先 mark 几个分析的帖子:
https://paper.seebug.org/557/
http://0gur1.cc/2019/02/16/Exim-Off-by-one-CVE-2018-6789%E6%BC%8F%E6%B4%9E%E5%A4%8D%E7%8E%B0/
https://www.freebuf.com/vuls/166519.html
https://leeeddin.github.io/exim-cve-2018-6789/
https://de4dcr0w.github.io/%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/CVE-2018-6789-Exim-Off-by-One%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90.html
环境搭建
git clone https://github.com/Exim/exim.gitgit checkout 38e3d2dff7982736f1e6833e06d4aab4652f337acd srcmkdir Localcd Localwget "https://bugs.exim.org/attachment.cgi?id=1051" -O Makefilecd ..修改Makefile文件的第134行,把用户修改为当前服务器上存在的用户,然后编译安装make -j8sudo make install/usr/exim/bin/exim -bdf -d+all
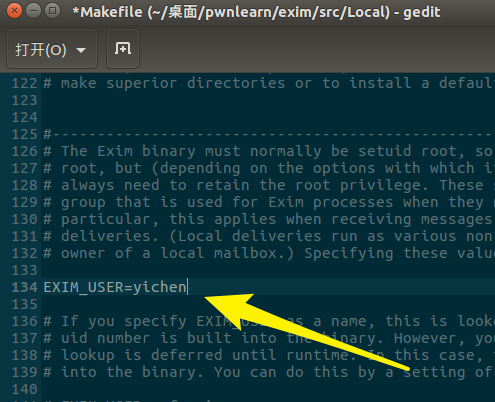
直接 docker 拉起来也行 Orzsudo docker run -it --name exim -p 25:25 skysider/vulndocker:cve-2018-6789
base64的C语言实现
先得介绍一下 base64:
他会把三个字节的内容转成四个字节,因为原本一个字节是八位的,base64 编码的时候是按照六位为一个编码的,38=24 对应的 46=24
编码
一开始先要算一下一共多少位,比如对 qwer 进行编码
按照每 3 字节转为 4 个的规则,len(qwer) mod 3 = 1 也就是说多出来 1 字节,那我们要补充 2 字节进去才能凑够 3 字节
放在 C 语言里可以这么写,其中 src 是待编码的数据
char table[65]="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";//定义的字典,根据这个找具体在哪里fill_bit=((3-strlen(src)%3)%3);for(int k=0;k<fill_bit;k++){src[data_length+k]='0';}
然后就到了编码部分了,在此之前还要先介绍一下位操作
每个字节有 8 bit,比如 q 就是 01110001,按位与操作 & 做的就是相同为 1 不同为 0
那 q 与 3 进行与运算就是(01110001 & 0011)= 1
左移、右移在下文中就理解为是把它直接移动就好了,比如 q 右移 2 位:就是 011100 01 的后两位给移动出去,只剩下前 6 位,然后前面补上两个 0
int j=0;for(int i=0;i<data_length;i+=3){index=src[i]>>2;result[j++]=table[index];index=((src[i]&3)<<4)+(src[i+1]>>4);result[j++]=table[index];index=((src[i+1]&15)<<2)+(src[i+2]>>6);result[j++]=table[index];index=(src[i+2]&63);result[j++]=table[index];//<< >> 运算符的优先级低于+ -,注意加括号}
index=src[i]>>2 是把第一个 ‘q’ 向右移了 2 位,也就是取前 6 位,得到了 00011100 也就是 28result[j++]=table[index] 然后在字典中找第几位,作为结果,在字典中第 28 个是 c,所以就有了编码后的第一个字符 ‘c’
src[i]&3 作用是取第一个 ‘q’ 的后两位 01,然后 (src[i]&3)<<4 左移4位 010000,再加第二个 ‘w’ src[i+1]>>4 右移 4 位得到的前 4 位 0111,加起来是 010111 也就是 23,在字典中第 23 位是 ‘X’,得到编码后第二个字符
src[i+1]&15 是取第二个 ‘w’ 后四位 0111(15 是 1111),左移 2 位得 00011100。第三个 ‘e’ 右移 6 位 src[i+2]>>6 得到的前 2 位 01,加起来得到得到 00011101 = 29 在字典中第 29 位是 ‘d’
最后再直接取第三个 ‘e’ 的后 6 位 src[i+2]&63(63 是 111111)
这样一个循环就结束了,把三个变成了四个
下一个循环中算上前面补充的两个 0 是这样分的:011100 100000 000000 000000
然后把补充的字符替换为 ‘=’
result_length=strlen(result);for(int k=0;k<fill_bit;k++){result[result_length-1-k]=padding_char;}
解码
int findchr(char *array,char ch){for(int i=0;i<strlen(array);i++){if(array[i]==ch){return i;}}return 0;}
对于前面编码的每一个字符,都要从 table 表里面去找对应的字符,比如 ‘A’ 应该是 0
首先可以把前面的 = 换成 A,因为 A 在我们定义的字典中是 000000,跟前面补上的 0 是一样的
for(int i=0;i<base_len;i++){if(src[i]==padding_char)src[i]='A';}for(int i=0;i<base_len;i+=4){result[j++]=(findchr(table,src[i])<<2)+((findchr(table,src[i+1])& 0xF0)>>4);result[j++]=((findchr(table,src[i+1])& 0x0F)<<4)+((findchr(table,src[i+2])& 0x3C)>>2);result[j++]=((findchr(table,src[i+2])& 0x03)<<6)+(findchr(table,src[i+3]));}
感觉里面这些与操作没啥用啊,与不与的都是那几位了
然后按照从表里面找出来的位置进行位操作,这里拿前面编码后的 cXdlcg== 来举例子
比如 ‘c’ 在表中是第 28 位(00011100)向左移动 2 位,那他就是 01110000,再加上表中 ‘X’ 是 23(00010111),向右移动 4 位得到 00000001,两者相加得到 01110001 即 113 也就是 ‘q’
剩下的也一样:
01110000+ 00000111 = 01110111 = 119 = ‘w’
01000000 + 00100101 = 01100101 = 101 = ‘e’
到这一轮就结束了,用了 src[0]、src[1]、src[2]、src[3],解码出来 qwe
接下来 src[4] 到了 ‘c’,00100011
01110000 + 00000010 = 01110010 = 114 = ‘r’
00000000 + 00000000 = 00000000 = null
00000000 + 00000000 = 00000000 = null
解码结束
完整的文件: https://pan.baidu.com/s/1mBQA9dT48Y1ZgnBUOui5lg 提取码: g79b
漏洞成因
通过上面对 base64 编码的了解,我们已经知道了 base64 编码后的应该都是 4 的倍数,它将会被解码为 3 的倍数的长度,然后下面的代码中给了 3n + 1 的空间,是没有问题的

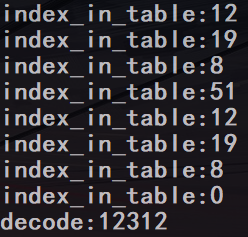
但是如果构造一个 4n+3 的 base64 编码去让他解码用到的就是 3n+2 就 off by one 了
例如:123 经过 base64 编码之后是:MTIz,在末尾加上两个字符:’MTI’,去解码的时候会解码为 12312
本来是 41,加上两个之后就是 41+3 然后解码出来是 3*1+2
漏洞复现
把环境拉起来sudo docker run --cap-add=SYS_PTRACE -it --name exim -p 25:25 skysider/vulndocker:cve-2018-6789
—cap-add=SYS_PTRACE 是为了能在 docker 中使用 gdb 调试
然后另外开个终端,docker exec -it 2a6ed3825be0 /bin/bash
安装一下 peda
git clone git://github.com/Mipu94/peda-heap.git ~/peda-heapecho "source ~/peda-heap/peda.py" >> ~/.gdbinit
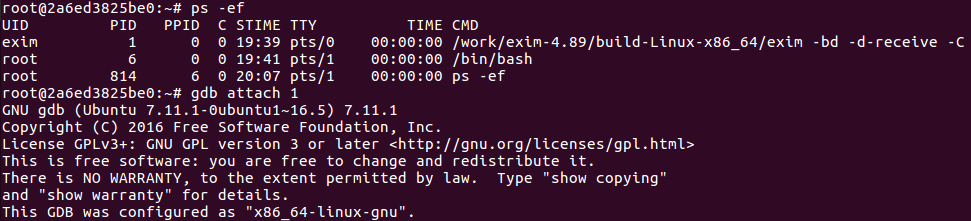
ps.这个 docker里面啥都没有,工具要自己安装,后面我把安好的传到 dockerhub 上
用 ps -ef 查看一下运行的程序,找到 exim 的 pid,然后 gdb attach PID

若有收获,就点个赞吧
0 人点赞
