
Collection集合
// 交集:C = A ∩ B// 并集:A U B = B U ACollection coll<T> = new ArrayList<T>();// 创建collectionboolean add(Object obj)// 添加元素到当前集合中boolean addAll(Collection<?> c);// 将c集合中的所有元素添加到当前集合中boolean remove(Object obj);// 删除集合中找到的第一个与obj对象equals的元素,返回trueboolean removeAll(Collection<?> c);// 删除与coll集合相同的元素void retainAll(Collection<?> c);// 从集合中删除不包含c集合中的元素boolean isEmpty();// 判断当前集合是否为空集合boolean contains(Object obj);// 判断当前集合是否存在与obj对象equals的元素boolean containsAll(Collection<?> c);// 判断c集合中元素是否都在当前集合中int size();// 获取当前元素集合中的实际存储的元素数量boolean retainAll(Collection<?> c);// 当前集合变成与c交集的元素 (coll=coll ∩ c)Object[] toArray();// 返回包含当前集合中所有元素的数组void clear();// 清空集合Iterator iterator();// 返回一个迭代器
Collections
Collections后面有多了一个s 它是一个操作Set、List、Map等集合的工具类,提供了一系列静态方法对集合进行排序、查找修改等操作 提供了对集合对象设置不可变、对集合对象实现同步控制等方法
boolean addAll(Collection<?super T>c, t...elements);// 将所有指定元素添加到指定collection中int binarySearch(List<?extends Comparable<?super T>>list, key);// 寻找元素下标,List是可比较大小的,List是有序的int binarySearch(List<?extends T>list, T key, Comparator<?super T>c);// 寻找元素下标,List按照C比较器规则排序过的数组进行寻找T max(Collection<?extends T> coll);// 在集合coll中寻找最大值void reverse(List<?>list);// 反转指定列表List中 元素的 顺序void shuffle(List<?>list);// List集合元素进行随机排序void sort(List<T> list);// 自然顺序升序void sort(List<T>list, Comparator<?super T>c);// 根据Comparator产生的顺序对List集合进行排序void swap(List<?>list, int i, int j);// 交换list集合中i和j索引位置的元素int frequency(Collection<?>c, T o);// 返回集合c,o出现的次数void copy(List<?super T>dest, List<? extends T>src);// 将src的元素复制到dest中boolean replaceAll(List<T>list, T oldVal, T newVal);// 使用newVal替换所有oldVal// Collection类提供了多个synchronizedXxx()方法// 该方法可使将指定集合包装成线程同步的集合// 从而可以解决多线程并发访问集合时的线程安全问题// Collections类中提供了多个unmodifiableXxx()方法// 该方法返回指定的集合是不可修改的视图。
Iterator->迭代器

Collection<Integer> c = new ArrayList<>();c.add(1);c.add(2);c.add(3);c.add(4);c.add(5);// 迭代器获取Iterator<Integer> it = c.iterator();while(it.hasNext())System.out.println(it.next());E next();// 返回迭代的下一个元素boolean hasNext();// 如果有元素可以迭代,返回truevoid reomve();// 通过迭代器删除元素
foreach
foreach它是在jdk5后出现的 foreach底层实现实际上就是普通的for循环实现的 foreach遍历集合的实现也是一个迭代器
// 遍历数组a = {1,2,3};for(int i: a)System.out.println(i);// 遍历集合Collection<Integer> c = new ArrayList<>();c.add(1);c.add(2);c.add(3);c.add(4);c.add(5);for(Integer i: c)System.out.println(i);
Iterable自定义迭代器
List集合
List的特点:
- List继承自Collection可以使用Collection相关方法
- 新增了一些根据元素索引来操作集合的特有方法
- 线性存储,带索引有序的集合,有重复的元素
- 遍历效率快,增删效率慢
ArrayList
ArrayList底层使用数组存储结构,所以查询快,增删慢
可变长数组的原理:
- jdk8中,默认初始容量为0,
- 在首次添加一个元素时初始化容量为10
- 每次添加修改modCount属性值
- 每次添加元素都会查询容量是否足够,当容量不足时进行扩容,扩容大小为原容量的1.5倍
(size+(size>>1))
// List继承了Collection接口中的方法List<E> list = new ArrayList<>();// list创建void add(int index, Object obj);// 往指定位置添加boolean addAll(int index, Collection cDF);// 将c集合添加到指定位置E remove(int index);// 弹出指定位置的元素(删除并返回)E set(int index, E ele);// 弹出指定位置的元素并使用ele进行替换E get(int index);// 获取指定位置的元素List subList(int from, int end);// 返回List从[from, end)的元素int indexOf(Object obj);// 返回obj的位置,没有返回-1int lastIndexOf(Object obj);// 返回obj最后一次的位置,没有返回-1
ListIterator
List特有的迭代器
ListIterator<E> List.listIterator();// 创建迭代器ListIterator<E> List.listIterator(int index);// 从指定位置开始创建,[index, size())void add();// 添加元素到对应集合void set(E obj);// 替换正迭代的元素void remove();// 删除刚迭代的元素boolean hasPrevious();// 逆向遍历,后方是否还有元素E previous();// 返回列表中前一个元素int previousIndex();// 返回列表中前一个元素的索引int nextIndex();// 返回下一个索引boolean hasNext(); E next();// 继承原迭代器
LinkedList
- 继承对象:AbstractSequentialList 类
- 实现接口:
- Queue接口:可作为队列使用
- List接口:可进行列表相关操作
- Deque接口:可作为队列使用
- Cloneable接口
LinkedList是List接口的常用实现类 LinkedList底层存储数据使用(双向链表) 特点增删快,查询慢 可以实现双端队列、队列、栈
// 链表LinkedList list = new LinkedList();V indexOf(V v); // 获取索引位V set(int index, V v); // 更新指定位置元素V remove(int index); // 删除索引元素// 队列Queue queue = new LinkedList();void addFirst(V V); // 首部入队void addLast(V V); // 尾部入队V getFirst(); // 首部读取V getLast(); // 尾部读取V removeFirst(); // 首部弹出V removeLast(); // 尾部弹出V peek(); // 只获取不出队V poll(); // 弹出最早进入的元素// 栈Stack stack = new Stack<>();void push(V V); // 压栈V pop(); // 弹栈// 堆Priority minheap = new PriorityQueue(); // 最小堆add(V v) offer(V v); // 压入remove() poll(); // 弹出
Vector
Stack
它是栈结构
Set集合
Set接口是Collection的子接口,但比collection接口更加严格 set集合不允许有相同元素(引用类型要注意) 如果添加相同元素则忽略重复元素
set判断重复的方法是用equals进行判断的, 当this.equals(obj)返回true时,这个元素就是重复的
HashSet
HashSet底层以数组+链表的形式进行存储的 HashSet集合判断两个元素相等的标准 存储无序的
boolean add();// 添加,存在返回falseboolean contains();// 是否存在,存在返回trueboolean remove();// 删除,成功返回trueint size();// 返回元素数量// 迭代for(E e: set)print(e);
LinkedHashSet
存储有序的,它在HashSet的基础行,在节点中新增两个属性
before和after维护了节点的前后添加顺序 性能略低于HashSet
SortedSet
有序集合
TreeSet
二叉树,实现了自动排序功能 底层使用平衡二叉树 查询效率高于链表
TreeSet存取元规则 存储元素时根据当前加入与已有元素比较的结果决定元素加入的位置 结果负数时放左边,结果为正时放右边,结果为0时则覆盖
List和set的各接口的特征和特点
- List:接口,元素可重复,有序(存取顺序一致)
- ArrayList:底层结构为数组,查询快,增删慢,线程不安全
- LinkedList:底层结构为链表,查询慢,增删慢
- Vector:底层结构为数组,线程安全,效率低
- set:接口,元素唯一性
- HashSet:底层结构为Hash表。查询和增删效率都高
- TreeSet:底层结构为红黑树,查询效率高于链表,增删效率高于数组,元素实现排序
- LinkedHashSet:底层结构为hash表+链表,链表保证元素的有序
Map集合
双列集合,数据以键值对组成。 在map中值的可重复的,但键必须要是唯一的
HashMap
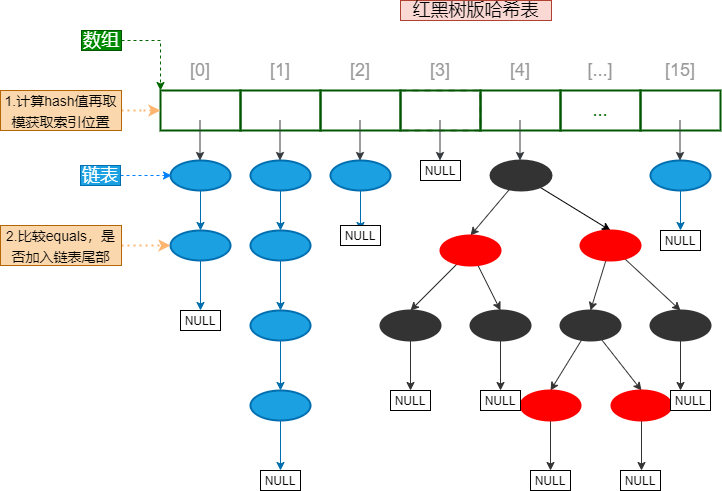
hashmap的底层原理:
- 底层数据结构:哈希表 = 数组 + 链表 + 红黑树
- 创建hashMap时,底层的数组容量是多少
- 为什么用到红黑树?
- 链表长度过长会降低查询效率,这时会转成红黑树,具体何时转换,何时再退化
- 当链表数量为8时,转换为红黑树。
- 当只有6个时退化为链表
- 容量不足时底层数组进行扩容,具体多少扩容,新容量多少?
- JDK7 与 JDK8中比较
/* 增改 */V put(K key, V value);// 添加或修改散列表,添加时返回null,修改时返回原值void putAll(Map<? extends K, ?extends V> m);// 添加一个键值对类型相同的散列表boolean replace(K key, V value);// 修改后返回原值boolean replace(K key, V oldValue, V newValue);// 只对key,oldValue修改newValue,修改成功返回true/* 删 */V remove(K key);// 删除某个键值对,并返回K对应的Vvoid clear();// 清空散列表/* 查 */V get(K key);// K键查询V值,V getOfDefault(k key, v valDefault);// k键查询v值,没有返回默认值Set<K> keySet();// 返回所有键Collection<V> values();// 返回所有值boolean isEmpty();// 判断散列表是否为空boolean containsKey(K key);// 判断键中是否有keyboolean containsValue(V value);// 判断值中是否有valueSet<Map.Entry<K,V>> entrySet();// 返回一个set的集合int size();// 返回散列表元素数量封捷/* 进阶操作 */void replaceAll(BiFunction<?super k,?super v,?extends v> function); // (k,v) -> v+10// 对所有元素进行修改void forEach(BiFunction<?super k,?super v> action); // (k,v) -> System.out.println(k+v)// 映射指定操作,不会修改散列表V merge(K key, V value, BiFunction<?super v,?super v,?extends v>remappingFunction);// 判断k是否存在,如果不存在写入k v,否者oldValue和value在remappingFunction中计算V computeIfAbsent(k key, Function<?super k,?extends v>remappingFunction);// 检查是否有key,如果有不操作,如果没有remappingFunction并返回V computeIfPresent(k key, BiFunction<?super k,?super v,?extends v>remappingFunction);// key, (k,v)->v+20// 检查是否有key,如果没有不操作,如果有remappingFunction并返回/* 遍历 */// keySet()获取所有键后,再遍历获取值for(K i: keySet())System.out.println("key=" + i + " value=" + get(i));// 获取一段键值对后使用getKey()和getValue()for(Map.Entry<String,Integer> item: entrySet())System.out.println("key=" + item.getKey() + " value=" + item.getValue());// 映射散列表forEach((k,v)-> System.out.println("key=" + k + " value=" + v));// 获取所有值后使用增强forfor(V v: values()) // 返回值System.out.println("value=" + v);
sortedMap
TreeMap
基于红黑树(Red-Break tree) 的NavigableMap实现 该映射根据键的自然顺序进行排序,或则根据创建映射提供的Comparator进行排序
Hashtable
Properties
Set去重规则
保证添加的元素按照equals判断时,不能返回true。 true表示他们是相同的
class Student{String name; int age;@Overridepublic boolean equals(Object o){if(this==o) return true;if(o==null ||| getClass()!=o.getClass())return false;Student s = (Student)o;if(age!=s.age) return false;return Objects.equals(name, s.name);}// 一致性:相同的对象,必须要有相同的散列码// 在哈希表的链表中,@Overridepublic int hashCode(){return 31 * (name!=null?name.hashCode():0) + age;}@Override // java自带的散列码校准public int hashCode() {return Objects.hash(name, age);}// 31 -> (2<<5)-1, 哈希值越大冲突越小,尽量以2的n次幂-1为主// 素数不能被1以外的数整除,也能减少冲突}
Tree排序规则
存储元素时根据当前加入与已有元素比较的结果决定元素加入的位置 Tree对象对比使用
Comparator接口,重写Compare结果负数时放左边,结果为正时放右边,结果为0时则覆盖
/* 自定义排序规则1 */Map<Student, Integer> map = new TreeMap<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o1.age - o2.age;}});/* 自定义排序规则2 */Map<Student, Integer> map = new TreeMap<>(new Student());class Student implements Comparator<Student>{String name;int age;@Overridepublic int compare(Student o1, Student o2) {return o1.age - o2.age;}}

若有收获,就点个赞吧
0 人点赞
