Jvm的工作流程
在我们编写完java代码后, 生成的是.java结尾的java源码, java代码经过javac.exe(java编译器)编译成.class结尾的字节码文件(二进制的指令集) , 然后通过java.exe(java解释器)翻译成对应不同操作系统(os)的机器码, jvm的解释器翻译字节码是从上至下逐行翻译的, 翻译一行,运行一行, 而且如果重复调用一些方法,循环之类的, 就会反复的翻译, 效率低下, 因此就出现了JIT技术来提高效率, JIT将全部或者部分代码代替jvm进行翻译, 将翻译后的和机器码保存,这样就能减少重复翻译带来的不必要的效率损失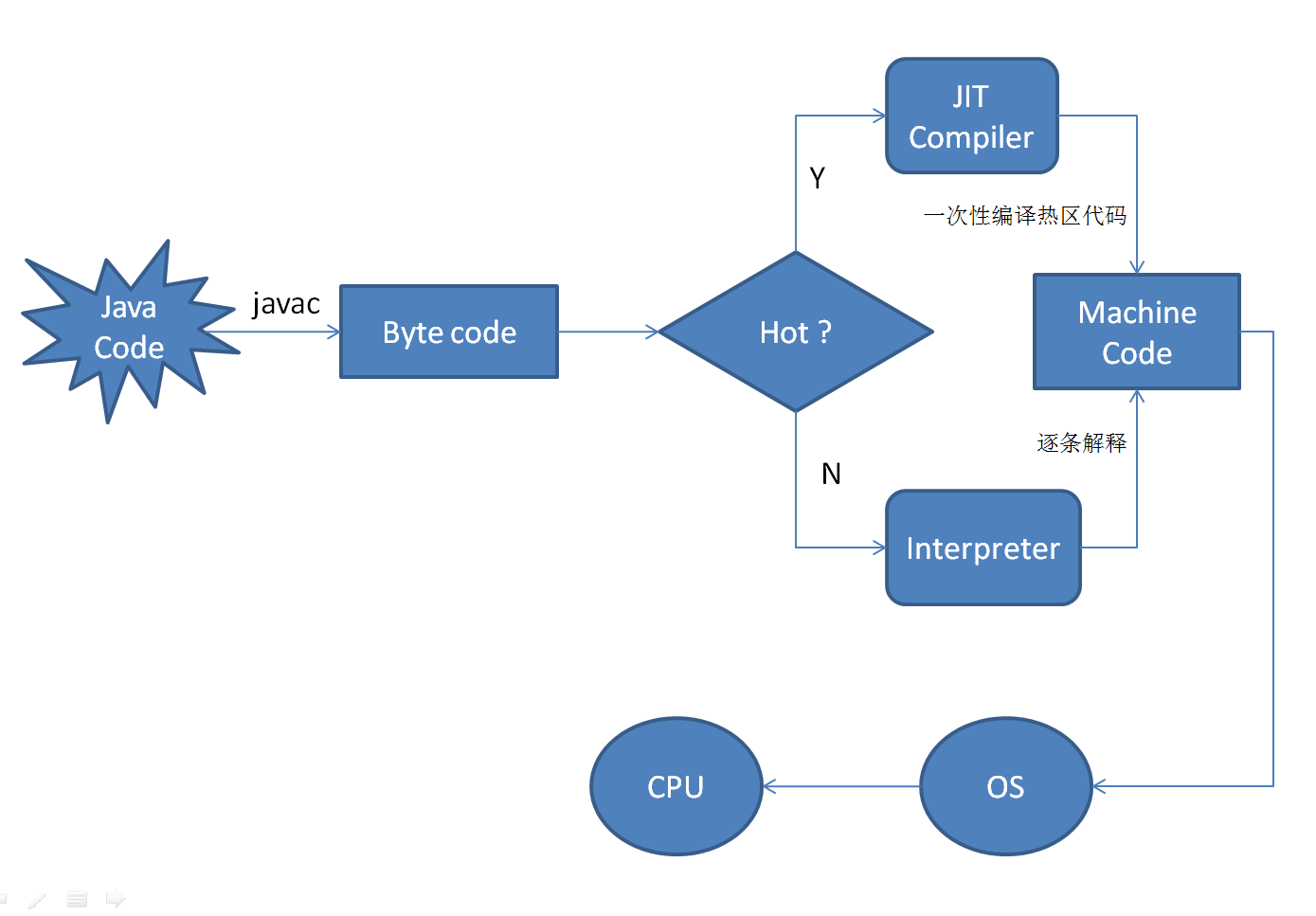
HotSpot 编译
在jvm(拥有jit技术了)执行的时候, 代码并不会直接被编译成机器码. 如果代码没有被使用或者只被使用了一次的话,那样jit替jvm进行翻译的意义就不大了,HotSpot就是判断代码是否需要进行JIT,会进行惰性判断,使用率高的代码会进行jit
寄存器和主存
public class RegisterTest {private int sum;public void calculateSum(int n) {for (int i = 0; i < n; ++i) {sum += i;}}}
从上面这个demo 来看, 每次循环将值存在主存的话是没问题的, 问题是在主存中进行索引搜索开销很大, 而JIT运用寄存器进行循环, 并将值返回到主存中这样能提高很多效率,前提是线程同步, 不同步的话一个线程无法得知另一个线程所使用的寄存器的值
寄存器的使用是JIT编译器的一个非常普遍的优化
我们将在后面讲解这些优化策略,这里,先举一个简单的例子:我们知道 equals() 这个方法存在于每一个 Java Object 中(因为是从 Object class 继承而来)而且经常被覆写。当解释器遇到 b = obj1.equals(obj2) 这样一句代码,它则会查询 obj1 的类型从而得知到底运行哪一个 equals() 方法。而这个动态查询的过程从某种程度上说是很耗时的。
JVM 注意到每次运行代码时,obj1 都是 java.lang.String 这种类型,那么 JVM 生成的被编译后的代码则是直接调用 String.equals() 方法。这样代码的执行将变得非常快,因为不仅它是被编译过的,而且它会跳过查找该调用哪个方法的步骤。当然过程并不是上面所述这样简单,如果下次执行代码时,obj1 不再是 String 类型了,JVM 将不得不再生成新的字节码。尽管如此,之后执行的过程中,还是会变的更快,因为同样会跳过查找该调用哪个方法的步骤。这种优化只会在代码被运行和观察一段时间之后发生。这也就是为什么 JIT 编译器不会理解编译代码而是选择等待然后再去编译某些代码片段的第二个原因。
初级JVM调优: 客户端模式和服务器模式
JIT编译器在运行时有两种模式可选, 分别是-server服务器模式跟-client客户端模式, 并且会在运行时来决定使用哪种模式来使性能的达到最优,server模式与client模式的区别在于,server模式启动的比较慢,但是一旦运行起来,性能会有很大的提升, 原因在于client使用的是一个名为C1的轻量级编译器,而server采用的是相对重量级的C2编译器,C2比C1编译的更彻底, 在服务起来之后性能也就越高
中级JVM编译器调优
大多数情况下,优化编译器性能都是通过选择合适的JVM和合适的编译器模式(-cient,-server 或是-xx:+TieredCompilation),多层编译器是长时运行程序的最佳选择,而毫秒级的client更合适短暂的应用程序
优化代码缓存
在 JVM编译代码的时候,它会将汇编指令集(字节码)放到代码缓存(内存)中,但是代码缓存是有大小的,一旦它被填满,JVM就不能再编译更多的代码,所以代码缓存如果很小的话就会导致有些热点代码会被编译,而其它的代码不会被编译,这个程序就得去用原始的JVM去解释字节码为机器码
这也是client跟多层编译器面临的问题-代码缓存小
目前没有较好的解决办法,只能通过提高代码缓存, 一般的做法是将代码缓存大小变成默认大小的二到四倍
可以通过 –XX:ReservedCodeCacheSize=Nflag(N 就是之前提到的默认大小)来最大化代码缓存大小。取决于硬件,cpu,位数等
所以说代码缓存并不是无限的,很多时候需要为大型应用程序来调优(或者甚至是使用分层编译的中型应用程序)。比如 64 位机器,为代码缓存设置一个很大的值并不会对应用程序本身造成影响,应用程序并不会内存溢出,这些额外的内存预定一般都是被操作系统所接受的。
编译阈值
在JVM中,编译是基于两个计数器的, 一个是方法被调用的次数,另一个是循环的回弹数,像continue也算一次
当执行一个java程序时,JVM会根据这两个计数器的总和来判断方法是否是热点方法,也就是是否有资格被编译, 如果有,就让这个方法排队等着被编译 ,官方没有给这种方式取名,不过一般叫做标准编译
如果有个很大很大的循环,以至于循环次数达到阈值,那么这个循环(并不是整个方法,只是指这个循环)会被赋予编译自个, 这是因为循环每一次执行都会进行自增跟自检,看是否达到阈值,这种编译方式叫做栈上替换(OSR)尽可能的立即完成编译,并且在完成必要的栈帧迁移转换后立即执行编译后的本地代码,即完成栈上替换。也就是说 比如这个循环有1000次 在第500的时候已经触发阈值了, 那么它就会替换栈上的方法为编译后的方法,也就是第501次开始运行编译后的方法.这种能力叫做栈上替换
标准编译是被-XX:CompileThreshold=Nflag 的值所触发。Client 编译器模式下,N 默认的值 1500,而 Server 编译器模式下,N 默认的值则是 10000。
多层编译机制
为了平衡启动跟顶峰性能的需求,主流的jvm都采用多层编译机制,在刚还是使用比较低优化的层级来执行,等代码热了以后再使用高优化的层级
检查编译过程
XX:+PrintCompilation(默认状态下是 false)。
如果 PrintCompilation 被启用,每次一个方法(或循环)被编译,JVM 都会打印出刚刚编译过的相关信息。不同的 Java 版本输出形式不一样
要想看到编译日志,则需要程序以-XX:+PrintCompilation flag 启动。如果程序启动时没有 flag,您可以通过 jstat 命令得到有限的可见性信息。
Jstat 有两个选项可以提供编译器信息。其中,-compile 选项提供总共有多少方法被编译的总结信息(下面 6006 是要被检查的程序的进程 ID):
% jstat -compiler 6006CompiledFailedInvalid TimeFailedTypeFailedMethod206 0 0 1.97 0
Jstat 对 6006 号 ID 进程每 1000 毫秒执行一次: %jstat –printcompilation 6006 1000,具体的
高级编译器调优-线程编译
我们知道当一个方法拥有了编译资格以后,他们就会排队等待被编译.这个队列是由一个或者很多个后台线程组成,这也就说明编译是一个异步的过程, 它允许程序在代码被编译的时候被执行,如果一个循环被栈上替换,那么下一次执行也会使用新的代码
这些排队的代码排队并不是按照先进先出原则, 而是谁的计数大谁就先编译
C1与C2编译器默认线程的数量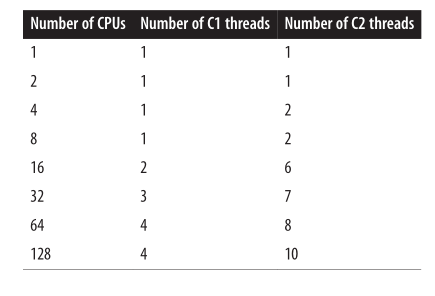
编译器线程的数量可以通过-XX:CICompilerCount=N flag 进行调节设置。这个数量是 JVM 将要执行队列所用的线程总数。对于分层编译,三分之一的(至少一个)线程被用于执行 client 编译器队列,剩下的(也是至少一个)被用来执行 server 编译器队列。

若有收获,就点个赞吧
0 人点赞
