重要性。
4.4.3 优势
树结构非常适合捕获数据中特征之间的交互。
这些数据以不同的组结束,这些组通常比多维超平面上的点更容易理解,就像线性回归一样。可以说,解释相当简单。
树结构也有一个自然的可视化,其节点和边缘。
树可以产生良好的解释,如中 “Human-Friendly Explanations”章节中所定义。树结构自动邀请将单个实例的预测值视为反事实:“如果某个特征大于/小于分割点,则预测值将是 y1 而不是 y2。树的解释具有对比性,因为您总是可以将实例的预测与相关的“假设”场景(由树定义)进行比较,这些场景只是树的其他叶节点。如果这棵树很短,像一到三个深的裂口,那么所得到的解释是有选择性的。深度为三的树最多需要三个特征和拆分点来为单个实例的预测创建解释。预测的真实性取决于树的预测性能。对于短树的解释非常简单和一般,因为对于每一个拆分,实例都属于一个或另一个叶子,并且二进制决策很容易理解。
不需要转换特征。在线性模型中,有时需要取特征的对数。决策树同样适用于特征的任何单调变换。
4.4.4 缺点
树不能处理线性关系。输入特征和结果之间的任何线性关系都必须通过分割来近似,从而创建一个阶跃函数。这是不有效的。
这与缺乏平滑度是紧密相连的。输入特征的微小变化会对预测结果产生很大影响,这通常是不可取的。想象一棵树预测房屋的价值,而这棵树使用房屋的大小作为分割特征之一。分裂发生在 100.5 平方米。想象一下,使用你的决策树模型的房价估计器的用户:他们测量他们的房子,得出房子有 99 平方米的结论,将其输入价格计算器,得到 20 万欧元的预测。用户注意到他们忘记了测量一个 2 平方米的小储藏室。储藏室有一道倾斜的墙,所以他们不确定是否能计算出所有的面积,或者只计算其中的一半。所以他们决定尝试 100.0 和 101.0 平方米。结果:价格计算器输出了 20 万欧元和 20.5 万欧元,这是相当不合理的,因为从 99 平方米到 100 没有变化。
树木也相当不稳定。训练数据集中的一些更改可以创建完全不同的树。这是因为每个拆分都依赖于父拆分。如果选择其他特征作为第一个拆分特征,则整个树结构将发生更改。如果结构如此容易更改,它不会在模型中创建信心。
决策树很容易理解——只要它们很短。终端节点的数量随着深度的增加而迅速增加。终端节点越多,树越深,就越难理解树的决策规则。深度为 1 表示 2 个终端节点。深度 2 表示最多 4 个节点。深度 3 表示最多 8 个节点。树中终端节点的最大数量是深度的 2 倍。
4.4.5 软件
对于本章中的示例,我使用了实现 CART(分类和回归树)的rpartR 包。CART 是用许多编程语言实现的,包括 Python。有争议的是,CART 是一个相当古老的,有些过时的算法,还有一些有趣的新算法来拟合树。您可以在关键字“递归分区”下的 Machine Learning and Statistical Learning CRAN Task View找到决策树的一些 R 包的概述。
- 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉尼。“统计学习要素”。www.web.stanford.edu/~hassie/elemstatlearn/(2009 年)。
4.5 决策规则
决策规则是一个简单的 IF-THEN 语句,由条件(也称为先行条件)和预测组成。例如:如果今天下雨,如果是四月(条件),那么明天下雨(预测)。可以使用单个决策规则或多个规则的组合进行预测。
决策规则遵循一个一般的结构:如果条件满足,那么做一个特定的预测。决策规则可能是最容易解释的预测模型。它们的 IF-THEN 结构在语义上类似于自然语言和我们的思维方式,前提是条件是由可理解的特征构建的,条件的长度很短(少数feature=与 and 组合的value对),并且没有太多规则。在编程中,编写IF-THEN规则是很自然的。机器学习中的新特征是通过算法学习决策规则。
想象一下,使用一种算法来学习预测房屋价值的决策规则(low, medium或high)。这个模型学习到的一个决策规则可能是:如果一个房子超过 100 平方米,并且有一个花园,那么它的价值就很高。更正式一点:如果size>100 AND garden(花园)=1,则value=high。
让我们打破决策规则:
size>100 是 if 部分的第一个条件。
garden=1 是 if 部分的第二个条件。
这两个条件通过“AND”连接以创建新条件。这两个规则都必须适用。
预测结果(THEN部分)
value=high。
决策规则在条件中至少使用一个feature=value语句,对于“AND”可以添加的数量没有上限。一个例外是没有显式 IF部分 的默认规则,当没有其他规则应用时该规则也适用,但稍后将对此进行详细说明。
决策规则的有用性通常概括为两个数字:支持和准确性。
规则的支持或覆盖率:应用规则条件的实例的百分比被称为支持。例如,规则大小=大,位置=好,然后值=高( size=big AND location=good THEN value=high),用于预测房屋价值。假设 1000 间房子中有 100 间大而位置好,那么规则的支持率是 10%。预测(然后是部分)对支护计算不重要。
规则的准确性或可信度:规则的准确性是衡量规则在预测规则条件适用的实例的正确类时的准确性的指标。例如:假设 100 个房屋中,规则大小=大,位置=好,则值=高(size=big AND location=good THEN value=high),85 个房屋中的值=高(value=high),14 个房屋中的值=中(value=medium),1 个房屋中的值=低( value=low),则规则的准确度为 85%。
通常在精度和支持之间有一个权衡:通过在条件中添加更多的特征,我们可以获得更高的精度,但会失去支持。
为了创建一个好的分类器来预测房子的价值,你可能不仅需要学习一条规则,而且可能需要学习 10 或 20 条规则。然后事情会变得更复杂,你会遇到以下问题之一:
- 规则可以重叠:如果我想预测一栋房子的价值和两个或两个以上的规则,它们会给我矛盾的预测呢?
- 没有适用的规则:如果我想预测一所房子的价值,但没有适用的规则怎么办?
组合多个规则有两种主要策略:决策列表(有序)和决策集(无序)。这两种策略都暗示了对重叠规则问题的不同解决方案。
决策列表向决策规则引入一个顺序。例如,如果第一条规则的条件为真,则使用第一条规则的预测。如果没有,我们将转到下一个规则,检查它是否适用,依此类推。决策列表通过只返回应用列表中第一个规则的预测来解决重叠规则的问题。
决策集类似于规则的民主,只是有些规则可能具有更高的投票权。在一套规则中,这些规则要么相互排斥,要么有解决冲突的策略,例如多数投票,这些策略可以通过个别规则的准确性或其他质量措施进行加权。当一些规则适用时,解释性可能会受到影响。
决策列表和决策集都可能面临没有规则适用于实例的问题。这可以通过引入默认规则来解决。默认规则是在没有其他规则适用时应用的规则。默认规则的预测通常是数据点中最频繁的一类,而其他规则不包括这些数据点。如果一组规则或一系列规则覆盖了整个特征空间,我们称之为详尽的。通过添加默认规则,集合或列表将自动变得详尽。
从数据中学习规则的方法有很多,本书远没有涵盖所有这些方法。这一章向你展示了其中三个。选择这些算法是为了涵盖广泛的学习规则的一般思想,因此这三种算法代表了非常不同的方法。
OneR 从一个特征学习规则。OneR 的特点是其简单性、可解释性和作为基准的使用。
顺序覆盖是一个迭代学习规则并删除新规则所覆盖的数据点的一般过程。这个过程被许多规则学习算法使用。
贝叶斯规则列表使用贝叶斯统计将预先挖掘的频繁模式组合成决策列表。使用预挖掘模式是许多规则学习算法常用的方法。
让我们从最简单的方法开始:使用单个最佳特征来学习规则。
4.5.1 从单个特征(OneR)学习规则
Holte(1993)提出的 OneR 算法是最简单的规则归纳算法之一。从所有特征中,OneR选择一个包含有关感兴趣结果的最多信息的特征,并从该特征创建决策规则。
尽管命名为OneR,代表“一条规则”,但是算法生成了不止一条规则:它实际上是所选最佳特征的每个唯一特征值的一条规则。一个更好的名字应该是一个特征。
算法简单快速:
通过选择适当的间隔来离散连续特征。
对于每个特征:
在特征值和(分类)结果之间创建交叉表。
对于特征的每个值,创建一个规则,预测具有此特定特征值(可以从交叉表中读取)的实例的最频繁类。计算特征规则的总错误。
选择总误差最小的特征。
OneR始终覆盖数据集的所有实例,因为它使用所选特征的所有级别。缺失值可以作为附加特征值处理,也可以预先输入。
OneR模型是一个只有一个拆分的决策树。拆分不一定像购物车中那样是二进制的,但取决于唯一特征值的数量。
让我们来看一个例子,OneR 是如何选择最佳特征的。下表显示了有关房屋的人工数据集,其中包含有关房屋价值、位置、大小以及是否允许养宠物的信息。我们有兴趣学习一个简单的模型来预测房子的价值。
| (地点)location | (大小)size | (宠物)pets | (价格)value |
|---|---|---|---|
| good | small | yes | high |
| good | big | no | high |
| good | big | no | high |
| bad | medium | no | medium |
| good | medium | only cats | medium |
| good | small | only cats | medium |
| bad | medium | yes | medium |
| bad | small | yes | low |
| bad | medium | yes | low |
| bad | small | no | low |
OneR 在每个特征和结果之间创建交叉表:
| value=low | value=medium | value=high | |
|---|---|---|---|
| location=bad | 3 | 2 | 0 |
| location=good | 0 | 2 | 3 |
| value=low | value=medium | value=high | |
|---|---|---|---|
| size=big | 0 | 0 | 2 |
| size=medium | 1 | 3 | 0 |
| size=small | 2 | 1 | 1 |
| value=low | value=medium | value=high | |
|---|---|---|---|
| pets=no | 1 | 1 | 2 |
| pets=only cats | 0 | 2 | 0 |
| pets=yes | 2 | 1 | 1 |
对于每一个特征,我们一行一行地遍历表:每个特征值都是规则的 IF部分;对于具有这个特征值的实例,最常见的类是预测,然后是规则的THEN部分。例如,大小特征与级别small,medium,big三个结果规则。对于每个特征,我们计算生成的规则的总错误率,即错误的总和。位置特征具有可能的值 bad和good。不良地段房屋最常见的价格是low,当我们用low作为预测时,我们会犯两个错误,因为两个房屋的价格是medium的。好地段的房屋预测价格很高,我们又犯了两个错误,因为两个房屋的价值medium。我们使用位置特征的误差是 4/10,对于尺寸特征是 3/10,对于宠物特征是 4/10。“size”特征生成误差最小的规则,并将用于最终的 OneR 模型:
IF size=small THEN value=small
IF size=medium THEN value=medium
IF size=big THEN value=high
OneR 喜欢具有许多可能级别的特征,因为这些特征可以更容易地覆盖目标。设想一个数据集,它只包含噪声,不包含信号,这意味着所有特征都具有随机值,并且对目标没有预测值。有些特征的级别比其他特征高。具有更多级别的特征现在可以更容易地过拟合。对于数据中的每个实例,具有单独级别的特征将完美地预测整个培训数据集。一种解决方案是将数据拆分为训练集和验证集,学习训练数据的规则,并评估在验证集上选择特征时的总错误。
领带是另一个问题,即当两个特征导致相同的总错误时。OneR 通过使用具有最小误差的第一个特征或具有卡方检验的最小 p 值的特征来解决关系。
例子
让我们用真实的数据来尝试一下 OneR。我们使用宫颈癌分类任务来测试 OneR 算法。将所有连续输入特征离散为 5 个分位数。将创建以下规则:
| (年龄)Age | (预测)prediction |
|---|---|
| (12.9,27.2] | Healthy |
| (27.2,41.4] | Healthy |
| (41.4,55.6] | Healthy |
| (55.6,69.8] | Healthy |
| (69.8,84.1] | Healthy |
OneR 选择年龄特征作为最佳预测特征。因为癌症是罕见的,所以对于每一个统治阶级来说,预测的标签总是健康的,这是相当没有帮助的。在这种不平衡的情况下使用标签预测是没有意义的。“年龄”间隔与癌症/健康之间的交叉表以及患癌症的妇女的百分比更能提供信息:
| # Cancer | # Healthy | P(Cancer) | |
|---|---|---|---|
| Age=(12.9,27.2] | 26 | 477 | 0.05 |
| Age=(27.2,41.4] | 25 | 290 | 0.08 |
| Age=(41.4,55.6] | 4 | 31 | 0.11 |
| Age=(55.6,69.8] | 0 | 1 | 0.00 |
| Age=(69.8,84.1] | 0 | 4 | 0.00 |
但是在您开始解释任何东西之前:因为每个特征和每个值的预测都是健康的,所以所有特征的总错误率都是相同的。默认情况下,通过使用错误率最低的特征中的第一个特征(这里,所有特征都有 55/858)来解决总错误中的关系,这恰好是年龄特征。
OneR 不支持回归任务。但是我们可以通过将连续结果分割成区间,将回归任务转化为分类任务。我们使用这个技巧通过将自行车的数量减少到四个四分位数(0-25%、25-50%、50-75%和 75-100%)来预测租赁自行车的数量。下表显示了安装 OneR 模型后所选的特征:
| 月份 | 预测 |
|---|---|
| 一月 | [22,3152] |
| 二月 | [22,3152] |
| 三月 | [22,3152] |
| 四月 | (3152,4548] |
| 五月 | (5956,8714] |
| 六月 | (4548,5956] |
| 七月 | (5956,8714] |
| 八月 | (5956,8714] |
| SEP | (5956,8714] |
| 十月 | (5956,8714] |
| 十一月 | (3152,4548] |
| 十二月 | [22,3152] |
所选特征是月份。月份特征有(哇!惊喜!)12 个特征级别,比大多数其他特征都要高。因此存在过拟合的危险。更乐观的一点是:月份特征可以处理季节性趋势(例如冬天租的自行车更少),而且预测似乎是明智的。
现在,我们从简单的 OneR 算法转移到一个更复杂的过程,使用由几个特征组成的条件更复杂的规则:顺序覆盖。
4.5.2 顺序覆盖
顺序覆盖是一个通用过程,它反复学习单个规则以创建一个决策列表(或集合),该决策列表(或集合)按规则覆盖整个数据集规则。许多规则学习算法是顺序覆盖算法的变体。本章介绍了主要的配方和使用开膛手,一个变种的顺序覆盖算法为例。
这个想法很简单:首先,找到一个适用于某些数据点的好规则。删除规则所涵盖的所有数据点。当条件适用时,不管这些点是否正确分类,都会覆盖数据点。重复规则学习和删除包含的点和剩余的点,直到不再留下点或满足另一个停止条件。结果是一个决策列表。这种重复规则学习和删除覆盖数据点的方法称为“分离和征服”。
假设我们已经有了一个算法,可以创建一个覆盖部分数据的规则。两个类(一个正类,一个负类)的顺序覆盖算法的工作原理如下:
从一个空的规则列表(rlist)开始。
学习规则 R。
当规则列表低于某个质量阈值(或正面示例未被覆盖)时:
将规则 R 添加到 rlist。
删除规则 R 涵盖的所有数据点。
学习其他有关剩余数据的规则。
返回决策列表。
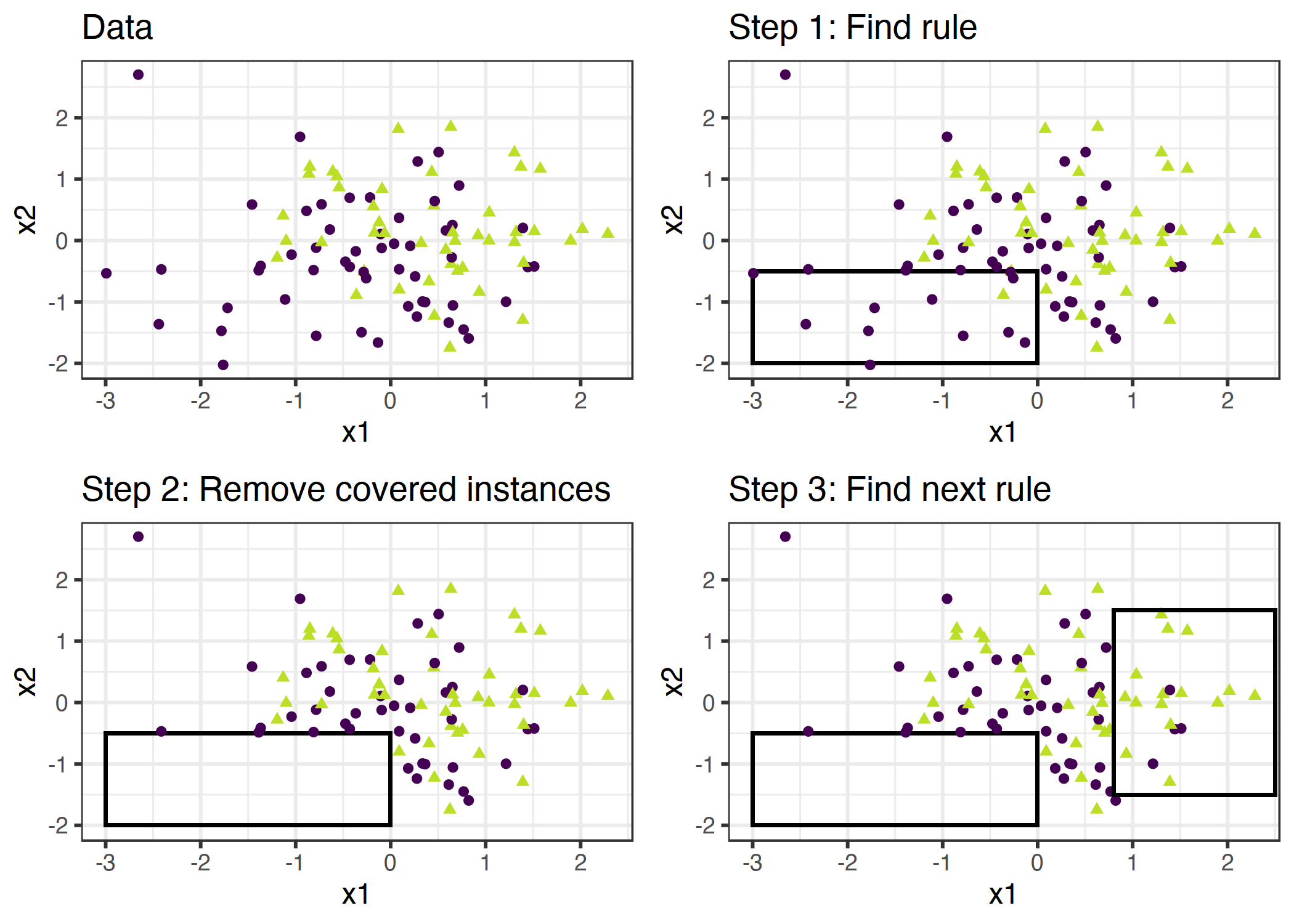
图 4.19:覆盖算法的工作原理是用单个规则依次覆盖特征空间,并删除那些规则已经覆盖的数据点。为了实现可视化,特征 x1 和 x2 是连续的,但是大多数规则学习算法都需要分类特征。
例如:我们有一个任务和数据集来预测房屋的大小、位置以及是否允许养宠物。我们学习了第一条规则,结果是:如果大小=大,位置=好,那么值=高。然后我们从数据集中删除所有位于良好位置的大房子。利用剩下的数据,我们学习下一个规则。可能:如果位置=好,则值=中。请注意,这条规则是在数据上学习的,在好的位置没有大房子,只留下中小型房子在好的位置。
对于多类设置,必须修改方法。首先,这些课程的顺序是随着流行率的增加。顺序覆盖算法从最小公共类开始,为其学习规则,删除所有覆盖的实例,然后转到第二个最小公共类,依此类推。当前班级始终被视为阳性班级,所有患病率较高的班级都被合并为阴性班级。最后一个类是默认规则。这在分类中也被称为一对一策略。
我们如何学习一条规则?OneR 算法在这里是无用的,因为它总是覆盖整个特征空间。但是还有很多其他的可能性。一种可能是通过梁搜索从决策树中学习单个规则:
学习决策树(使用购物车或其他树学习算法)。
从根节点开始,递归地选择最纯的节点(例如,具有较低的错误分类率)。
- 终端节点的大多数类用作规则预测;通向该节点的路径用作规则条件。
下图说明了树中的波束搜索:
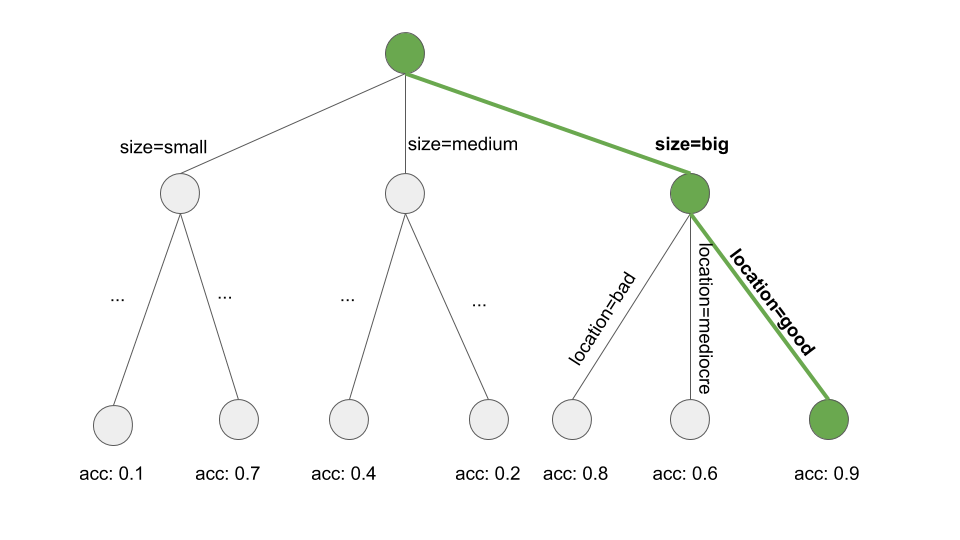
图 4.20:通过搜索决策树的路径来学习规则。发展决策树来预测感兴趣的目标。我们从根节点开始,贪婪地迭代地遵循本地生成最纯子集(例如,最高精度)的路径,并将所有拆分值添加到规则条件中。结果是: If location=good and size=big, then value=high。
学习单个规则是一个搜索问题,其中搜索空间是所有可能规则的空间。搜索的目标是根据某些条件找到最佳规则。有许多不同的搜索策略:爬山搜索,波束搜索,穷尽搜索,最佳优先搜索,有序搜索,随机搜索,自上而下搜索,自下而上搜索,…
Cohen(1995)的 RIPPER(重复增量修剪以减少误差)是顺序覆盖算法的一个变种。 RIPPER 有点复杂,它使用后处理阶段(规则修剪)来优化决策列表(或集合)。裂土器可以在有序或无序模式下运行,并生成决策列表或决策集。
示例
我们将使用 RIPPER 作为例子。
RIPPER算法在宫颈癌的分类任务中找不到任何规则。
当我们在回归任务中使用 RIPPER 来预测自行车数量时,我们发现了一些规则。由于裂土器只能用于分类,自行车计数必须转化为分类结果。我通过把自行车的数量减少到四分之一来达到这个目的。例如(4548, 5956)是覆盖 4548 和 5956 之间预测自行车数量的时间间隔。下表显示了已学习规则的决策列表。
| rules |
|---|
| (days_since_2011 >= 438) and (temp >= 17) and (temp <= 27) and (hum <= 67) => cnt=(5956,8714] |
| (days_since_2011 >= 443) and (temp >= 12) and (weathersit = GOOD) and (hum >= 59) => cnt=(5956,8714] |
| (days_since_2011 >= 441) and (windspeed <= 10) and (temp >= 13) => cnt=(5956,8714] |
| (temp >= 12) and (hum <= 68) and (days_since_2011 >= 551) => cnt=(5956,8714] |
| (days_since_2011 >= 100) and (days_since_2011 <= 434) and (hum <= 72) and (workingday = WORKING DAY) => cnt=(3152,4548] |
| (days_since_2011 >= 106) and (days_since_2011 <= 323) => cnt=(3152,4548] |
| => cnt=[22,3152] |
解释很简单:如果条件适用,我们可以预测右侧的自行车数量间隔。最后一个规则是当其他规则都不适用于实例时应用的默认规则。要预测新实例,请从列表顶部开始,检查规则是否适用。当一个条件匹配时,规则的右侧就是这个实例的预测。默认规则确保始终存在预测。
4.5.3 贝叶斯规则列表
在本节中,我将向您展示学习决策列表的另一种方法,它遵循以下粗略的方法:
从数据中预挖掘频繁的模式,这些模式可用作决策规则的条件。
从一系列预先挖掘的规则中学习决策列表。
使用此配方的特定方法称为贝叶斯规则列表(Letham 等人,2015 年)或简称为 BRL。BRL 使用贝叶斯统计从频繁模式中学习决策列表,这是 FP 树算法(Borgelt 2005)的前提。
但让我们从 BRL 的第一步慢慢开始。
频繁模式的预挖掘
频繁模式是特征值的频繁(共)出现。作为BRL 算法预处理步骤,我们使用特征(在这个步骤中我们不需要目标结果)并从中提取频繁发生的模式。模式可以是单个特征值(如size=medium)或特征值 size=medium AND location=bad的组合。
模式的频率是通过其在数据集中的支持来测量的:
$$
Support(xj=A)=\frac{1}n{}\sum{i=1}^nI(x^{(i)}_{j}=A)
$$
其中 a 是特征值,n 是数据集中的数据点数量,i 是如果实例 i 的特征x_j具有级别 a,则返回 1 的 indicator 函数,否则为 0。在房屋价值数据集中,如果 20%的房屋没有阳台,80%的房屋有一个或多个阳台,那么对模式阳台的支持为 20%。还可以测量特征值组合的支持,例如balcony=0 AND pets=allowed。
有许多算法可以找到这种频繁的模式,例如 Apriori 或 FP 增长。您使用的模式并不重要,只有找到模式的速度不同,但得到的模式总是相同的。
我将给你一个大致的概念,先验算法如何工作,以找到频繁的模式。实际上,Apriori 算法由两部分组成,第一部分查找频繁的模式,第二部分从中构建关联规则。对于 BRL 算法,我们只对 Apriori 第一部分中生成的频繁模式感兴趣。
在第一步中,Apriori 算法从所有支持大于用户定义的最小支持的特征值开始。如果用户说最小支持应该是 10%,只有 5%的房子的size=big,我们会删除这个特征值,只保留size=medium,size=small作为模式。这并不意味着房屋从数据中删除,它只是意味着size=big不会作为频繁模式返回。先验算法基于具有单个特征值的频繁模式,迭代地寻找越来越高阶的特征值组合。模式是通过将 feature=value 语句与逻辑 AND(例如,size=medium AND location=bad)相结合来构造的。将删除支持低于最小支持的生成模式。最后我们有了所有常见的模式。频繁模式的任何子集都会再次频繁出现,这称为 Apriori 属性。直观地说,它是有意义的:通过从模式中删除一个条件,简化的模式只能覆盖更多或相同数量的数据点,但不能少于。例如,如果 20%的房屋size=medium,location=good,那么只有size=medium的房屋的支撑为 20%或更大。Apriori 属性用于减少要检查的模式的数量。只有在频繁模式的情况下,我们必须检查高阶模式。
现在我们已经完成了贝叶斯规则列表算法的预挖掘条件。但在我们继续进行 BRL 的第二步之前,我想提示一下基于预先挖掘的模式的规则学习的另一种方法。其他方法建议将感兴趣的结果包含到频繁的模式挖掘过程中,并执行构建IF-THEN规则的 Apriori 算法的第二部分。由于该算法是无监督的,因此THEN部分还包含我们不感兴趣的特征值。但是我们可以通过规则过滤,这些规则在当时THEN部分中只具有感兴趣的结果。这些规则已经形成了一个决策集,但也可以对规则进行排列、删减、删除或重新组合。
然而,在 BRL 方法中,我们使用频繁的模式,学习然后的部分以及如何使用贝叶斯统计将模式安排到决策列表中。
学习贝叶斯规则列表
BRL 算法的目标是通过选择预先挖掘的条件来学习一个准确的决策列表,同时对规则较少、条件较短的列表进行优先级排序。BRL 通过定义决策列表的分布来实现这一目标,其中包含条件长度(最好是较短的规则)和规则数量(最好是较短的列表)的优先分布。
列表的后验概率分布使我们能够在假设短的情况下,以及列表与数据的匹配程度下,判断决策列表的可能性有多大。我们的目标是找到最大化后验概率的列表。由于无法直接从列表的分布中找到准确的最佳列表,BRL 建议采用以下方法:
1) 生成从先验分布中随机抽取的初始决策列表。
2) 通过添加、切换或删除规则来迭代修改列表,确保生成的列表允许列表的后分布。
3) 根据后验分布,从概率最高的抽样列表中选择决策列表。
让我们更仔细地研究一下算法:该算法从预先挖掘特征值模式开始,使用 fp 增长算法。BRL 对目标的分布和定义目标分布的参数的分布做了许多假设。(那是贝叶斯统计。)如果你不熟悉贝叶斯统计,不要太在意下面的解释。重要的是要知道贝叶斯方法是一种结合现有知识或需求(所谓的先验分布)的方法,同时也适合于数据。在决策列表的情况下,贝叶斯方法是有意义的,因为先前的假设用短规则推动决策列表变短。
目标是从后验分布中抽取决策列表 D:
$$ \underbrace{p(d|x,y,A,\alpha,\lambda,\eta)}{posteriori}\propto\underbrace{p(y|x,d,\alpha)}{likelihood}\cdot\underbrace{p(d|A,\lambda,\eta)}_{priori} $$ 其中,d 是决策列表,x 是特征,y 是目标,a 是预先挖掘的条件集,\lambda决策列表的先前预期长度,a 是规则中先前预期的条件数,a 是正类和负类的先前伪计数,其中最好固定在(1,1)。
$$ p(d|x,y,A,\alpha,\lambda,\eta) $$ 根据观察数据和先验假设,量化决策列表的可能性。这与给定决策列表和数据的结果 Y 的可能性成正比,乘以给定先前假设和预先挖掘条件的列表概率。 $$ p(y|x,d,\alpha) $$ 给定决策列表和数据,是观察到的 y 的可能性。brl 假设 y 由 Dirichlet 多项式分布生成。决策列表 D 解释数据越多,可能性越高。 $$ p(d|A,\lambda,\eta) $$ 是决策列表的优先分发。它将列表中规则数的截断泊松分布\lambda与规则条件中特征值数的截断泊松分布(参数\eta相乘。
如果一个决策列表能够很好地解释结果 Y,并且根据先前的假设,它具有很高的后验概率。
贝叶斯统计中的估计总是有点棘手,因为我们通常不能直接计算出正确的答案,但是我们必须绘制候选者,对他们进行评估,并使用马尔可夫链蒙特卡罗方法更新后验估计。对于决策列表,这更为棘手,因为我们必须从决策列表的分布中提取数据。BRL 的作者建议首先绘制一个初始决策列表,然后对其进行迭代修改,从列表的后分布(决策列表的马尔可夫链)中生成决策列表的样本。结果可能依赖于初始决策列表,因此建议重复此过程以确保列表的多样性。软件实现中的默认值是 10 次。以下配方告诉我们如何绘制初始决策列表:
带 FP 增长的矿前模式。
从截断的泊松分布中采样列表长度参数 m。
对于默认规则:对目标值的 Dirichlet 多项式分布参数\(\theta_0\)进行采样(即在没有其他应用时应用的规则)。
对于决策列表规则 j=1,…,m,做以下处理:
对规则 J 的规则长度参数 L(条件数)进行采样。
从预采条件中取样长度为(L_j)的条件。
对该部分的 Dirichlet 多项式分布参数进行抽样(即给定规则的目标结果的分布)
对于数据集中的每个观测:
从首先应用的决策列表中查找规则(从上到下)。
根据适用规则建议的概率分布(二项式)得出预测结果。
下一步是从这个初始样本开始生成许多新的列表,从决策列表的后分布中获取许多样本。
新的决策列表从初始列表开始取样,然后随机将规则移动到列表中的其他位置,或者从预先挖掘的条件向当前决策列表添加规则,或者从决策列表中删除规则。随机选择要切换、添加或删除的规则。在每个步骤中,该算法评估决策列表的后验概率(准确性和短性的混合)。大都会黑斯廷斯算法确保我们对具有高后验概率的决策列表进行抽样。这个过程为我们提供了许多来自决策列表分发的样本。BRL 算法选择后验概率最高的样本的决策列表。
示例
这就是理论,现在让我们看看 BRL 方法的实际应用。示例使用了 Yang 等人(2017)提出的一种更快的 BRL 变种,称为可伸缩贝叶斯规则列表(SBRL)。我们使用 SBRL 算法来预测宫颈癌风险。首先必须离散化所有输入特征,以便 SBRL 算法工作。为此,我将基于分位数值频率的连续特征组合起来。我们得到以下规则:
| rules |
|---|
| If {STDs=1} (rule[259]) then positive probability = 0.16049383 |
| else if {Hormonal.Contraceptives..years.=[0,10)} (rule[82]) then positive probability = 0.04685408 |
| else (default rule) then positive probability = 0.27777778 |
注意,我们得到了合理的规则,因为当时的预测部分不是类结果,而是癌症的预测概率。
这些条件是从使用FP增长算法预先挖掘的模式中选择的。下表显示了 SBRL 算法在构建决策列表时可以选择的条件池。在我作为用户允许的条件下,特征值的最大数目是 2。以下是十种图案的示例:
| pre-mined conditions |
|---|
| Num.of.pregnancies=[3.67,7.33) |
| IUD=0,STDs=1 |
| Number.of.sexual.partners=[1,10),STDs..Time.since.last.diagnosis=[1,8) |
| First.sexual.intercourse=[10,17.3),STDs=0 |
| Smokes=1,IUD..years.=[0,6.33) |
| Hormonal.Contraceptives..years.=[10,20),STDs..Number.of.diagnosis=[0,1) |
| Age=[13,36.7) |
| Hormonal.Contraceptives=1,STDs..Number.of.diagnosis=[0,1) |
| Number.of.sexual.partners=[1,10),STDs..number.=[0,1.33) |
| STDs..number.=[1.33,2.67),STDs..Time.since.first.diagnosis=[1,8) |
接下来,我们将 SBRL 算法应用到租赁自行车预测任务。只有当预测自行车数量的回归问题转化为二元分类任务时,这才有效。我随意创建了一个分类任务,创建了一个标签,如果一天的自行车数量超过 4000 辆,则为 1,否则为 0。
以下列表由 SBRL 学习:
| rules |
|---|
| If {yr=2011,temp=[-5.22,7.35)} (rule[718]) then positive probability = 0.01041667 |
| else if {yr=2012,temp=[7.35,19.9)} (rule[823]) then positive probability = 0.88125000 |
| else if {yr=2012,temp=[19.9,32.5]} (rule[816]) then positive probability = 0.99253731 |
| else if {season=SPRING} (rule[351]) then positive probability = 0.06410256 |
| else if {yr=2011,temp=[7.35,19.9)} (rule[730]) then positive probability = 0.44444444 |
| else (default rule) then positive probability = 0.79746835 |
让我们预测一下,2012 年,在 17 摄氏度的温度下,自行车的数量将超过 4000 辆。第一条规则不适用,因为它只适用于 2011 年的几天。第二条规则适用,因为这一天是在 2012 年,17 度是在时间间隔[7.35,19.9]。我们对这种可能性的预测是超过 4000 辆自行车的出租率是 88%。
4.5.4 优势
本节一般讨论 IF-THEN规则的好处。
如果-那么规则很容易解释。它们可能是可解释模型中最容易解释的。此声明仅适用于规则数量较少、规则条件较短(最多 3 个)以及规则组织在决策列表或不重叠的决策集中的情况。
决策规则可以像决策树那样具有表现力,同时更紧凑。决策树通常也会遭受复制的子树,也就是说,当左子节点和右子节点中的拆分具有相同的结构时。
使用 IF-THEN 规则的预测很快,因为只需要检查几个二进制语句就可以确定哪些规则适用。
决策规则对于输入特征的单调变换具有很强的鲁棒性,因为条件中只有阈值会发生变化。它们对于异常值也很健壮,因为它只在条件适用或不适用时才重要。
IF-THEN 规则通常生成稀疏模型,这意味着不包含许多特征。它们仅为模型选择相关特征。例如,默认情况下,线性模型为每个输入特征指定权重。不相关的特征可以简单地被 IF-THEN 规则忽略。
像来自 OneR 这样的简单规则可以用作更复杂算法的基线。
4.5.5 缺点
本节一般讨论 IF-THEN 规则的缺点。
关于 IF-THEN 规则的研究和文献主要集中在分类上,几乎完全忽略了回归。虽然你可以将一个连续的目标划分为间隔,并将其转化为分类问题,但你总是会丢失信息。一般来说,如果方法可以同时用于回归和分类,则更具吸引力。
这些特征通常也必须是分类的。这意味着如果要使用数字特征,必须对它们进行分类。有很多方法可以将一个连续的特征分割成间隔,但这并不是一件微不足道的事情,并且会带来许多没有明确答案的问题。该特征应划分为多少个间隔?分割标准是什么:固定的间隔长度、分位数或其他什么?对连续特征进行分类是一个经常被忽视的问题,人们只使用下一个最佳方法(就像我在示例中所做的那样)。
许多旧的规则学习算法容易过度拟合。这里给出的算法都至少有一些保护措施来防止过拟合:OneR 是有限的,因为它只能使用一个特征(只有当特征具有太多的级别或有许多特征时才有问题,这等同于多个测试问题),ripper 进行修剪和间隔 ESIA 规则列表对决策列表施加了优先分布。
在描述特征和输出之间的线性关系时,决策规则是不好的。这是他们与决策树共享的问题。决策树和规则只能产生阶跃预测函数,其中预测的变化总是离散的阶跃,而不是平滑的曲线。这与输入必须是分类的问题有关。在决策树中,它们通过拆分来隐式分类。
4.5.6 软件和备选方案
在 R package OneR中实现了 OneR,本书中的示例使用了 OneR。OneR 也可以在 Java、R 和 Python 中的Weka machine learning library实现。RIPPER也在 Weka中实现。对于这些示例,我在 RWeka package中使用了JRIP 的R 实现,SBRL在R package(我在示例中使用的), Python或 C implementation中都是可使用的。
我甚至不会列出学习决策规则集和列表的所有备选方案,而是指出一些总结工作。我推荐 Fuernkranz 等人(2012 年)的《规则学习的基础》一书,这是一本关于学习规则的广泛著作,适用于那些想深入研究该主题的人。它为思考学习规则提供了一个整体框架,并提出了许多规则学习算法。我还建议查看Weka rule learners,它实现了 RIPPER, M5Rules, OneR, PART等等其他更多。 IF-THEN 规则可以用在线性模型中,如本书中 关于RuleFit algorithm的内容。
Holte, Robert C. “非常简单的分类规则在大多数常用数据集上表现良好。”
Machine learning 11.1 (1993): 63-90.↩
Cohen, William W.”快速有效的规则归纳。“Machine Learning Proceedings (1995). 115-123.↩
Letham, Benjamin, et al.”使用规则和贝叶斯分析的可解释的分类器: 创建一个更好的中风预测模型。”The Annals of Applied Statistics 9.3 (2015): 1350-1371.↩
Borgelt, C. “一个FP增长算法的实现。”Proceedings of the 1st International Workshop on Open Source Data Mining Frequent Pattern Mining Implementations - OSDM ’05, 1–5. http://doi.org/10.1145/1133905.1133907 (2005).↩
Yang, Hongyu, Cynthia Rudin, and Margo Seltzer.“可扩展的贝叶斯规则列表。”Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.↩
Fürnkranz, Johannes, Dragan Gamberger, and Nada Lavrač. “规则学习基础。”Springer Science & Business Media, (2012).↩
4.6 规则拟合
Friedman 和 Popescu(2008)的 RuleFit 算法学习稀疏线性模型,其中包括以决策规则形式自动检测到的交互效应。
线性回归模型不考虑特征之间的相互作用。拥有一个像线性模型一样简单和可解释的模型,同时又集成了特征交互,这难道不方便吗?RuleFit 填补了这个空白。RuleFit 学习具有原始特征的稀疏线性模型,以及许多新的特征,这些特征是决策规则。这些新特征捕获原始特征之间的交互。RuleFit 自动从决策树生成这些特征。通过将拆分的决策组合成规则,可以将树中的每条路径转换为决策规则。节点预测将被丢弃,决策规则中仅使用拆分:

图 4.21:4 规则可以从具有 3 个终端节点的树中生成。
这些决策树来自哪里?这些树被训练来预测感兴趣的结果。这样可以确保分割对预测任务有意义。任何生成大量树的算法都可以用于规则拟合,例如随机林。每棵树被分解成决策规则,作为稀疏线性回归模型(Lasso)中的附加特征。
RuleFit 论文使用波士顿住房数据来说明这一点:目的是预测波士顿社区的房屋价值中位数。RuleFit 生成的规则之一是:IF房间数>6.64AND一氧化氮浓度<0.67,THEN 1 ELSE 0。
RuleFit 还提供了一个特征重要性度量,有助于识别对预测很重要的线性项和规则。根据回归模型的权重计算特征重要性。重要性度量可以针对原始特征进行聚合(这些特征以“原始”形式使用,并且可能在许多决策规则中使用)。
RuleFit 还引入了部分相关图,通过改变特征来显示预测的平均变化。偏相关图是一种模型不可知论方法,可用于任何模型,并在
4.6.1 解释和示例
由于 RuleFit 最终估计了一个线性模型,所以解释与”普通的”线性模型相同。唯一的区别是该模型具有从决策规则派生的新特征。决策规则是二进制特征:值 1 表示满足规则的所有条件,否则值为 0。对于规则拟合中的线性项,其解释与线性回归模型中的解释相同:如果特征增加一个单位,则预测的结果将根据相应的特征权重变化。
在这个例子中,我们使用 RuleFit 来预测给定日期租赁自行车的数量。该表显示了 RuleFit 生成的五个规则,以及它们的套索权重和重要性。计算将在本章后面解释。
| (描述)Description | (权重)Weight | (重要性)Importance |
|---|---|---|
| days_since_2011 > 111 & weathersit in (“GOOD”, “MISTY”) | 793 | 303 |
| 37.25 <= hum <= 90 | -20 | 272 |
| temp > 13 & days_since_2011 > 554 | 676 | 239 |
| 4 <= windspeed <= 24 | -41 | 202 |
| days_since_2011 > 428 & temp > 5 | 366 | 179 |
最重要的规则是:“自 2011 年 11 月 11 日起的天数和天气状况”(“好”,“雾”),相应的重量为 793。其解释是:如果自 2011 年以来的天数大于 111 天且天气状况稳定(“良好”,“雾状”),那么当所有其他特征值保持不变时,预测的自行车数量将增加 793 辆。总共有 278 个规则是根据最初的 8 个特征创建的。相当多!但多亏了Lasso,278 只中只有 58 只的体重与 0 不一样。
计算全局特征重要性表明,温度和时间趋势是最重要的特征:
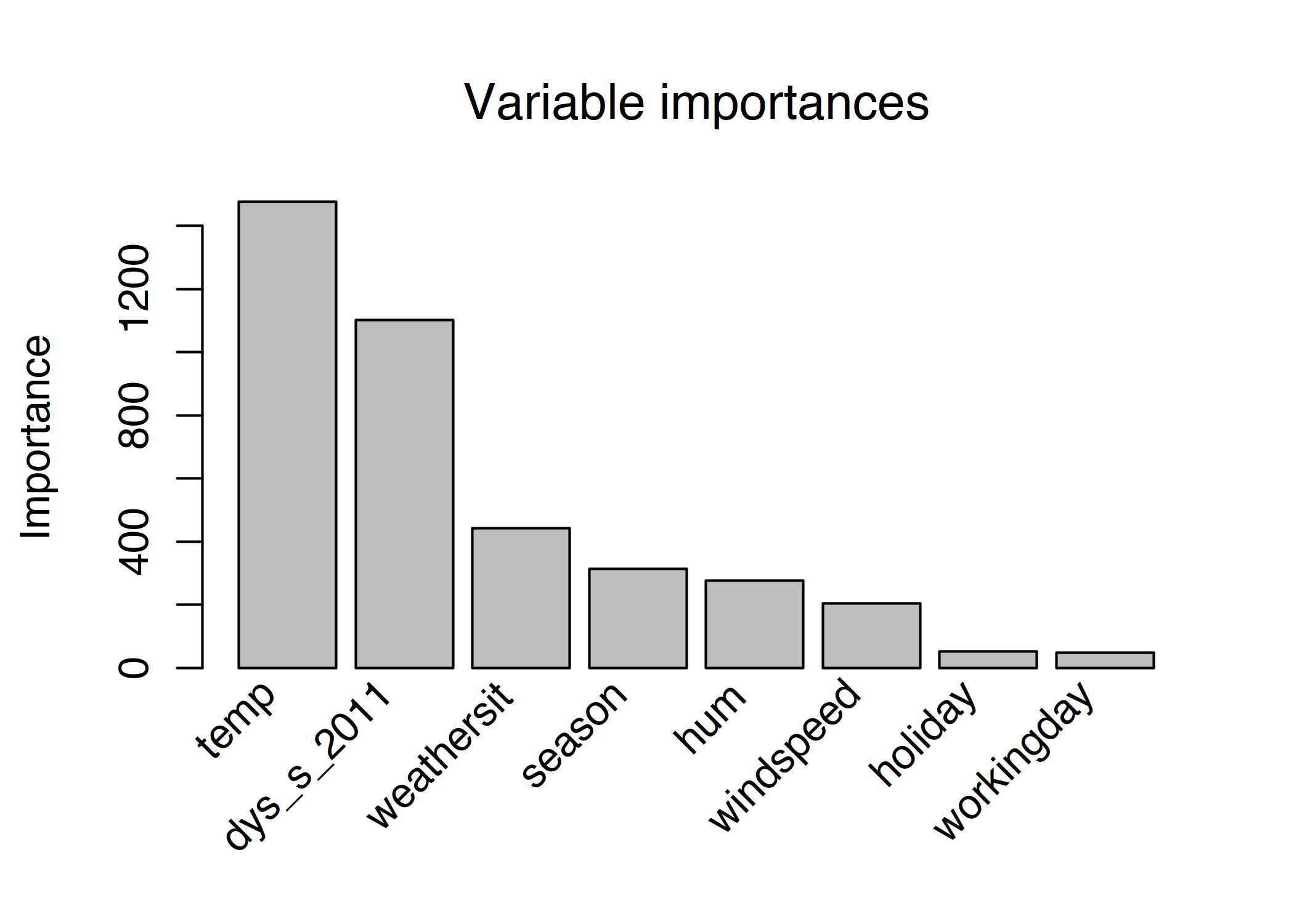
图 4.22:预测自行车数量的规则拟合模型的特征重要性度量。预测的最重要特征是温度和时间趋势。
特征重要性度量包括原始特征项的重要性和特征出现的所有决策规则。
解释模板
这种解释类似于线性模型:如果一个单元的特征x_j发生变化,则预测结果 β_j会发生变化,前提是所有其他特征保持不变。决策规则的权重解释是一种特殊情况:如果一个决策规则的所有条件r_k都适用,那么预测的结果会改变(在线性模型中规则r_k的已知权重)。
对于分类(使用逻辑斯蒂回归而不是线性回归):如果决策规则的所有条件都适用α_k,则事件与无事件的概率会变化一个α_k系数。
4.6.2 理论
让我们深入研究 RuleFit 算法的技术细节。RuleFit 由两个组件组成:第一个组件从决策树创建“规则”,第二个组件使用原始特征和新规则作为输入来适应线性模型(因此称为“RuleFit”)。
步骤 1:规则生成
规则是什么样子的?算法生成的规则具有简单的形式。例如:如果 x2<3 和x5<7,则为 1,否则为 0。这些规则是通过分解决策树来构建的:到树中节点的任何路径都可以转换为决策规则。规则中使用的树被拟合来预测目标结果。因此,对分割和结果规则进行了优化,以预测您感兴趣的结果。您只需将导致某个节点的二进制决策与“AND”链接起来,voilà,您就有了一个规则。人们希望能制定出许多多样而有意义的规则。梯度增强用于通过回归或分类 Y 来适应一组决策树,使用您的原始特征 X。每个结果树被转换成多个规则。不仅可以增强树,而且可以使用任何树集成算法来生成树以进行规则拟合。树系综可以用以下一般公式来描述:
$$ f(x)=a0+\sum{m=1}^M{}a_m{}f_m(X) $$ m 是树的数目,而T_m是 m-树的预测函数。 α’s 是权重。袋装套装、随机森林、Adaboost 和 Mart 生产树套装,可用于规则拟合。
我们从合奏的所有树中创造出规则。每个规则(r_m)的形式如下:
$$ rm(x)=\prod{j\in\text{T}m}I(x_j\in{}s{jm}) $$ 其中T_m是 m-th 树中使用的一组特征,I是当特征x_j位于 j-th 特征的指定值子集(由树拆分指定)中时为 1 的指标函数,否则为 0。对于数字特征,是特征值范围内的间隔。间隔看起来像两种情况之一:
$$ x{s{jm},\text{lower}}<x_j $$
$$ xj<x{s_{jm},upper} $$
该特征的进一步分割可能导致更复杂的间隔。对于分类特征,子集 S 包含特征的某些特定类别。
自行车租赁数据集的组成示例:
$$ r{17}(x)=I(x{\text{temp}}<15)\cdot{}I(x{\text{weather}}\in{\text{good},\text{cloudy}})\cdot{}I(10\leq{}x{\text{windspeed}}<20) $$ 如果满足所有三个条件,则此规则返回 1,否则返回 0。RuleFit 从树中提取所有可能的规则,而不仅仅是从叶节点中。因此,另一个将要创建的规则是:
$$ r{18}(x)=I(x{\text{temp}}<15)\cdot{}I(x_{\text{weather}}\in{\text{good},\text{cloudy}} $$ 总的来说,由 m 树和t_m终端节点组成的集合所创建的规则数为:
$$ K=\sum_{m=1}^M2(t_m-1) $$
RuleFit 作者引入的一个技巧是学习具有随机深度的树,以便生成许多具有不同长度的不同规则。注意,我们丢弃每个节点中的预测值,只保留将我们引导到节点的条件,然后从中创建规则。决策规则的权重在 RuleFit 的步骤 2 中进行。
另一种查看步骤 1 的方法:RuleFit 从原始特征生成一组新特征。
这些特征是二进制的,可以表示原始特征的非常复杂的交互。选择规则最大化预测任务。规则是从协变量矩阵 X 自动生成的。您可以简单地将规则视为基于原始特征的新特征。
第二步:稀疏线性模型
在步骤 1 中有很多规则。由于第一步只能被视为特征转换,因此您仍然没有完成模型的拟合。此外,您还希望减少规则的数量。除了规则之外,原始数据集中的所有“原始”特征也将用于稀疏线性模型。每一条规则和每一个原始特征都成为线性模型中的一个特征,并得到一个权重估计。添加原始特征是因为树在表示 y 和 x 之间的简单线性关系时失败。在训练稀疏线性模型之前,我们先对原始特征进行缩尾调整,以便它们对异常值更为强大: $$ l_j^*(x_j)=min(\delta_j^+,max(\delta_j^-,x_j)) $$ 其中\delta_j^-和\delta_j^+是特征x_j的数据分布的δ分位数。选择 0.05 代表δ意味着在 5%最小值或 5%最大值中的任何特征值x_j将分别设置为 5%或 95%的分位数。根据经验,您可以选择δ=0.025。此外,必须对线性项进行归一化,使其具有与典型决策规则相同的优先重要性:
$$ l_j(x_j)=0.4\cdot{}l^_j(x_j)/std(l^_j(x_j)) $$ 0.4是规则的平均标准偏差,统一支持分布为 s_k∼U(0,1)。
我们结合这两种特征生成新的特征矩阵,并用Lasso 训练稀疏线性模型,其结构如下:
$$ ^f(x)=^β0+K∑k=1^αkrk(x)+p∑j=1^βjlj(xj) $$ 其中^αα^ 是规则特征的估计权重向量,而 ^ββ^是原始特征的权重向量。由于 RuleFit 使用 Lasso,因此 loss 函数将获得额外的约束,强制某些权重获得零估计:
$$ ({\hat{\alpha}}1^K,{\hat{\beta}}_0^p)=argmin{{\hat{\alpha}}1^K,{\hat{\beta}}_0^p}\sum{i=1}^n{}L(y^{(i)},f(x^{(i)}))+\lambda\cdot\left(\sum{k=1}^K|\alpha_k|+\sum{j=1}^p|b_j|\right) $$
结果是一个线性模型,对所有原始特征和规则都有线性影响。与线性模型的解释相同,唯一的区别是一些特征现在是二进制规则。
步骤 3(可选):特征重要性
对于原始特征的线性项,使用标准化预测因子测量特征重要性:
$$ I_j=|\hat{\beta}_j|\cdot{}std(l_j(x_j)) $$ 其中,β_j 是来自 Lasso 模型的权重,std(lj(xj))是线性项相对于数据的标准偏差。
对于决策规则术语,重要性的计算公式如下:
$$ I_k=|\hat{\alpha}_k|\cdot\sqrt{s_k(1-s_k)} $$ 其中\hat{\alpha}_k是决策规则的关联 Lasso 权重,而s_k是数据中特征的支持,这是决策规则适用的数据点的百分比(其中r_k(x)=0):
$$ sk=\frac{1}{n}\sum{i=1}^n{}r_k(x^{(i)}) $$ 一个特征作为一个线性项出现,也可能出现在许多决策规则中。我们如何衡量特征的总体重要性?一个特征的重要性J_j(x) 可以为每个单独的预测进行测量:
$$ Jj(x)=I_j(x)+\sum{x_j\in{}r_k}I_k(x)/m_k $$ 其中,I_l是线性项的重要性,以及I_k决策规则的重要性,其中x_j出现,并且m_k是构成规则的特征数r_k。从所有实例中添加特征重要性可以使我们获得全局特征重要性:
$$ Jj(X)=\sum{i=1}^n{}J_j(x^{(i)}) $$ 可以选择实例的子集并计算此组的特征重要性。
4.6.3 优势
RuleFit 自动将特征交互添加到线性模型中。因此,它解决了线性模型的问题,需要手动添加交互项,这对非线性关系的建模有一定帮助。
RuleFit 可以处理分类和回归任务。
创建的规则易于解释,因为它们是二元决策规则。规则是否适用于实例。只有规则中的条件数量不太多,才能保证良好的解释性。我觉得有 1 到 3 个条件的规则是合理的。这意味着树群中树的最大深度为 3。
即使模型中有许多规则,它们也不适用于每个实例。对于个别情况,只有少数规则适用(=具有非零权重)。这提高了本地的可解释性。
RuleFit 提出了一系列有用的诊断工具。这些工具是模型不可知论的,所以您可以在本书的模型不可知论部分找到它们:feature importance, partial dependence plots 和 feature interactions.。
4.6.4 缺点
有时 RuleFit 会创建许多规则,在 Lasso 模型中获得非零权重。随着模型中特征数量的增加,解释性降低。一个有希望的解决方案是强制特征效果是单调的,这意味着特征的增加必须导致预测的增加。
一个奇闻轶事的缺点:论文声称规则拟合的良好性能——通常接近于随机森林的预测性能!–但在我亲自尝试的少数案例中,表现令人失望。只需针对您的问题尝试一下,看看它是如何工作的。
RuleFit 过程的最终产物是一个具有额外的花哨特征(决策规则)的线性模型。但由于它是一个线性模型,因此权重解释仍然是非确定性的。它和通常的线性回归模型一样带有相同的“脚注”:“……假设所有的特征都是固定的。”当你有重叠的规则时,它会变得更加复杂。例如,自行车预测的一个决策规则(特征)可能是:“temp>10”,另一个规则可能是“temp>15&weather=’good’”。如果天气好,温度在 15 度以上,温度自动高于 10 度。在第二条规则适用的情况下,第一条规则也适用。对第二条规则的估计重量的解释是:“假设所有其他特征保持不变,当天气好,温度超过 15 度时,预测的自行车数量增加了”(β2)。但是,现在很明显,“所有其他特征都是固定的”是有问题的,因为如果规则 2 适用,规则 1 也适用,并且解释是无意义的。
4.6.5 软件和备选方案
RuleFit 算法由 Fokkema 和 Christoffersen(2017)在 R 中实现,您可以找到Python version on Github。
一个非常相似的框架是skope-rules,一个 也可以从集合中提取规则python 模块。它在学习最终规则的方式上有所不同:首先,skope 规则根据回忆和精度阈值删除性能低下的规则。然后,根据逻辑项(变量+大/小运算符)的多样性和规则的性能(F1 分数)执行选择,删除重复的和类似的规则。最后一步并不依赖于使用 Lasso,而是只考虑现成的 F1 分数和构成规则的逻辑术语。
Friedman、Jerome H 和 Bogdan E Popescu。“通过规则集合进行预测性学习。”应用统计学的名称。JSTOR,916–54。(2008 年)。↩
Fokkema、Marjolein 和 Benjamin Christoffersen。“预:预测规则集合”。https://CRAN.R-project.org/package=pre(2017 年)。↩
4.7 其他可解释模型
可解释模型的列表不断增长,而且规模未知。它包括简单的模型,如线性模型、决策树和朴素贝叶斯,但也包括更复杂的模型,这些模型结合或修改了不可解释的机器学习模型,使它们更易于解释。尤其是后一类模型的出版物目前正以高频率出版,很难跟上发展的步伐。这本书在这一章只取笑朴素的贝叶斯分类器和K近邻。
4.7.1 朴素贝叶斯分类器
朴素贝叶斯分类器使用条件概率的贝叶斯定理。对于每个特征,它根据特征值计算类的概率。Naive Bayes分类器独立地计算每个特征的类概率,这相当于特征独立性的强(=naive)假设。Naive Bayes 是一个条件概率模型,它对类c_k的概率建模如下:
$$ P(Ck|x)=\frac{1}{Z}P(C_k)\prod{i=1}^n{}P(x_i|C_k) $$ 术语 Z 是一个比例参数,它确保所有类的概率之和为 1(否则它们将不是概率)。类的条件概率是类概率乘以给定类的每个特征的概率,用 z 归一化。这个公式可以用贝叶斯定理导出。
由于独立性假设,朴素贝叶斯是一个可解释的模型。它可以在模块级别上解释。对于每个特征来说,它对某个类预测的贡献是非常明显的,因为我们可以解释条件概率。
4.7.2 K近邻
K近邻法可用于回归和分类,并利用数据点的最近邻进行预测。对于分类,k-最近邻方法为实例的最近邻分配最常见的类。对于回归,它取邻居结果的平均值。棘手的部分是找到正确的 k 并决定如何测量实例之间的距离,这最终定义了邻域。
K近邻模型不同于本书提出的其他可解释模型,因为它是一种基于实例的学习算法。如何解释 K近邻?
首先,没有要学习的参数,所以在模块级别上没有可解释性。
此外,由于模型本身是局部的,没有显式学习的全局权重或结构,因此缺乏全局模型的可解释性。也许在地方一级可以解释?要解释预测,您总是可以检索用于预测的 k 个邻居。模型是否可解释完全取决于您能否“解释”数据集中的单个实例。如果一个实例包含成百上千个特征,那么它就不可解释了,我会争辩。但是,如果您没有一些特征或将实例简化为最重要的特征的方法,那么展示 K近邻可以为您提供很好的解释。

若有收获,就点个赞吧
0 人点赞
