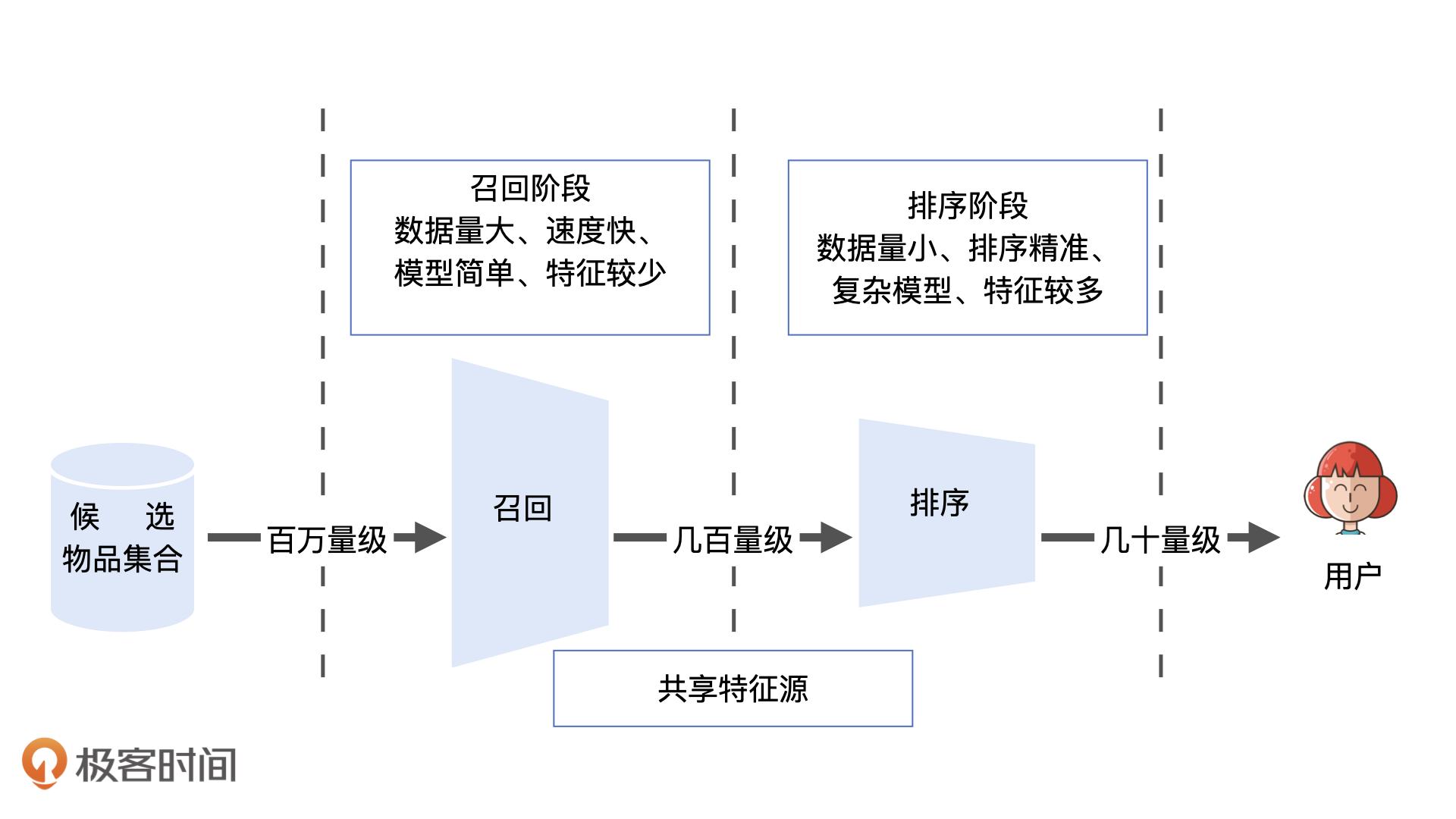
- 召回层排序曾解决的问题
- 召回:快速、准确地过滤出相关物品,缩小候选集。
- 排序:以提升推荐效果为目标,作出精准的推荐列表排序。
- 召回层和排序层的功能特点
单策略召回
- 含义:通过制定一条规则或者利用一个简单模型来快速地召回可能的相关物品。这里的规则其实就是用户可能感兴趣的物品的特点。
- _例子:在推荐电影的时候,我们首先要想到用户可能会喜欢什么电影。按照经验来说,很有可能是这三类,分别是大众口碑好的、近期非常火热的,以及跟我之前喜欢的电影风格类似的。基于其中任何一条,我们都可以快速实现一个单策略召回层。比如:如果用户对电影 A 的评分较高,比如超过 4 分,那么我们就将与 A 风格相同,并且平均评分在前 50 的电影召回,放入排序候选集中_
问题:大多数时候用户的兴趣是非常多元的,他们不仅喜欢自己感兴趣的,也喜欢热门的,也喜欢新上映的。此时,单一策略就难以满足用户的潜在需求。
多路召回
含义:采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用。
- 例子:_电影推荐中常用的多路召回策略,包括热门电影、风格类型、高分评价、最新上映以及朋友喜欢等等。除此之外,我们也可以把一些推断速度比较快的简单模型(比如逻辑回归,协同过滤等)生成的推荐结果放入多路召回层中,形成综合性更好的候选集。具体的操作过程就是,我们分别执行这些策略,让每个策略选取 Top K 个物品,最后混合多个 Top K 物品,就形成了最终的多路召回候选集。整个过程就如下所示:_
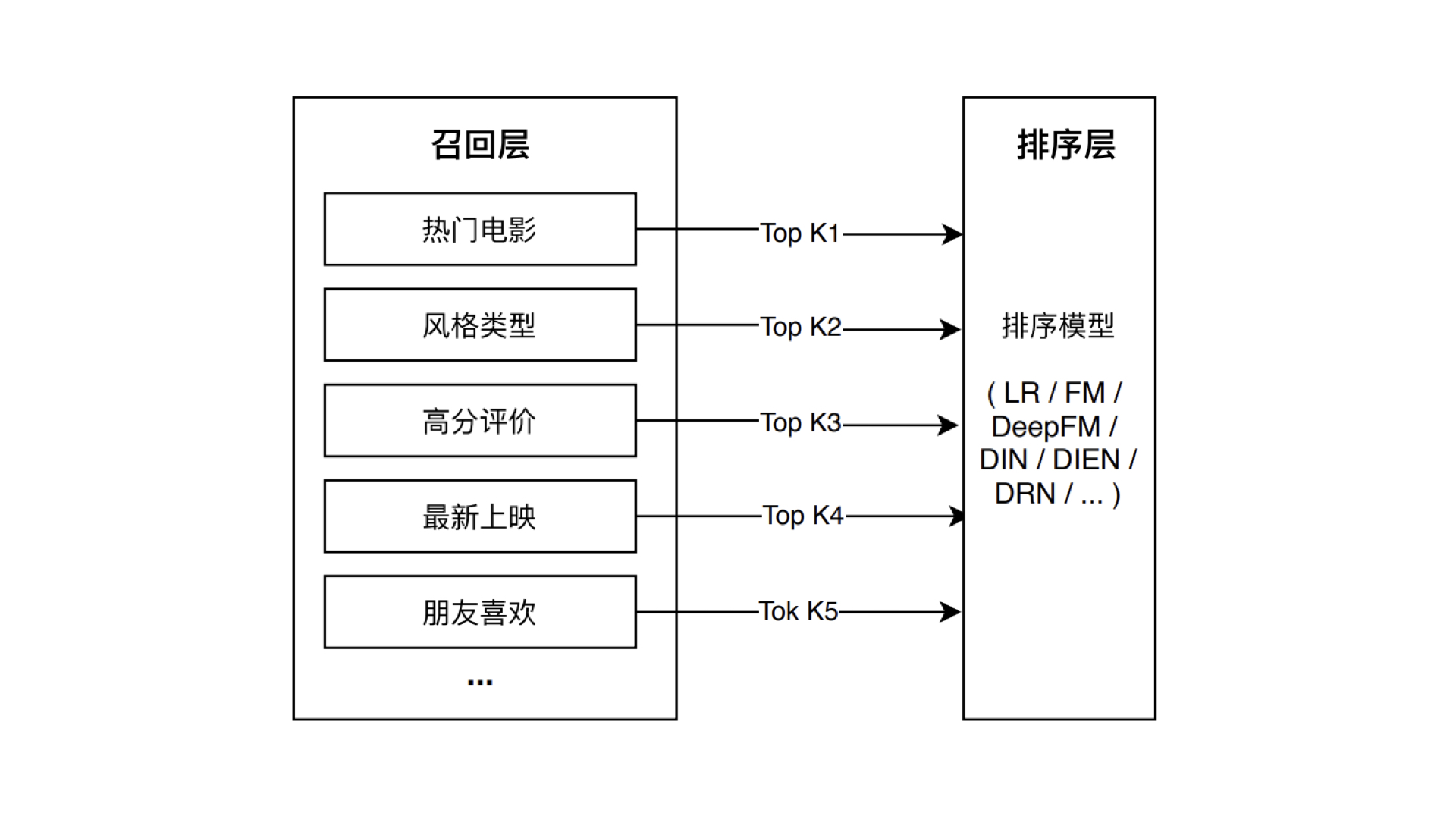
问题:在确定每一路的召回物品数量时,往往需要大量的人工参与和调整,具体的数值需要经过大量线上 AB 测试来决定。此外,因为策略之间的信息和数据是割裂的,所以我们很难综合考虑不同策略对一个物品的影响。
基于Embedding的召回方法
含义:利用物品和用户 Embedding 相似性来构建召回层。
- 原因
- 多路召回中使用的“兴趣标签”“热门度”“流行趋势”“物品属性”等信息都可以作为 Embedding 方法中的附加信息(Side Information),融合进最终的 Embedding 向量中 。在利用 Embedding 召回的过程中,相当于考虑到了多路召回的多种策略。
- Embedding 召回的评分具有连续性。多路召回中不同召回策略产生的相似度、热度等分值不具备可比性,所以我们无法据此来决定每个召回策略放回候选集的大小。
- 在线上服务的过程中,Embedding 相似性的计算也相对简单和直接。
- 步骤
- 获取用户的 Embedding。
- 我们获取所有物品的候选集,并且逐一获取物品的 Embedding,计算物品 Embedding 和用户 Embedding 的相似度。(主要时间开销在这一步,时间复杂度是线性的,当物品集规模大时,可能造成很大的时间开销。解决办法:局部敏感哈希(下一节))
- 我们根据相似度排序,返回规定大小的候选集。

若有收获,就点个赞吧
0 人点赞
