运维开发工程师 全职软件研发类 北京市湖北·武汉市 职位描述
岗位描述: 1、我们为小米的站点稳定性提供系统和工具,是稳定性工程专家; 2、实践DevOps 和 Google SRE的工程思想; 3、站在软件生命周期全局考虑如何保障系统健壮性,稳定性,并通过软件工程技术为站点保驾护航; 4、站在用户/工程师的角度提供易用的工具和平台产品,不断完善使用体验; 5、负责集团基础软件/工具/平台的设计和研发,维护小米各项业务的稳定运行; 6、按照优秀的工程实践完成需求,设计,编码,测试,发布的软件开发流程; 7、按照标准编写设计/开发/运维/用户文。 任职要求: 1、熟练C/C++/Java至少一种编程语言,有Ruby/Python/Bash经验更好; 2、熟悉Linux/Unix系统; 3、熟悉软件开发方法/流程,理解软件设计,开发,测试,发布过程; 4、持续学习,不断追求更好,不断挑战自己,包括: 产品/架构/方案/流程/编码; 5、乐于分享,具备服务精神,良好的沟通能力和团队合作精神; 6、优秀的分析和解决问题能力,勇于解决难题,有“问题到我为止”的精神。
急2022届校招-运维开发工程师 云产品群全职技术类 北京市·海淀区 职位描述 岗位职责: 1、负责存储部门日常工单进度跟进,故障设备维修处理,监控管理等 2、负责业务稳定性项目方案推动落地 3、负责存储服务线上变更操作 4、负责存储自动化工具的开发维护 任职资格: 1、计算机或相关专业本科或以上学历; 2、熟练使用linux系统,熟悉主要系统配置含义和修改方式 3、至少熟悉open-falcon、prometheus中一种开源监控系统的原理 4、至少熟悉shell、Python、go语言中的一种 5、熟悉中间件、例如zk\kafka\memcache\redis的工作原理,有实际操作经验 6、了解网络架构,熟悉掌握DNS缓存原理 加分项: 1、应用运维经验丰富,有线上丰富问题排查、解决经验 2、熟悉业界云存储系统架构和产品服务者优先,如S3,OSS等 3、对react、vue等前端技术有实际开发经验

一面
linux各项命令的使用
深入使用~~
例如netstat里面各项都是什么意思
回答三次握手和四次挥手后:
2.2 2MSL等待状态
2.3 四次挥手释放连接时,等待2MSL的意义?
访问博客使用的是LNMP这些,再深入谈LNMP
只让我写了个排序算法。
1. 自我介绍
2. 实习介绍
3. 网络知识
3.1 OSI七层模型
物理层——连接计算机,线路、无线电之类的
数据链路层——把电信号组织成01之类的
网络层——IP协议在网络层,可以区分不同的计算机用于通信;ARP协议
传输层——TCP,UDP之类的协议在传输层,用于实现端口到端口的通信
会话层——负责建立和断开通信连接
表示层——用于接受不同类型的信息
应用层——HTTP协议,ssh,telnet远程登陆协议,FTP文件传输协议,DNS域名解析协议
3.2 TCP,UDP
TCP和UDP的异同
首先他们都是传输层的协议,负责实现计算机端口间的通信。
TCP是面向连接的协议,需要通过三次握手建立连接,四次挥手断开连接。
UDP是非连接的,想传送数据的时候就直接扔过去。
因此TCP是可靠的传输,UDP是不可靠的传输,UDP可能丢包,不能保证数据顺序。
TCP的包头最小需要20字节,UDP要8字节。
TCP的报文是流模式的(收发可以不同次数),UDP报文是数据报模式的(发一次收一次)。
UDP的优点是它的速度快很多,谷歌为了提高速度就搞了一个基于UDP的QUIC协议。
TCP的三次握手
第一次握手,客户端向服务器发送syn报文(Synchronize同步序列号标志位)表示要建立连接。
第二次握手,服务端收到syn后向客户端回复syn+ack报文(Synchronize-Acknowledge确认应答),表示回复我可以连接。
第三次握手,客户端收到服务端的syn-ack报文后,向服务端发送ack报文。服务端收到ack报文之后,连接就建立了。
为什么会有第三次?防止过去的失效请求又发过来。
TCP四次挥手
第一次挥手,客户端发送一个FIN报文(finis),报文中会指定一个序列号,表示数据已经发送完毕,请求结束连接。这个时候客户端处于FIN_WAIT1状态。
第二次挥手,服务端收到FIN报文后,向客户端回复ack报文,这个ack报文的序号值是刚才客户端发来的值+1,表示我已经收到你的结束请求了,这时候服务端处于CLOSE_WAIT状态。
第三次挥手,服务端像客户端第一次挥手一样,发送一个FIN报文给客户端,并指定一个序列号。此时服务端处于LAST_ACK的状态。
第四次挥手,客户端收到FIN后,也会回答一个ack,这时客户端处于TIME_WAIT状态。然后服务端收到这个ack后,连接正式断开。
3.3 HTTP协议
HTTP协议是网络请求协议,位于应用层。
HTTP报文包括 { 起始行start line[请求、响应];头部header;主体body }
HTTP报文分成 { 请求报文requset;响应报文response }
典型的请求方法有GET,POST,HEAD,PUT,DELETE等
http响应码(状态码)
- 1XX 指示信息——100表示请求已接受,请客户端继续
- 2XX 成功——200 OK成功;204 Not Content正常响应没有实体;206 Partial Content返回部分数据
- 3XX 重定向——要完成请求必须进行更进一步的操作;301永久重定向,就是请求的url移除了给你导向了另一个;302,303临时重定向
- 4XX 客户端错误——400请求报文有语法错误;401请求未授权;403 Forbidden 服务器拒绝提供服务;404 not found 找不到资源
- 5XX 服务端错误——500 Internal Server Error服务器故障;503 Server Unavailable服务器繁忙
https(http over SSL)就是在http的基础上家里加密处理,SSL加密协议,认证,完整性保护啥的。
3.4 DNS域名解析协议
DNS是一个用来把域名映射成IP地址的系统。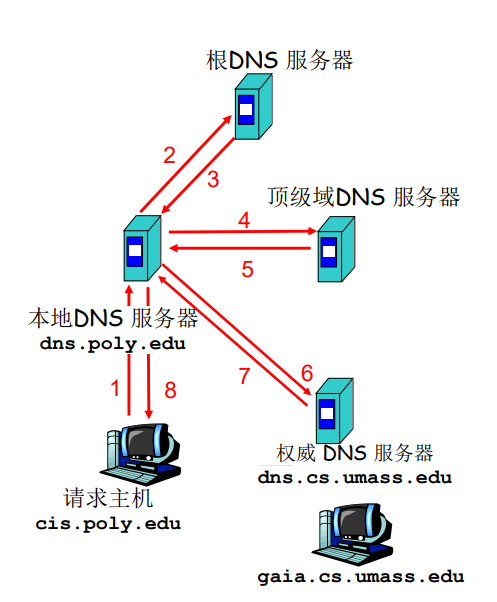
3.5 cookie和session的概念和区别?
cookie的概念:
(1)HTTP 协议是无状态的,为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP 引入 Cookie 来保存状态信息。
(2)Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。
session的概念:
(1)Session 是另一种记录客户状态的机制,不同的是 Cookie 保存在客户端浏览器中,而Session 保存在服务器上。
(2)客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是 Session 。客户端浏览器再次访问时只需要从该 Session中查找该客户的状态就可以了。
cookie与session之间的区别
(1)cookie数据存放在客户的浏览器上,session数据放在服务器上
(2)cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
(3)session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
(4)单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
(5)所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
3.6789 其他
ping命令属于ICMP协议,与IP协议、ARP协议等位于网络层。
arp协议是实现IP地址到mac地址的映射。
4 linux
4.1 常用Linux命令
ls
cd
sudo :以root身份执行命令,如果本身是root就不用。
w : 显示正在使用的用户
cat :查看文件内容
rm : 删除文件
systemctl :可以查看一些软件服务的状态运行状况,启动软件(apache,ngnix之类)
journalctl :查看所有日志(内核日志和应用日志)
↑ 只适用centos7之后的利用Systemd统一管理的
wget :用来下载的软件,可以直接wget 下载链接
yum :是redhat系列-linux的软件包管理工具
rpm :是用来安装卸载rpm软件的
一般yum install 软件名 没有的话,就会用wget先下载一个rpm包,然后用rpm命令安装。
安装 rpm -ivh *.rpm
mv : Linux mv(英文全拼:move file)命令用来为文件或目录改名、或将文件或目录移入其它位置。
grep :用于查找文件中符合条件的字符串,
怎么用grep排除呢?grep -v
tail : 可以显示一个或多个文件的最后一部分 tail -50 some.log | grep “fail”
经常用以上两个组合来查看日志
目录在 /var/log
ps (process show): 查看进程 ps -e 查看所有进程和环境变量 ps aux
top :实时显示各个进程情况,类似任务管理器
pstree :用树状图展示进程间的派生关系
kill: 可以杀死进程
df :查看磁盘空间
free : 查看内存空间
sed (stream editor): sed是面向行处理的工具,
cut :在文件中剪切数据
wc:计算文件的byte数(-c),字数(-w)或列数(-l)
※iptables
iptables时集成在Linux内核中的包过滤防火墙系统。
——待补充
如何查看占用端口8080的进程。
方法1 使用lsof命令
lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。
使用IPv4协议的局域网:
执行命令: lsof -Pnl +M -i4|grep 8080
输出结果: java 1419 1401 10u IPv4 6793357 TCP *:8080 (LISTEN)
方法2 先使用 netstat命令,再用 ps命令
执行命令: netstat -anp|grep 8080
输出结果: tcp 0 0 :::8080 :::* LISTEN 12006/java
执行命令: ps -ef | grep 12006
输出结果: root 12886 12851 0 Dec09 ? 00:01:14 /home/bjca/bea/jdk160_05/bin/java -client -Xms256m -Xmx512m -XX:CompileThreshold=8000 -XX:PermSize=48m -XX:MaxPermSize=128m……
如何关闭防火墙
systemctl stop firewalld 暂时关闭防火墙
service iptables stop
systemctl disable firewalld 永久关闭防火墙
service iptables off
4.2 vim
vim三个模式
- 命令模式
- 输入模式
- 查看模式
命令模式输入冒号+/用于搜索查找 :/abcd 搜索abcd字符串
查找结果按n表示next,N表示查看上一个
5. 操作系统知识
5.1 关于进程与线程
什么时候要用到多线程?
多线程的使用主要是用来处理程序在一部分上阻塞,在另一部分上需要持续运行的场合。
5.2 并发和并行有什么区别
5.3 进程通信方式
5.4 进程同步方式
5.5 什么是死锁,死锁产生的必要条件是什么
5.6 什么是缓冲区溢出
6. 用过哪些数据库
6.1 MySQL
MySQL查询语言你了解哪些MySQL支持哪些事物<br /> MySQL读写分离原理<br /> MySQL读写分离出现故障,导致主从数据不一致,说说你的排错思路,你应该则么去做
6.2 Mongodb
MongoDB是一个文档数据库,是一个非关系型数据库,易扩展,高性能,高可用性。
插入文档的命令:db.collection.insert_one( )或insert()
使用索引的基本命令:db.collection.ensureIndex( {KEY: 1} ),key指的是键名。
查找的命令:db.collection.find({KEY:skjdk })
创建集合:db.createCollection(name, options) (一般直接db.name或db[name]就行)
集合只有在里面有数据了之后才正式创建。
删除集合:db.collection.drop( )
集合就相当于sql中的表。 collection里面的键值对组 叫做文档。
mongodb不支持主键外键关系。
分片:在多台计算机存储数据记录的过程。
什么时候用nosql?
处理非结构化或者半结构化数据时(sql是结构化的数据);
需要随时应对动态增长的数据项时;
在水平方向上扩展时(增加服务器就能增加性能);
垂直扩展指的是提高单机处理能力。
大多数情况下应该优先考虑关系型数据库。
schema:数据库的组织和结构。(表,列,对象,关系之类的)
6.3 redis
redis也是nosql,它不仅能用作数据库,还能用作缓存和消息中间件。
redis响应快
应对高并发能力强。
缺点:缓存击穿、缓存雪崩
redis 数据类型<br /> redis主从同步<br /> redis高可用方案(哨兵、集群)
7. 算法、数据结构
7.1 快排一把梭
快排的实现思想是什么,如何实现的
def quick_sort(alist, start, end):"""快速排序"""if start >= end: # 递归的退出条件returnmid = alist[start] # 设定起始的基准元素low = start # low为序列左边在开始位置的由左向右移动的游标high = end # high为序列右边末尾位置的由右向左移动的游标while low < high:# 如果low与high未重合,high(右边)指向的元素大于等于基准元素,则high向左移动while low < high and alist[high] >= mid:high -= 1alist[low] = alist[high]# 走到此位置时high指向一个比基准元素小的元素,将high指向的元素放到low的位置上,# 此时high指向的位置空着,接下来移动low找到符合条件的元素放在此处# 如果low与high未重合,low指向的元素比基准元素小,则low向右移动while low < high and alist[low] < mid:low += 1alist[high] = alist[low]# 此时low指向一个比基准元素大的元素,将low指向的元素放到high空着的位置上,# 此时low指向的位置空着,之后进行下一次循环,将high找到符合条件的元素填到此处# 退出循环后,low与high重合,此时所指位置为基准元素的正确位置,左边的元素都比基准元素小,右边的元素都比基准元素大alist[low] = mid # 将基准元素放到该位置,# 对基准元素左边的子序列进行快速排序quick_sort(alist, start, low - 1) # start :0 low -1 原基准元素靠左边一位# 对基准元素右边的子序列进行快速排序quick_sort(alist, low + 1, end) # low+1 : 原基准元素靠右一位 end: 最后if __name__ == '__main__':alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]quick_sort(alist, 0, len(alist) - 1)print(alist)
7.2 排序算法
常见的排序方法有哪些?
稳定的:冒泡排序、插入排序、归并排序
不稳定的:选择排序、希尔排序、快速排序、堆排序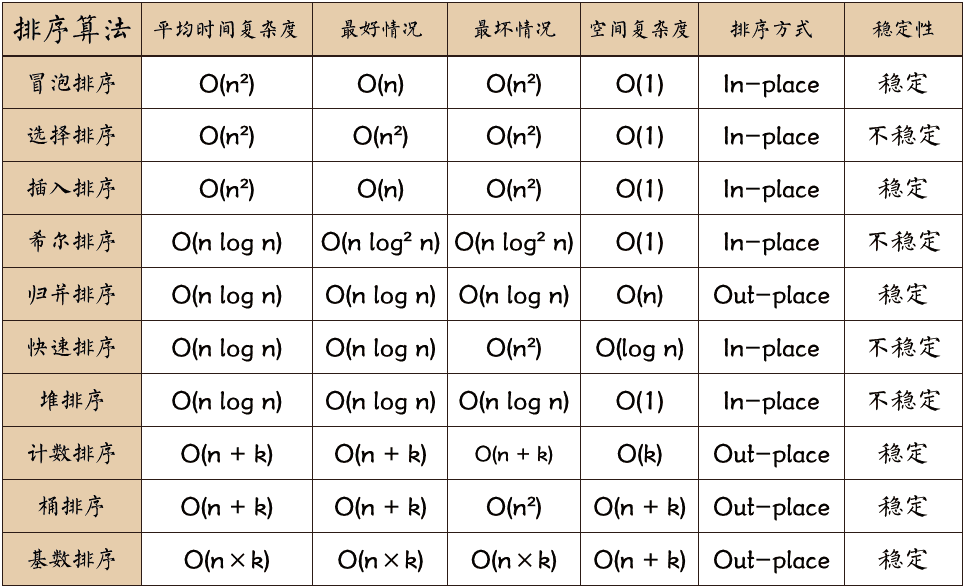
冒泡排序
# -*- coding:utf8 -*-def bubble_sort(li):for i in range(len(li),0,-1):for j in range(i-1):if li[j] > li[j+1]:li[j],li[j + 1]=li[j+1],li[j]# print('-'*10)li = [54,26,93,17,77,31,44,55,20]bubble_sort(li)print(li)
选择排序
# -*- coding:utf8 -*-def selection_sort(alist):n = len(alist)# 需要进行n-1次选择操作for i in range(n - 1):# 记录最小位置min_index = i# 从i+1位置到末尾选择出最小数据for j in range(i + 1, n):if alist[j] < alist[min_index]:min_index = j# 如果选择出的数据不在正确位置,进行交换if min_index != i:alist[i], alist[min_index] = alist[min_index], alist[i]alist = [54, 226, 93, 17, 77, 31, 44, 55, 20]selection_sort(alist)print(alist)
插入排序
# -*- coding:utf8 -*-def insert_sort(alist):# 从第二个位置,即下标为1的元素开始向前插入for i in range(1, len(alist)):# 从第i个元素开始向前比较,如果小于前一个元素,交换位置for j in range(i, 0, -1):if alist[j] < alist[j - 1]:alist[j], alist[j - 1] = alist[j - 1], alist[j]alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]insert_sort(alist)print(alist)
7.3 数据结构
树跟图的区别是什么?
树是图,图不一定树,树一定没有环,图可以有环
树是有向无环图。
8. 一些软件
8.1 Docker
Docker是一个用于创建容器的引擎,我的理解容器就是类似虚拟机技术但比虚拟机更加轻量化,能实现方便的在不同环境复制迁移。
我之前实习的时候让我部署腾讯的蓝鲸平台,就把不同的功能都装进了Docker,还实现了模块化。
有一个很好的比喻就是容器container是一个饭盒,然后程序员准备好饭摆放好各种菜,就可以直接交给下一个程序员,下一个程序员不用关心里面装了什么,也不用关心需要怎么样的配置文件,怎么样的版本,能减少很多沟通成本。
Docker之间可以共用资源。
Docker的口号
“Build, Ship and Run”
“Build once,Run anywhere”
如何使用Docker?
Docker技术有三大核心概念:
- 镜像Image
- 容器Container
- 仓库repository
8.2 k8s
k8s也就是kubernetes。
kubernetes脱胎于Google的Borg大型集群管理系统。
8.3 cmdb
配置管理数据库。
8.4 zabbix
zabbix是一款基于web的监控服务器的软件。
类似的——promethues
8.5 nginx
ngnix是一个轻量级的反向代理web服务器,能支持上万的并发连接。可以通过不同的负载均衡算法来解决请求量过大的问题。
ngnix的好处和作用
- 跨平台、配置简单
- ※支持高并发连接(支持负载均衡,官方描述一个支持5万访问)、
- 稳定性高(很少宕机)
- 内存消耗小(10~20M)
- nginx内置健康检查功能,如果有服务器宕机 再发送的请求 就不会发送到宕机的服务器了。
- 节省宽带(支持GZIP压缩)
- 接收用户请求是异步的(异步非阻塞的处理机制:提供队列排队解决——这也是ngnix性能非常高的原因)
- 反向代理
- 高扩展性
- 开源
- 可以用一台服务器虚拟出很多个网站
什么是负载均衡(Load Balancing)? 将工作负载分布到多个服务器来提高网站、应用等服务的性能和可靠性。
什么是正向代理和反向代理? 正向代理:客户端知道要到达的目标服务器,发送请求到一个代理服务器让其到达目标服务器(如翻墙)。 反向代理:请求统一被nginx接收,然后nginx的反向代理服务器按照一定规则再分发给后端的业务处理服务器。(反向代理隐藏了源服务器,比较安全)
缺点:动态页面处理比较差。
参考:https://www.nginx.org.cn/article/detail/451
Apache与nginx的异同及优缺点比较
apache同步多进程(一个连接对应一个进程),ngnix异步;
apache比较适合配上php,ngnix需要配合其他后端;
apache做动态比较合适;
apache配置没有ngnix简洁。
9. 我自己能说出来的一些其他的东西
9.1 关于IaaS,Paas和SaaS
10. 一些计算机基础
10.1 左移右移
左移:(转化成)二进制数向左移动,高位移出,低位补零。
没有溢出的时候数学意义是乘以2的n次方(n为左移的位数)
右移:(转化成)二进制数向右移动,低位移出,高位补零。
相当于除2的n次方(n为右移的位数)
11. 编程语言
11.1 Shell
bash
echo 用来打印数据
$ 表示引用变量名
11.2 Python
Python装饰器是什么?
装饰器也是一个python函数,它可以让其他的函数在不做代码改动的情况下增加其他的功能,装饰器的返回值也是一个函数。
装饰器应用场景:
- 引入日志
- 函数执行时间统计
- 执行函数前的预备处理
- 执行函数后的清理功能
- 权限校验等
——目前还没有机会用到,用到了再补充
python常用的数据类型
不可变:当修改值时,会再申请一块新的内存空间,不再是之前的内存空间。
整数int(所以python不支持++操作)
字符串string
浮点数double
布尔型bool
元组tuple ()
可变:改变值时,就在这一块内存空间直接改变值。
列表list []
字典dict {key:value}
集合set {} 集合是无序非重复的
python中的is和==的区别:
python中的一切都是对象。
is叫做同一性运算符 ==叫做比较操作符
is 比较的是两个对象的id值是否相同,也就是比较两个对象是否是同一个实例对象,是否指向同一个内存地址。
== 是用来判断两个对象的value是否相同。
python的垃圾回收机制你知道吗?
以引用计数为主,标记-清除和分代收集为辅。
- 引用计数:引用计数表示记录对象被引用的次数,如果有新的引用指向对象,对象引用计数就+1,引用被销毁时,对象引用计数就-1,当某个对象的引用计数变为0的时候内存就被释放了。
- 标记清除:标记对象,然后清除垃圾。
- 分代收集:原理是(对象存在的时间越长越有可能不是垃圾)。
python常用的魔术方法?(类中定义)
init(构造函数)
初始化实例后的对象,对new创建的对象进行初始化。
new
负责创建类的实例对象
new方法必须有返回值,如果init和new都存在,先执行new。
new可以调用其他类的构造方法或直接返回别的对象来作为本类的实例。
str
类中的str方法会打印这个方法return的数据。
通常用来返回一段字符串来表示这个对象的描述信息。
del
程序运行结束的时候,把对象进行销毁。
一般参数是self __del__(self)
lambda函数是什么?使用场景?
lambda函数是匿名函数,当不想给函数命名的时候可以用lambda来简单定义一个函数。
一般是lambda关键词后面接参数,一个冒号,然后一个表达式。f = lambda x, y, z : x + y + z
第一个问的我是进程跟线程的区别,这个问题不能不会,很多面试都会问到。
第二个问的是我有没有做过关于线程的项目,我做过一个线程并发拷贝程序,后来技术员问我,为什么要使用线程来做这个项目。
第三个问的是常见的排序方法有哪些,我给他回答了几个;
第四个是问我快排的实现思想是什么,如何实现的。
第五个问的我是树跟图的区别是什么。
期间还问了几个关于网络的问题,问tcp/ip各层的协议有哪些,这个是我的优势,我跟他回答上来了。
—————————————
DevOps

若有收获,就点个赞吧
0 人点赞
