re
规则表达式(Regular Expression, RE),又称作正则表达式,通常用于检索和替换符合指定规则的文本,正则表达式定义的规则,称作模式(Pattern)。正则表达式的作用是从文本中查找到符合模式的文本,在Python中使用正则表达式,需要导入re模块
基本语法
普通字符
可以通过自身出现过的字符进行匹配a = "abc123+-*" b = re.findall('abc',a)
OUT:[‘abc’]
元字符
元字符指的是. ^ $ ? + {} \ []之类的特殊字符,通过它们我们可以对目标字符串进行个性化检索,返回我们要的结果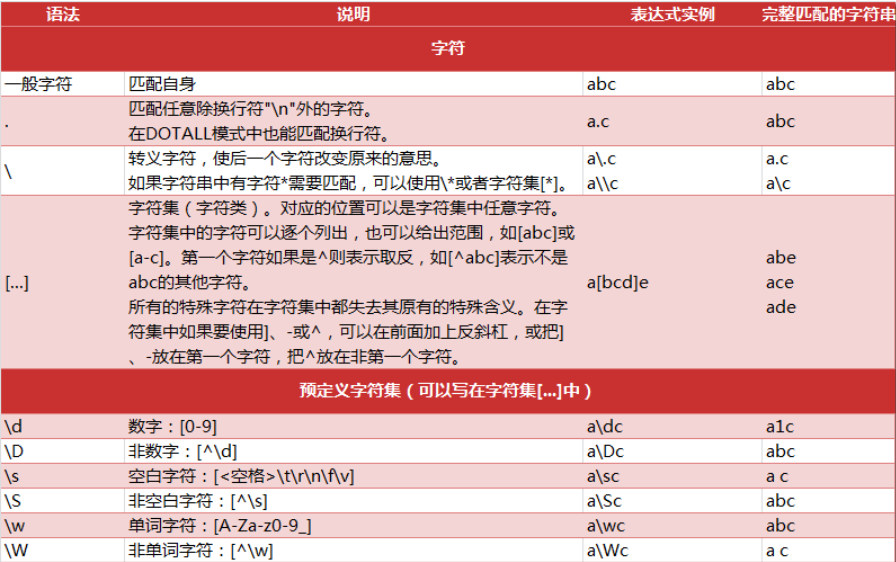
[…..]字符集合
- [abc] 指定包含字符
- [a-zA-Z] 来指定所以英文字母的大小写
-
或方法
将两个规则并列起来,以‘ | ’连接,表示只要满足其中之一就可以匹配。
[a-zA-Z]|[0-9] 表示满足数字或字母就可以匹配,这个规则等价于 [a-zA-Z0-9]
匹配数字
\d等价于[0-9]
- \D匹配非数字
- \w匹配字母和数字
- \W匹配非字母和数字
-
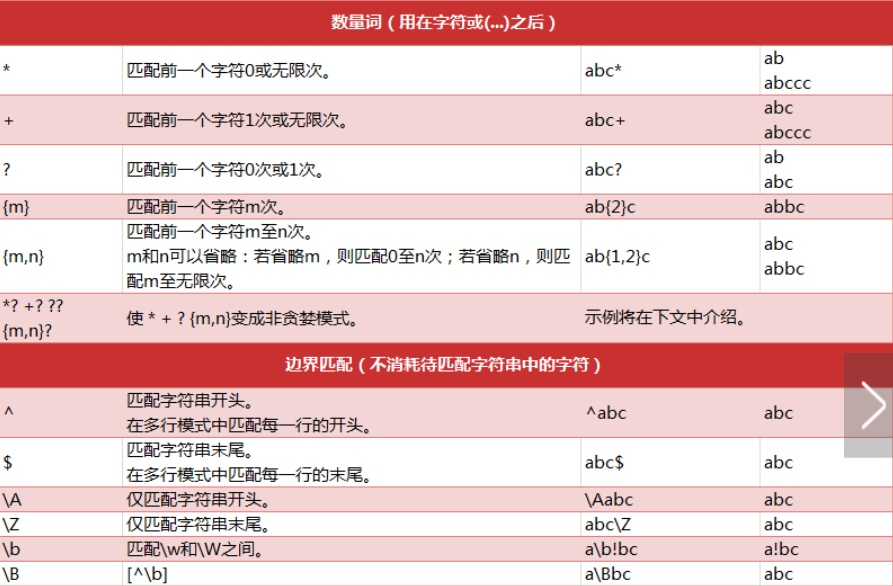
重复
正则式可以匹配不定长的字符串
‘*’0或多次匹配
- ‘+’1次或多次匹配
-
精确匹配和最小匹配
‘{m}’精确匹配m次
‘{m,n}’ 匹配最少 m 次,最多 n 次。 (n>m)
complie()
新手不建议使用https://zhuanlan.zhihu.com/p/78628786
findall()
match和search
它们的返回不是一个简单的字符串列表,而是一个 MatchObject,可以得到更多的信息。只有这样才可以用group()方法
- 如果匹配不成功,它们则返回一个 NoneType 。所以在对匹配完的结果进行操作之前,必需先判断一下是否匹配成功了。
- match 从字符串的开头开始匹配,如果开头位置没有匹配成功,就算失败了;而 search 会跳过开头,继续向后寻找是否有匹配的字符串。
字符串的替换和修改
在目标字符串中规格规则查找匹配的字符串,再把它们替换成指定的字符串。你可以指定一个最多替换次数,否则将替换所有的匹配到的字符串。
sub ( rule , replace , target [,count] )
subn(rule , replace , target [,count] )
第一个参数是正则规则,第二个参数是指定的用来替换的字符串,第三个参数是目标字符串,第四个参数是最多替换次数。
sub 返回一个被替换的字符串
subn 返回一个元组,第一个元素是被替换的字符串,第二个元素是一个数字,表明产生了多少次替换。
pattern = re.compile(r’\d’)
re.sub(pattern,’数字’,input2)
Out[34]:
‘数字数字数字自然语言处理’
In [38]:
pattern = re.compile(r’\d’)
re.subn(pattern,’’,input2)
Out[38]:
(‘自然语言处理’, 3)split 切片函数
使用指定的正则规则在目标字符串中查找匹配的字符串,用它们作为分界,把字符串切片split( rule , target [,maxsplit] )
第一个参数是正则规则,第二个参数是目标字符串,第三个参数是最多切片次数,返回一个被切完的子字符串的列表
input3 = ‘自然语言处理123机器学习456深度学习’
pattern = re.compile(r’\d+’)
re.split(pattern,input3)
Out[39]:
[‘自然语言处理’, ‘机器学习’, ‘深度学习’]group()
返回re匹配的字符串,用之前得分清对象是啥‘(?P…)’ 命名组
<…>’ 里面是你给这个组起的名字
pattern = re.compile(r’(?P\d+)(?P \D+)’)
m = re.search(pattern,input3)
m.group(‘lol’)
Out[42]:
‘机器学习’数据清洗实例
```python import re import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize nltk.download(‘stopwords’)输入数据
s = ‘ RT @Amila #Test\nTom\’s newly listed Co & Mary\’s unlisted Group to supply tech for nlTK.\nh $TSLA $AAPL https:// t.co/x34afsfQsh’
指定停用词
cache_english_stopwords = stopwords.words(‘english’)
def text_clean(text): print(‘原始数据:’, text, ‘\n’)
# 去掉HTML标签(e.g. &)text_no_special_entities = re.sub(r'\&\w*;|#\w*|@\w*', '', text)print('去掉特殊标签后的:', text_no_special_entities, '\n')# 去掉一些价值符号text_no_tickers = re.sub(r'\$\w*', '', text_no_special_entities)print('去掉价值符号后的:', text_no_tickers, '\n')# 去掉超链接text_no_hyperlinks = re.sub(r'https?:\/\/.*\/\w*', '', text_no_tickers)print('去掉超链接后的:', text_no_hyperlinks, '\n')# 去掉一些专门名词缩写,简单来说就是字母比较少的词text_no_small_words = re.sub(r'\b\w{1,2}\b', '', text_no_hyperlinks)print('去掉专门名词缩写后:', text_no_small_words, '\n')# 去掉多余的空格text_no_whitespace = re.sub(r'\s\s+', ' ', text_no_small_words)text_no_whitespace = text_no_whitespace.lstrip(' ')print('去掉空格后的:', text_no_whitespace, '\n')# 分词tokens = word_tokenize(text_no_whitespace)print('分词结果:', tokens, '\n')# 去停用词list_no_stopwords = [i for i in tokens if i not in cache_english_stopwords]print('去停用词后结果:', list_no_stopwords, '\n')# 过滤后结果text_filtered = ' '.join(list_no_stopwords) # ''.join() would join without spaces between words.print('过滤后:', text_filtered)
text_clean(s) ```

若有收获,就点个赞吧
0 人点赞
