信道的不可靠性,决定了RDT实现的复杂性。
- 问题的描述
- 停止等待协议:
RDT{1.0, 2.0, 2.1, 2.2, 3.0}
- 流水线协议
- GBN
- SR
RDT 1.0 可靠信道的数据传输
ASSUME:
- 不丢失
- 不出错
这样的情况就很简单,发送与接受方只需要做好封装与解封装就好了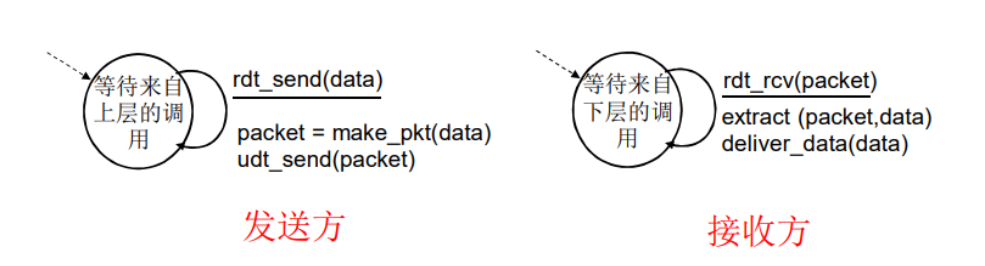
RDT 2.0 具有比特差错的信道
ASSUME:
- 不丢失
当信息可能出错时,RDT提供了一种差错控制编码的方案,接受方会丢弃校验和出错的分组。
同时提供一个ACK NAK确认机制来督促发送方进行分组的重发,进而完成在出错后的恢复工作。

RDT 2.1发送/接受方处理出错的ACK/NAK
ASSUME:
- 不丢失
RDT2.0最大的问题是,如果控制信息出错了怎么办?
发送方提供了一种序号的机制,这样接受方可以去除重复的分组,获得一个正确的报文。
如果发送方发现ACK/NAK出错或者无法识别,则重发一次当前的分组。
- 如果接收方发的是
ACK。由于存在序号,可以剔除多余的分组。 - 如果接收方发的是
NAK。则行为是正确的。
接收方没有安排确认的确认。但是它可以从是否存在多余的分组,来判断出控制信息是否发生了出错。
RDT 2.2 NAK free
从提供两种控制信息ACK/NAK,变成提供一种带序号的确认ACK {0,1}。
RDT 3.0 具有比特差错与分组丢失的信道
ASSUME:
- 无
提供超时重发机制来应对分组可能丢失的情况。
经此,我们即可在一个可能出错,可能丢失的信道上,完成可靠的数据传输服务了。但是RDT 3.0有一个缺点就是,它每次只能发送一个分组,然后等待确认后才能发下一个(stop-wait)。这样很显然效率很低。
对RDT 3.0进行性能优化的协议有两个:GBN与SR。他们是流水线协议,即一次可以发送多个分组,然后等待多个确认。发送/接收缓冲区,是流水协议的基础。
slide window
| 协议名 | send window | receive window |
|---|---|---|
| stop_wait | 1 | 1 |
| go back N | N | 1 |
| select receive | N | M |
GO-BACK-N(最大窗口大小是2^n - 1):
- 发送端在流水线中最多有N个未确认的分组;
- 接收端发送的是累计确认;
- 发送端只对最老的分组做定时
- 如果超时,重传所有分组
Selective Repeat(最大窗口大小为:2^(n-1))
- 发送端/接收端在流水线中最多有N,M个未确认的分组;
- 接收方对每个到来的分组做单独确认(非累计确认);
DIFF GBN , SR



若有收获,就点个赞吧
0 人点赞
