召回与用户向量最相似的物品 Embedding 向量这一问题就是在向量空间内搜索最近邻的过程。
局部哈希的基本原理
- 基本思想
希望让相邻的点落入同一个“桶”,这样在进行最近邻搜索时,我们仅需要在一个桶内,或相邻几个桶内的元素中进行搜索即可。如果保持每个桶中的元素个数在一个常数附近,我们就可以把最近邻搜索的时间复杂度降低到常数级别。
- 如何构建“桶”?
- 理论基础:欧式空间中,将高维空间的点映射到低维空间,原本接近的点在低维空间中肯定依然接近,但原本远离的点则有一定概率变成接近的点。
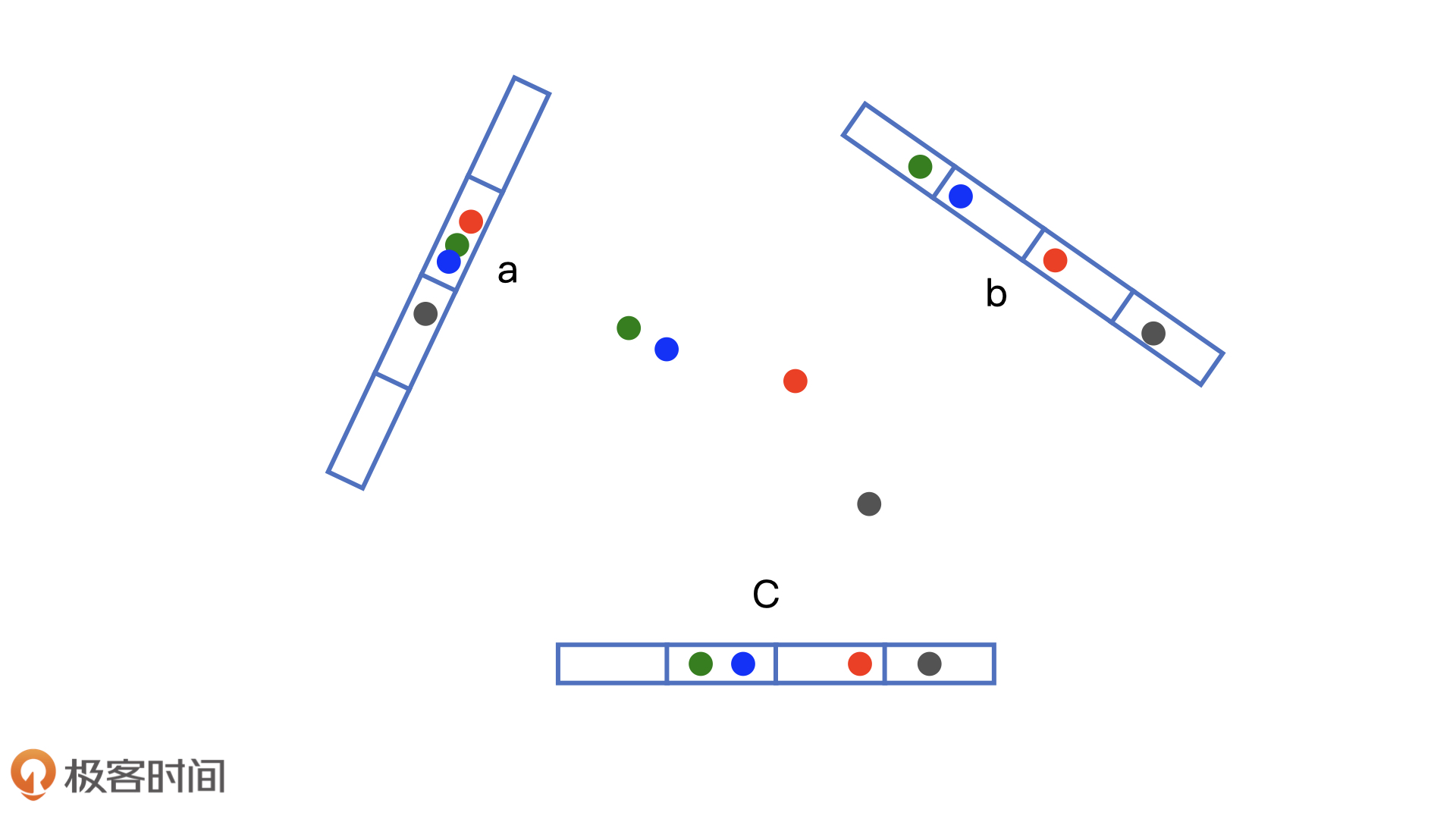
- 策略:利用哈希函数(基于内积)将高维的embedding映射到低维,如

- 问题:映射操作会损失部分距离信息,如果我们仅采用一个哈希函数进行分桶,必然存在相近点误判的情况。因此需要用多桶策略。
局部哈希的多桶策略
- 含义:使用多个分桶函数的方式来增加找到相似点的概率。
- 问题:如果有多个分桶函数的话,具体应该如何处理不同桶之间的关系呢?到底应该选择“且”操作还是“或”操作,以及到底该选择使用几个分桶函数,每个分桶函数分几个桶呢?这些都还是工程上的权衡问题。
- 一些取值的建议:


若有收获,就点个赞吧
0 人点赞
