1 简单的方法
不同模态的表现方式不一样,different aspects,存在信息冗余,信息互补,如果能合理的处理多模态信息,就能得到丰富特征信息。
early fusion
属于feature-level,将不同模态的特征融合在一起(特征的联合表征),再用分类器进行分类,主要利用特征间的依赖性。
优点:利用不同模态的多个特征的相关性,只需要训练一个模型
问题:多模态特征的粒度不同,例如时间同步性问题如何解决?(文字Embedding:是一个将离散变量转为连续向量表示的一个方式)
不同模态特征的表示差距太大时,怎么融合?
最终特征集可能会很大,维度可能会很高,是否需要进行选择?
方法:
concatenate:进行连接维度上可以不同,其他维度上必须相同。叠加后某个维度会增加
add:需要特征的形状相同,每一个维度下的信息量增加,维度数没有变化。
add是concatenate的特殊情况,add需要的内存和参数更少,模型训练更快。
late fusion
属于decision-level,对个单模态的特征分别使用分类器(未必相同,pre-train),对所有结果进行融合。
投票,加权或机器学习方法,属于高层次的融合。
优点:决策的表示基本上一致,融合更容易;扩展性更好,更灵活;每个模态可以用更合适的分类器。
缺点:需要多个训练阶段;会忽略特征的相关性;
2 MFAS
对于多层神经模型,MFAS(multimodal fusion architecture search):在各自最深层的特征上融合模态不一定是解决给定多模态问题的最佳方法,哪一层与融合任务相关 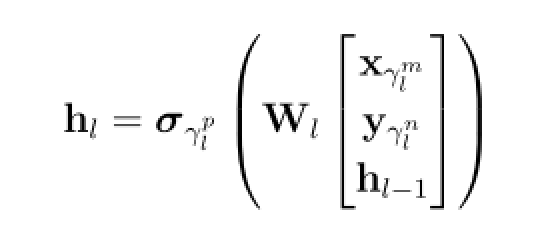
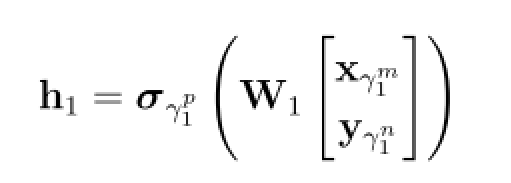
融合层数为L,l ∈ {1, · · · , L},三元体γl=(γml , γnl , γpl),
γml ∈{1, · · · ,M}:第一个模态的层
γnl ∈{1, · · · ,N}:第二个模态的层
γpl ∈{1, · · · ,P}:使用的非线性方法
一个架构所有三元体的集合标示为一个向量[γl]l ∈ {1, · · · , L},L层的所有可能的三元体集合为ΓL
算法

Epochs=3
行14-16用从验证集得到的准确度分数A1训练代理函数π。π的参数在第l次迭代时通过随机梯度下降(SGD)训练对ΓL的一个子集进行更新,实值精度为Al
行18 将这一层的所有可能架构与上一层的架构结合起来
行19-21 π预测计算随机采样的概率,架构i的最终采样概率为,采样K个架构作为融合方案Sl
行22假设存在预先训练的模态函数f和g。从融合方案Sl的描述中建立一个具有l层的多模态网络Ml
行23训练Ml
行24-26用从验证集得到的准确度分数Al更新代理函数π。
行27更新温度,随着迭代次数的增加,温度τ迅速衰减到1
行29从所有采样架构B的集合中返回最佳K
结果
算法结束后从最后K个架构中训练最好的5个,并用验证准确率挑选出绝对最好的一个。
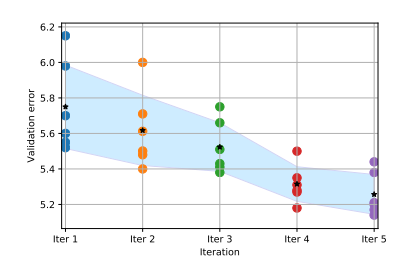
在少数迭代中,找到的架构的准确性的方差相对较高。这可以用采样温度的增加来解释。随着迭代次数的增加和采样温度的降低,方差也随之减少。星星表示平均值,蓝色范围表示方差。
考虑的问题
1.几个epoch?
2个epochs。
2.为什么概率随机抽样?
概率随机抽样比简单地抽取表现最好的K个架构要好。随机抽样使我们的方法能够摆脱局部最小值。我们实现了一个温度驱动的抽样程序,所以搜索空间首先被更随机地探索,同时在最后完全信任代理函数。
介于贪婪的渐进方法和纯粹的随机搜索之间
3.代理函数用什么?
由于渐进式搜索,加上所处理的具有可变长度和连接性的架构类型,用RNN
4.张量维度不同?
我们沿着二维和三维卷积的通道维度进行global pooling,同时让线性层的输出保持原样
global pooling: pooling的 滑窗size 和整张feature map的size一样大。这样,每个 W × H × C 的feature map输入就会被转化为 1 × 1 × C 输出。因此,其实也等同于每个位置权重都为 1 / ( W × H ) 的FC层操作。
实验
1.AV-MNIST视听数据集
第一个模态是28×28的MNIST图像,通过PCA去除其75%的能量。LeNet-3
第二个模态是112×112的频谱图计算的Tidigits数据库中的25,102个发音的数字,通过添加从ESC-50数据集[36]中随机选择的噪声样本而得到增强。LeNet-5
受污染的音频样本与MNIST的数字随机配对,并相应地加上标签,以达到55000对用于训练,10000对用于测试。对于验证,我们从训练集中抽取5000个样本。数字能量去除和音频污染是有意为之,以增加任务的难度。
M=3,N=5,P=2,L=4,
对于验证集,MFAS比纯随机准确率更高,标准差更小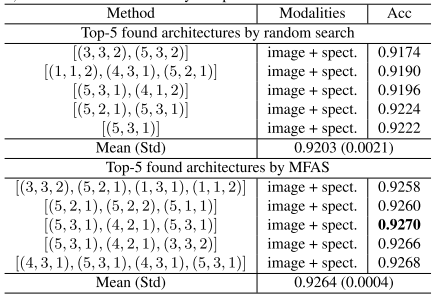

对于测试集,MFAS整体准确率最高
2.MM-IMDB数据集
第一个模态是电影海报,VGG-19图像网络的八个卷积层
第二个模态是电影描述,两个文本Maxout-MLP特征
根据海报和电影描述来预测电影类型。由于很多时候一部电影被归入一个以上的类型,所以分类是多标签的。用于训练的损失函数是二元交叉熵,其权重用于平衡数据集。15,552部电影用于训练,7,799部用于测试,2,608部用于验证。要预测的类型包括戏剧、喜剧、纪录片、体育、西部片、黑色电影等,总共有23个非互斥的类别。
M=8,N=2,P=3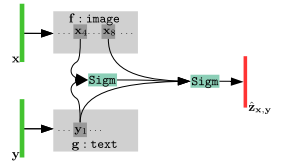

3.NTU RGB+D数据集
拥有56,880个样本,从80个视角捕捉40个主体进行60类活动,它的特点是在RGB视频序列的基础上提供基于骨架的动态姿势数据。目标活动包括喝水、吃饭、摔倒,甚至包括拥抱、握手、打拳等主体互动。
第一个模态是视频,用的Inflated ResNet-50,
第二个模态是基于骨架的动态姿势数据,deep co-occurrence model
将40个主体分成训练组、验证组和测试组。在搜索过程中,训练的主体:1, 4, 8, 13, 15, 17, 19。验证的主体:2,5,9,14。
M=4,N=4,P=3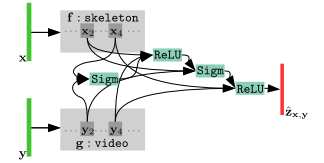


若有收获,就点个赞吧
0 人点赞
