感知机(Perceptron), 是一种二分类的线性分类器。 其输入是一个待分类的实例,输出为该实例对应的类型。
根据模型、策略和算法三部曲,来说:
1. 模型
由于是一个分类器,其函数模型为:

2. 策略
分类问题的误差函数,可以采用误分类个数之和

但是,该函数无法使用梯度下降法来进行求解。可以考虑一下,每个点到该分类器超平点的距离。
2.1 损失函数
假设存在一个超平面 S  ,将特征划分为正、负两个超平面。超平面 S,其中 w是法向量,b为截距,如下图绿线
,将特征划分为正、负两个超平面。超平面 S,其中 w是法向量,b为截距,如下图绿线
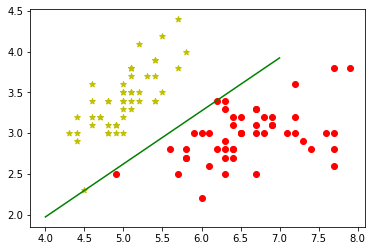
此时,我们采用误分类点到超平面的距离之和来作为损失函数。向量空间的任意一点 x 到超平面S的距离为

由于, 对于误分类的点有:

因此损失函数为:

这里省略掉了 ||w|| 或者说是加了约束条件 ||w|| = 1, 思考为什么可以? 答案见附录 B-1
明显是一个无约束的线性优化问题,转化为优化问题为:

M 是所有误分类的集合,即:

要求解式(4)对应得到优化问题,可以采取随机梯度下降法(SGD),参数更新为:

3. 算法
1. init w and b2. sample an point (x, y) from dataset:3. if (w^Tx + b)y <= 0update parameters w and b as following:w = w + lr*y*xb = b + lr*y4. to (2) util 没有误分类点结束
3.1 Show me code
下面使用了 epoch, 其实完全不用,只需要将
error == 0作为结束条件也一样,因为如果数据是线性可分的话,可以证明能够通过有限次的迭代更新来找到一个超平面的。 使用 epoch 主要是为了方便控制。
for epoch in range(epochs):
x, y = shuffle(x, y) # 这里每次都重新拍不一下数据
error = 0
for i in range(l):
y_i = y[i]*f(x[i],w,b)
if y_i <= 0:
error = error + 1
w = w + lr*y[i]*x[i]
b = b + lr*y[i]
print('{} epoch, error is {}'.format(epoch,error))
if error == 0: # 直到没有误分类数据结束
break
4. 对偶问题
由优化理论可知,任何线性优化问题都有对应的对偶问题。这里采用较为感性的认识来引出它的对偶问题
当 w 和 b 均采用 0 初始化时,假设进行了n次更新,模型对点 (x, y) 误分类了 n 次,则由式子(5)可知:
这里可以思考一下如何证明线性可分的问题可以能够通过有限次的迭代获取一个超平面? 答案见附录 B-1

将w,b 代入到模型中去:

这里就可以简化一下计算的过程,无需每次都重复计算向量之间的内积。

# 相当于对这一步重的 `f(x[i],w,b)` 结果做了一个缓存, 无需重复计算并且对于矩阵运算可以采用 GPU 加速
y_i = y[i]*f(x[i],w,b)
Code
下面是训练过程,代码参考 https://www.kaggle.com/hsjfans/perceptron

总结?
- 通过感知机生成的超平面可能存在多个,不同的初始值可能得到不同的超平面,但是哪一个泛化能力最好呢?这就是 svm要讨论的问题了!
- 感知机是线性的,它无法处理非线性的问题,或者抑或问题。后面会介绍到多层感知机,神经网络是用来解决这个问题的。
附录
以下都是一家之言,如果问题,欢迎斧正~~~
B-1 为什么能够省略掉 ||w||呢?
个人理解主要是两个方面:
- 对于感知机模型来说,其损失函数的最终结果要优化为0,即没有误差点,所以||w||可以固定为1或者不考虑。
- 对于梯度下降过程来讲,我们每次迭代关注符号的正负,而||w||的值对其符号没有影响。
B-2 算法的收敛性
这里参考 《统计学系方法》 p.42
参考

若有收获,就点个赞吧
0 人点赞
