1. MySQL的架构设计
MySQL的整体架构如下图所示:
- SQL接口:MySQL接收到sql语句后,就会交给SQL接口去处理
- SQL解析器:按照既定的sql语法,解析发送的sql语句
- 查询优化器:选择最优的查询路径
- 执行器:按照查询优化器给出的执行方案,调用存储引擎的接口
-
2. InnoDB存储引擎的架构设计
2.1 InnoDB引擎的架构
假设我们现在有一条 update 语句,这条sql语句在InnoDB引擎中的执行流程如下:
InnoDB引擎首先把要修改的数据从磁盘加载到缓冲池中,同时对这行数据加锁。缓冲池是InnoDB中的一个重要组件,用于在内存中缓存大量数据,以避免后续查询时直接查询磁盘
- 将更新前的值写入 Undo Log 中,以便于回滚数据。事务提交之前都是可以对数据进行回滚的
- 更新缓冲池中的数据,此时内存中的数据和磁盘上的数据不一致了,因此这行数据就是脏数据
- 把对内存做出的修改写入 Redo Log 中,Redo日志用于在MySQL宕机时恢复更新过的数据
- 提交事务的时候将 Redo Log 写入磁盘中。这个策略可以通过 innodb_flush_log_at_trx_commit 来配置:
- 值为0:不写入磁盘
- 值为1:提交事务时写入磁盘
- 值为2:提交事务时把Redo Log写入磁盘文件对应的OS Cache缓存中,可能1s后操作系统才会把OS Cache中里的数据写入磁盘中
如果在提交事务前MySQL宕机了,必然会导致缓冲池中修改的数据丢失,同时Redo Log中的redo日志也会丢失。此时虽然更新的数据都丢失了,但是因为事务没有提交,所以此时的数据是正确的。
如果提交事务后MySQL宕机了,虽然内存中的缓冲池的数据丢失了,但是因为Redo Log还在,所以MySQL重启后,可以根据Redo Log来恢复数据,所以数据也是正确的。
一般情况下Redo Log的刷盘策略都是使用的是 “1”。
MySQL后台有一个IO线程,会在之后的某个时间,随机地把内存Buffer Pool中的修改后的脏数据刷回到磁盘上。
2.2 redo log
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么redo log总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下图所示: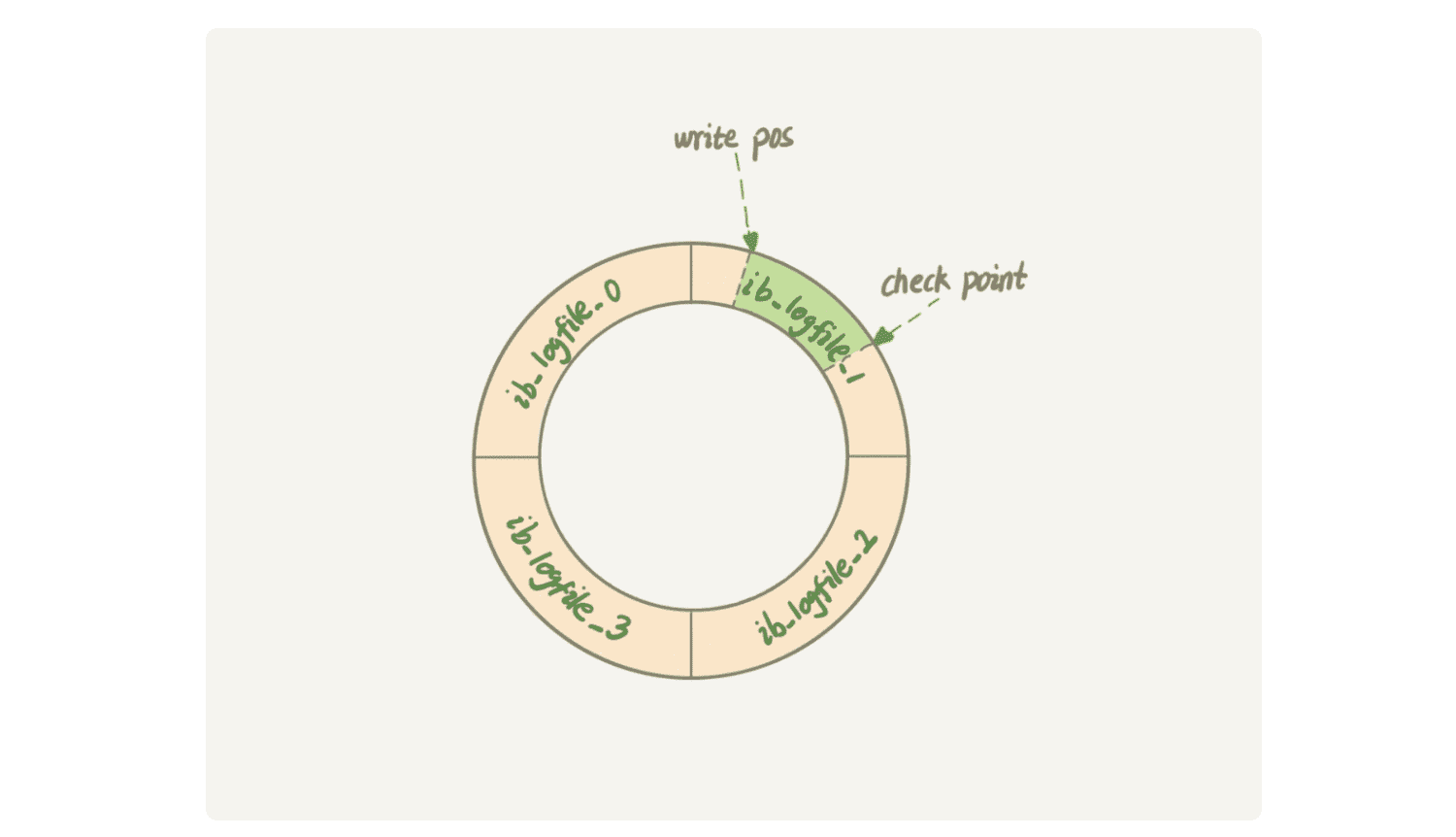
- write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头
- checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos 和 checkpoint 之间的是区间是redo log还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。

若有收获,就点个赞吧
0 人点赞
