




加速训练: 首先,网络不必学习每次迭代带来的分布变化(学习任务更加简单了),训练时可以选择比较大的学习率。
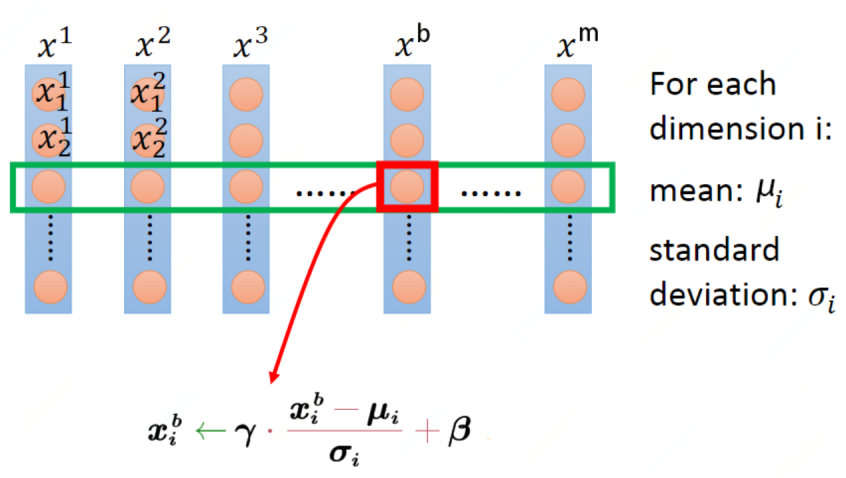
防止梯度消失:当使用sigmoid或者tanh时,可能会造成梯度消失。链式法则导致反向传播时低层神经网络的梯度消失(数学导数),而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
正则:由于我们使用mini-batch的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
卷积神经网络如何用BN
1个卷积核产生1个feature map,1个feature map有1对γγ和ββ参数,同一batch同channel的feature map共享同一对γγ和ββ参数,若卷积层有nn个卷积核,则有nn对γγ和ββ参数。


若有收获,就点个赞吧
0 人点赞
