浏览器环境,规格
在这里,我们将学习如何使用 JavaScript 来操纵网页。
下面是 JavaScript 在浏览器中运行时的鸟瞰示意图: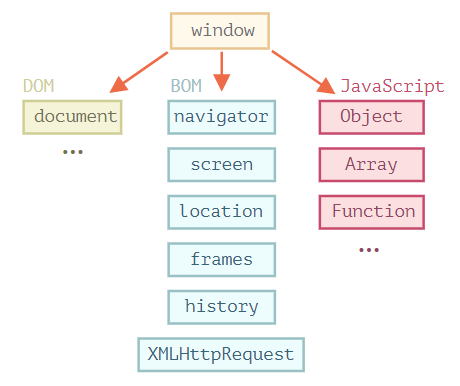
window :“根”对象
文档对象模型(DOM)
文档对象模型(Document Object Model),简称 DOM。将所有页面内容表示为可以修改的对象。document 对象是页面的主要“入口点”。我们可以使用它来更改或创建页面上的任何内容。
DOM 不仅仅用于浏览器
DOM 规范解释了文档的结构,并提供了操作文档的对象。有的非浏览器设备也使用 DOM。
例如,下载 HTML 文件并对其进行处理的服务器端脚本也可以使用 DOM。但它们可能仅支持部分规范中的内容。
浏览器对象模型(BOM)
浏览器对象模型(Browser Object Model),简称 BOM,表示由浏览器(主机环境)提供的用于处理文档(document)之外的所有内容的其他对象。
例如:
- navigator 对象提供了有关浏览器和操作系统的背景信息。navigator 有许多属性,但是最广为人知的两个属性是:navigator.userAgent — 关于当前浏览器,navigator.platform — 关于平台(可以帮助区分 Windows/Linux/Mac 等)。
location 对象允许我们读取当前 URL,并且可以将浏览器重定向到新的 URL。
Mozilla 手册
当你想要了解某个属性或方法时,Mozilla 手册 https://developer.mozilla.org/en-US/search 是一个很好的资源,但对应的规范可能会更好:它更复杂,且阅读起来需要更长的时间,但是会使你的基本知识更加全面,更加完整。
DOM 树
DOM 的例子
自己看看
要在实际中查看 DOM 结构,请尝试 Live DOM Viewer。只需输入文档,它将立即显示为 DOM。
探索 DOM 的另一种方式是使用浏览器开发工具。Chrome 开发者工具
在 https://developers.google.cn/web/tools/chrome-devtools 上有关于 Chrome 开发者工具的详细文档说明。
总结
HTML/XML 文档在浏览器内均被表示为 DOM 树。
标签(tag)成为元素节点,并形成文档结构。
- 文本(text)成为文本节点。
- ……等,HTML 中的所有东西在 DOM 中都有它的位置,甚至对注释也是如此。
我们可以使用开发者工具来检查(inspect)DOM 并手动修改它。
遍历 DOM
DOM 让我们可以对元素和它们中的内容做任何事,但是首先我们需要获取到对应的 DOM 对象。
对 DOM 的所有操作都是以 document 对象开始。它是 DOM 的主“入口点”。从它我们可以访问任何节点。
在最顶层:documentElement 和 body
= document.documentElement
= document.body
= document.head
脚本无法访问在运行时不存在的元素。
在 DOM 的世界中,null 就意味着“不存在”
子节点:childNodes,firstChild,lastChild
childNodes 集合列出了所有子节点,包括文本节点。
<html><body><div>Begin</div><ul><li>Information</li></ul><div>End</div><script>for (let i = 0; i < document.body.childNodes.length; i++) {alert( document.body.childNodes[i] ); // Text, DIV, Text, UL, ..., SCRIPT}</script>...more stuff...</body></html>
DOM 集合
正如我们看到的那样,childNodes 看起来就像一个数组。但实际上它并不是一个数组,而是一个 集合 — 一个类数组的可迭代对象。
我们可以使用 for..of 来迭代它。这是因为集合是可迭代的(提供了所需要的 Symbol.iterator 属性)。
for (let node of document.body.childNodes) {alert(node); // 显示集合中的所有节点}
无法使用数组的方法,因为它不是一个数组。如果我们想要使用数组的方法的话,我们可以使用 Array.from 方法来从集合创建一个“真”数组:
alert( Array.from(document.body.childNodes).filter ); // function
DOM 集合是只读的
DOM 集合是实时的
不要使用 for..in 来遍历集合,for..in 循环遍历的是所有可枚举的(enumerable)属性。兄弟节点和父节点
纯元素导航
更多链接:表格
```javascript
one two three four
<a name="vpVmj"></a># 搜索:getElement*,querySelector*<a name="V6jkq"></a>## document.getElementById 或者只使用 id如果一个元素有 id 特性(attribute),那我们就可以使用 document.getElementById(id) 方法获取该元素,<br />**请不要使用以 id 命名的全局变量来访问元素**<br />**id 必须是唯一的**<a name="eR89g"></a>## querySelectorAll到目前为止,最通用的方法是 elem.querySelectorAll(css),它返回 elem 中与给定 CSS 选择器匹配的所有元素。<a name="QC4ab"></a>## querySelectorelem.querySelector(css) 调用会返回给定 CSS 选择器的第一个元素。<br />换句话说,结果与 elem.querySelectorAll(css)[0] 相同,但是后者会查找 **所有** 元素,并从中选取一个,而 elem.querySelector 只会查找一个。因此它在速度上更快,并且写起来更短。<a name="oOijA"></a>## matches当我们遍历元素(例如数组或其他内容)并试图过滤那些我们感兴趣的元素时,这个方法会很有用。<a name="CODTt"></a>## closestelem.closest(css) 方法会查找与 CSS 选择器匹配的最近的祖先。方法 closest 在元素中得到了提升,并检查每个父级。<a name="qR5hB"></a>## getElementsBy*如今,它们大多已经成为了历史,因为 querySelector 功能更强大,写起来更短。<a name="HHc7c"></a>## 总结有 6 种主要的方法,可以在 DOM 中搜索元素节点:| 方法名 | 搜索方式 | 可以在元素上调用? | 实时的? || --- | --- | --- | --- || querySelector | CSS-selector | ✔ | - || querySelectorAll | CSS-selector | ✔ | - || getElementById | id | - | - || getElementsByName | name | - | ✔ || getElementsByTagName | tag or '*' | ✔ | ✔ || getElementsByClassName | class | ✔ | ✔ |目前为止,最常用的是 querySelector 和 querySelectorAll,但是 getElement(s)By* 可能会偶尔有用,或者可以在旧脚本中找到。<a name="Tsf45"></a># 节点属性:type,tag 和 content<a name="uE6Bd"></a>## DOM 节点类所有类型的 DOM 节点都形成了一个单一层次的结构(single hierarchy)。<br />每个 DOM 节点都属于相应的内建类。<br />层次结构(hierarchy)的根节点是 [EventTarget](https://dom.spec.whatwg.org/#eventtarget),[Node](http://dom.spec.whatwg.org/#interface-node) 继承自它,其他 DOM 节点继承自 Node。<br />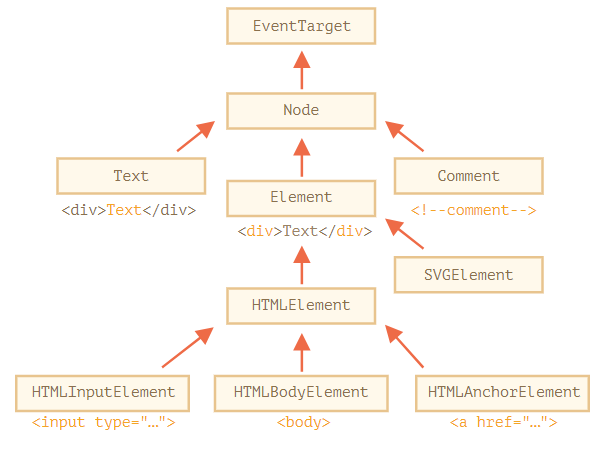<br />类如下所示:- [EventTarget](https://dom.spec.whatwg.org/#eventtarget) — 是根的“抽象(abstract)”类。该类的对象从未被创建。它作为一个基础,以便让所有 DOM 节点都支持所谓的“事件(event)”,我们会在之后学习它。- [Node](http://dom.spec.whatwg.org/#interface-node) — 也是一个“抽象”类,充当 DOM 节点的基础。它提供了树的核心功能:parentNode,nextSibling,childNodes 等(它们都是 getter)。Node 类的对象从未被创建。但是有一些继承自它的具体的节点类,例如:文本节点的 Text,元素节点的 Element,以及更多异域(exotic)类,例如注释节点的 Comment。- [Element](http://dom.spec.whatwg.org/#interface-element) — 是 DOM 元素的基本类。它提供了元素级的导航(navigation),例如 nextElementSibling,children,以及像 getElementsByTagName 和 querySelector 这样的搜索方法。浏览器中不仅有 HTML,还会有 XML 和 SVG。Element 类充当更多特定类的基本类:SVGElement,XMLElement 和 HTMLElement。- [HTMLElement](https://html.spec.whatwg.org/multipage/dom.html#htmlelement) — 最终是所有 HTML 元素的基本类。各种 HTML 元素均继承自它:- [HTMLInputElement](https://html.spec.whatwg.org/multipage/forms.html#htmlinputelement) — <input> 元素的类,- [HTMLBodyElement](https://html.spec.whatwg.org/multipage/semantics.html#htmlbodyelement) — <body> 元素的类,- [HTMLAnchorElement](https://html.spec.whatwg.org/multipage/semantics.html#htmlanchorelement) — <a> 元素的类,- ……等,每个标签都有自己的类,这些类可以提供特定的属性和方法。因此,给定节点的全部属性和方法都是继承的结果。<br />DOM 节点是常规的 JavaScript 对象。它们使用基于原型的类进行继承。<a name="wpGqx"></a>## “nodeType” 属性nodeType 属性提供了另一种“过时的”用来获取 DOM 节点类型的方法。<a name="EavPB"></a>## 标签:nodeName 和 tagName- tagName 属性仅适用于 Element 节点。- nodeName 是为任意 Node 定义的:- 对于元素,它的意义与 tagName 相同。- 对于其他节点类型(text,comment 等),它拥有一个对应节点类型的字符串。<a name="jvRK8"></a>## innerHTML:内容[innerHTML](https://w3c.github.io/DOM-Parsing/#the-innerhtml-mixin) 属性允许将元素中的 HTML 获取为字符串形式。<br />我们也可以修改它。因此,它是更改页面最有效的方法之一。<a name="ZKpn8"></a>### 小心:“innerHTML+=” 会进行完全重写我们可以使用 elem.innerHTML+="more html" 将 HTML 附加到元素上。<br />但我们必须非常谨慎地使用它,因为我们所做的 **不是** 附加内容,而且完全地重写。<br />换句话说,innerHTML+= 做了以下工作:1. 移除旧的内容。1. 然后写入新的 innerHTML(新旧结合)。**因为内容已“归零”并从头开始重写,因此所有的图片和其他资源都将重写加载。**<br />如果 chatDiv 有许多其他文本和图片,那么就很容易看到重新加载(译注:是指在有很多内容时,**重新加载会耗费更多的时间**,所以你就很容易看见页面重载的过程)。<br />并且还会有其他**副作用**。例如,如果现有的文本被用鼠标选中了,那么大多数浏览器都会在重写 innerHTML 时删除选定状态。如果这里有一个带有用户输入的文本的 <input>,那么这个被输入的文本将会被移除。<a name="v6ODA"></a>## outerHTML:元素的完整 HTML**注意:与 innerHTML 不同,写入 outerHTML 不会改变元素。而是在 DOM 中替换它。**```javascript<div>Hello, world!</div><script>let div = document.querySelector('div');// 使用 <p>...</p> 替换 div.outerHTMLdiv.outerHTML = '<p>A new element</p>'; // (*)// 蛤!'div' 还是原来那样!alert(div.outerHTML); // <div>Hello, world!</div> (**)</script>
在 div.outerHTML=… 中发生的事情是:
- div 被从文档(document)中移除。
- 另一个 HTML 片段
A new element
被插入到其位置上。 - div 仍拥有其旧的值。新的 HTML 没有被赋值给任何变量。
nodeValue/data:文本节点内容
innerHTML 属性仅对元素节点有效。
其他节点类型,例如文本节点,具有它们的对应项:nodeValue 和 data 属性。这两者在实际使用中几乎相同,只有细微规范上的差异。因此,我们将使用 data,因为它更短。textContent:纯文本
“hidden” 属性
“hidden” 特性(attribute)和 DOM 属性(property)指定元素是否可见。 ```javascriptBoth divs below are hidden
从技术上来说,hidden 与 style="display:none" 做的是相同的事。
<a name="D7alU"></a>
## 更多属性
大多数标准 HTML 特性(attribute)都具有相应的 DOM 属性,我们可以像这样访问它。<br />如果我们想知道给定类的受支持属性的完整列表,我们可以在规范中找到它们。例如,在 [https://html.spec.whatwg.org/#htmlinputelement](https://html.spec.whatwg.org/#htmlinputelement) 中记录了 HTMLInputElement。<br />如果我们想要快速获取它们,或者对具体的浏览器规范感兴趣 — 我们总是可以使用 console.dir(elem)输出元素并读取其属性。或者在浏览器的开发者工具的元素(Elements)标签页中探索“DOM 属性”。
<a name="SsDKn"></a>
## 总结
每个 DOM 节点都属于一个特定的类。这些类形成层次结构(hierarchy)。<br />完整的属性和方法集是继承的结果。
<a name="JLndR"></a>
# 特性和属性(Attributes and properties)
<a name="zmOfP"></a>
## DOM 属性
<a name="Q1bs9"></a>
## HTML 特性
HTML 特性有以下几个特征:
- 它们的名字是大小写不敏感的(id 与 ID 相同)。
- 它们的值总是字符串类型的。
<a name="N3J16"></a>
## 属性—特性同步
<a name="mpL5y"></a>
## DOM 属性是多类型的
<a name="vqtTl"></a>
## 非标准的特性,dataset
<a name="IB8du"></a>
# 修改文档(document)
<a name="MgFV9"></a>
## 创建一个元素
要创建 DOM 节点,这里有两种方法:<br />用给定的标签创建一个新 **元素节点(element node)**:
```javascript
let div = document.createElement('div');
用给定的文本创建一个 文本节点:
let textNode = document.createTextNode('Here I am');
创建一条消息
// 1. 创建 <div> 元素
let div = document.createElement('div');
// 2. 将元素的类设置为 "alert"
div.className = "alert";
// 3. 填充消息内容
div.innerHTML = "<strong>Hi there!</strong> You've read an important message.";
插入方法
append:document.body.append(div)
这里是更多的元素插入方法,指明了不同的插入位置:
- node.append(…nodes or strings) —— 在 node 末尾 插入节点或字符串,
- node.prepend(…nodes or strings) —— 在 node 开头 插入节点或字符串,
- node.before(…nodes or strings) —— 在 node 前面 插入节点或字符串,
- node.after(…nodes or strings) —— 在 node 后面 插入节点或字符串,
- node.replaceWith(…nodes or strings) —— 将 node 替换为给定的节点或字符串。
insertAdjacentHTML/Text/Element
克隆节点:cloneNode
样式和类
通常有两种设置元素样式的方式:
- 在 CSS 中创建一个类,并添加它:
- 将属性直接写入 style:。
JavaScript 既可以修改类,也可以修改 style 属性。
className 和 classList
元素样式
元素大小和滚动
JavaScript 中有许多属性可让我们读取有关元素宽度、高度和其他几何特征的信息。
我们在 JavaScript 中移动或定位元素时,我们会经常需要它们。
Window 大小和滚动
我们如何找到浏览器窗口(window)的宽度和高度呢?我们如何获得文档(document)的包括滚动部分在内的完整宽度和高度呢?我们如何使用 JavaScript 滚动页面?
窗口的 width/height
为了获取窗口(window)的宽度和高度,我们可以使用 document.documentElement 的 clientWidth/clientHeight:
不是 window.innerWidth/innerHeight
clientWidth/clientHeight 返回的是可用于内容的文档的可见部分的 width/height。
window.innerWidth/innerHeight 包括了滚动条。
文档的 width/height
为了可靠地获得完整的文档高度,我们应该采用以下这些属性的最大值:
let scrollHeight = Math.max(
document.body.scrollHeight, document.documentElement.scrollHeight,
document.body.offsetHeight, document.documentElement.offsetHeight,
document.body.clientHeight, document.documentElement.clientHeight
);
alert('Full document height, with scrolled out part: ' + scrollHeight);
获得当前滚动
alert('Current scroll from the top: ' + window.pageYOffset);
alert('Current scroll from the left: ' + window.pageXOffset);
滚动:scrollTo,scrollBy,scrollIntoView
必须在 DOM 完全构建好之后才能通过 JavaScript 滚动页面。例如,如果我们尝试通过 中的脚本滚动页面,它将无法正常工作。
可以通过更改 scrollTop/scrollLeft 来滚动常规元素。
或者,有一个更简单的通用解决方案:使用特殊方法 window.scrollBy(x,y) 和 window.scrollTo(pageX,pageY)。
禁止滚动
要使文档不可滚动,只需要设置 document.body.style.overflow = “hidden”。该页面将“冻结”在其当前滚动位置上。
坐标
大多数 JavaScript 方法处理的是以下两种坐标系中的一个:

若有收获,就点个赞吧
0 人点赞
