第一章 引言
这本书向你解释了如何使(监督)机器学习模型可解释。本章包含一些数学公式,但即使没有公式,您也应该能够理解这些方法背后的思想。这本书不适合那些机器学习的初学者。如果你对机器学习不熟悉,有很多书和其他资源可以学习基础知识。我推荐 Hastie, Tibshirani, and Friedman (2009 年)的《统计学习要素》$^1$一书以及Andrew Ng 的机器学习在线课程,从在线学习平台 coursera.com 从机器学习开始。这本书和这门课程都是免费的!
机器学习模型解释的新方法以惊人的速度发表。要跟上发表的所有文章都是不可思议的,根本不可能。这就是为什么你在这本书中找不到最新颖和最奇特的方法,而是建立了机器学习可解释性的方法和基本概念。这些基础知识使您能够理解机器学习模型。将基本概念消化后,可以使你在开始阅读这本书的 5 分钟内,能够更好地理解和评价任何在arxiv.org上的最新关于可解释性文章(我可能夸大了发表速度)。
这本书开始于一些(反乌托邦)的小故事,不需要理解这本书,但希望你开心和并令你思考。然后这本书开始探讨机器学习解释性的概念。我们将讨论可解释性何时重要以及有哪些不同类型的解释。书中使用的术语可以在术语章中查找。大多数解释的模型和方法都是用在数据章中真实的数据来表示的。使机器学习可解释的一种方法是使用可解释的模型,即使用线性模型或决策树。另一种方法是使用不可知的解释工具,可以应用于任何监督机器学习模型。模型不可知论方法一章论述了偏相关图和排序特征重要性等方法。模型不可知方法通过改变机器学习模型的输入和计算预测输出的变化来工作。返回数据实例作为解释的模型不可知方法将在基于示例的说明这章讨论。所有模型不可知方法都可以根据它们是解释所有数据实例的全局模型行为还是单个预测来进一步区分。以下方法解释了模型的整体行为:部分依赖图、累积局部效应、特征交互、特征重要性、全局代理模型和原型与批评。一些方法可用于解释全局模型行为和单个预测的两个方面:个人条件期望与影响实例。
本书以对可解释机器学习的未来可能看起来如何的乐观展望结束。
你可以从头到尾阅读这本书,也可以直接跳到你感兴趣的方法上。
我希望你会喜欢这本书!
$^1$ 弗里德曼、杰罗姆、特雷弗·黑斯迪和罗伯特·提比西拉尼。“统计学习要素”。www.web.stanford.edu/~hassie/elemstatlearn/(2009 年)。
1.1 故事时间
我们将从一些短篇故事开始。每个故事都是对可解释机器学习的夸张表现。如果你赶时间,你可以跳过它们。如果你想为此产生兴趣和(失去)动力,继续读下去!
该排版的灵感来自杰克 克拉克在他的Import AI Newsletter。如果你喜欢这种故事,或者你对人工智能感兴趣,我建议你注册。
闪电从不打两次
2030 年:瑞士医学实验室

“这绝对不是最糟糕的死法!“汤姆总结了一下,试图在负面的事情中找到一些正面的东西。他从静脉输液管上取下了泵。 “他是因为错误而死的,”莉娜补充说。 “当然是用错了吗啡泵!为我们增大了工作量!“汤姆一边抱怨一边拧下泵的后板。拆下所有的螺丝后,他把盘子举起放在一边。他把电缆插入诊断端口。 “你不只是抱怨工作量,是吗?“莉娜嘲笑他。“当然不是。从未!”他用讽刺的语气喊道。
他启动了水泵的计算机。 莉娜把电缆的另一端插入平板电脑。“好吧,诊断正在运行。”她说,“我真的很好奇出了什么问题。” “它确实为 John Doe 进行了注射 Nirvana。高浓度的吗啡。伙计。我是说…这是第一次,对吧?通常情况下,一个坏泵会释放出太少的甜味或者没有味道。但是,你知道,从来没有像那疯狂的射击那样,”汤姆解释说。 “我知道。你不必说服我……嘿,看看那个。”莉娜举起她的平板电脑。”你看到这里的峰值了吗?这就是止痛药混合物的功效。看!这一行显示参考水平。” 这个可怜的家伙在他的血液系统中混合了止痛药,可以杀死他 17 次以上。用我们的泵注射。在这里……”她侧身,“在这里你可以看到病人死亡的那一刻。” “那么,知道发生了什么事吗,老板?“汤姆问他的上司。 “嗯……传感器看起来不错。心率、含氧量、葡萄糖等数据按预期收集。血氧数据中有些缺失值,但这并不罕见。看这里。传感器还检测到病人心率减慢,以及吗啡衍生物和其他止痛药导致的皮质醇水平极低。”她继续浏览诊断报告。 汤姆被屏幕迷住了。这是他第一次调查真正的设备故障。
“好吧,这是我们的第一块拼图。系统未能向医院的通信通道发送警告。警告已触发,但在应急方案未响应。可能是我们的错,也可能是医院的错。请将日志发送给 IT 团队,”莉娜告诉汤姆。 汤姆点了点头,眼睛仍然盯着屏幕。 莉娜继续说:“真奇怪。警告也应导致泵关闭。但显然没有这样做。那一定是个 bug。质检团队错过了一些东西。真的很糟糕。可能与应急方案有关。” “所以,泵的紧急系统不知怎么地坏了,但是为什么泵会充满香蕉,给 John Doe 注射那么多止痛药呢?“汤姆想知道。 “好问题。你是对的。除了应急方案发生故障外,泵不应该使用那么多的药物。考虑到皮质醇和其他警告信号的水平较低,该算法应该提前停止。 “也许是运气不好,比如百万分之一的运气,像被闪电击中?“汤姆问她。“不,汤姆。如果你阅读过我发给你的文件,你就会知道这个泵首先是在动物实验中测试的,然后是在人类身上测试的,以学习根据感觉输入来注射完美数量的止痛药。泵的算法可能是不透明且复杂的,但不是随机的。这意味着在同样的情况下,泵的工作原理会完全相同。我们的病人会再次死亡。感官输入的组合或不期望的交互作用一定触发了泵的错误行为。这就是为什么我们必须深入挖掘,找出这里发生的事情,”莉娜解释说。
“我明白了……”,汤姆回答,陷入沉思。“病人不是很快就会死吗?因为癌症还是什么?“ 莉娜边看分析报告边点头。 汤姆站起来走到窗前。他向外看,眼睛盯着远处的一个点。 “也许机器帮了他一个忙,让他摆脱痛苦。不再受苦。也许它只是做了正确的事,就像闪电,但是,你知道,一个好闪电。我的意思是喜欢彩票,但不是随机的。但出于某种原因。如果我是泵,我也会这样做的。”她最后抬起头看着他。 他一直在看外面的东西。 两人都沉默了一会儿。 莉娜又低下头继续分析。“不,汤姆。这是一只 bug……只是一只该死的 bug。
信任倒下
2050 年:新加坡的地铁站

她赶到璧山地铁站。按照她的想法,她已经在工作了。新的神经架构的测试现在应该已经完成了。她领导重新设计了政府的“个人实体纳税亲和力预测系统”,该系统预测一个人是否会向税务局隐瞒资金。她的团队想出了一个优雅的想法。如果成功,该系统不仅可以为税务局服务,还可以提供给其他系统,如反恐警报系统和商业登记处。有一天,政府甚至可以将这些预测纳入公民信任评分。公民信任评分评估一个人的可信度。这个估计会影响到每个人日常生活的每一部分,比如贷款或者要等多久才能拿到新护照。当她走下扶梯时,她想象着她的团队系统与公民信任评分系统的整合会是怎样的。
她经常在不降低行走速度的情况下用手擦拭 RFID 阅读器。她的思绪被占据了,但是感官期望和现实的不一致在她的大脑中敲响了警钟。
太晚了。
她先是鼻子撞上地铁入口大门,然后屁股先倒在地上。门本来应该开的,…但它没有。她目瞪口呆地站起来,看着门旁边的屏幕。“请再试一次,”屏幕上一个友好的笑脸建议道。一个人路过却无视她,把他的手覆盖在读取系统上。门开了,他进去了。门又关上了。她擦了擦鼻子。它受伤了,但至少没有流血。她试图开门,但又被拒绝了。这很奇怪。也许她的公共交通账户没有足够的代币。她用智能手表查看帐户余额。
“登录被拒绝。请联系您的公民咨询局!“她的手表告知她。
恶心的感觉像拳头打在她的肚子上。她怀疑是发生了什么事。为了证实她的想法,她启动了移动游戏“狙击手协会”,一个自我射击。应用程序又自动关闭了,这证实了她的想法。她头晕目眩,再次坐在地板上。
只有一个可能的解释:她的公民信任分数下降了。基本上。小幅度的下降意味着一些小的不便,比如没有头等舱的航班,或者需要等待更长的时间才能获得官方文件。低信任度的分数是少见的,这意味着你被列为对社会是有威胁的。对付这些人的一个措施是让他们远离公共场所,比如地铁。政府限制公民信任分数低的受试者的金融交易。他们也开始积极监控你在社交媒体上的行为,甚至限制某些内容,比如暴力游戏。你的公民信任分数越低,就越难增加公民信任分。得分很低的人通常不会恢复原来分数。
她想不出任何理由为什么她的分数会下降。该分数基于机器学习。公民信任评分系统就像一台运转良好的发动机,为社会服务。信任评分系统的绩效始终受到密切监控。自本世纪初以来,机器学习变得越来越好。它变得如此有效,以至于信任评分系统做出的决定不再有争议。一个可靠的系统。
她绝望地笑了。可靠的系统。只要,系统很少出故障。但失败了。她一定是那些特殊情况中的一个;系统错误;从现在起,她就成了被抛弃的人。没有人敢质疑这个系统。它过于融入了政府,融入了社会,这是不可质疑的。在仅存的少数几个民主国家,禁止开展反民主运动,不是因为这些国家在本质上是恶意的,而是因为它们会破坏现有制度的稳定。同样的逻辑也适用于现在更常见的算法。由于对现状的危险,禁止对算法进行批判。
算法信任是社会秩序的结构。为了共同的利益,少见的虚假信任评分被默认接受。成百上千的其他预测系统和数据库输入了分数,使得无法得知是什么导致了她的分数下降。她觉得自己身下有一个巨大的黑洞,她惊恐地看着空虚。
她的税收亲和系统最终被纳入公民信托评分系统,但她一直不知道。
费米的回形针
612 年(火星定居后):火星博物馆
![img]I(https://christophm.github.io/interpretable-ml-book/images/burnt-earth.jpg)
“历史很无聊,”Xola 低声对她的朋友说。Xola,一个蓝头发的女孩,正懒洋洋地用左手追着一架投影仪在房间里嗡嗡作响。“历史很重要,”老师看着女孩们,用一种沮丧的声音说。Xola 脸红了。她没想到老师会听到了她说话。
“Xola,你刚学到了什么?”老师问她。“古人用尽了地球上所有的资源,然后死了?“她仔细地问。“不,他们让气候变热,不是人,而是电脑和机器。“这是行星地球,而不是地球行星,”另一个叫林·塞拉的女孩点头表示同意。带着一丝骄傲,老师微笑着点了点头。“你们都是对的。你知道为什么会这样吗?因为人们目光短浅,贪婪?“Xola 问。“人们无法停止他们的机器!”林脱口而出。
“再说一次,你们都是对的,”老师决定,“但这比这复杂得多。当时大多数人都不知道发生了什么。有些人看到了巨大的变化,但无法逆转。这一时期最著名的作品是一首匿名作者的诗。它最能捕捉当时发生的事情。认真听!“
老师开始写这首诗。十几架小型无人机在孩子们面前重新定位,开始将视频直接投射到他们的眼睛里。它显示一个穿着西装的人站在森林里,只剩下树桩。他开始说话:
机器计算;机器预测。
我们继续前进,因为我们是其中的一部分。
我们追求一个经过训练的最佳状态。
最优解是一维的、局部的、无约束的。
硅和肉,追求指数性。
成长是我们的心态。收集所有奖励,忽略副作用;当所有的硬币都被开采出来,自然已经落后;
我们会有麻烦的,
毕竟,指数增长是一个泡沫。
公地悲剧正在上演,
爆炸,
在我们眼前。
冰冷的计算和贪婪,让地球充满热量。一切都在死亡,
我们是顺从的。
就像蒙着眼睛的马一样,我们在自己创造的种族中崛起,向着文明的伟大过滤器前进。
所以我们坚持不懈地前进。
因为我们是机器的一部分。
拥抱熵。
“黑暗的记忆,”老师说,打破了房间里的沉默。“它将上载到你的图书馆中。你的家庭作业下个星期交。”Xola 叹了口气。她设法抓住了一只小无人机。无人机从中央处理器和引擎发出的声音很温暖。Xola 喜欢它温暖她的手。
1.2 什么是机器学习?
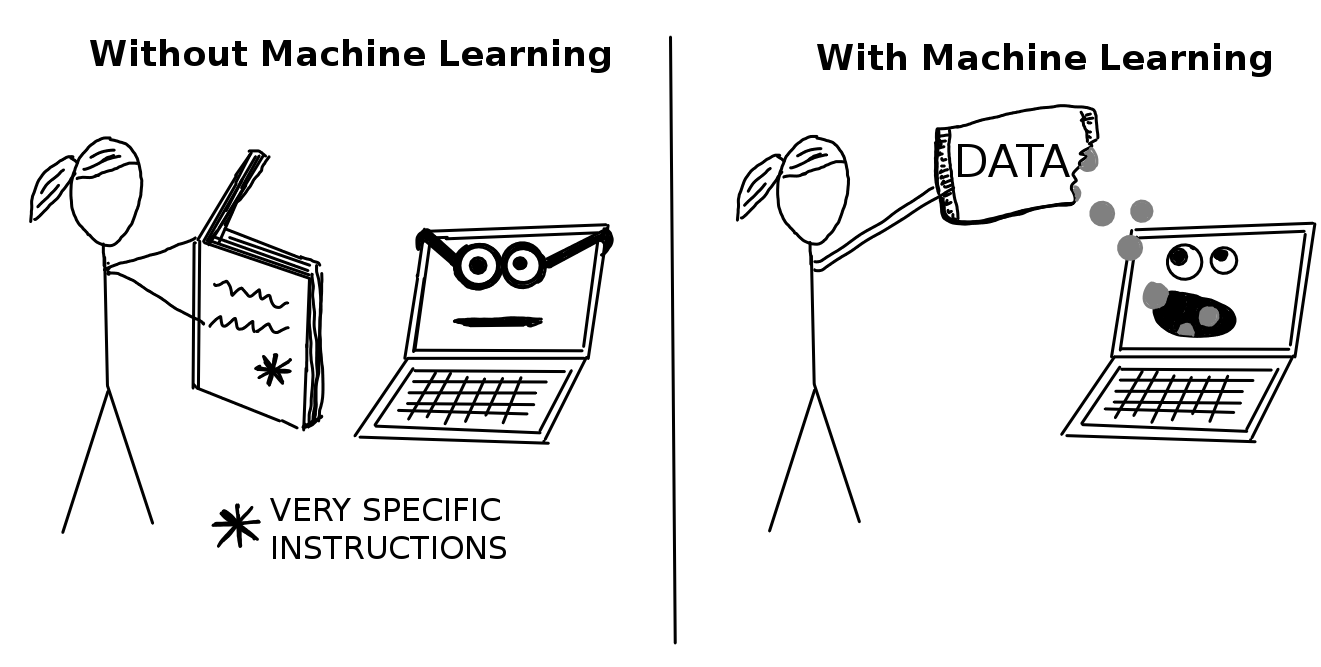
机器学习是计算机用来根据数据作出和改进预测或行为的一套方法。
例如,为了预测房屋的价值,计算机将从过去的房屋销售中学习模式。这本书关注点在监督机器学习上,它涵盖了所有的预测问题,其中我们有一个数据集,我们已经知道感兴趣的结果(如过去的房价),并希望学习预测新数据的结果。例如,聚类任务(=无监督学习)就不在监督学习范畴中,在这些任务中,我们没有特定关注的结果,但希望找到数据点的簇(中心点)。此外,诸如强化学习之类的事情也被排除,在这种情况下,智能体通过在一个环境中(如玩俄罗斯方块的计算机)的行为来学习优化某种奖励。监督学习的目标是学习一个预测模型,将数据特征(如房屋大小、位置、楼层类型等)映射到输出(如房价)。如果输出是类别,则任务称为分类,如果输出是数值,则称为回归。机器学习算法通过估计参数(如权重)或学习结构(如树)来学习模型。该算法由一个最小化的分数或损失函数指导。在房屋价值示例中,机器将估计房屋价格和预测价格之间的差值进行最小化。然后,可以使用经过充分训练的机器学习模型来预测新实例。
房价估算、产品推荐、路标检测、信用违约预测和欺诈检测:所有这些例子都有共同点,可以通过机器学习来解决。任务不同,但方法相同:
第一步:数据采集。越多越好。数据必须包含要预测的结果以及要从中进行预测的其他信息。对于街道标志检测器(“图像中有街道标志吗?“),您将收集街道图像并标记是否存在街道标志。对于信用违约的预测,您需要过去实际贷款的数据、客户是否拖欠贷款的信息以及有助于您做出预测的数据,例如收入、过去信用违约等。对于自动房屋价值评估程序,您可以从过去的房屋销售中收集数据和有关房地产的信息,如大小、位置等。
第二步:将这些信息输入机器学习算法,生成信号检测器模型、信用评级模型或房屋价值估计器。
第三步:将新数据输入模型。将模型集成到产品或流程中,例如自动驾驶汽车、信贷申请流程或房地产市场网站。
机器在许多任务上都超过人类,例如下棋(或最近的 Go)或天气预测。即使机器和人一样好,或者在任务上略微逊色,在速度、再现性和缩放方面仍然有很大的优势。一个一旦实现的机器学习模型可以比人类更快地完成一项任务,可靠地提供一致的结果,并且可以无限地复制。在另一台机器上复制机器学习模型既快又廉价。训练一个人完成一项任务可能需要几十年(尤其是当他们年轻时),而且成本很高。使用机器学习的一个主要缺点是,关于数据和机器解决的任务的思路被隐藏在愈加复杂的模型中。你需要数以百万计的参数来描述一个深层的神经网络,而没有办法完全理解这个模型。其他模型,如随机森林,由数百个决策树组成,它们“投票”预测。为了理解这个决定是如何做出的,你必须查看数百棵树中每棵树的投票和结构。不管你有多聪明或者你的记忆能力有多好,这都是行不通的。即使每个模型都可以被解释,但性能最好的模型通常是无法解释的多个模型(也称为集合)的集成。如果只关注性能,您将自动获得越来越多不透明的模型。只需看一看Kaggle.com机器学习竞赛平台对获胜者的采访:胜出的模型大多是模型的集成,或是非常复杂的模型,如集成树或深层神经网络。
1.3 术语
为避免歧义引起混淆,本书中使用的术语定义如下:
算法是机器为达到特定目标$^2$而遵循的一组规则。可以将算法视为定义输入、输出以及从输入到输出所需的所有步骤的说明。烹饪食谱是一种算法,其中成分是输入,熟食是输出,准备和烹饪步骤是算法指令。
机器学习是一套方法,允许计算机从数据中学习,以做出和改进预测(例如癌症、每周销售、信用违约)。机器学习是从“正常编程”到“间接编程”的一种范式转换,所有指令都必须明确地提供给计算机,而“间接编程”是通过提供数据来实现的。
学习者或机器学习算法是用来从数据中学习机器学习模型的程序。另一个名字是“诱导器”(例如“树诱导器”)。
机器学习模型是将输入映射到预测的学习程序。这可以是线性模型或神经网络的一组权重。“模型”这个不太具体的词的其他名称是“预测器”,或者——取决于任务——“分类器”或者“回归模型”。在公式中,经过训练的机器学习模型称为 $(\hat{f})$ 或 $(\hat{f}(x))$。

图 1.1:学习者从标记的训练数据学习模型。该模型用于预测。
黑盒模型是一个不揭示其内部机制的系统。在机器学习中,“黑匣子”描述了通过查看参数(例如神经网络)却无法理解的模型。黑盒的对立面有时被称为白盒,在本书中被称为可解释性模型,用于解释模型的不可知方法将机器学习模型视为黑盒,即使它们不是。

可解释机器学习是指使机器学习系统的行为和预测对人类可理解的方法和模型。
数据集是一个表格,其中包含机器从中学习的数据。数据集包含要预测的特征和目标。当用于训练模型时,数据集称为训练数据。
实例是数据集中的一行。“instance”的其他名称是:(数据)点,样本,观测对象。实例由特征值 $(x^{i})$ 和目标结果 $(y_i)$(如果已知)组成。
这些特征是用于对输入进行预测或分类的。特征是数据集中的列。在整本书中,人们都认为特征是可解释的,这意味着很容易理解它们的含义,比如某一天的温度或一个人的身高。特征的可解释性是一个很大的假设。但是,如果很难理解输入特征,那么更难理解模型的行为。对于单个实例,具有所有特征的矩阵称为 $X$ 和 $(x^{i})$ 。所有实例的单个特征向量是 $(x_j)$,而特征 $j$ 和实例 $i$ 的值是 $(x^i_j)$。
目标是机器学会预测的信息。在数学公式中,对于单个实例,目标通常称为 $y$ 或 $(y_i)$ 。
机器学习任务是一个具有特征和目标的数据集的组合。根据目标的类型,任务可以是分类、回归、生存分析、聚类或异常值检测。
预测是机器学习模型根据给定的特征“猜测”目标值应该是什么。在本书中,模型预测用 $(\hat{f}(x^i))$ 或 $\hat{y}$ 表示。

若有收获,就点个赞吧
0 人点赞

{kind=link}