数据结构
二叉树,B-Tree,B+Tree,hash表
B 树和 B+树有什么不同呢?
第一,B 树一个节点里存的是数据,而 B+树存储的是索引(地址),所以 B 树里一个节点存不了很多个数据,但是 B+树一个节点能存很多索引,B+树叶子节点存所有的数据。
第二,B+树的叶子节点是数据阶段用了一个链表串联起来,便于范围查找。
B+树节点存储的是索引,在单个节点存储容量有限的情况下,单节点也能存储大量索引,使得整个 B+树高度降低,减少了磁盘 IO。其次,B+树的叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,在数据范围查找时,更具备效率。因此 Mysql 的索引用的就是 B+树,B+树在查找效率、范围查找中都有着非常不错的性能。
show global status like “INNODB_page_size” 查看BTree 页节点的分配空间
hash表存储结构:
myisam引擎
MyISAM 虽然数据查找性能极佳,但是不支持事务处理
- frm:创建表的语句
- MYD:表里面的数据文件(myisam data)
- MYI:表里面的索引文件(myisam index)
myisam使用引擎查询的执行流程
如果使用索引查找,数据库会根据二分法查找MYI索引文件,最终查找到叶子结点的索引位置;叶子结点的索引中包含的有数据的磁盘文件地址如图:0xF3,然后根据磁盘文件地址直接在MYD数据文件中查找到对应的数据;
Innodb引擎
Innodb 最大的特色就是支持了 ACID 兼容的事务功能,而且他支持行级锁
- frm:创建表的语句
- idb:表里面的数据+索引文件
Innodb数据存储结构:其叶结点不知放的数据索引,也放的有对应的整个数据文件;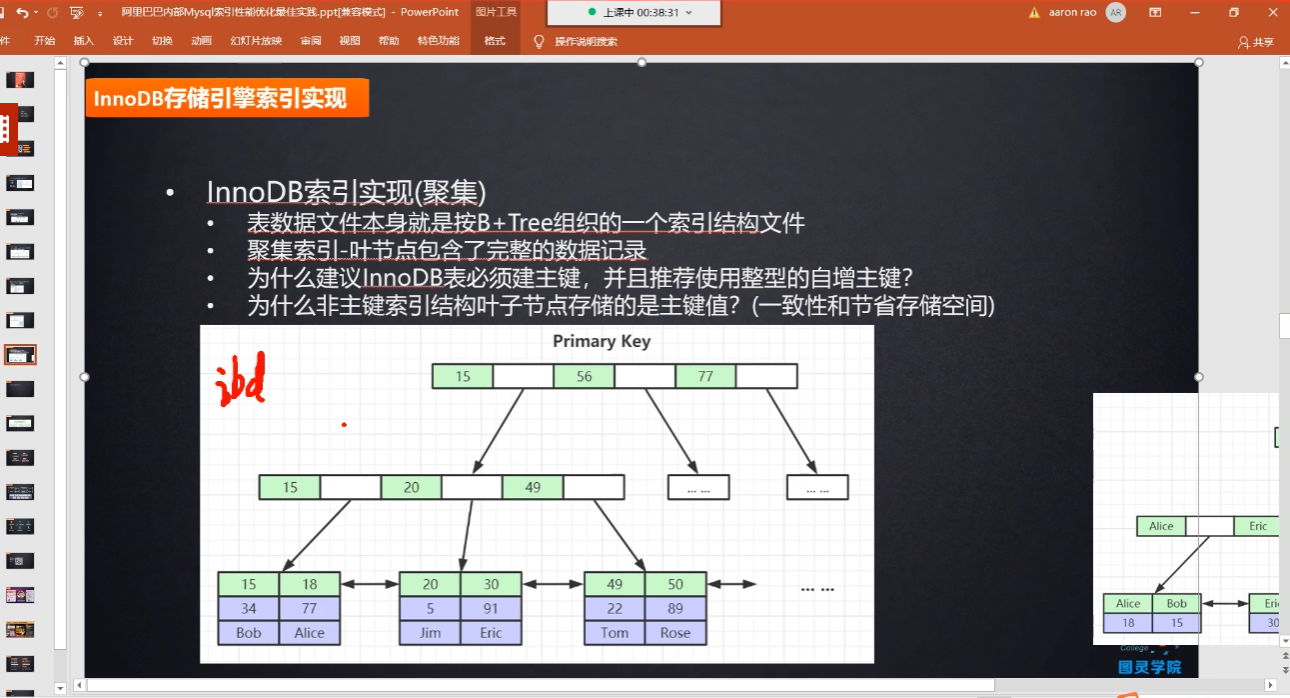
Innodb的二级索引机构图:
二级索引也是非聚集的;数据库会先根据二级索引查找到叶子结点,叶子结点中存储的是二级索引和对应行数剧的主键。在查找到二级索引以及对应主键后,会返回主键索引B+Tree中再重新查找对饮的主键位置以及对应的数据行元素,这个步骤叫回表
辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录;
索引
聚集索引:
索引中键值的逻辑顺序决定了表中相应行的物理顺序(索引中的数据物理存放地址和索引的顺序是一致的),可以这么理解:只要是索引是连续的,那么数据在存储介质上的存储位置也是连续的。
比方说:想要到字典上查找一个字,我们可以根据字典前面的拼音找到该字,注意拼音的排列时有顺序的。
打个比方:当我们想要找“啊”这个字,然后又想找“不”这个字,根据拼音来看“b”一定在”a“的后面。
聚集索引就像我们根据拼音的顺序查字典一样,可以大大的提高效率。在经常搜索一定范围的值时,通过索引找到第一条数据,根据物理地址连续存储的特点,然后检索相邻的数据,直到到达条件截至项
即索引文件也有索引对应的具体行的数据文件;类似于Innodb文件存储类型;
非聚集索引
索引的逻辑顺序与磁盘上的物理存储顺序不同。非聚集索引的键值在逻辑上也是连续的,但是表中的数据在存储介质上的物理顺序是不一致的,即记录的逻辑顺序和实际存储的物理顺序没有任何联系。索引的记录节点有一个数据指针指向真正的数据存储位置。
非聚集索引就像根据偏旁部首查字典一样,字典前面的目录在逻辑上也是连续的,但是查两个偏旁在目录上挨着的字时,字典中的字却很不可能是挨着的。
即索引位置和对应的具体行数据磁盘地址不一致;类似于Myisam文件结构
联合索引
联合索引:是有多跟表字段组合成的索引,
最左排序原则:从最左字段比较大小,如果第一个字段能比较大小就无须使用后面几个字段进行排序;
一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效
比如有一条语句是这样的:select * from users where area=’beijing’ and age=22;
如果我们是在area和age上分别创建单个索引的话,由于mysql查询每次只能使用一个索引,所以虽然这样已经相对不做索引时全表扫描提高了很多效率,但是如果在area、age两列上创建复合索引的话将带来更高的效率。如果我们创建了(area, age,salary)的复合索引,那么其实相当于创建了(area,age,salary)、(area,age)、(area)三个索引,这被称为最佳左前缀特性。
因此我们在创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。
- 索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
- 使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
- 排序的索引问题
mysql查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
- like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引,而like “aaa%”可以使用索引。
不要在列上进行运算
不使用NOT IN操作
NOT IN操作不会使用索引将进行全表扫描。NOT IN可以用NOT EXISTS代替
最左前缀优化
如果索引属于联合索引,需要遵循最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引的列。
limit优化
limit 100000,20的意思是扫描满足条件的100020行,扔掉前面的100000行,返回最后20行。所以偏移量越大,查询性能越差。

若有收获,就点个赞吧
0 人点赞
