Java 泛型的核心概念:你只需告诉编译器要使用什么类型,剩下的细节交给它来处理。]
简单泛型
促成泛型出现的最主要的动机之一是为了创建集合类,参见 集合 章节。集合用于存放要使用到的对象。数组也是如此,不过集合比数组更加灵活,功能更丰富。几乎所有程序在运行过程中都会涉及到一组对象,因此集合是可复用性最高的类库之一。
我们先看一个只能持有单个对象的类。这个类可以明确指定其持有的对象的类型:
// generics/Holder1.java
class Automobile {}
public class Holder1 {
private Automobile a;
public Holder1(Automobile a) { this.a = a; }
Automobile get() { return a; }
}
这个类的可复用性不高,它无法持有其他类型的对象。我们可不希望为碰到的每个类型都编写一个新的类。
在 Java 5 之前,我们可以让这个类直接持有 Object 类型的对象:
// generics/ObjectHolder.java
public class ObjectHolder {
private Object a;
public ObjectHolder(Object a) { this.a = a; }
public void set(Object a) { this.a = a; }
public Object get() { return a; }
public static void main(String[] args) {
ObjectHolder h2 = new ObjectHolder(new Automobile());
Automobile a = (Automobile)h2.get();
h2.set(“Not an Automobile”);
String s = (String)h2.get();
h2.set(1); // 自动装箱为 Integer
Integer x = (Integer)h2.get();
}
}
现在,ObjectHolder 可以持有任何类型的对象,在上面的示例中,一个 ObjectHolder 先后持有了三种不同类型的对象。
一个集合中存储多种不同类型的对象的情况很少见,通常而言,我们只会用集合存储同一种类型的对象。泛型的主要目的之一就是用来约定集合要存储什么类型的对象,并且通过编译器确保规约得以满足。
因此,与其使用 Object ,我们更希望先指定一个类型占位符,稍后再决定具体使用什么类型。要达到这个目的,需要使用类型参数,用尖括号括住,放在类名后面。然后在使用这个类时,再用实际的类型替换此类型参数。在下面的例子中,T 就是类型参数:
public class GenericHolder
private T a;
public GenericHolder() {}
public void set(T a) { this.a = a; }
public T get() { return a; }
public static void main(String[] args) {
GenericHolder
h3.set(new Automobile()); // 此处有类型校验
Automobile a = h3.get(); // 无需类型转换
//- h3.set(“Not an Automobile”); // 报错
//- h3.set(1); // 报错
}
}
java7之后GenericHolder
一个元组类库
有时候想要返回多个属性 但是java的return只能返回一个属性 ,这个时候可以把属性放到对象中返回, 当然还有其他的方法 , 另一种就是通过返回元祖
元祖:它是将一组对象直接打包存储于单一对象中。可以从该对象读取其中的元素,但不允许向其中存储新对象(这个概念也称为 数据传输对象 或 信使 )。
// generics/Amphibian.javapublic class Amphibian {}// generics/Vehicle.javapublic class Vehicle {}// onjava/Tuple2.javapackage onjava;public class Tuple2<A, B> {public final A a1;public final B a2;public Tuple2(A a, B b) { a1 = a; a2 = b; }public String rep() { return a1 + ", " + a2; }@Overridepublic String toString() {return "(" + rep() + ")";}}// onjava/Tuple3.javapackage onjava;public class Tuple3<A, B, C> extends Tuple2<A, B> {public final C a3;public Tuple3(A a, B b, C c) {super(a, b);a3 = c;}@Overridepublic String rep() {return super.rep() + ", " + a3;}}// onjava/Tuple4.javapackage onjava;public class Tuple4<A, B, C, D>extends Tuple3<A, B, C> {public final D a4;public Tuple4(A a, B b, C c, D d) {super(a, b, c);a4 = d;}@Overridepublic String rep() {return super.rep() + ", " + a4;}}// onjava/Tuple5.javapackage onjava;public class Tuple5<A, B, C, D, E>extends Tuple4<A, B, C, D> {public final E a5;public Tuple5(A a, B b, C c, D d, E e) {super(a, b, c, d);a5 = e;}@Overridepublic String rep() {return super.rep() + ", " + a5;}}// generics/TupleTest.javaimport onjava.*;public class TupleTest {static Tuple2<String, Integer> f() {// 47 自动装箱为 Integerreturn new Tuple2<>("hi", 47);}static Tuple3<Amphibian, String, Integer> g() {return new Tuple3<>(new Amphibian(), "hi", 47);}static Tuple4<Vehicle, Amphibian, String, Integer> h() {return new Tuple4<>(new Vehicle(), new Amphibian(), "hi", 47);}static Tuple5<Vehicle, Amphibian, String, Integer, Double> k() {return new Tuple5<>(new Vehicle(), new Amphibian(), "hi", 47, 11.1);}public static void main(String[] args) {Tuple2<String, Integer> ttsi = f();System.out.println(ttsi);// ttsi.a1 = "there"; // 编译错误,因为 final 不能重新赋值System.out.println(g());System.out.println(h());System.out.println(k());}}/* 输出:(hi, 47)(Amphibian@1540e19d, hi, 47)(Vehicle@7f31245a, Amphibian@6d6f6e28, hi, 47)(Vehicle@330bedb4, Amphibian@2503dbd3, hi, 47, 11.1)*/
通过上面的demo你可以发现你可以很简单的通过构造函数传参创建元祖, 然后用返回元组对象, 从元组对象中拿对象
泛型接口
泛型也可以应用于接口。例如 生成器,这是一种专门负责创建对象的类。实际上,这是 工厂方法 设计模式的一种应用。不过,当使用生成器创建新的对象时,它不需要任何参数,而工厂方法一般需要参数。生成器无需额外的信息就知道如何创建新对象。
一般而言,一个生成器只定义一个方法,用于创建对象。例如 java.util.function 类库中的 Supplier 就是一个生成器,调用其 get() 获取对象。get() 是泛型方法,返回值为类型参数 T。
// generics/Fibonacci.java// Generate a Fibonacci sequenceimport java.util.function.*;import java.util.stream.*;public class Fibonacci implements Supplier<Integer> {private int count = 0;@Overridepublic Integer get() { return fib(count++); }private int fib(int n) {if(n < 2) return 1;return fib(n-2) + fib(n-1);}public static void main(String[] args) {Stream.generate(new Fibonacci()).limit(18).map(n -> n + " ").forEach(System.out::print);}}结果:1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584
这个例子表现, java中基本类型无法使用泛型,不过好在有java5之后提供了自动拆箱装箱功能
泛型方法
泛型方法独立于类而改变方法。作为准则,请“尽可能”使用泛型方法。通常将单个方法泛型化要比将整个类泛型化更清晰易懂。
如果方法是 static 的,则无法访问该类的泛型类型参数,因此,如果使用了泛型类型参数,则它必须是泛型方法。
要定义泛型方法,请将泛型参数列表放置在返回值之前,如下所示:
// generics/GenericMethods.javapublic class GenericMethods {public <T> void f(T x) {System.out.println(x.getClass().getName());}public static void main(String[] args) {GenericMethods gm = new GenericMethods();gm.f("");gm.f(1);gm.f(1.0);gm.f(1.0F);gm.f('c');gm.f(gm);}}/* Output:java.lang.Stringjava.lang.Integerjava.lang.Doublejava.lang.Floatjava.lang.CharacterGenericMethods*/
变长参数和泛型方法
泛型方法和变长参数列表可以很好地共存
// generics/GenericVarargs.javaimport java.util.ArrayList;import java.util.List;public class GenericVarargs {@SafeVarargspublic static <T> List<T> makeList(T... args) {List<T> result = new ArrayList<>();for (T item : args)result.add(item);return result;}public static void main(String[] args) {List<String> ls = makeList("A");System.out.println(ls);ls = makeList("A", "B", "C");System.out.println(ls);ls = makeList("ABCDEFFHIJKLMNOPQRSTUVWXYZ".split(""));System.out.println(ls);}}/* Output:[A][A, B, C][A, B, C, D, E, F, F, H, I, J, K, L, M, N, O, P, Q, R,S, T, U, V, W, X, Y, Z]*/
@SafeVarargs 注解保证我们不会对变长参数列表进行任何修改,这是正确的,因为我们只从中读取。如果没有此注解,编译器将无法知道这些并会发出警告。
一个 Set 工具
对于泛型方法的另一个示例,请考虑由 Set 表示的数学关系。这些被方便地定义为可用于所有不同类型的泛型方法:
// onjava/Sets.javapackage onjava;import java.util.HashSet;import java.util.Set;public class Sets {public static <T> Set<T> union(Set<T> a, Set<T> b) {Set<T> result = new HashSet<>(a);result.addAll(b);return result;}public static <T>Set<T> intersection(Set<T> a, Set<T> b) {Set<T> result = new HashSet<>(a);result.retainAll(b);return result;}// Subtract subset from superset:public static <T> Set<T>difference(Set<T> superset, Set<T> subset) {Set<T> result = new HashSet<>(superset);result.removeAll(subset);return result;}// Reflexive--everything not in the intersection:public static <T> Set<T> complement(Set<T> a, Set<T> b) {return difference(union(a, b), intersection(a, b));}}
这四种方法代表数学集合操作: union() 返回一个包含两个参数并集的 Set , intersection() 返回一个包含两个参数集合交集的 Set , difference() 从 superset 中减去 subset 的元素 ,而 complement() 返回所有不在交集中的元素的 Set
**
泛型擦除
import java.util.*;public class ErasedTypeEquivalence {public static void main(String[] args) {Class c1 = new ArrayList<String>().getClass();Class c2 = new ArrayList<String>().getClass();System.out.println(c1 == c2);}}/* Output:true*/
从上面这个demo中可以看出看出, 尽管你往ArrayList
下面的例子是对该谜题的补充:
// generics/LostInformation.javaimport java.util.*;class Frob {}class Fnorkle {}class Quark<Q> {}class Particle<POSITION, MOMENTUM> {}public class LostInformation {public static void main(String[] args) {List<Frob> list = new ArrayList<>();Map<Frob, Fnorkle> map = new HashMap<>();Quark<Fnorkle> quark = new Quark<>();Particle<Long, Double> p = new Particle<>();System.out.println(Arrays.toString(list.getClass().getTypeParameters()));System.out.println(Arrays.toString(map.getClass().getTypeParameters()));System.out.println(Arrays.toString(quark.getClass().getTypeParameters()));System.out.println(Arrays.toString(p.getClass().getTypeParameters()));}}/* Output:[E][K,V][Q][POSITION,MOMENTUM]*/
根据 JDK 文档,Class.getTypeParameters() “返回一个 TypeVariable 对象数组,表示泛型声明中声明的类型参数…” 这暗示你可以发现这些参数类型。但是正如上例中输出所示,你只能看到用作参数占位符的标识符,这并非有用的信息。
残酷的现实是:
在泛型代码内部,无法获取任何有关泛型参数类型的信息
因此你只能知道类型参数标识符和泛型边界这些信息,但无法得知实际的类型参数从而来创建特定的实例。
Java的泛型是使用擦除实现的,这意味着当你在使用泛型的时候,任何具体的类型信息都被擦除了,你唯一知道的就只是你在使用一个对象,因此,List<String> 和 List<Integer> 在运行时实际上是相同的类型。它们都被擦除成原生类型 List。
public class Manipulator2<T extends HasF> {private T obj;Manipulator2(T x) {obj = x;}public void manipulate() {obj.f();}}
这里的
我们说泛型参数会擦除到它的第一个边界(可能有多个边界), 编译器实际上会把类型参数替换为它的擦除,就像上面的示例,T 擦除到了 HasF,就像在类的声明中用 HasF 替换了 T 一样。
你可能正确地观察到了泛型在 Manipulator2.java 中没有贡献任何事。你可以很轻松地自己去执行擦除,生成没有泛型的类
这提出了很重要的一点:泛型只有在类型参数比某个具体类型(以及其子类)更加“泛化”——代码能跨多个类工作时才有用。因此,类型参数和它们在有用的泛型代码中的应用,通常比简单的类替换更加复杂。但是,不能因此认为使用 <T extends HasF> 形式就是有缺陷的。例如,如果某个类有一个返回 T 的方法,那么泛型就有所帮助,因为它们之后将返回确切的类型:
public class ReturnGenericType<T extends HasF> {private T obj;ReturnGenericType(T x) {obj = x;}public T get() {return obj;}}
迁移兼容性
泛型擦除并不是java语音的特性,而是为了解决迁移兼容性的一种妥协.
在泛型擦除的实现中,泛型类型被当作第二类型处理,即不能在某些重要的上下文使用泛型。
泛型类型只有在静态类型检测期间才出现,在此之后程序中的泛型将被擦除,替换为他们的非泛型上界,例如List
核心擦除的动机是你在泛化的客户端上使用非泛化的类库,反之亦然,这被称为“迁移兼容性”,就算有一天所有的程序都要实现泛化,那也必须处理java5之前的非泛化类库,而原来的非泛化类库的设计者们可能都没有想过以后会出现泛化这一说,例如,假设一个应用使用了两个类库 X 和 Y,Y 使用了类库 Z。随着 Java 5 的出现,这个应用和这些类库的创建者最终可能希望迁移到泛型上。但是当进行迁移时,它们有着不同的动机和限制。为了实现迁移兼容性,每个类库与应用必须与其他所有的部分是否使用泛型无关。因此,它们不能探测其他类库是否使用了泛型。因此,某个特定的类库使用了泛型这样的证据必须被”擦除“。
如果没有某种类型的迁移途径,所有已经构建了很长时间的类库就需要与希望迁移到 Java 泛型上的开发者们说再见了。类库毫无争议是编程语言的一部分,对生产效率有着极大的影响,所以这种代码无法接受。擦除是否是最佳的或唯一的迁移途径,还待时间来证明。
总结起来就是:Java的类库不是都支持泛型的,类库与类库之间也无法判断其它是否使用的泛型,所以只能将其擦除,来实现类库的可用性,是一种妥协
擦除的问题
因此,擦除主要的正当理由是从非泛化代码到泛化代码的转变过程,以及在不破坏现有类库的情况下将泛型融入到语言中。擦除允许你继续使用现有的非泛型客户端代码,直至客户端准备好用泛型重写这些代码。这是一个崇高的动机,因为它不会骤然破坏所有现有的代码。
擦除的代价是显著的。泛型不能用于显式地引用运行时类型的操作中,例如转型、instanceof 操作和 new 表达式。因为所有关于参数的类型信息都丢失了,当你在编写泛型代码时,必须时刻提醒自己,你只是看起来拥有有关参数的类型信息而已。
@SuppressWarnings(“unchecked”)
这个注解是JAVA提供的用来关闭警告的, 放在方法上面
边界处的动作
因为擦除,我发现了泛型最令人困惑的方面是可以表示没有任何意义的事物。例如:
// generics/ArrayMaker.javaimport java.lang.reflect.*;import java.util.*;public class ArrayMaker<T> {private Class<T> kind;public ArrayMaker(Class<T> kind) {this.kind = kind;}@SuppressWarnings("unchecked")T[] create(int size) {return (T[]) Array.newInstance(kind, size);}public static void main(String[] args) {ArrayMaker<String> stringMaker = new ArrayMaker<>(String.class);String[] stringArray = stringMaker.create(9);System.out.println(Arrays.toString(stringArray));}}/* Output[null,null,null,null,null,null,null,null,null]*/
即使 kind 被存储为 Class<T>,擦除也意味着它实际被存储为没有任何参数的 Class。因此,当你在使用它时,例如创建数组,Array.newInstance() 实际上并未拥有 kind 所蕴含的类型信息。所以它不会产生具体的结果,因而必须转型,这会产生一条令你无法满意的警告。
本例中这么做真的毫无意义吗?如果在创建 List 的同时向其中放入一些对象呢,像这样:
// generics/FilledList.java
import java.util.*;
import java.util.function.*;
import onjava.*;
public class FilledList<T> extends ArrayList<T> {
FilledList(Supplier<T> gen, int size) {
Suppliers.fill(this, gen, size);
}
public FilledList(T t, int size) {
for (int i = 0; i < size; i++) {
this.add(t);
}
}
public static void main(String[] args) {
List<String> list = new FilledList<>("Hello", 4);
System.out.println(list);
// Supplier version:
List<Integer> ilist = new FilledList<>(() -> 47, 4);
System.out.println(ilist);
}
}
/* Output:
[Hello,Hello,Hello,Hello]
[47,47,47,47]
*/
即使编译器无法得知 add() 中的 T 的任何信息,但它仍可以在编译期确保你放入 FilledList 中的对象是 T 类型。因此,即使擦除移除了方法或类中的实际类型的信息,编译器仍可以确保方法或类中使用的类型的内部一致性。
因为擦除移除了方法体中的类型信息,所以在运行时的问题就是边界:即对象进入和离开方法的地点。这些正是编译器在编译期执行类型检查并插入转型代码的地点。
考虑如下这段非泛型示例:
// generics/SimpleHolder.java
public class SimpleHolder {
private Object obj;
public void set(Object obj) {
this.obj = obj;
}
public Object get() {
return obj;
}
public static void main(String[] args) {
SimpleHolder holder = new SimpleHolder();
holder.set("Item");
String s = (String) holder.get();
}
}
如果用 javap -c SimpleHolder 反编译这个类,会得到如下内容(经过编辑):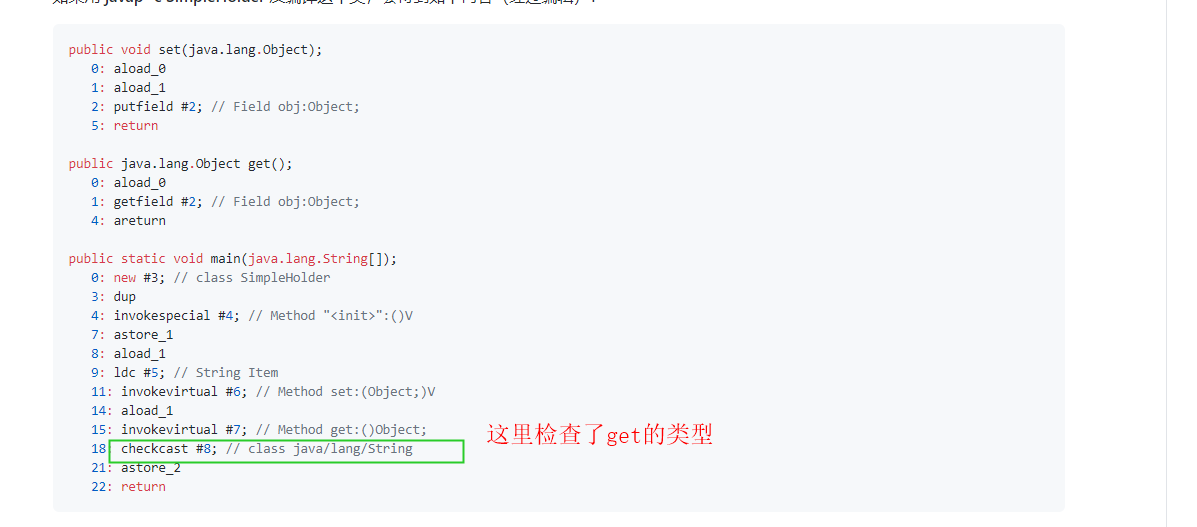
set() 和 get() 方法存储和产生值,转型在调用 get() 时接受检查。
现在将泛型融入上例代码中:
// generics/GenericHolder2.java
public class GenericHolder2<T> {
private T obj;
public void set(T obj) {
this.obj = obj;
}
public T get() {
return obj;
}
public static void main(String[] args) {
GenericHolder2<String> holder = new GenericHolder2<>();
holder.set("Item");
String s = holder.get();
}
}
这里就不需要强制转型了
从 get() 返回后的转型消失了,但是我们还知道传递给 set() 的值在编译期会被检查。下面是相关的字节码: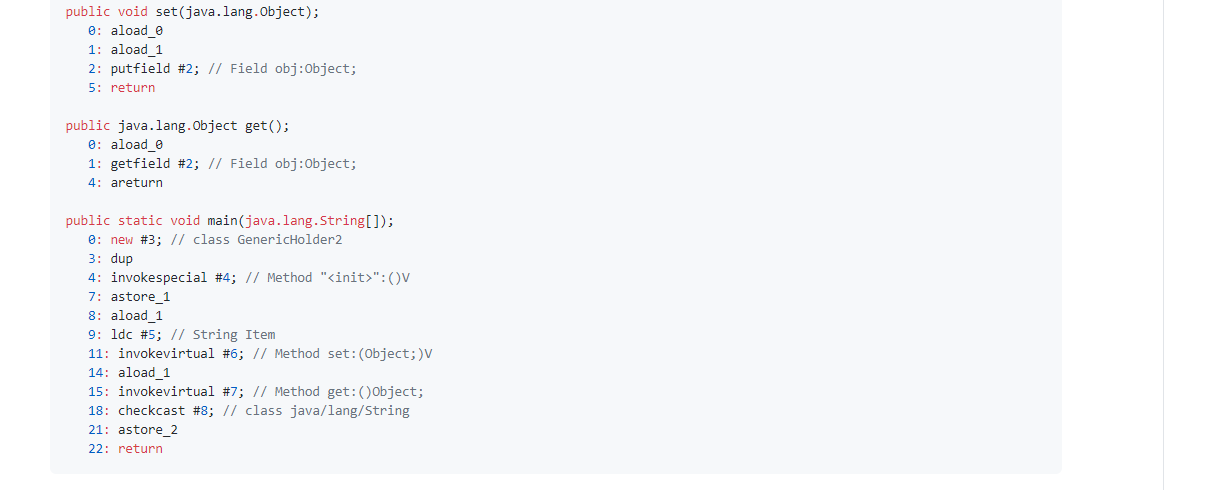
这里可以发现 两种方法的字节码是一样的
所产生的字节码是相同的。对进入 set() 的类型进行检查是不需要的,因为这将由编译器执行。而对 get() 返回的值进行转型仍然是需要的,只不过不需要你来操作,它由编译器自动插入,这样你就不用编写(阅读)杂乱的代码。
get() 和 set() 产生了相同的字节码,这就告诉我们泛型的所有动作都发生在边界处——对入参的编译器检查和对返回值的转型。这有助于澄清对擦除的困惑,记住:“边界就是动作发生的地方”。
总结: 泛型擦除 就是除了边界位置,其它的地方都会给你把泛型擦除掉来处理,只有参数传入跟产出的时候才会有类型
补偿擦除
因为擦除,我们将失去执行泛型代码中某些操作的能力。无法在运行时知道确切类型:
// generics/Erased.java
// {WillNotCompile}
public class Erased<T> {
private final int SIZE = 100;
public void f(Object arg) {
// error: illegal generic type for instanceof
if (arg instanceof T) {
}
// error: unexpected type
T var = new T();
// error: generic array creation
T[] array = new T[SIZE];
// warning: [unchecked] unchecked cast
T[] array = (T[]) new Object[SIZE];
}
}
由于擦除了类型信息,因此在尝试使用 instanceof 将会失败
我们可以对这些问题进行编程,但是有时必须通过引入类型标签来补偿擦除。这意味着为所需的类型显式传递一个 Class 对象,以在类型表达式中使用它。(还是通过对象附带的信息来解决泛型擦除导致的没有类型的问题) ->也就是你主动传类型信息进去
类型标签可以使用动态 isInstance() :
// generics/ClassTypeCapture.java
class Building {
}
class House extends Building {
}
public class ClassTypeCapture<T> {
Class<T> kind;
public ClassTypeCapture(Class<T> kind) {
this.kind = kind;
}
public boolean f(Object arg) {
return kind.isInstance(arg);
}
public static void main(String[] args) {
ClassTypeCapture<Building> ctt1 =
new ClassTypeCapture<>(Building.class);
System.out.println(ctt1.f(new Building()));
System.out.println(ctt1.f(new House()));
ClassTypeCapture<House> ctt2 =
new ClassTypeCapture<>(House.class);
System.out.println(ctt2.f(new Building()));
System.out.println(ctt2.f(new House()));
}
}
/* Output:
true
true
false
true
*/
边界
边界(bounds)在本章的前面进行了简要介绍。边界允许我们对泛型使用的参数类型施加约束。尽管这可以强制执行有关应用了泛型类型的规则,但潜在的更重要的效果是我们可以在绑定的类型中调用方法。
由于擦除会删除类型信息,因此唯一可用于无限制泛型参数的方法是那些 Object 可用的方法。但是,如果将该参数限制为某类型的子集,则可以调用该子集中的方法。为了应用约束,Java 泛型使用了 extends 关键字。
边界 说白了就是限定上界
通配符
// generics/CovariantArrays.java
class Fruit {}
class Apple extends Fruit {}
class Jonathan extends Apple {}
class Orange extends Fruit {}
public class CovariantArrays {
public static void main(String[] args) {
Fruit[] fruit = new Apple[10];
fruit[0] = new Apple(); // OK
fruit[1] = new Jonathan(); // OK
// Runtime type is Apple[], not Fruit[] or Orange[]:
try {
// Compiler allows you to add Fruit:
fruit[0] = new Fruit(); // ArrayStoreException
} catch (Exception e) {
System.out.println(e);
}
try {
// Compiler allows you to add Oranges:
fruit[0] = new Orange(); // ArrayStoreException
} catch (Exception e) {
System.out.println(e);
}
}
}
/* Output:
java.lang.ArrayStoreException: Fruit
java.lang.ArrayStoreException: Orange
main() 中的第一行创建了 Apple 数组,并赋值给一个 Fruit 数组引用。这是有意义的,因为 Apple 也是一种 Fruit,因此 Apple 数组应该也是一个 Fruit 数组。
但是,如果实际的数组类型是 Apple[],你可以在其中放置 Apple 或 Apple 的子类型,这在编译期和运行时都可以工作。但是你也可以在数组中放置 Fruit 对象。这对编译器来说是有意义的,因为它有一个 Fruit[] 引用——它有什么理由不允许将 Fruit 对象或任何从 Fruit 继承出来的对象(比如 Orange),放置到这个数组中呢?因此在编译期,这是允许的。然而,运行时的数组机制知道它处理的是 Apple[],因此会在向数组中放置异构类型时抛出异常。
向上转型用在这里不合适。你真正在做的是将一个数组赋值给另一个数组。数组的行为是持有其他对象,这里只是因为我们能够向上转型而已,所以很明显,数组对象可以保留有关它们包含的对象类型的规则。看起来就像数组对它们持有的对象是有意识的,因此在编译期检查和运行时检查之间,你不能滥用它们。
数组的这种赋值并不是那么可怕,因为在运行时你可以发现插入了错误的类型。但是泛型的主要目标之一是将这种错误检测移到编译期
// generics/NonCovariantGenerics.java
// {WillNotCompile}
import java.util.*;
public class NonCovariantGenerics {
// Compile Error: incompatible types:
List<Fruit> flist = new ArrayList<Apple>();
}
尽管你在首次阅读这段代码时会认为“不能将一个 Apple 集合赋值给一个 Fruit 集合”。记住,泛型不仅仅是关于集合,它真正要表达的是“不能把一个涉及 Apple 的泛型赋值给一个涉及 Fruit 的泛型”。如果像在数组中的情况一样,编译器对代码的了解足够多,可以确定所涉及到的集合,那么它可能会留下一些余地。但是它不知道任何有关这方面的信息,因此它拒绝向上转型。然而实际上这也不是向上转型—— Apple 的 List 不是 Fruit 的 List。Apple 的 List 将持有 Apple 和 Apple 的子类型,Fruit 的 List 将持有任何类型的 Fruit。是的,这包括 Apple,但是它不是一个 Apple 的 List,它仍然是 Fruit 的 List。Apple 的 List 在类型上不等价于 Fruit 的 List,即使 Apple 是一种 Fruit 类型。
白话说也就是apple能向上转型成fruit,但是呢,现在的主角是list 而不是apple,apple只是它的泛型而已
真正的问题是我们在讨论的集合类型,而不是集合持有对象的类型。与数组不同,泛型没有内建的协变类型。这是因为数组是完全在语言中定义的,因此可以具有编译期和运行时的内建检查,但是在使用泛型时,编译器和运行时系统不知道你想用类型做什么,以及应该采用什么规则。
有时你想在两个类型间建立某种向上转型关系。通配符可以产生这种关系。
List<? extends Fruit> flist = new ArrayList
这样写就是可以的 -》也就是通配符的作用就让list因为其类型的继承关系可以进行转型
flist 的类型现在是 List<? extends Fruit>,你可以读作“一个具有任何从 Fruit 继承的类型的列表”。然而,这实际上并不意味着这个 List 将持有任何类型的 Fruit。通配符引用的是明确的类型,因此它意味着“某种 flist 引用没有指定的具体类型”。因此这个被赋值的 List 必须持有诸如 Fruit 或 Apple 这样的指定类型,但是为了向上转型为 Fruit,这个类型是什么没人在意。
// generics/GenericsAndCovariance.java
import java.util.*;
public class GenericsAndCovariance {
public static void main(String[] args) {
// Wildcards allow covariance:
List<? extends Fruit> flist = new ArrayList<>();
// Compile Error: can't add any type of object:
// flist.add(new Apple());
// flist.add(new Fruit());
// flist.add(new Object());
flist.add(null); // Legal but uninteresting
// We know it returns at least Fruit:
Fruit f = flist.get(0);
}
}
flist 的类型现在是 List<? extends Fruit>,你可以读作“一个具有任何从 Fruit 继承的类型的列表”。然而,这实际上并不意味着这个 List 将持有任何类型的 Fruit。通配符引用的是明确的类型,因此它意味着“某种 flist 引用没有指定的具体类型”。因此这个被赋值的 List 必须持有诸如 Fruit 或 Apple 这样的指定类型,但是为了向上转型为 Fruit,这个类型是什么没人在意。
List 必须持有一种具体的 Fruit 或 Fruit 的子类型,但是如果你不关心具体的类型是什么,那么你能对这样的 List 做什么呢?如果不知道 List 中持有的对象是什么类型,你怎能保证安全地向其中添加对象呢?就像在 CovariantArrays.java 中向上转型一样,你不能,除非编译器而不是运行时系统可以阻止这种操作的发生。你很快就会发现这个问题。
你可能认为事情开始变得有点走极端了,因为现在你甚至不能向刚刚声明过将持有 Apple 对象的 List 中放入一个 Apple 对象。是的,但编译器并不知道这一点。List<? extends Fruit> 可能合法地指向一个 List<Orange>。一旦执行这种类型的向上转型,你就丢失了向其中传递任何对象的能力,甚至传递 Object 也不行。
另一方面,如果你调用了一个返回 Fruit 的方法,则是安全的,因为你知道这个 List 中的任何对象至少具有 Fruit 类型,因此编译器允许这么做。
这里可以看到 泛型就像是一个看门的, 具体的泛型是啥它才让你传进来啥, 如果是? 那就啥都不让你传,因为它自己都不知道?代表的是哪个类型。看到extend Fruit呢 就说明它里面的东西可能是Fruit的子类或者Fruit,但你也不知道具体是啥,不过返回的结果可以是Fruit或者向上转型为Fruit
逆变
使用超类型通配符。可以声明通配符是由某个特定类的任何基类来界定的方法是指定 <?super MyClass> ,或者甚至使用类型参数: <?super T>
通过这个超类通配符就可以使用add了
// generics/SuperTypeWildcards.java
import java.util.*;
public class SuperTypeWildcards {
static void writeTo(List<? super Apple> apples) {
apples.add(new Apple());
apples.add(new Jonathan());
// apples.add(new Fruit()); // Error
}
}
问题
任何基本类型都不能作为类型参数
Java 泛型的限制之一是不能将基本类型用作类型参数。因此,不能创建 ArrayList<int> 之类的东西。 解决方法是使用基本类型的包装器类以及自动装箱机制。
实现参数化接口
一个类不能实现同一个泛型接口的两种变体,由于擦除的原因,这两个变体会成为相同的接口。下面是产生这种冲突的情况:
// generics/MultipleInterfaceVariants.java
// {WillNotCompile}
package generics;
interface Payable<T> {}
class Employee implements Payable<Employee> {}
class Hourly extends Employee implements Payable<Hourly> {}
Hourly 不能编译,因为擦除会将 Payable<Employe> 和 Payable<Hourly> 简化为相同的类 Payable,这样,上面的代码就意味着在重复两次地实现相同的接口。十分有趣的是,如果从 Payable 的两种用法中都移除掉泛型参数(就像编译器在擦除阶段所做的那样)这段代码就可以编译。
转型和警告
使用带有泛型类型参数的转型或 instanceof 不会有任何效果。
重载
下面的程序是不能编译的,即使它看起来是合理的:
// {WillNotCompile}
import java.util.*;
public class UseList<W, T> {
void f(List<T> v) {}
void f(List<W> v) {}
}
因为擦除,所以重载方法产生了相同的类型签名。

若有收获,就点个赞吧
0 人点赞
