联邦学习
某互联网企业A和某金融企业B,达成了企业级的合作,于是他们想联合起来搞点事情。互联网企业A有用户的上网行为数据X1,金融企业B有用户的信用,消费等特征数据X2和标注数据Y,把两边的数据特征结合到一起,再通过机器学习来提高金融产品购买的转化率。但是在合作时遇到问题了,由于不同行业之间的行政手续,用户数据隐私安全,企业A,B无法互通数据。
现实中这样的“数据孤岛”问题非常常见,对人工智能的现有模式提出了全新的挑战。
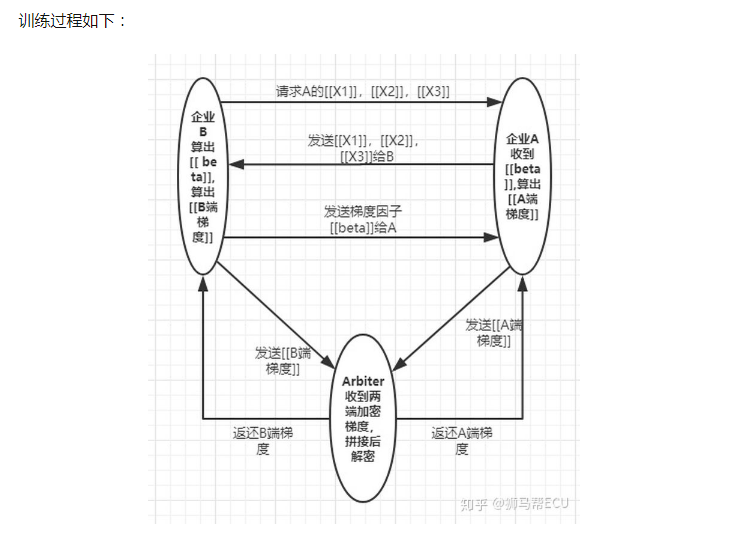
那么什么是联邦学习呢?还是回到刚才我们说的那两个例子,企业A和B他们在已经获取在用户认可可使用数据的前提下,想各自建立模型完成分类或者预测,但是由于数据特征不完整(A只有用户特征数据,B只有产品特征和标注特征),导致训练出来的模型质量不高。而联邦学习就是解决这个问题:联邦学习做到企业在本地训练模型,数据不出本地,而系统通过交换模型参数的方式,来建立一个虚拟的共享模型,而建好的模型又在各自的区域为本地的目标服务,这样既可以不泄露用户数据隐私,又可以达到高质量的效果。在这样一个联邦的机制下,每个参与者的地位是相同的。
联邦学习的分类
根据数据孤岛的类型,可以把联邦学习分为横向联邦学习,纵向联邦学习和联邦迁移学习。
横向联邦学习:数据在特征维度重叠较多,在用户维度重叠较少
纵向联邦学习:数据在用户维度重叠较多,在特征维度重叠较少



若有收获,就点个赞吧
0 人点赞
