夜莺是一个通用的数值型时序数据监控系统,不止监控机器,还监控各类中间件、日志、业务模块,所以没法直接根据要监控的机器做配置度量。夜莺的各个模块中,tsdb模块是性能瓶颈,因为要存储数据落盘,需要消耗硬盘IO,监控指标的量比较大的话,就需要更多机器来承载这个IO。
我们使用如下配置的机器做了性能压测,供各位参考:
CPU:Architecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 40On-line CPU(s) list: 0-39Thread(s) per core: 2Core(s) per socket: 10Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 79Model name: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHzStepping: 1CPU MHz: 2200.000BogoMIPS: 4405.48Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 25600KNUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39内存:total used free shared buff/cache availableMem: 125G 25G 1.2G 4.0G 99G 94GSwap: 0B 0B 0B硬盘:SATA SSD RAID5
压测方法:
10内写入200万个点,即每秒大约20个万个点,机器各性能指标如图
CPU看起来还好,超线程的,40个逻辑核,如果16核应该也没问题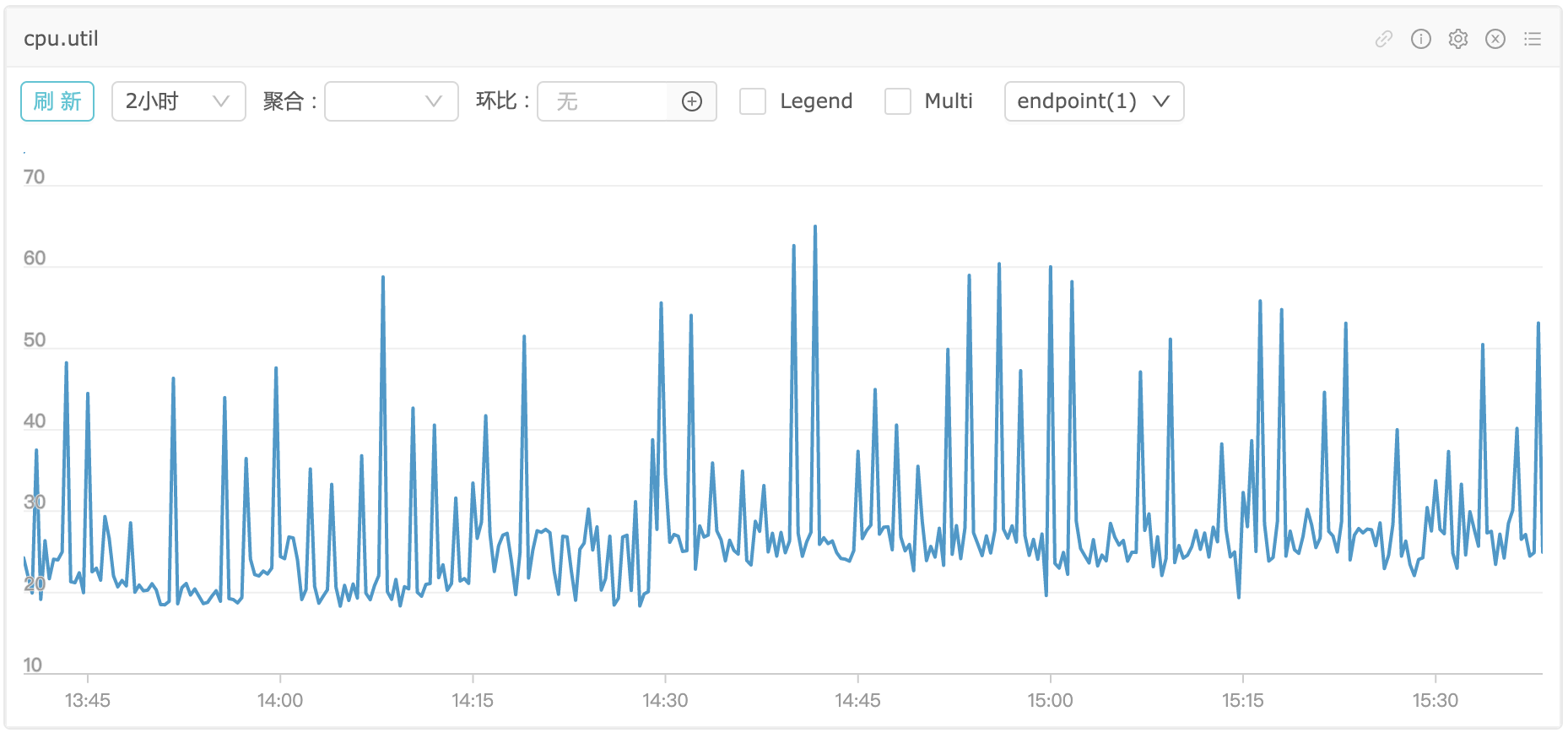
内存差不多到了34G,之前机器上有其他进程在跑,已经用了15.5G,所以TSDB模块吃掉了18.5GB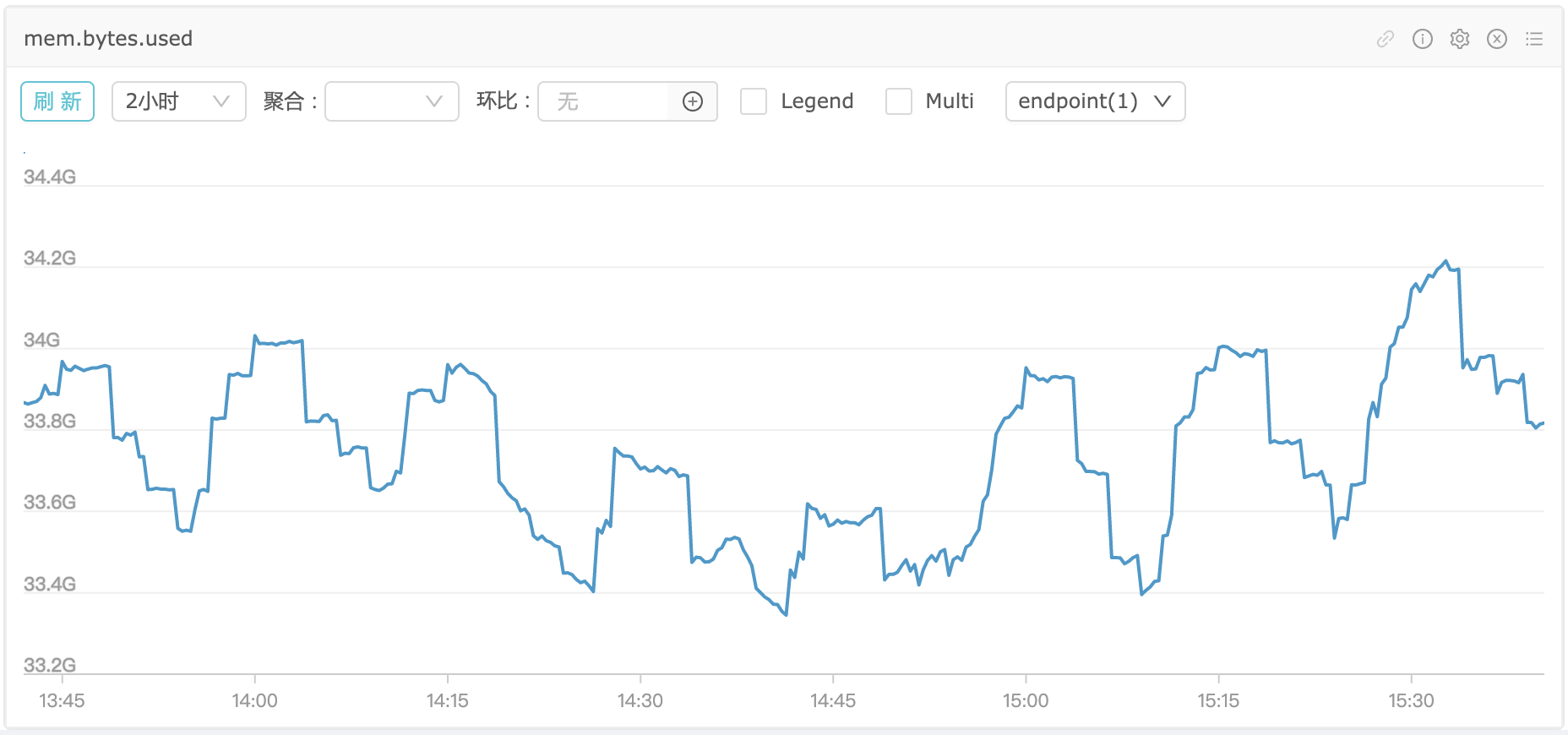
IO.UTIL整体没有维持在100%,其实即使维持在100%也未必就代表硬盘IO能力被榨干了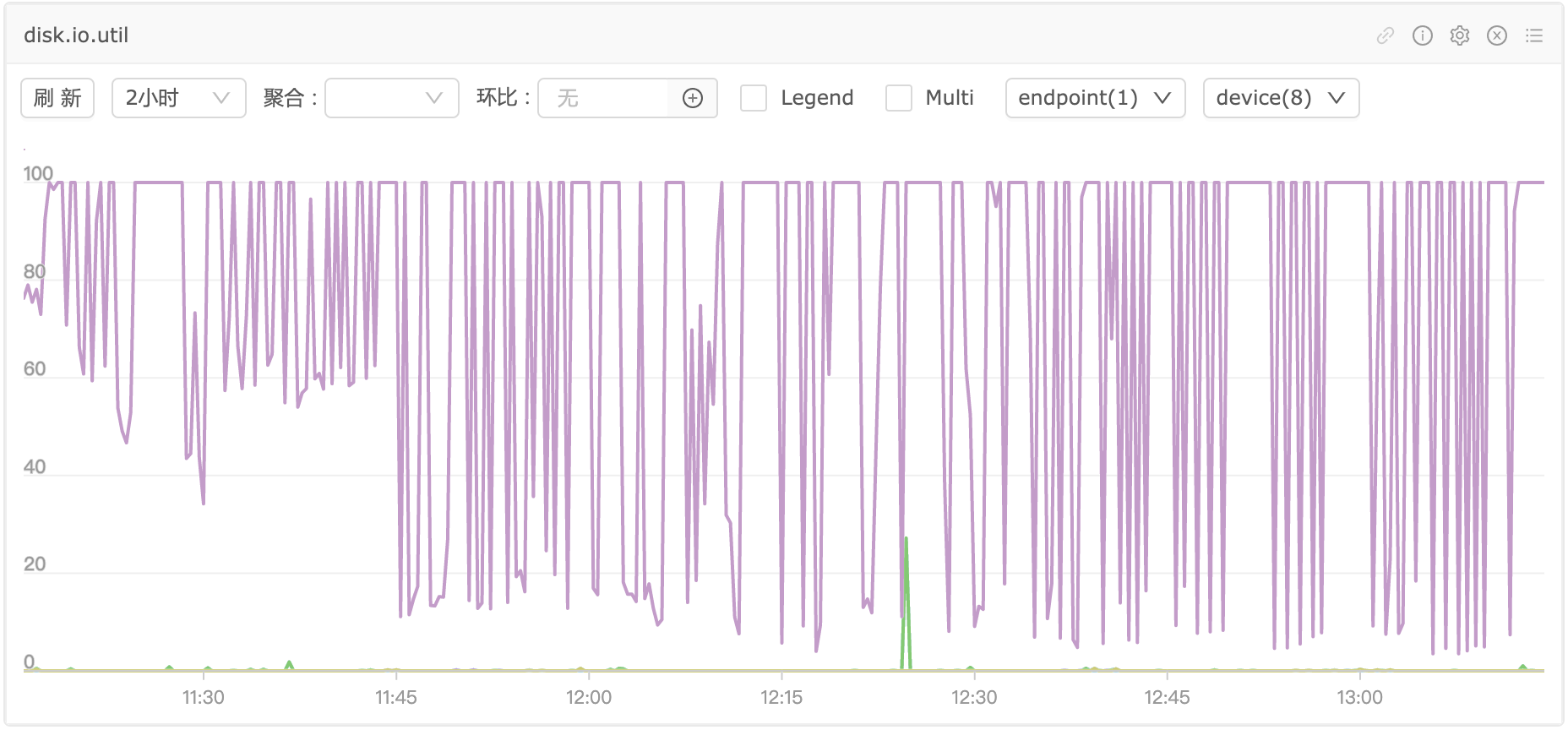
IO.AWAIT更有参考意义,维持在10左右,很平稳,说明进来的IO请求都正常被处理了,另外队列深度也没有明显增加,说明IO没有被打到瓶颈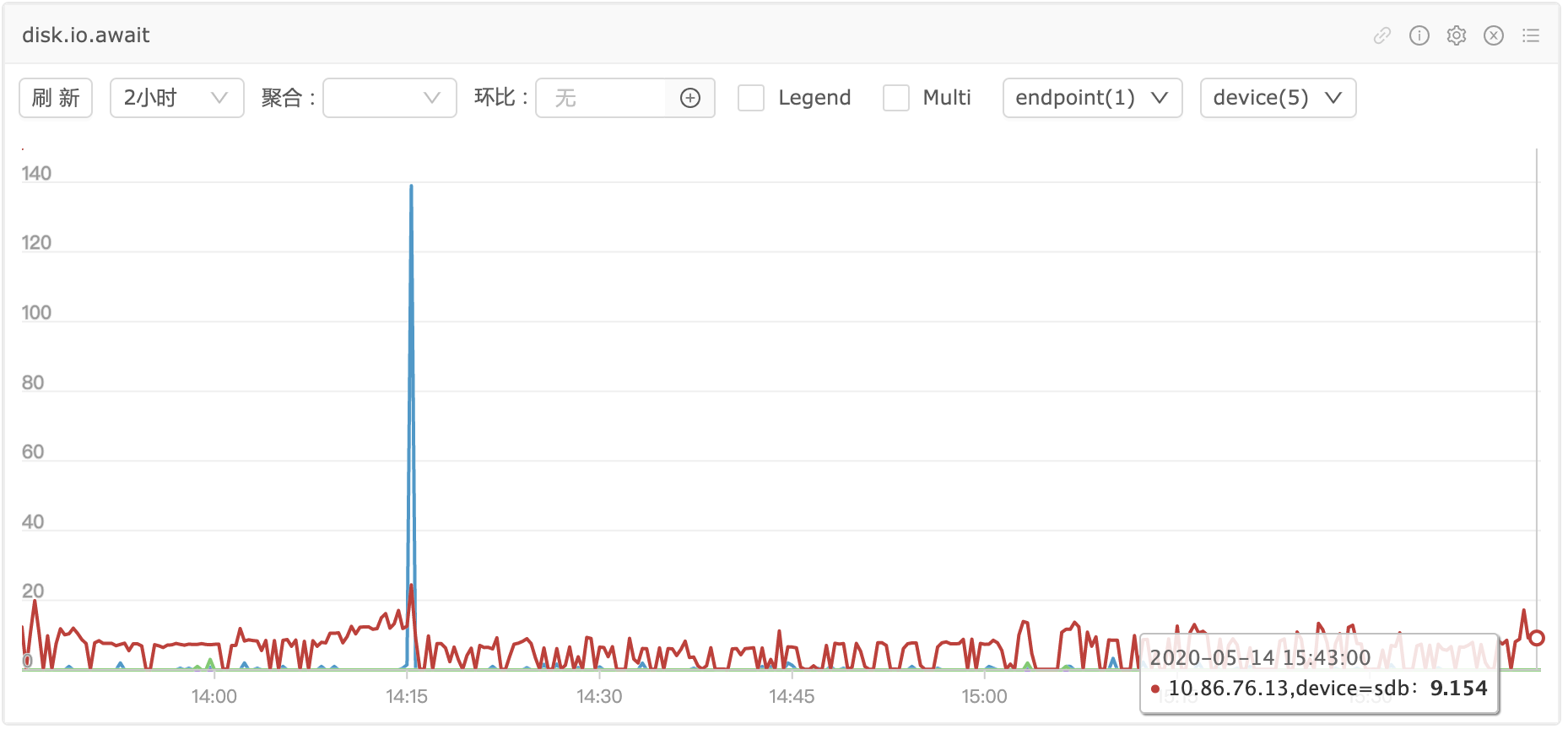
所以,每秒20万个点,理论上16C32G的SSD机器,可以抗住,并且还有余量,但是余量也不多了。
如果,我们只监控机器,每个机器大约采集150个监控指标,我们来计算不同采集频率可以抗住多少台机器。
如果采集频率是10s,20万*10s/150=13333台如果采集频率是60s,20万*60s/150=80000台
tsdb底层使用rrdtool,默认有4个归档策略,如果把归档策略调整为2个(会牺牲历史数据的精度),IO会减少50%,相应的单机每秒可以抗40万指标。rrdtool在归档的时候,对于归档数据会计算max、min、avg,如果我们改成只保留avg,IO又会大幅减少,所以具体还是看需求,来灵活调整。

若有收获,就点个赞吧
0 人点赞
