https://www.cnblogs.com/dj-TechMan/p/7700230.html
hashMap的基本原理
HashMap底层就是一个数组结构,数组中的每一项又是一个链表。这个数据是有对应下标的.想往hash表里放数据,需要先进行散列运算, 而散列运算最近本的算法就是取模运算,如果算出的hash值已经存在,则在该位置追加链表,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。 也就是说 不同的key的hash值可能是相同的, 所以先定位到数组的位置,之后,先判断链表中的key跟你要查找的key是否equal, 相等的话,返回value
归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
这里还有一个知识点:
在java 1.8之后引入了红黑树, 条件是 当链表长度大于8 且表长度(就那个数组)大于64的时候,hashMap会转成红黑树
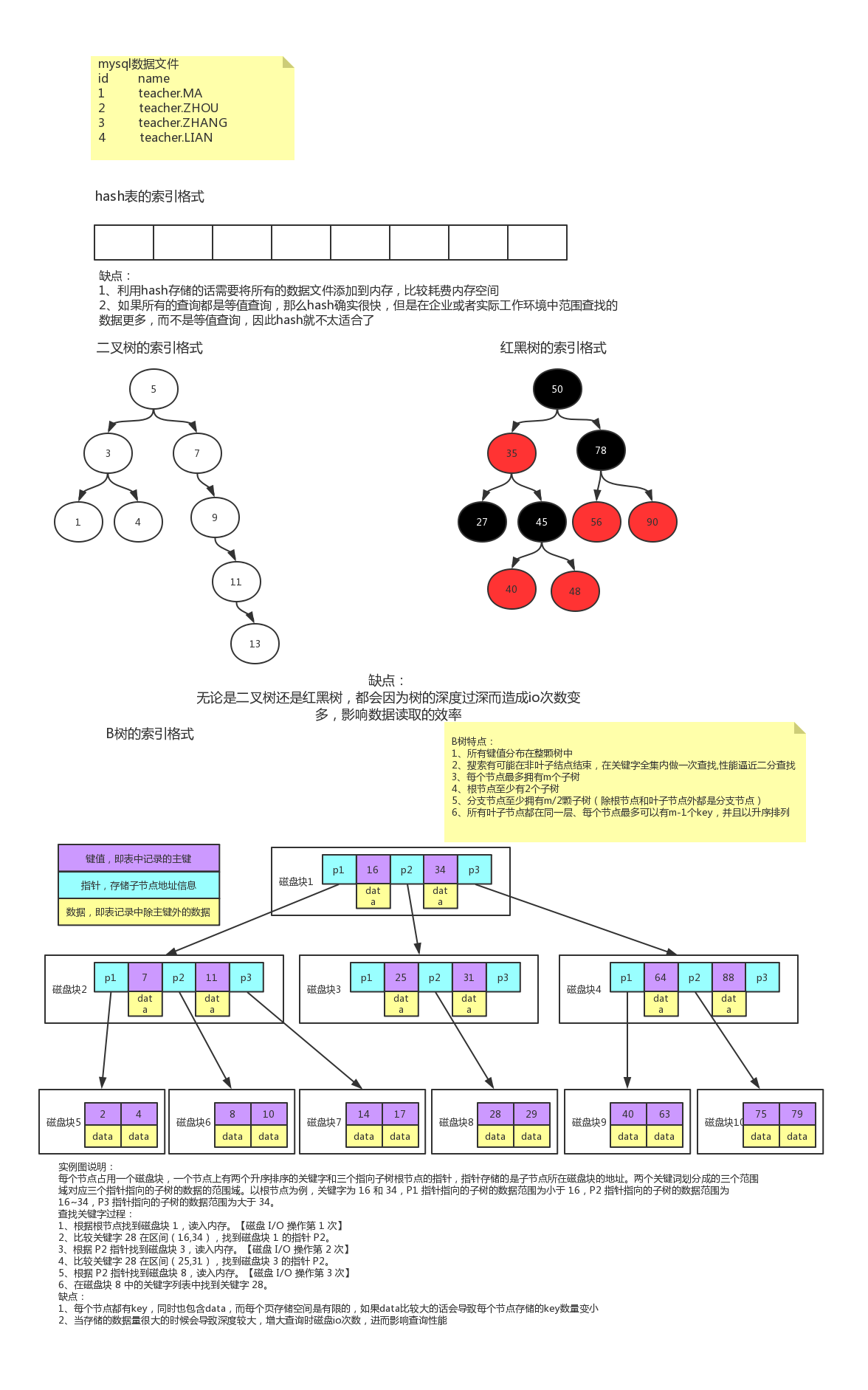
hash表的缺点:
1.用hash进行存储的话,需要将所有的数据文件添加到内存,很耗费内存
2.如果所有的查询都是等值查询(where name = XX), 那么hash表确实很快, 但是如果是范围查询的话,就不太合适了,数据越多越不行
mysql有一种存储引擎就是用hash的, 叫memory

若有收获,就点个赞吧
0 人点赞
