首先,老规矩:
未经允许禁止转载(防止某些人乱转,转着转着就到蛮牛之类的地方去了)
B站:Heskey0
李航《统计学习方法》
BiliBili:Heskey0
#机器学习 第4 5 6 7 13 14 17 18 20-34 36 37 47-52讲
//TODO: 决策树预剪枝/后剪枝
Machine Learning: 十大机器学习算法 - 简书 (jianshu.com)
机器学习十大算法:
- 线性回归算法 Linear Regression
- 支持向量机算法 (Support Vector Machine,SVM)
- 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
- 逻辑回归算法 Logistic Regression
- 决策树算法 Decision Tree
- k-平均算法 K-Means
- 随机森林算法 Random Forest
- 朴素贝叶斯算法 Naive Bayes
- 降维算法 Dimensional Reduction
- 梯度增强算法 Gradient Boosting
深度学习是机器学习中的一类模型
它和任意一个深度学习的模型是平级别的关系
例如:GAN是用网络去做生成模型,判别模型。Generative Adversarial Networks
Chapter 1. 介绍
1.1 分类
基本分类:
- 监督学习
- 无监督学习
- 强化学习
按技巧分类:
贝叶斯学习
核方法
算法角度:
- 在线学习
- 批量学习
1.2 基本分类
(1) 监督学习
监督学习的基本假设:X和Y具有联合概率分布 #card=math&code=P%28X%2CY%29)
监督学习的目的:学习一个输入到输出的映射,这一映射以模型表示
模型的形式:条件概率分布 #card=math&code=P%28Y%7CX%29) 或决策函数
#card=math&code=Y%3Df%28X%29) (概率用于分类,决策描述连续)
对于分类问题,函数的目的就是学习到,你拿到的样本的概率分布。所以:你建的一切模型都是为了拟合你用于训练的这批训练集的概率分布情况
输入空间:
- 输入空间(Input Space):输入的所有可能取值的集合;
- 实例(Instance):每一个具体的输入,通常由特征向量(Feature Vector)表示;
- 特征空间(Feature Space):所有特征向量存在的空间
大多时候,输入空间和特征空间是相同的。
输出空间:
- 输出空间(Output Space):输出的所有可能取值的集合
根据变量的不同类型,要解决的问题可以分为回归问题、分类问题和标注问题。
- 输入变量与输出变量均为连续变量的预测问题——回归问题
- 输出变量为有限个离散变量的预测问题——分类问题
- 输入变量与输出变量均为变量序列的预测问题—— 标注问题
example: 预测连续就是回归。预测属于猫狗就是分类。给一个句子标注主语谓语宾语就是序列标注
设输入变量X,输出变量Y
监督学习的基本假设:X和Y具有
(2) 无监督学习
无监督:无标注
无监督学习的目的:研究数据中的潜在结构内容,所以无监督学习对应的不是输出空间,而是隐式结构空间
输入空间:
隐式结构空间:
模型:函数
#card=math&code=z%3Dg%28x%29) ,条件概率分布
#card=math&code=P%28z%7Cx%29) 或条件概率分布
#card=math&code=P%28x%7Cz%29)
训练集:
(3) 强化学习
强化学习其实要强调一个互动,互动是指的是智能系统与环境之间的一个连续互动,通过这个互动,学习一个最优的行为策略。
1.3 模型选择方法
过拟合:如果参数过多,甚至超出训练数据集中样本点的个数,这时候模型结构会十分复杂,虽然对已知数据有一个很好的预测效果,但对未知数据预测效果很差。
欠拟合:训练误差高,测试误差低
监督学习中两种常用的模型选择方法:
- 正则化
- 交叉验证
监督学习的两种基本策略:经验风险最小化(ERM)和结构风险最小化(SRM)
风险最小化就是认为,经验/结构风险最小的模型是最优的模型
经验风险最小化的例子:极大似然估计(maximum likelihood estimation)
结构风险最小化的例子:贝叶斯最大后验概率估计
(1) 正则化
损失函数度量模型一次预测的好坏,风险函数度量平均意义下模型预测的好坏。
损失函数:
)%0A#card=math&code=L%28y_i%2Cf%28x_i%29%29%0A)
风险函数有两种:
经验风险
结构风险:考虑过拟合问题,增加正则项
经验风险 (Empirical Risk):
)%0A#card=math&code=%5Cfrac1N%5Csum_%7Bi%3D1%7D%5ENL%28y_i%2Cf%28x_i%29%29%0A)
结构风险 (Structural Risk)=经验风险+正则化项:
)%2B%5Clambda%20J(f)%0A#card=math&code=%5Cfrac1N%5Csum_%7Bi%3D1%7D%5ENL%28y_i%2Cf%28x_i%29%29%2B%5Clambda%20J%28f%29%0A)
其中
#card=math&code=J%28f%29) 度量模型的复杂度,系数
用以调整经验风险和模型复杂度之间的关系
一般,模型参数越多,模型越复杂,
常用正则化项:
范数:
,即参数绝对值之和
范数:
,即参数的平方和
(2) 交叉验证
在样本的数据量足够充足的情况下,通常可以将数据集随机地分为:
- 训练集(Training Set):用以训练模型
- 验证集(Validation Set):用以选择模型
- 测试集(Test Set):用以最终对学习方法的评估
交叉验证的基本思想就是,重复使用数据,以解决数据不足的这种问题。
(2.1) 简单交叉验证
将数据集随机的分为:
- 训练集
- 测试集
通过训练集得到不同的学习模型,将学习训练得到的不同模型放到测试集上,计算测试误差,测试误差最小的模型则是最优模型
(2.2) S折交叉验证
随机将数据分为 S 个互不相交、大小相同的子集,其中以 S-1 个子集作为训练集,余下的子集作为测试集
(2.3) 留一交叉验证
每次用N-1个样本训练模型,余下的那个样本测试模型。这是在数据非常缺乏的情况下才使用的方法。
1.3 泛化能力
泛化能力:指的是通过某一学习方法训练所得模型,对未知数据的预测能力
测试误差:计算测试误差所使用的样本为测试集
)%0A#card=math&code=%5Cfrac1%7BN%5E%5Cprime%7D%5Csum%7Bi%5E%5Cprime%3D1%7D%5E%7BN%5E%5Cprime%7DL%28y%7Bi%5E%5Cprime%7D%2C%5Chat%20f%28x_%7Bi%5E%5Cprime%7D%29%29%0A)
(1) 泛化误差
泛化误差:是基于整个样本空间的
%26%3DEp%5BL(Y%2C%5Chat%20f(X))%5D%5C%5C%0A%26%3D%5Cint%7BX%5Ctimes%20Y%7DL(y%2C%5Chat%20f(x))P(x%2Cy)dxdy%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0AR%7Bexp%7D%28%5Chat%20f%29%26%3DE_p%5BL%28Y%2C%5Chat%20f%28X%29%29%5D%5C%5C%0A%26%3D%5Cint%7BX%5Ctimes%20Y%7DL%28y%2C%5Chat%20f%28x%29%29P%28x%2Cy%29dxdy%0A%5Cend%7Baligned%7D%0A)
泛化误差是度量对未知数据预测能力的理论值,测试误差则是经验值
在训练集上的误差成为“训练误差”(训练)。在新样本上的误差称为“泛化误差”(实战)
(2) 泛化误差上界
泛化误差上界:泛化误差的概率上界。
在理论上比较两种学习方法所得模型的优劣时,可通过比较两者的泛化误差上界来进行
泛化误差上界的两条性质:
- 样本容量的函数:当样本容量增加时,泛化误差上界趋于 0。
- 假设空间容量的函数:假设空间容量越大,模型就越难学,泛化误差上界就越大。
1.4 生成模型与判别模型
(1) 生成模型
生成模型:由数据学习联合分布概率 #card=math&code=P%28X%2CY%29),然后求出
#card=math&code=P%28Y%7CX%29) 作为预测模型,即生成模型(Generative Model):
%3D%5Cfrac%7BP(X%2CY)%7D%7BP(X)%7D%0A#card=math&code=P%28Y%7CX%29%3D%5Cfrac%7BP%28X%2CY%29%7D%7BP%28X%29%7D%0A)
每给定一个输入变量X,就可以根据分布函数生成一个输出变量Y
生成模型中的输入变量和输出变量,都为随机变量
典型的生成模型有朴素贝叶斯法,还有隐马可夫模型
(2) 判别模型
判别模型:由数据直接学习决策函数 #card=math&code=f%28X%29) 或者条件概率分布
#card=math&code=P%28Y%7CX%29) 作为预测模型,即判别模型(Discriminative Model)
不需要考虑X和Y的联合分布
判别方法是有针对性的,研究的是对于特定的输入,应该预测得到一个什么样的输出
典型的判别模型有 k 近邻法、感知机,还有决策树
(3) 差异
从样本量上来比较:
- 生成模型所需要的数据量较大,因为只有在大数据量的情况下,才能够更好地估计联合概率分布,也就是所有变量的一个全概率模型;
- 判别模型,是针对性地学习,只需要得到条件概率分布或者决策函数即可,所以不需要像生成模型的那样,必须配备足够多的样本,因此判别模型所需的样本量要少于生成模型。
从目的来比较:
- 生成模型可以还原联合概率分布,借此可以计算出边际分布和条件概率分布,所以可以提供更多的信息;
- 判别模型的目的就是预测,所以准确率往往比生成模型会更高一些。
从过程来比较:
- 对生成模型而言,样本容量越多,学习到的模型就能够更快地收敛到真实模型上,所以生成模型的收敛速度,较之判别模型更快;
- 判别模型,是直接学习的过程,所以不需要面面俱到,因此可以简化学习问题。
从反映数据特征来比较:
- 生成模型学习到的模型更接近于真实模型,所以能够反映同类数据本身的相似度;
- 判别模型,并不考虑数据的各项特征,所以并不能像生成模型那样反映数据本身的特性。
最后一条是关于隐变量的,生成模型,可以很好地应对具有隐变量的情况,比如混合高斯模型
Chapter 2. 模型
2.1 KNN
KNN (K-Nearest-Neighbour)可以说是机器学习中最简单的是一种「分类回归方法」
KNN是一种Lazy Learning,也就是一种不具有显性表达式的方法
(1) 算法介绍
(1.1) 主要思想
主要思想:给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以根据其最近 个训练实例的标签,预测新实例对应的标注信息。
当给定一个新的实例
时,我们就可以在训练数据集
里面寻找与
个实例,然后根据这
值。
(1.2) 具体算法
输入:训练集 %2C(x_2%2Cy_2)%2C…%2C(x_N%2Cy_N)%5C%7D#card=math&code=T%3D%5C%7B%28x_1%2Cy_1%29%2C%28x_2%2Cy_2%29%2C…%2C%28x_N%2Cy_N%29%5C%7D) 其中
输出:实例 所属类别
步骤:
给出距离度量的方式,计算新的
找出与
#card=math&code=N_k%28x%29)
根据分类决策规则来决定
%7DI(yi%3Dc_j)%2Ci%3D1%2C2%2C…%2CN%3Bj%3D1%2C2%2C…%2CK%0A#card=math&code=y%3D%5Cmax%7Bcj%7D%5Csum%7Bx_i%5Cin%20N_k%28x%29%7DI%28y_i%3Dc_j%29%2Ci%3D1%2C2%2C…%2CN%3Bj%3D1%2C2%2C…%2CK%0A)
其中,
#card=math&code=I%28y_i%3Dc_j%29) 是一个示性函数,
时,函数值为1
0-1损失函数:
)%3D%0A%5Cleft%5C%7B%0A%5Cbegin%7Baligned%7D%0A%261%2C%26Y%5Cne%20f(X)%5C%5C%0A%260%2C%26Y%3Df(X)%0A%5Cend%7Baligned%7D%0A%5Cright.%0A#card=math&code=L%28Y%2Cf%28X%29%29%3D%0A%5Cleft%5C%7B%0A%5Cbegin%7Baligned%7D%0A%261%2C%26Y%5Cne%20f%28X%29%5C%5C%0A%260%2C%26Y%3Df%28X%29%0A%5Cend%7Baligned%7D%0A%5Cright.%0A)
(2) 三要素
- 距离度量
- k个邻居
- 分类决策规则
(2.1) 距离度量
距离:
%3D(%5Csum%7Bl%3D1%7D%5En%7Cx_i%5E%7B(l)%7D-x_j%5E%7B(l)%7D%7C%5Ep)%5E%7B%5Cfrac1p%7D%0A#card=math&code=L_p%28x_i%2Cx_j%29%3D%28%5Csum%7Bl%3D1%7D%5En%7Cx_i%5E%7B%28l%29%7D-x_j%5E%7B%28l%29%7D%7C%5Ep%29%5E%7B%5Cfrac1p%7D%0A)
其中,
%7D#card=math&code=x%5E%7B%28l%29%7D) 代表第
个特征
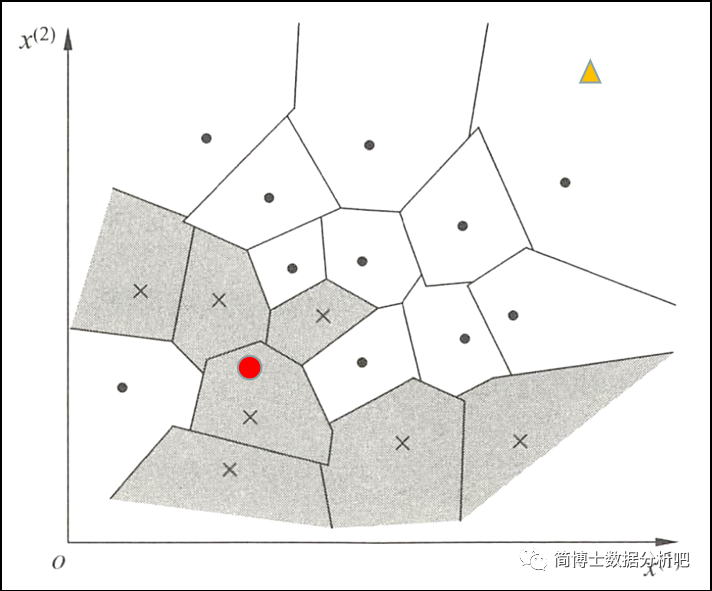
如图:
- 横坐标是第一个特征 (身高),纵坐标是第二个特征 (体重)
- ×代表男,· 代表女
- 根据红点与周围点的距离判定类别
example:
假设我想让你帮我区分一个人是好人还是坏人。我就给你2个纬度的信息: 1.你的手机过去一个月内平均每天的通话时长,2.你过去一个月每个月的收入金额。 你帮我用knn建模。训练集10000个样本,里面有5000好人,5000坏人。现在每个训练集在这2个维度上就有个分布情况。比如横轴是 通话 纵轴是 收入。然后新来一个样本点,第10001个,这个样本点就可以用之前的10000个做knn了,找第10001样本周围欧式距离最近的k个样本计算
knn不用训练什么参数,k就是唯一要考虑的
(2.2) k值的选择
| 特点 | 值较小 | 值较大 |
|---|---|---|
| 近似误差 | 小 | 大 |
| 估计误差 | 大 | 小 |
| 敏感性 | 强 | 弱 |
| 模型 | 复杂 | 简单 |
| 拟合程度 | 过拟合 | 欠拟合 |
可通过交叉验证选择
(2.3) 分类决策规则
多数表决规则:由输入实例的 个邻近的训练实例中的多数类决定输入实例的类别
(3) kd树
从根本上来看,是一个二叉树结构,每个结点代表 维超矩形区域
(3.1) 构建
输入: 维空间数据集:
其中
%7D%2Cx_i%5E%7B(2)%7D%2C…x_i%5E%7B(k)%7D)#card=math&code=x_i%3D%28x_i%5E%7B%281%29%7D%2Cx_i%5E%7B%282%29%7D%2C…x_i%5E%7B%28k%29%7D%29),
%7D#card=math&code=x_i%5E%7B%28l%29%7D) 的上标代表第
输出:kd 树
构建过程:见 讲义(十四):kd 树的构造和搜索
(3.2) 搜索
输入:kd树,目标点是
输出: 的最近邻
搜索过程:
寻找“当前最近点”:从根结点出发,递归访问 kd 树,找出包含
回溯:以目标点和”当前最近点”的距离沿树根部进行回溯和迭代,当前最近点一定存在于该结点一个子结点对应的区域,检查子结点的父结点的另一子结点对应的区域是否有更近的点。当回退到根结点时,搜索结束,最后的“当前最近点”即为 的最近邻点。
2.2 感知机
感知机是一个二分类的线性分类模型,之所以说是线性,是因为它的模型是线性形式的
(1) 模型
输入:%7D%2Cx%5E%7B(2)%7D%2C…%2Cx%5E%7B(n)%7D)%5ET#card=math&code=x%3D%28x%5E%7B%281%29%7D%2Cx%5E%7B%282%29%7D%2C…%2Cx%5E%7B%28n%29%7D%29%5ET) ,即
维特征向量
输出:
感知机:
%3Dsign(w%5Ccdot%20x%2Bb)%3D%0A%5Cleft%5C%7B%0A%5Cbegin%7Baligned%7D%0A%26%2B1%2C%26w%5Ccdot%20x%2Bb%5Cge0%5C%5C%0A%26-1%2C%26w%5Ccdot%20x%2Bb%3C0%0A%5Cend%7Baligned%7D%0A%5Cright.%0A#card=math&code=f%28x%29%3Dsign%28w%5Ccdot%20x%2Bb%29%3D%0A%5Cleft%5C%7B%0A%5Cbegin%7Baligned%7D%0A%26%2B1%2C%26w%5Ccdot%20x%2Bb%5Cge0%5C%5C%0A%26-1%2C%26w%5Ccdot%20x%2Bb%3C0%0A%5Cend%7Baligned%7D%0A%5Cright.%0A)
其中
%7D%2Cw%5E%7B(2)%7D%2C…%2Cw%5E%7B(n)%7D)%5ET#card=math&code=w%3D%28w%5E%7B%281%29%7D%2Cw%5E%7B%282%29%7D%2C…%2Cw%5E%7B%28n%29%7D%29%5ET) 称为权值,
为Bias,
为内积
在几何中,如果环境空间是 维的,那么它所对应的超平面其实就是一个
维的子空间。换句话说,超平面是比他所处的环境空间小一个维度的子空间
感知机:
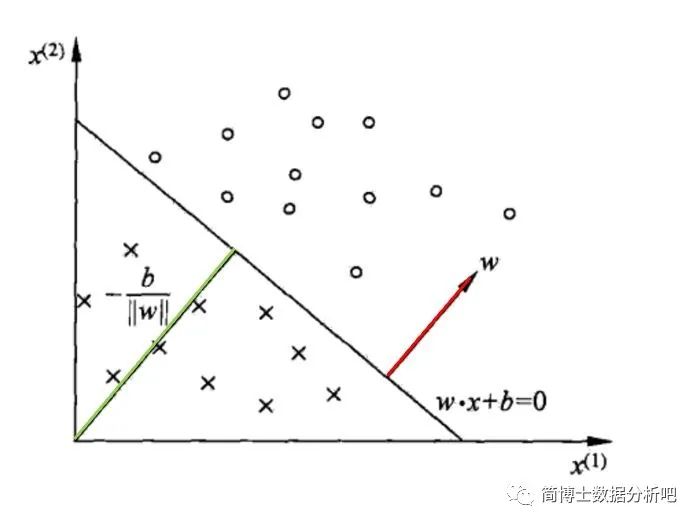
(2) 学习策略
感知机模型,有一个比较严苛的条件,就是要求数据集必须是线性可分的 (存在超平面划分)
特征空间中,任意一点到超平面的距离:
若 是正确分类点,则:
若 是错误分类点,则:
%7D%7B%7C%7Cw%7C%7C%7D%0A#card=math&code=%5Cfrac1%7B%7C%7Cw%7C%7C%7D%7Cw%5Ccdot%20x_0%2Bb%7C%3D%0A%5Cleft%5C%7B%0A%5Cbegin%7Baligned%7D%0A%26-%5Cfrac%7Bw%5Ccdot%20x_0%2Bb%7D%7B%7C%7Cw%7C%7C%7D%2C%26y_0%3D%2B1%5C%5C%0A%26%5Cfrac%7Bw%5Ccdot%20x_0%2Bb%7D%7B%7C%7Cw%7C%7C%7D%2C%26y_0%3D-1%0A%5Cend%7Baligned%7D%0A%5Cright.%0A%3D%5Cfrac%7B-y_0%28w%5Ccdot%20x_0%2Bb%29%7D%7B%7C%7Cw%7C%7C%7D%0A)
如果是错误分类点,通过分类器所得到的类别
#card=math&code=f_0%28x_0%29) 与 真实的类别
, 应该符号相反。
如果用 代表所有误分类点的集合,则所有误分类点到超平面
的距离总和为:
%0A#card=math&code=-%5Cfrac1%7B%7C%7Cw%7C%7C%7D%5Csum_%7Bx_i%5Cin%20M%7Dy_i%28w%5Ccdot%20x_i%2Bb%29%0A)
所以最小化距离等价于最小化损失函数:
%3D-%5Csum%7Bx_i%5Cin%20M%7Dy_i(w%5Ccdot%20x_i%2Bb)%0A#card=math&code=L%28w%2Cb%29%3D-%5Csum%7Bx_i%5Cin%20M%7Dy_i%28w%5Ccdot%20x_i%2Bb%29%0A)
不会影响距离和的符号,即不影响正值还是负值的判断。
为空集,那么误分类点的距离和是否为 0 取决于分子,而不是分母,因此与
(3) 多层感知机
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络且每个隐藏层的输出通过激活函数进行变换。(最简单的MLP只有一个隐含层)
MLP是一种多层前馈神经网络 ,常用的快速训练算法有共轭梯度法、拟牛顿法
2.3 决策树
决策树是一棵多叉树
(1) 概念
决策树的根本其实还是一个条件概率模型,条件概率分布就相当于对特征空间的划分
如图
- 对于特征
%7D#card=math&code=x%5E%7B%281%29%7D) 和
%7D#card=math&code=x%5E%7B%282%29%7D) 而言,他们的取值空间为
区间
- 每个区域标
和
就是对应的类别
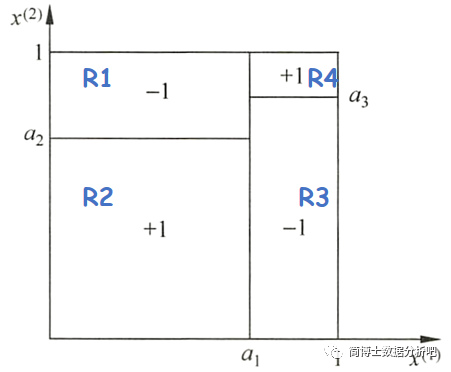
例如:
特征:%7D%3D#card=math&code=x_i%5E%7B%281%29%7D%3D)年收入,
%7D%3D#card=math&code=x_i%5E%7B%282%29%7D%3D)房产,
%7D%3D#card=math&code=x_i%5E%7B%283%29%7D%3D)婚姻状况
类别:可以偿还,
无法偿还
构建决策树:
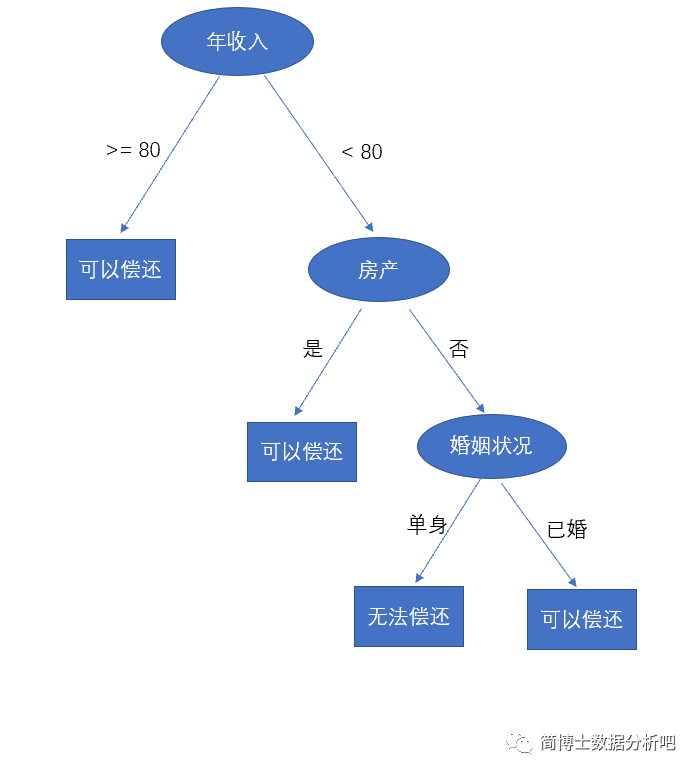
非叶子结点代表特征,叶子结点代表类别
(2) 构建
构建根节点:训练数据集,包含
个样本
选择最优特征:选择最优特征来分割训练数据集
判断是否产生了叶节点:若子集被正确分类,构建叶子结点,否则,重新选择新的最优特征
重复2, 3
(2.1) 如何选择最优特征
ID3算法:用信息增益选择最优特征,侧重于选择数量较多的某一特征
- 计算经验熵
- 计算经验条件熵
- 计算信息增益
- 信息增益比最大值确认最优特征
C4.5算法:用信息增比选择最优特征,侧重于某一特征单位数量的选择
(2.2) 信息增益
经验熵:
%3D-%5Csum%5EK%7Bk%3D1%7D%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7D%5Clog_2%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7D%0A#card=math&code=H%28D%29%3D-%5Csum%5EK%7Bk%3D1%7D%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7D%5Clog_2%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7D%0A)
其中:
- 训练数据集
,其样本容量
(样本个数)
- 设有
个类别
,
,
为属于类
在特征 下每个子集所占的权重为
经验条件熵:
%3D%5Csum%5En%7Bi%3D1%7D%5Cfrac%7B%7CD_i%7C%7D%7B%7CD%7C%7DH(D_i)%0A#card=math&code=H%28D%7CA%29%3D%5Csum%5En%7Bi%3D1%7D%5Cfrac%7B%7CD_i%7C%7D%7B%7CD%7C%7DH%28D_i%29%0A)
信息增益:
%3DH(D)-H(D%7CA)%0A#card=math&code=g%28D%2CA%29%3DH%28D%29-H%28D%7CA%29%0A)
物理意义:
得知特征
而使类
的 信息的不确定性 减少的程度
(3) 预剪枝
好的模型,树的深度小,叶子结点少。
剪枝的目的:解决过拟合的问题
分类:
- 预剪枝:生成过程中,对每个结点划分前进行估计,若当前结点的划分不能提升泛化能力,则停止划分,记当前结点为叶结点
- 后剪枝:生成一棵完整的决策树后,从底部向上对内部结点进行考察,如果将内部结点变成叶结点,可以提升泛化能力,那么就进行交换。
(4) 后剪枝
REP,PEP,MEP,EBP,CCP
2.4 朴素贝叶斯
朴素贝叶斯算法(Naive Bayes)基于概率论的贝叶斯定理,应用非常广泛,从文本分类、垃圾邮件过滤器、医疗诊断等等。朴素贝叶斯适用于特征之间的相互独立的场景,例如利用花瓣的长度和宽度来预测花的类型。“朴素”的内涵可以理解为特征和特征之间独立性强。
Chapter 3. CART,SVM
3.1 CART
3.2 逻辑回归
Logistic函数:
%3D%5Cfrac%7Bexp(%5Calpha%2B%5Cbeta%20t)%7D%7B1%2Bexp(%5Calpha%2B%5Cbeta%20t)%7D%0A#card=math&code=p%28t%29%3D%5Cfrac%7Bexp%28%5Calpha%2B%5Cbeta%20t%29%7D%7B1%2Bexp%28%5Calpha%2B%5Cbeta%20t%29%7D%0A)
其中,令
,那么就形成一个 Sigmoid function:
%26%3D%5Cfrac%7Be%5Ex%7D%7B1%2Be%5Ex%7D%5C%5C%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0AF%28x%29%26%3D%5Cfrac%7Be%5Ex%7D%7B1%2Be%5Ex%7D%5C%5C%0A%5Cend%7Baligned%7D%0A)
可以理解为 多个逻辑回归一个个嵌套起来 成为早期的神经网络
3.3 SVM
SVM (Support-Vector Machine) 支持向量机,是一种用于分类回归的方法。发表于1995年。
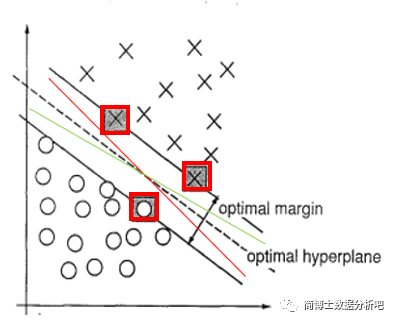
红框点,对于某个超平面,“最小间隔的点(几何间隔
)” 最大的时候,类别分的最开
那些被最终选中的点,因为在代数空间中,我们也可以用向量表示,所以称为支持向量机,有了它们的支持就可以找到唯一分离的超平面
(1) 算法
SVM的分类决策可以写成:
%3Dsign(w%5Ccdot%20x%2Bb)%0A#card=math&code=f%28x%29%3Dsign%28w%5Ccdot%20x%2Bb%29%0A)
与感知机类似
几何间隔 正是实例点
到超平面
的距离:
同时,为了去掉绝对值符号,引入分类标签 ,即
对应的类别:
%7D%7B%7C%7C%5Comega%7C%7C%7D%3Dy_i(%5Cfrac%7B%5Comega%5Ccdot%20x_i%7D%7B%7C%7C%5Comega%7C%7C%7D%2B%5Cfrac%7Bb%7D%7B%7C%7C%5Comega%7C%7C%7D)%0A#card=math&code=%5Cgamma_i%3D%5Cfrac%7By_i%28%5Comega%5Ccdot%20x_i%2Bb%29%7D%7B%7C%7C%5Comega%7C%7C%7D%3Dy_i%28%5Cfrac%7B%5Comega%5Ccdot%20x_i%7D%7B%7C%7C%5Comega%7C%7C%7D%2B%5Cfrac%7Bb%7D%7B%7C%7C%5Comega%7C%7C%7D%29%0A)
其中
代表欧式距离,
是
维向量
间隔的最小值记作:
那么优化问题可以写成:
%5Cge%5Cgamma%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%26%5Cmax_%7B%5Comega%2Cb%7D%5Cgamma%5C%5C%0A%26s.t.%26y_i%28%5Cfrac%7B%5Comega%5Ccdot%20x_i%7D%7B%7C%7C%5Comega%7C%7C%7D%2B%5Cfrac%7Bb%7D%7B%7C%7C%5Comega%7C%7C%7D%29%5Cge%5Cgamma%0A%5Cend%7Baligned%7D%0A)
为了解决模型的不可识别性,即 %7D%2B4x%5E%7B(2)%7D%2B1%3D0#card=math&code=3x%5E%7B%281%29%7D%2B4x%5E%7B%282%29%7D%2B1%3D0) 与
%7D%2B8x%5E%7B(2)%7D%2B2%3D0#card=math&code=6x%5E%7B%281%29%7D%2B8x%5E%7B%282%29%7D%2B2%3D0) 表示同一个超平面,引入归一化思想:令
,再给
加个约束
(SVM中约定俗成的是定为1),也就是距离超平面最近的点距离都是 1
优化问题变为:
%5Cge1%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%26%5Cmin_%7B%5Comega%2Cb%7D%7C%7C%5Comega%7C%7C%5C%5C%0A%26s.t.%26y_i%28%5Comega%5Ccdot%20x_i%2Bb%29%5Cge1%0A%5Cend%7Baligned%7D%0A)
也就是将约束条件
隐藏在优化问题中,而不是单独列出来
线性可分SVM的最优解是唯一解
(2) 最大间隔算法
输入:训练数据集
%2C…%2C(x_N%2Cy_N)%0A#card=math&code=T%3D%28x_1%2Cy_1%29%2C…%2C%28x_N%2Cy_N%29%0A)
输出:最大间隔分离超平面与决策函数
【十分钟 机器学习 系列课程】 讲义(43):SVM支持向量机-线性可分支持向量机的对偶问题
Appendix
1. 激活函数对比
sigmoid缺点:
- 激活函数的计算量较大,在反向传播中,当求误差梯度时,求导涉及除法;
- 在反向传播中,容易就会出现梯度消失,无法完成深层网络的训练;
- 函数的敏感区间较短,(-1,1)之间较为敏感,超过区间,则处于饱和状态,
relu对比于sigmoid:
- sigmoid的导数,只有在0附近,具有较好的激活性,而在正负饱和区的梯度都接近于0,会造成梯度弥散;而relu的导数,在大于0时,梯度为常数,不会导致梯度弥散。
- relu函数在负半区的导数为0 ,当神经元激活值进入负半区,梯度就会为0,也就是说,这个神经元不会被训练,即稀疏性;
- relu函数的导数计算更快,程序实现就是一个if-else语句;而sigmoid函数要进行浮点四则运算,涉及到除法;
relu的缺点:
在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度,流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。
2. Metroplis-Hastings Algorithm
Metropolis-Hastings algorithm - RyanXing - 博客园
2.1 思想
Core:构造转移矩阵 ,使平稳分布恰好是我们要的分布
#card=math&code=p%28x%29)
定理:若
P%7Bij%7D%3D%5Cpi(j)P%7Bji%7D%0A#card=math&code=%5Cpi%28i%29P%7Bij%7D%3D%5Cpi%28j%29P%7Bji%7D%0A)
where:
:状态转移矩阵
#card=math&code=%5Cpi%28x%29):分布
则分布 #card=math&code=%5Cpi%28x%29) 为该马尔可夫链的平稳分布
物理意义:
对于任意两个状态
,从状态
流失到状态
的概率质量,等于反向流动的概率质量,因此是状态概率是稳定的。
2.2 算法思想
刚开始不是平稳分布
Q%7Bij%7D%5Cne%20P(j)Q%7Bji%7D%0A#card=math&code=P%28i%29Q%7Bij%7D%5Cne%20P%28j%29Q%7Bji%7D%0A)
引入接受率:概率#card=math&code=%5Calpha%28xt%2Cx%7Bnext%7D%29) 满足
%5Cleft%5BQ%7Bij%7D%5Calpha(i%2Cj)%5Cright%5D%3D%20P(j)%5BQ%7Bji%7D%5Calpha(j%2Ci)%5D%0A#card=math&code=P%28i%29%5Cleft%5BQ%7Bij%7D%5Calpha%28i%2Cj%29%5Cright%5D%3D%20P%28j%29%5BQ%7Bji%7D%5Calpha%28j%2Ci%29%5D%0A)
其中:
#card=math&code=P%28i%29) 是状态
是初始转移概率矩阵,满足任意一个给定的简单分布,便于抽样即可。
最简单的接受率构造方法是:
%3DP(j)Q%7Bji%7D%5C%5C%0A%5Calpha(j%2Ci)%3DP(i)Q%7Bij%7D%0A#card=math&code=%5Calpha%28i%2Cj%29%3DP%28j%29Q%7Bji%7D%5C%5C%0A%5Calpha%28j%2Ci%29%3DP%28i%29Q%7Bij%7D%0A)
此时满足平稳分布的条件
如果 #card=math&code=%5Calpha%28xt%2Cx%7Bnext%7D%29) 太小,会导致转移很难发生,马尔可夫链收敛很慢。所以要在保持平稳条件成立的前提下,是接受率尽量增大。
由于接受率的本质是概率,因此 #card=math&code=%CE%B1%28i%2Cj%29) 和
#card=math&code=%CE%B1%28j%2Ci%29) 中的较大者不应大于1。
故做以下改进:
Q%7Bji%7D%7D%7BP(i)Q%7Bij%7D%7D%5C%5C%0Aa(i%2Cj)%3D%5Cmin(buf%2C1)%0A#card=math&code=buf%3D%5Cfrac%7BP%28j%29Q%7Bji%7D%7D%7BP%28i%29Q%7Bij%7D%7D%5C%5C%0Aa%28i%2Cj%29%3D%5Cmin%28buf%2C1%29%0A)
2.3 算法Coding
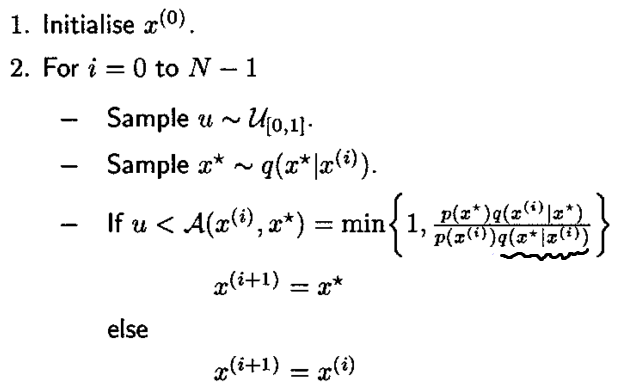
function SamplefromExponentialclc;close all;clear;% 随意设data_size=100000; % 越大越准start=1; % 非负即可% 初始化data=start;index=1;% 直接生成多个服从均值为10的指数分布的样本data_dir=exprnd(10,[1,data_size]);figure;subplot(1,2,1)histogram(data_dir,'BinWidth',1);axis([0,100,0,data_size/10]);% 随机模拟while(index<data_size)u=rand; % 均匀抽样data_next=normrnd(data(index),1); % 简单分布为标准正态分布buf=exppdf(data_next,10)/exppdf(data(index),10);alpha=min(1,buf);if u<alphadata=[data data_next];elsedata=[data data(index)];endindex = index+1;endsubplot(1,2,2)histogram(data,'BinWidth',1);axis([0,100,0,data_size/10]);
3. Auto-encoder
【机器学习基础】无监督学习(3)——AutoEncoder - Uniqe - 博客园 (cnblogs.com)
4. PCA
【机器学习基础】无监督学习(1)——PCA - Uniqe - 博客园 (cnblogs.com)
5. 聚类
【Python机器学习实战】聚类算法(1)——K-Means聚类 - Uniqe - 博客园 (cnblogs.com)
【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN - Uniqe - 博客园 (cnblogs.com)
主要的聚类算法可以划分为如下几类:
- 划分方法:如k-means聚类算法
- 层次方法:如凝聚型层次聚类算法
- 基于密度的方法
- 基于网格的方法
- 基于模型的方法:神经网络聚类算法
6. 损失函数

若有收获,就点个赞吧
0 人点赞
