前面讲解 感知机 , 说明其有一个很大的不足之处,即它无法求解非线性问题或者异或问题。后面就发展出了多层感知机(deep feebforward network or multilayer perceptron),以及求解使用的BP算法。这也是深度学习的基础。
 > http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/DL%20(v2).pdf.pdf)
> http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/DL%20(v2).pdf.pdf)
1. 多层感知机
1.1 Neuron

我们将逻辑回归抽象成一个neural network的一个“Neuron”,而多层感知机即是将这些神经元连接在一起。对于深度学习网络来说,它也是有一个个神经元组成,但是它可以有各个不同的网络结构(网络堆叠)。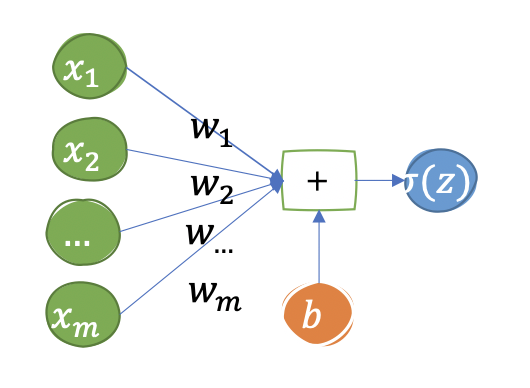
1.2 Multilayer Perceptron
多层感知机,其中一个小白色长方形(f)为一个一个”Neuron”,每一层可以有多个 Neruon, 而多层感知机可以有很多层。其中灰色部分为隐含层(Hidden Layer),绿色为输入层(Input Layer),黄色部分为输出层 (Output Layer) 。蓝色线可以看作是一个权重(w), 而 f 代表激活函数(activate function)。 目前激活函数有很多种,常用的有 Sigmoid、Relu 、Tanh、Leaky Relu、Softmax 等。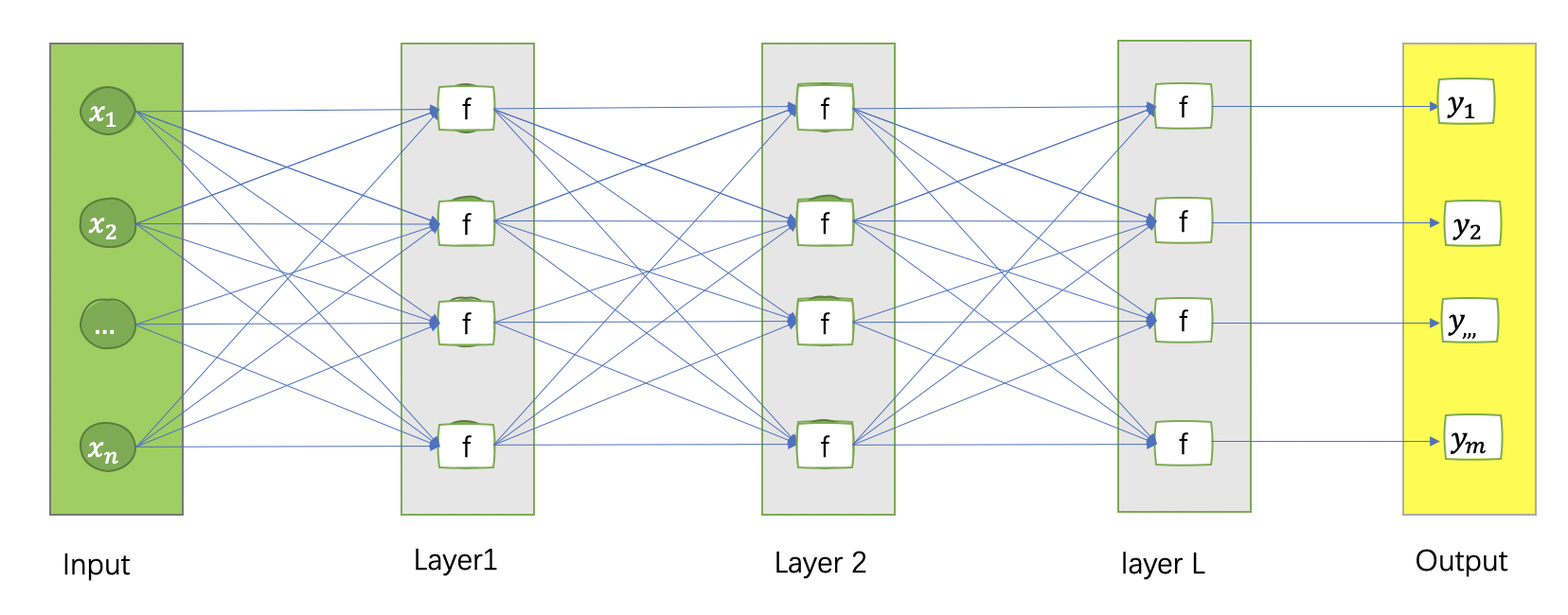
多层感知机是一种监督模型,它可以解决分类和回归问题(输出层的结构有所不同)。一般在解决分类问题时,它会在输出层前增加一层 softmax 处理,来模拟各个分类的概率。
1.2.1 数据流动
数据是如何在感知机内流动的?
本质上,多层感知机是一个个矩阵的乘法运算,它的数据流是从前向后流动的,即 Feedforward
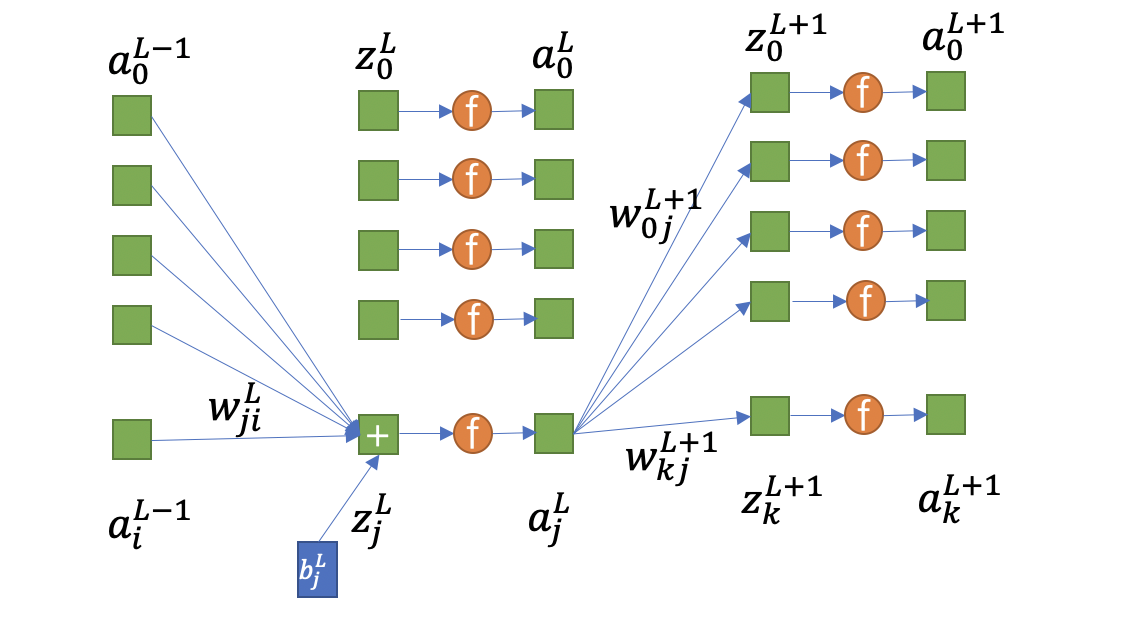
如,输入为  , 其中
, 其中 , 即单个x存在m个特征。
, 即单个x存在m个特征。
对于隐含层第元素有:
 代表第L层的j个z值与第L-1层的第i个输入之间的权重
代表第L层的j个z值与第L-1层的第i个输入之间的权重 代表第L层的偏移量
代表第L层的偏移量 代表第L层输出的第i的元素,同时是第L+1的输入的第i个元素
代表第L层输出的第i的元素,同时是第L+1的输入的第i个元素- f为激活函数


对于输入层有:

对于输出层有(这里不考虑softmax):

数据流通为:

其中 为 jxi 得 matrix, j为第L层的输出Dimensions,i为第L层的输入的Dimensions。
为 jxi 得 matrix, j为第L层的输出Dimensions,i为第L层的输入的Dimensions。
根据公式1, 2,可以推出输出为:

1.2.2 损失函数
由于多层感知机可以处理分类和回归问题,所有其损失函数也分为两类,下面以分类问题为例。
可以看作是多分类问题,这是可以采取最大似然概率来作为其损失函数(交叉熵)。
做分类问题时,需要在输出层之前增加一个 softmax 层。
Tips 这里看出多层感知机其实是一个
discriminative model。
假设共有m个类别  ,
, 为所有的参数,则 Loss Function 为:
为所有的参数,则 Loss Function 为:

或者使用

其中  , one-shot vector 的样式
, one-shot vector 的样式
Tips:
- 如果是回归模型的话,无需添加 softmax 层,而且可以使用 mean square errors 作为损失函数
Thinking
- 式4和式5在使用过程中,有什么区别呢?那个效果更好呢?
了解了损失函数之后,那么如何来寻找损失函数的极大值呢?或者是如何解决这个优化问题呢?这里就引出了BackPropagation, 即BP算法
2. BP算法
由式子(5) 可知, 使用SGD来解该优化问题,在给定x的情况下, 令 c 为损失函数。
首先对隐含层某个参数求偏导数,如 

其中

其中

令  ,
,  ,
, 
则

由于, 故:
因此找到了 和
和 之间的关系,一旦得到了就可以求出。
之间的关系,一旦得到了就可以求出。
令 
又因为:
故有

在输出层有: , 这个要根据具体的损失函数来确定
, 这个要根据具体的损失函数来确定
 这个如果没有 softmax 层或者说是回归问题的话,值因为1
这个如果没有 softmax 层或者说是回归问题的话,值因为1
Tips 如果是softmax的话,应该怎么做?
因此,对最后一个隐含层的输出有

然后一次向前求解,即可求出对所有参数的倒数。
对  求导数时:
求导数时:

因此 

若有收获,就点个赞吧
0 人点赞
