1.什么是线程池?
简而言之,线程池就是管理线程的一个容器,有任务需要处理时,会相继判断核心线程数是否还有空闲、线程池中的任务队列是否已满、是否超过线程池大小,然后调用或创建线程或者排队,线程执行完任务后并不会立即被销毁,而是仍然在线程池中等待下一个任务,如果超过存活时间还没有新的任务就会被销毁,通过这样复用线程从而降低开销。
2.使用线程池有什么优点?
可能有人就会问了,使用线程池有什么好处吗?那不用说,好处自然是有滴。
- 提升线程池中线程的使用率,减少对象的创建、销毁。
- 线程池的伸缩性对性能有较大的影响,使用线程池可以控制线程数,有效的提升服务器的使用资源,避免由于资源不足而发生宕机等问题。(创建太多线程,将会浪费一定的资源,有些线程未被充分使用;销毁太多线程,将导致之后浪费时间再次创建它们;创建线程太慢,将会导致长时间的等待,性能变差;销毁线程太慢,导致其它线程资源饥饿。)
3.线程池的核心工作流程(重要)
我们要使用线程池得先了解它是怎么工作的,流程如下图,废话不多说看图就行。核心就是复用线程,降低开销。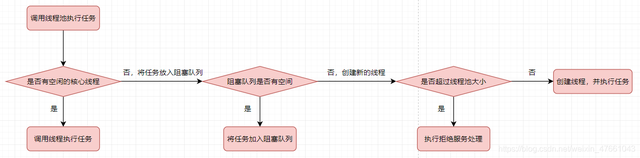
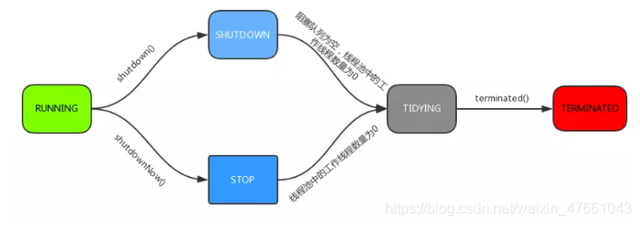
4.线程池的五种状态生命周期
- RUNNING :能接受新提交的任务,并且也能处理阻塞队列中的任务。
- SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown() 方法会使线程池进入到该状态。(finalize() 方法在执行过程中也会调用 shutdown() 方法进入该状态)。
- STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态。
- TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入 TERMINATED 状态。
- TERMINATED:在 terminated() 方法执行完后进入该状态,默认 terminated() 方法中什么也没有做。
5. 创建线程池的几种方式
|5.1通过 Executors 工厂方法创建
创建可缓存线程池 newCachedThreadPool
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
这种类型的线程池特点是:
工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。
如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
public void newCachedPool(){ExecutorService cachedThreadPool = Executors.newCachedThreadPool();for (int i=0;i<10;i++){final int index=i;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}cachedThreadPool.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+"==="+index);}});}}
创建定长的线程池 newFixedThreadPool
创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。
FixedThreadPool是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
public void newFixedPool(){ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);for (int i=0;i<10;i++){final int index=i;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}fixedThreadPool.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+"==="+index);}});}// fixedThreadPool.shutdown(); //不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务// fixedThreadPool.shutdownNow(); // 立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务}
创建单一线程执行 newSingleThreadExecutor
创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO,优先级)执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。
单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。
corepoolsize 核心线程数为1 ,非核心线程数为1 ;
队列为无界队列
public void newSingledPool(){ExecutorService singledThreadPool = Executors.newSingleThreadExecutor();for (int i=0;i<10;i++){final int index=i;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}singledThreadPool.execute(new Runnable() {@Overridepublic void run() {System.out.println("单线程执行任务"+new Date()+"--"+Thread.currentThread().getName()+"==="+index);}});}}
创建一个定长、定时、周期性的线程池 newScheduledThreadPool
创建一个定长的线程池,而且支持定时的以及周期性的任务执行,支持定时及周期性任务执行。
核心线程数为 参数设定,非核心线程数为MAX_VALUE
定义了一个DelayedWorkQueue,它是一个有序队列,会通过每个任务按照距离下次执行时间间隔的大小来排序。
public void newScheduledPool(){ExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);for (int i=0;i<10;i++){final int index=i;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}scheduledThreadPool.execute(new Runnable() {@Overridepublic void run() {System.out.println(new Date()+"--"+Thread.currentThread().getName()+"==="+index);}});}}/*** 延迟3秒执行一次*/public void newScheduledPool2() {ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);scheduledThreadPool.schedule(new Runnable() {public void run() {System.out.println(new Date()+"--"+Thread.currentThread().getName()+"==="+"delay 3 seconds");}}, 3, TimeUnit.SECONDS);}/*** 延迟1秒执行,每隔3秒执行一次*/public void newScheduledPool3() {ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);scheduledThreadPool.scheduleAtFixedRate(new Runnable() {public void run() {System.out.println("delay 1 seconds, and excute every 3 seconds");}}, 1, 3, TimeUnit.SECONDS);}
这四种线程池都是直接或者间接获取的 ThreadPoolExecutor 实例 ,只是实例化时传递的参数不一样。所以如果 Java 提供的线程池满足不了我们的需求,我们可以通过 ThreadPoolExecutor 构造方法创建自定义线程池。
|5.2通过 new ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue) 自定义创建
public class ThreadPoolConfig {// 核心线程池大小private int corePoolSize = 50;// 最大可创建的线程数private int maxPoolSize = 200;// 队列最大长度private int queueCapacity = 1000;// 线程池维护线程所允许的空闲时间private int keepAliveSeconds = 300;/*** 参数说明*corePoolSize //线程池核心线程大小*maximumPoolSize //线程池最大线程数量*keepAliveTime //空闲线程存活时间*TimeUnit unit //空闲线程存活时间单位,一共有七种静态属性TimeUnit.DAYS天,TimeUnit.HOURS小时,TimeUnit.MINUTES分钟,TimeUnit.SECONDS秒,TimeUnit.MILLISECONDS毫秒,TimeUnit.MICROSECONDS微妙,TimeUnit.NANOSECONDS纳秒*workQueue //工作队列*threadFactory //线程工厂,主要用来创建线程(默认的工厂方法是:Executors.defaultThreadFactory()对线程进行安全检查并命名*handler //拒绝策略(默认是:ThreadPoolExecutor.AbortPolicy不执行并抛出异常)*/public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler )ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 20, 2, TimeUnit.SECONDS, new LinkedBlockingQueue<>(5));public ThreadPoolTaskExecutor threadPoolTaskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setMaxPoolSize(maxPoolSize);executor.setCorePoolSize(corePoolSize);executor.setQueueCapacity(queueCapacity);executor.setKeepAliveSeconds(keepAliveSeconds);// 线程池对拒绝任务(无线程可用)的处理策略executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());return executor;}/*** 执行周期性或定时任务*/protected ScheduledExecutorService scheduledExecutorService() {return new ScheduledThreadPoolExecutor(corePoolSize,new BasicThreadFactory.Builder().namingPattern("schedule-pool-%d").daemon(true).build()) {@Overrideprotected void afterExecute(Runnable r, Throwable t) {super.afterExecute(r, t);Threads.printException(r, t);}};}}
工作队列-jdk 中提供了四种工作队列
- ArrayBlockingQueue 基于数组的有界阻塞队列,按 FIFO 排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到 corePoolSize 后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到 maxPoolSize,则会执行拒绝策略。
- LinkedBlockingQuene 基于链表的无界阻塞队列(其实最大容量为 Interger.MAX_VALUE),按照 FIFO 排序。由于该队列的近似无界性,当线程池中线程数量达到 corePoolSize 后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到 maxPoolSize,因此使用该工作队列时,参数 maxPoolSize 其实是不起作用的。
- SynchronousQuene 一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到 maxPoolSize,则执行拒绝策略。
PriorityBlockingQueue 具有优先级的无界阻塞队列,优先级通过参数 Comparator 实现。
拒绝策略-jdk中提供了4中拒绝策略
当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,就会执行拒绝策略。
ThreadPoolExecutor.CallerRunsPolicy 该策略下,在调用者线程中直接执行被拒绝任务的 run 方法,除非线程池已经 shutdown,则直接抛弃任务。
- ThreadPoolExecutor.AbortPolicy 该策略下,直接丢弃任务,并抛出 RejectedExecutionException 异常。
- ThreadPoolExecutor.DiscardPolicy 该策略下,直接丢弃任务,什么都不做。
- ThreadPoolExecutor.DiscardOldestPolicy 该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列。 除此之外,还可以根据应用场景需要来实现 RejectedExecutionHandler 接口自定义策略。
线程池执行逻辑说明
判断核心线程数是否已满,核心线程数大小和corePoolSize参数有关,未满则创建线程执行任务
若核心线程池已满,判断队列是否满,队列是否满和workQueue参数有关,若未满则加入队列中
若队列已满,判断线程池是否已满,线程池是否已满和maximumPoolSize参数有关,若未满创建线程执行任务
若线程池已满,则采用拒绝策略处理无法执执行的任务,拒绝策略和handler参数有关
拒绝策略
拒绝策略 => 默认采用的是AbortPolicy拒绝策略,直接在程序中抛出RejectedExecutionException异常【因为是运行时异常,不强制catch】,这种处理方式不够优雅。处理拒绝策略有以下几种比较推荐:
在程序中捕获RejectedExecutionException异常,在捕获异常中对任务进行处理。针对默认拒绝策略
使用CallerRunsPolicy拒绝策略,该策略会将任务交给调用execute的线程执行【一般为主线程】,此时主线程将在一段时间内不能提交任何任务,从而使工作线程处理正在执行的任务。此时提交的线程将被保存在TCP队列中,TCP队列满将会影响客户端,这是一种平缓的性能降低
自定义拒绝策略,只需要实现RejectedExecutionHandler接口即可
如果任务不是特别重要,使用DiscardPolicy和DiscardOldestPolicy拒绝策略将任务丢弃也是可以

若有收获,就点个赞吧
0 人点赞
