修改mnist数据集从本地导入
找一下 mnist.py,在我这里就这俩,第二个就是
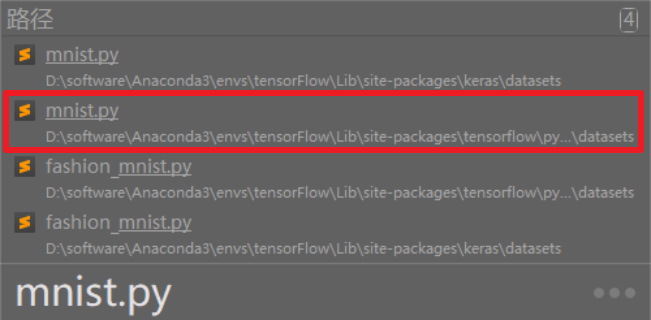
找东西用的软件叫:listary
把原来的 path 改为本地下好的路径
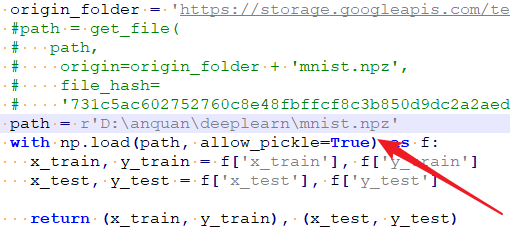
参考:https://blog.csdn.net/wayne1000/article/details/102901960
mnist数据集介绍
mnist 数据集分两部分:训练数据、测试数据
训练数据分为:训练特征、训练标签
测试数据分为:测试特征、测试标签
使用 mnist.load_data() 导入数据集
可以给训练数据跟测试数据起个名字
(train_image,train_label),(test_image,test_label) = mnist.load_data()
这样,train_image 就表示训练数据,通过 print 可以看出,训练数据一共有 60000 个
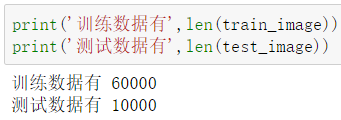
可以使用
train_image[0] 来查看训练数据中的第一个,这是像素值,因为是灰度图片,所以不是 r,g,b 那样三个值
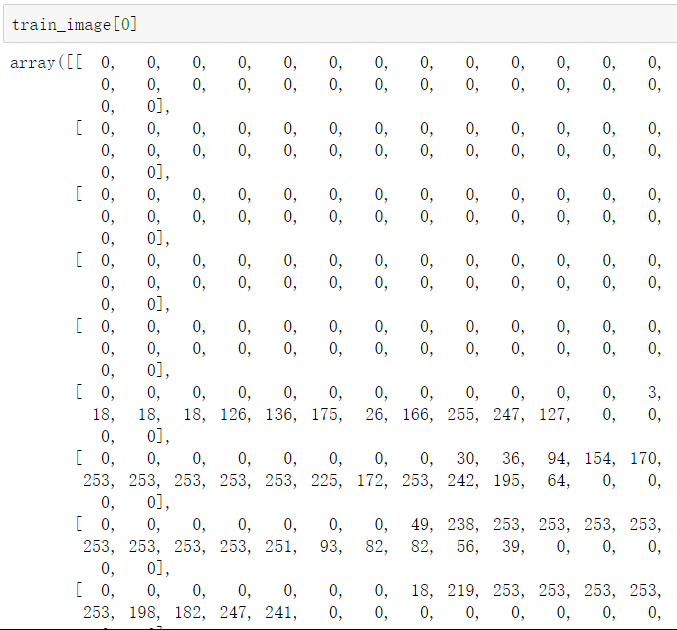
可以编写一个函数,来查看图片
import matplotlib.pyplot as pltdef show_image(image):plt.imshow(image,cmap='gray')#这表示是灰色的图片plt.show()
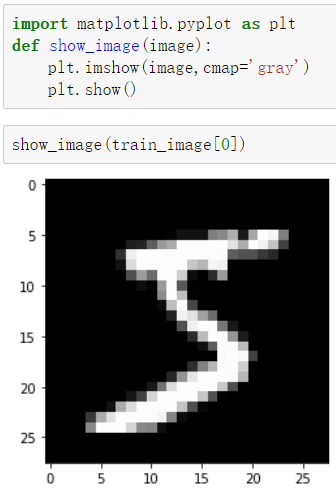
查看数据信息
print("训练图片样式",train_image.shape)print("训练图片标签",train_label.shape)
根据打印结果看,有 60000 张图片,每一张都是 28*28 像素的

MLP多层感知器模型

它是一种全连接的模型,上一层任何一个神经元与下一层的所有神经元都有连接
点击查看【bilibili】
数据预处理
现在的数据没法加载到模型中,因为输入层传入的数据只能是一维的那种数组数据,所以需要对数据进行处理
首先转成一维的并且改为浮点型
train_image_matric = train_image.reshape(60000, 784).astype(float)test_image_matric = test_image.reshape(10000, 784).astype(float)
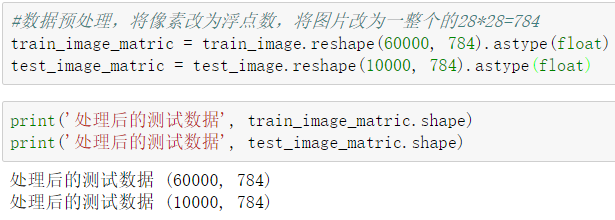
然后标准化,去除量纲,让数据落在 0-1 之间,直接除以 255,变成都是零点几的数:
train_image_normalize = train_image_matric / 255test_image_normalize = test_image_matric / 255
把标签改为一位有效编码(独热编码):通过使用 N 个状态寄存器来对 N 个状态进行编码
因为我们仅仅是识别数字,直接用 10 个 0 和 1 组成的编码来判断是十种中的哪一种就可以
0:1000000000
1:0100000000
2:0010000000
……
train_label_onehotencoding = np_utils.to_categorical(train_label)test_label_onehotencoding = np_utils.to_categorical(test_label)
做完上面那些数据的处理就可以开始建立模型了
from keras.models import Sequentialfrom keras.layers import Densemodel = Sequential()
添加输入层与隐藏层之间的关系
units = 256 表示隐藏层有 256 个神经单元
input_dim=784 表示输入层有 784 个神经单元
kernel_initializer=’normal’ 表示采用正态分布的方式产生权重和偏差
activation=’relu’ 表示使用 relu 作为激活函数
model.add(Dense(units = 256, input_dim=784, kernel_initializer='normal', activation='relu'))
前两个不需要啥理解,关于权重与偏差是干啥的,看 3Blue1Brown 的那个视频大概 8:40 开始有解释,这里通过截图来简单说一下,假设我们希望某一个单元的作用是:识别是不是一个小横杠

设绿色为正,红色为负,作为权重
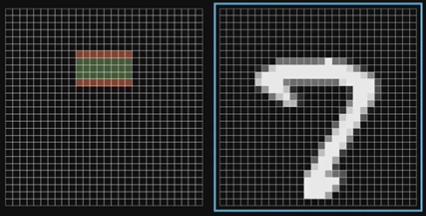
他俩叠加在一起,拿到每个像素的加权值,加在一起是加权和
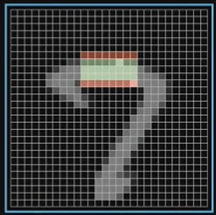
但不是所有情况都合适,我们想要的是一个横杠,只有加权和大于一个数的时候才算,这个数叫偏差,比如是 10,那就拿加权和减去 10 看看得出来的数是不是大于 0,如果大于 0 那表示,确实是有这么一个横杠
我们采用 relu 这个激活函数,只有当大于 0 的时候才有值,对应上面的例子就是只有当 加权和 - 10 > 0 的时候才激活
添加隐藏层与输出层之间的关系
激活函数 softmax 让每个神经单元都会计算出当前样本属于本类的概率
model.add(Dense(units=10, kernel_initializer='normal', activation='softmax'))
查看当前神经网络模型,每一层神经单元的关联数:上一层神经单元个数*本层神经单元个数+本层神经单元个数
200960 = 784*256+256
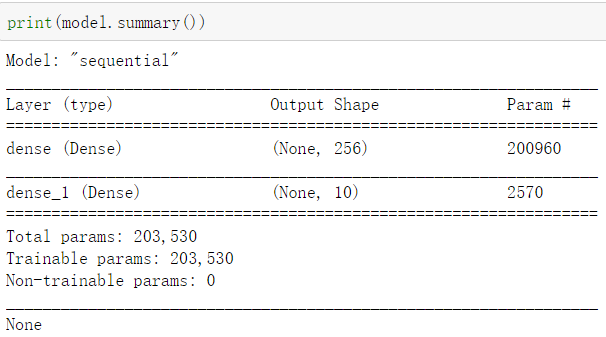
配置训练模型
loss=’categorical_crossentropy’ 设置损失函数,预测值与真实值之间的误差称为:损失,用于计算损失的函数称为损失函数,通过损失函数来判断模型的好坏
optimizer=’adam’ 设置优化器
metrics=[‘accuracy’] 目的是提高准确度
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
训练模型
train_history = model.fit(train_image_normalize, train_label_onehotencoding, validation_split=0.2, epochs=10, batch_size=200, verbose=2)#train_image_normalize 训练的数据#train_label_onehotencoding 训练的标签#validation_split=0.2 取一定比例用来验证#epochs=10 训练次数#batch_size=200 每次训练取出多少数据用于训练#verbose=2 显示训练过程
其中,val_loss 跟 val_accuracy 是验证损失和验证准确率
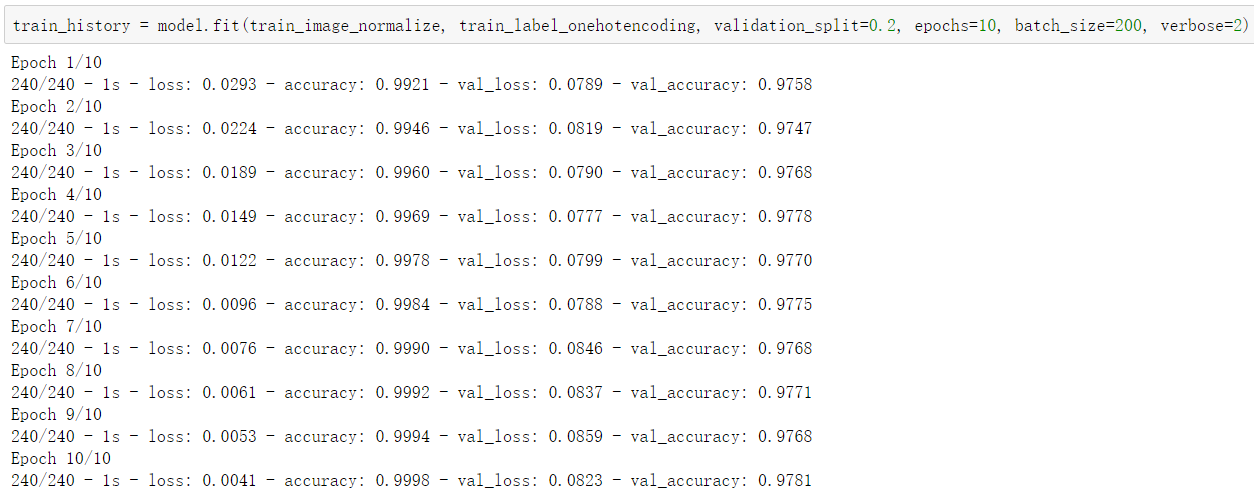
训练过程中训练相关的数据都记录在了 train_history 中,可以使用 train_history.history 来查看
print(train_history.history['accuracy'])#打印精确度历史print(train_history.history['val_accuracy'])#打印验证精确度历史print(train_history.history['loss'])#打印损失历史print(train_history.history['val_loss'])#打印验证损失历史
借助 matplotlib 展示准确率
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif']=['SimHei']plt.plot(train_history.history['accuracy'])plt.plot(train_history.history['val_accuracy'])plt.legend(['训练准确率', '验证准确率'], loc = 'upper left')plt.title("训练历史")plt.xlabel('训练次数')plt.ylabel('准确率')plt.show()
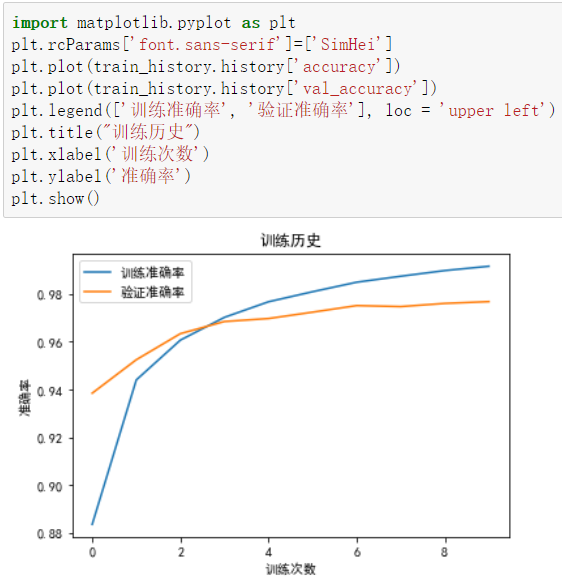

验证模型准确率
之前说过 mnist 包含了 10000 个用来测试的数据,接下来用这些数据验证模型准确率model.evaluate 的两个参数分别是测试用的图片跟标签(经过预处理)
scores = model.evaluate(test_image_normalize, test_label_onehotencoding)print(scores)
可以看到,我们训练后的模型准确率是 0.9775

预测图片
from PIL import Imageimg = Image.open('9.bmp')#打开图片number_data = img.getdata()#获取图片的数据number_data_array = np.array(number_data)#把数据转换为数组number_data_array = number_data_array.reshape(1,784).astype(float)#数组转换为一维的number_data_normalize = number_data_array / 255 #标准化prediction = model.predict(number_data_normalize) #带入模型进行预测print(prediction)np.max(prediction)np.argmax(prediction)
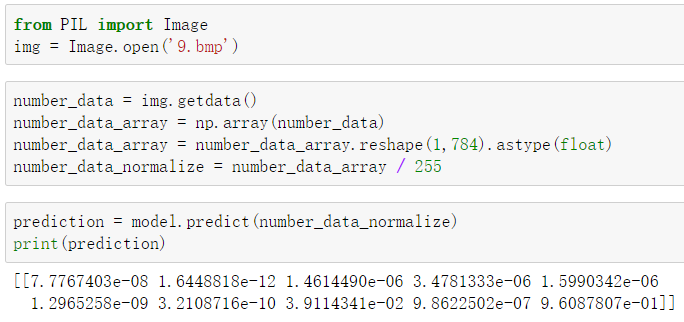
可以看到可能性最大的是最后一个,即数字 9,可能性为:0.96087…
导出模型
提高精度
增加神经单元个数、增加训练次数等
增加隐藏层,输入来自上层可以直接去掉
model.add(Dense(units = 256, kernel_initializer='normal', activation='relu'))
解决过度拟合
值得注意的是随着训练次数的增加训练准确率很高了,但是验证准确率却越来越平,上不去了
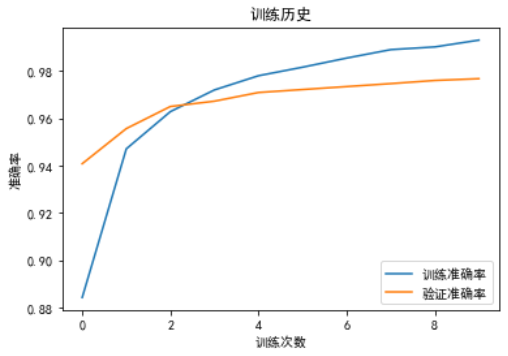
为了解决这个问题,有一个简单粗暴的方法 Dropout,每次训练都随机忽略一部分神经单元
要先:from keras.layers import Dropout
然后在每层之间添加一个:model.add(Dropout(0.5))
CNN卷积神经网络模型
卷积操作就是卷积核(kernal)跟输入数据每个值相乘再加起来得到的一个值作为输出

图源:https://flat2010.github.io/2018/06/15/手算CNN中的参数
数据预处理
在数据预处理上需要注意不再是一维的了,而要保持数组样式,是 28281 的,其他的没差别
train_image_matric = train_image.reshape(60000, 28, 28, 1).astype(float)test_image_matric = test_image.reshape(10000, 28, 28, 1).astype(float)train_image_4D_normalize = train_image_4D / 255test_image_4D_normalize = test_image_4D / 255train_label_onehotencoding = np_utils.to_categorical(train_label)test_label_onehotencoding = np_utils.to_categorical(test_label)
数据预处理之后开始建立模型
from keras.models import Sequentialfrom keras.layers import Densefrom keras.layers import Dropoutfrom keras.layers import Conv2D, MaxPooling2D, Flatten #卷积层、池化层、平坦层model = Sequential()
添加卷积层
filters=16 表示有 16 个卷积核(也叫滤镜)
kernel_size=(5,5) 表示卷积核的尺寸
padding=’same’ 表示对原图片进行填充,使得输出能够保持和输入尺寸一致
input_shape=(28,28,1) 输入的尺寸
activation=’relu’ 激活函数
model.add(Conv2D(filters=16, kernel_size=(5,5), padding='same', input_shape=(28,28,1), activation='relu'))
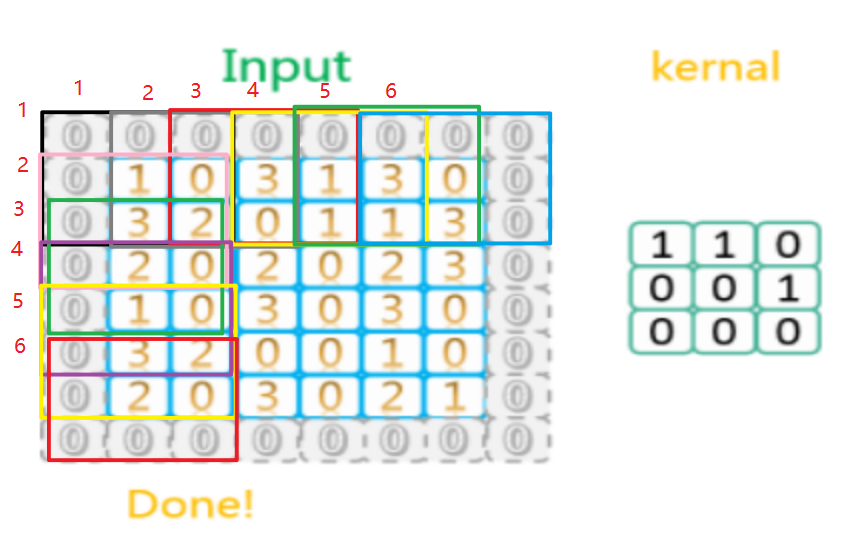
从这幅图中可以看到,周围添加了一圈之后,经过卷积核再输出的还是原来的尺寸大小
添加池化层
池化层也有一个池化核,但池化运算分为几种:
最大池化核,取池化数据的最大值; 平均池化核,取池化数据的平均值; 最小池化核,取池化数据的最小值; L2池化核,取池化数据的L2范数;
图示是最大池化过程
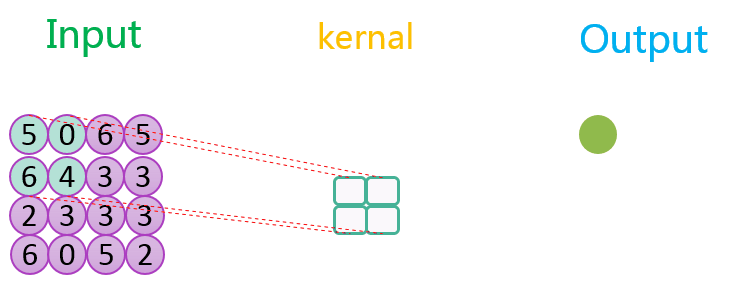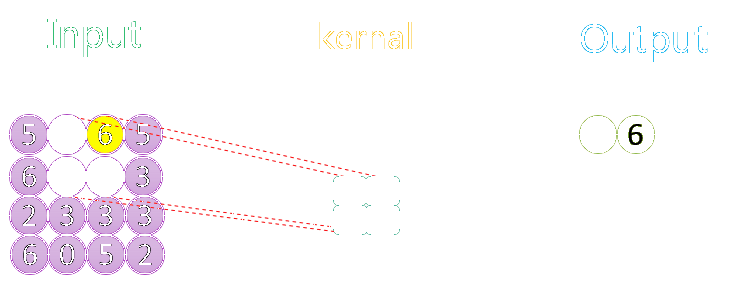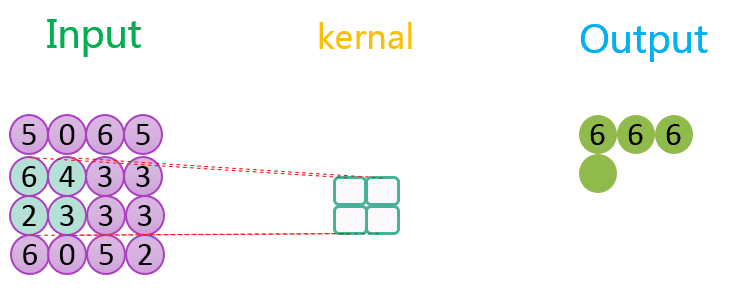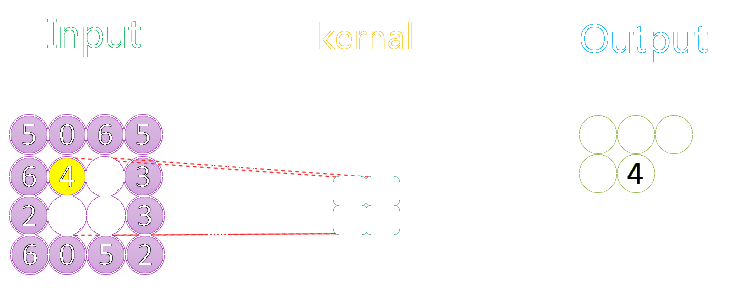
model.add(MaxPooling2D(pool_size = (2, 2)))#沿(垂直,水平)方向缩小比例的因数#(2,2)会把输入张量的两个维度都缩小一半

添加平坦层
还不知道是干啥的
model.add(Flatten())
添加隐藏层
model.add(Dense(units=128, kernel_initializer='normal', activation='relu'))model.add(Dropout(0.5))
添加隐藏层与输出层之间的关系
model.add(Dense(units=10, kernel_initializer='normal', activation='softmax'))
配置训练模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
训练模型
train_history = model.fit(train_image_4D_normalize, train_label_onehotencoding, validation_split=0.2, epochs=10, batch_size=200, verbose=2)
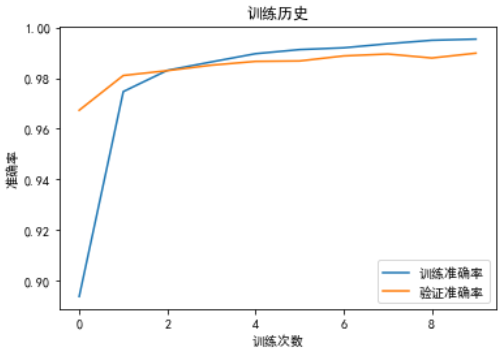
验证模型准确率
模型准确率是 0.9916

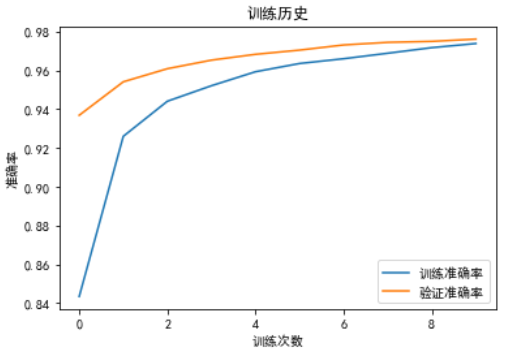
可以看到 CNN 比 MLP 不仅准确率提高了,在不加 Dropout 的情况下过度拟合现象也比 MLP 要小一些
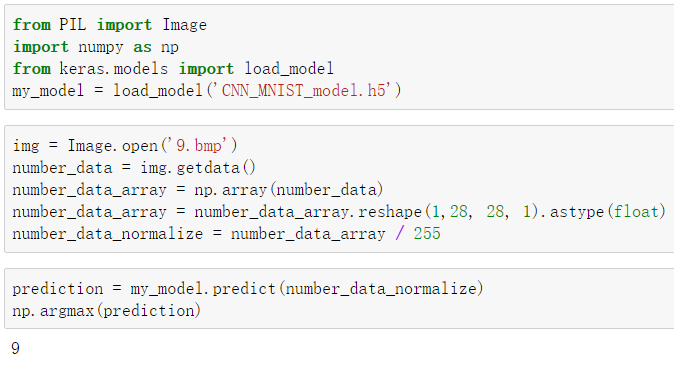
导入训练好的模型进行预测
还是先用之前的方法导出模型model.save('CNN_MNIST_model.h5')
导入模型load_model('CNN_MNIST_model.h5')
处理好数据之后调用 predict 函数就可以啦

若有收获,就点个赞吧
0 人点赞
