1.关键字解释
叉
根节点,非叶子节点,叶子节点,层级
如下图所示
其中节点A跟B 或者 节点1 2 3 4 或M 都叫做一个层级
查询速度
查询性能跟层级是成反比的, 查的层级越高,效率越低,不难理解
指针
树的发展史:
刚开始是二叉树, 二叉树的缺点就是不一定分叉,层级太深,它会进行排序, 又叫DOST树即二叉查找树
之后出现了二叉平衡树(AVL树,为什么是AVL.这个是其三个作者的简称), 即最长子树跟最短子树的高度差,不能超过1,而为了达到这种目的,它需要进行1-N次的旋转来达到平衡,而这个旋转的过程是比较浪费时间跟性能的(其插入跟删除就比较慢) 于是又出现了红黑二叉树, 它的好处就是用变色来减少旋转的次数,进而提效率,它要求1.最长子树只要不超过最短子树的两倍即可, 2.任何一个单分支上不许出现两个连续的红色节点, 3.根节点到任何叶子节点所经过的黑节点数是一致的,这样能提高一定的插入效率,但是会损失一定的查询效率
但不管你是红黑树 还是AVL二叉树都会很容易造成几点过深,节点越深,访问IO的次数就越多,影响读取效率,其主要原因就是你只分了两个叉 
2.平衡二叉树
定义:是基于二分法策略来提升数据查询速度的一种数据结构,特点就是二叉
特点:
1:一个节点下面只允许有两个子节点
2:节点的子节点左边小于该节点, 右边的子节点大于该节点
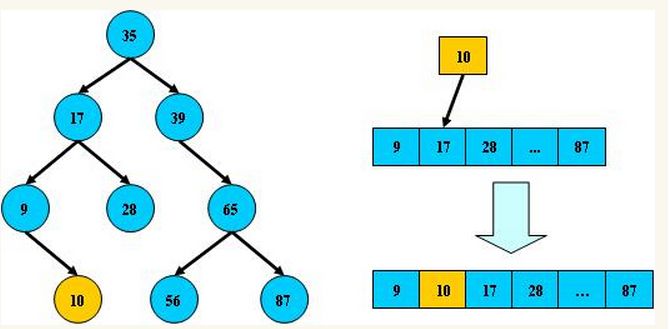
查询过程跟二分法差不多, 不断的比较子节点来定位数据的位置
总结
(1)非叶子节点最多拥有两个子节点;
(2)非叶子节值大于左边子节点、小于右边子节点;
(3)树的左右两边的层级数相差不会大于1;
(4)没有值相等重复的节点;
二叉树的时间复杂度为: O(logn)
3.b树
b树跟平衡二叉树的区别就是b树是多叉的, 又叫做平衡多路查找树
如今主流的数据库基本上都是用b树或者b+树, mysql就是b+树
b树的特点
1.从左到右增序排列
2.子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
3.关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
4.所以的叶子节点都在同一层,叶子节点有关机字及关键字记录对应的指针,同时还有一个指向其子节点的指针,只不过指向为null
b树的时间复杂度为 O(logm底n指数)
最后我们用一个图和一个实际的例子来理解B树(这里为了理解方便我就直接用实际字母的大小来排列C>B>A)图中叶子节点下面的空白格就是指向子节点的空指针
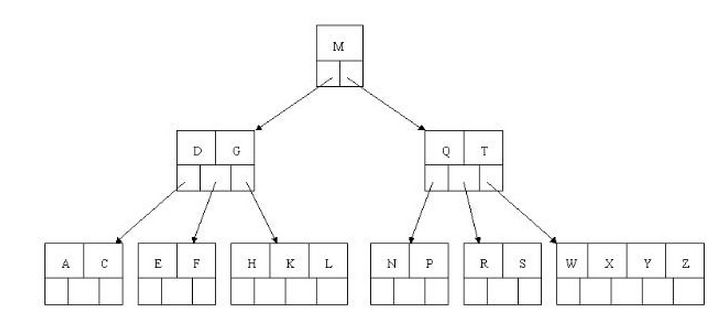
B树的查询流程:
比如我们想查E
step1 先跟根节点M相比, 小于M 往左边的子节点走(跟二分法一样)
step2 走到D跟G 因为D
**
B树的插入节点流程
定义一个5阶树(平衡5路查找树;),现在我们要把3、8、31、11、23、29、50、28 这些数字构建出一个5阶树出来;
遵循规则:
(1)节点拆分规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须<=5-1(这里关键字数>4就要进行节点拆分);
(2)排序规则:满足节点本身比左边节点大,比右边节点小的排序规则;
先插入 3、8、31、11
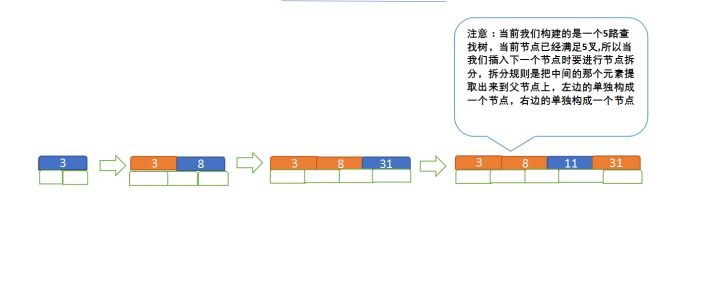
再插入23、29 因为达到大于关键字数了,取中间节点,左边右边节点依次变为子节点
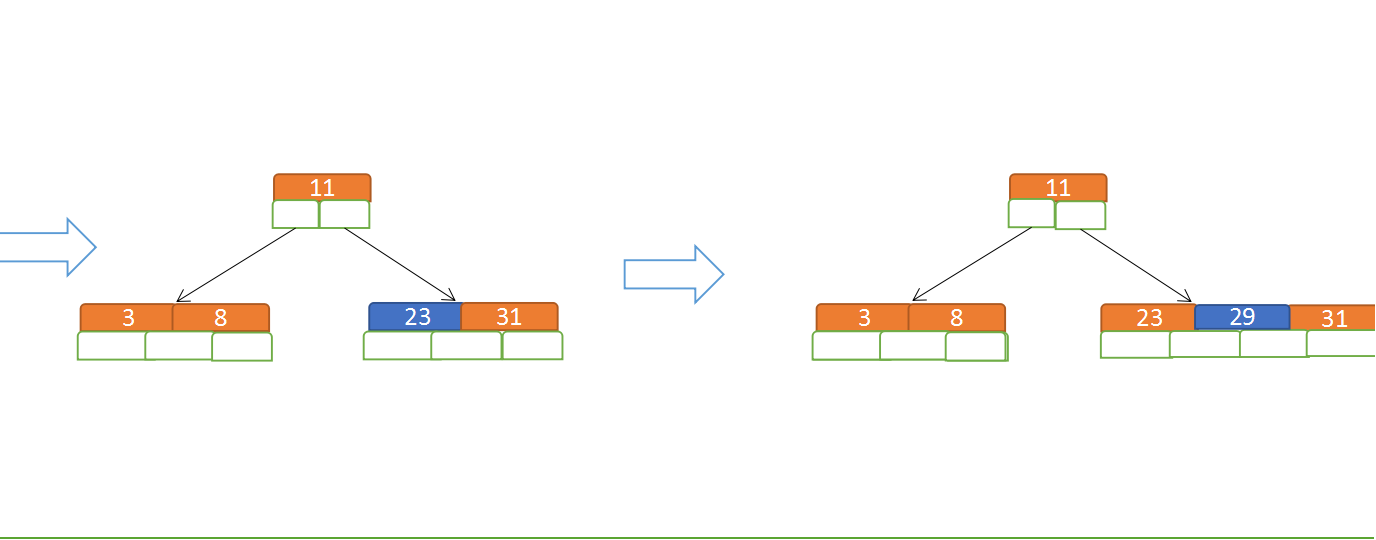
再插入50、28
插到28时 满足了拆分条件,29被拆出,拆出的节点跳到非叶子节点处

B树节点的删除
规则:
(1)节点合并规则:当前是要组成一个5路查找树,那么此时m=5,关键字数必须大于等于ceil(5/2)(这里关键字数<2就要进行节点合并);
(2)满足节点本身比左边节点大,比右边节点小的排序规则;
(3)关键字数小于二时先从子节点取,子节点没有符合条件时就向向父节点取,取中间值往父节点放;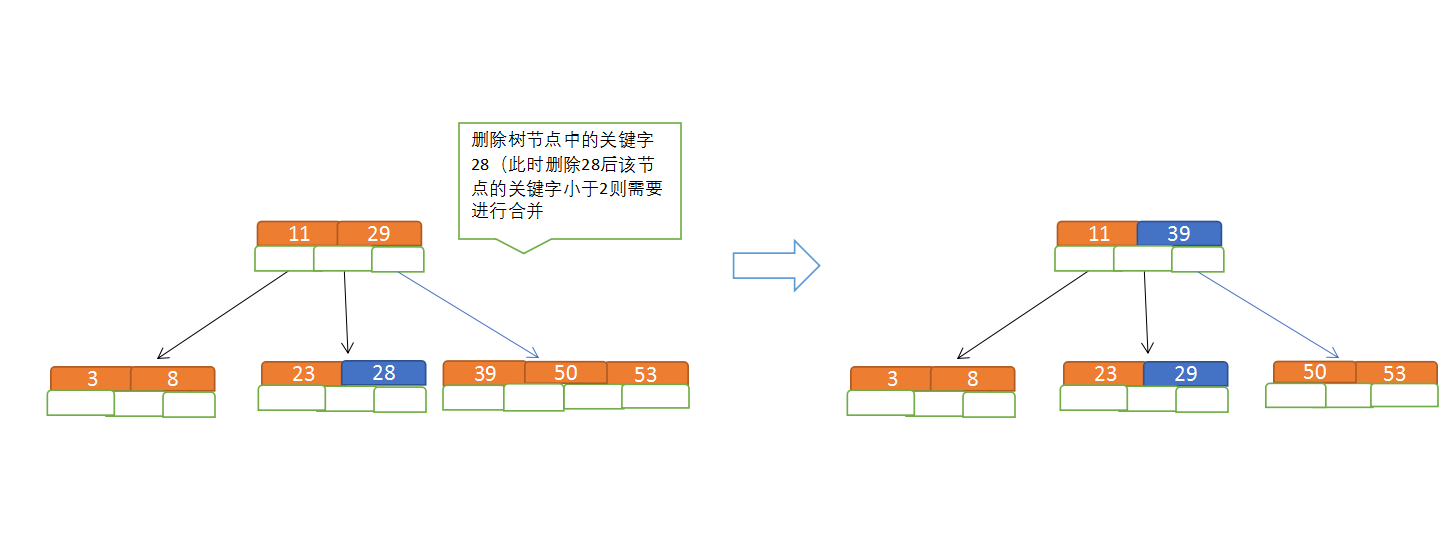
从这你大概可以看出, 不论时增节点还是减节点 只要触发了节点的拆分, 就会跳到非叶子节点上,s型的,即减节点从父节点拿,而不是从兄弟节点拿, 增加节点也是往父节点增不是往子节点增
特点:
相比于平衡二叉树, b树的分叉更多,这样使得每个节点的关键字增多了(二叉树的关键字就两个),特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度;
4.b+树
b+树跟b树的区别就是, 非叶子节点不再存储指向关键字属性的指针,而只保存节点的索引,这样就使非叶子节点能存储更多的索引,相比与b树 ,它的查询效率更稳定,更高
- 规则
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
- 特点
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
3、、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
5.b*树
B树是B+树的变种,相对于B+树他们的不同之处如下:
(1)首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b树的初始化个数为(cei(2/3m))
(2)B+树节点满时就会分裂,而B树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来;
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树额分解次数变得更少;

6.红黑树
优点:
相比于avl(二叉平衡树), 红黑树并不追求完全平衡,而是部分平衡(黑色平衡),这样达到平衡要比avl树来的更方便一些,同时查询效率,时间复杂度跟avl又没什么区别
https://www.jianshu.com/p/e136ec79235c
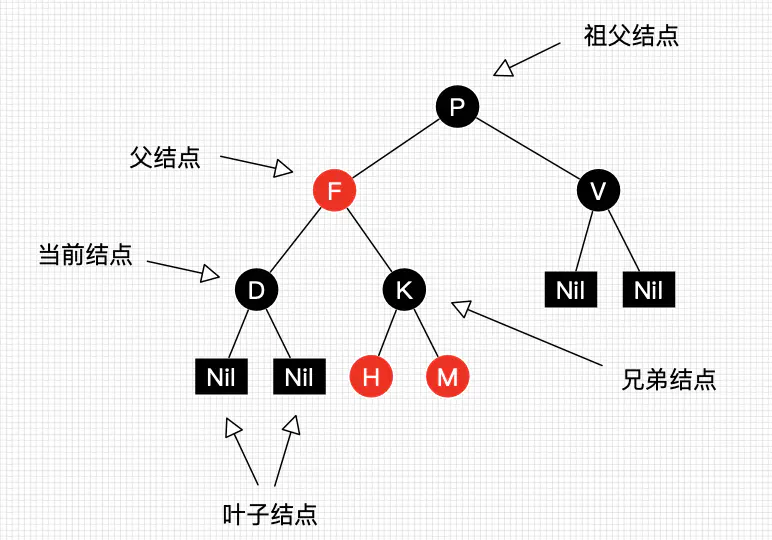
红黑树也是一种二叉平衡查找树, 只是他不是完美平衡二叉树,而是完美黑树
- 性质1:每个节点要么是黑色,要么是红色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NIL)是黑色。
- 性质4:每个红色结点的两个子结点一定都是黑色。
- 性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
**
红黑树通过左旋,右旋跟变色来实现黑子的自平衡
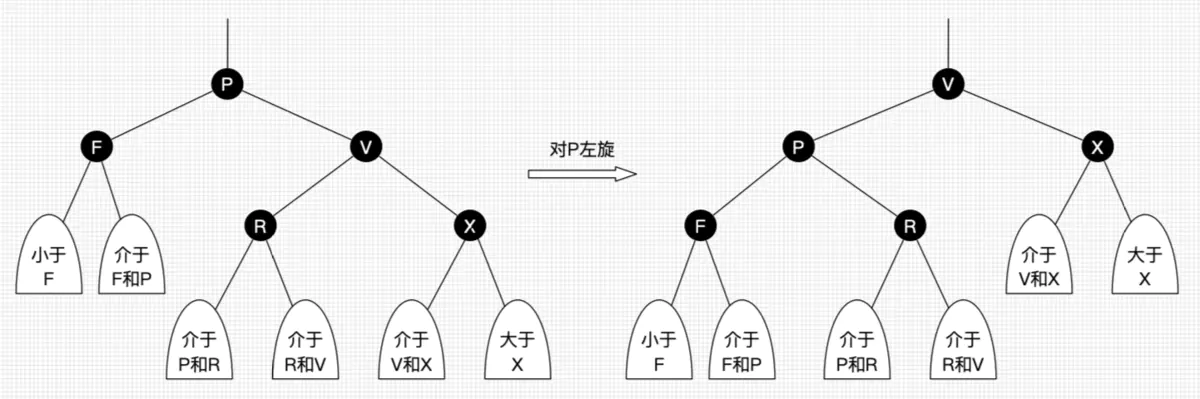
前面讲到红黑树能自平衡,它靠的是什么?三种操作:左旋、右旋和变色。
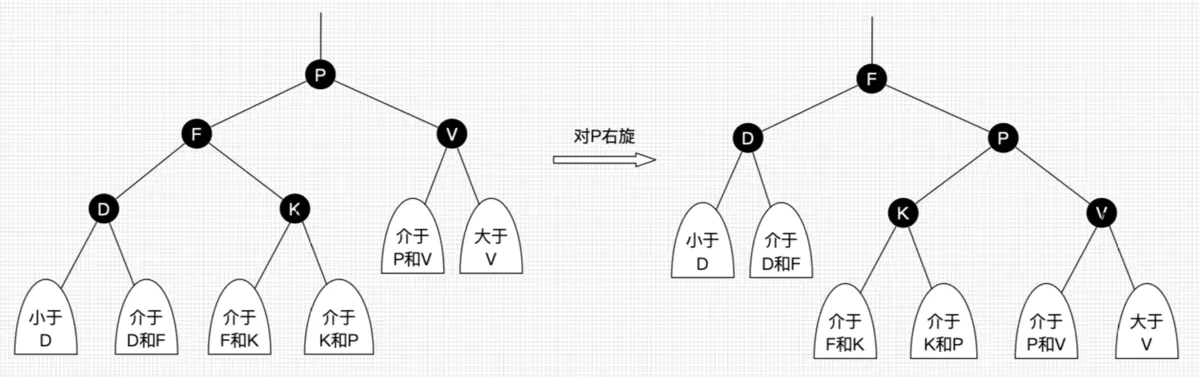
- 左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。如图3。
- 右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变。如图4。
- 变色:结点的颜色由红变黑或由黑变红。
查找
红黑树的查找过程比较简单,就跟正常的二叉树的查询过程一致
比较复杂的就是插入数据跟删除数据,为了满足黑色平衡,会进行很多次的左右旋跟变色
所有的插入情形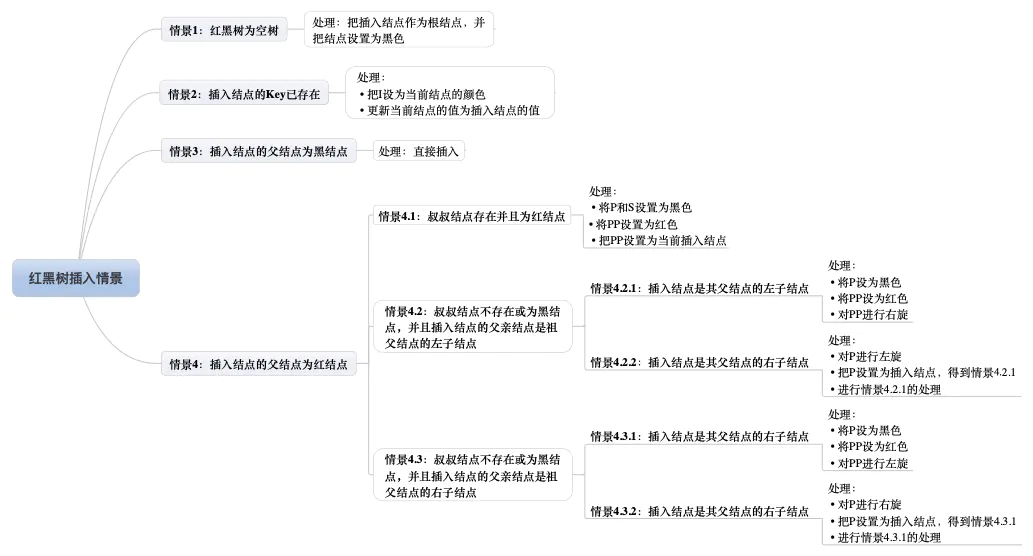
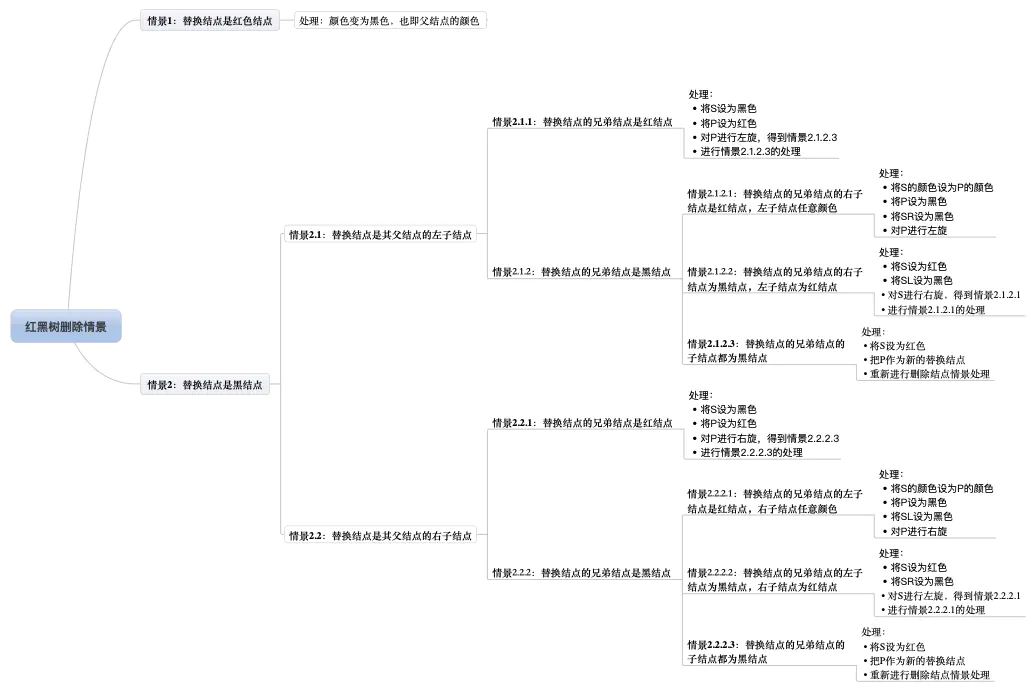
所有的删除情形
红黑树跟B树的区别
差别有些大。红黑树是二叉树的变种, b树一个节点代表数据的集合或者范围。从应用看,红黑树适合小数据范围内的快速查找(比如map当量的容器)。b树适合大范围数据查找(db场合)
7.时间复杂度
https://blog.csdn.net/qq_41523096/article/details/82142747
衡量代码好坏的非常重要的两个指标是 :1.运行时间 2.占用空间
T(n) 为基本执行时间数, 当n趋近无穷大时,存在函数f(n) 使得T(n)/f(n) 不为0时,称作f(n)为T(n)的同量级函数
T(n)=O(f(n)) 我们称O(f(n))为算法的渐进时间复杂度,简称时间复杂度
如何推导出时间复杂度呢?有如下几个原则:
- 如果运行时间是常数量级,用常数1表示;例如 T(n) = 2 , 就说明其时间复杂度为 O(1)
- 只保留时间函数中的最高阶项;T(n) = 5n^2+5n 它的复杂度为 O(n^2)
- 如果最高阶项存在,则省去最高阶项前面的系数。T(n) = 3n 的时间复杂度为 O(n)
然后通过比较时间复杂度, 就可以来判断执行时间了
算法A的相对时间规模是T(n)= 100n,时间复杂度是O(n)
算法B的相对时间规模是T(n)= 5n^2,时间复杂度是O(n^2)
算法A运行在小灰家里的老旧电脑上,算法B运行在某台超级计算机上,运行速度是老旧电脑的100倍。
那么,随着输入规模 n 的增长,两种算法谁运行更快呢?
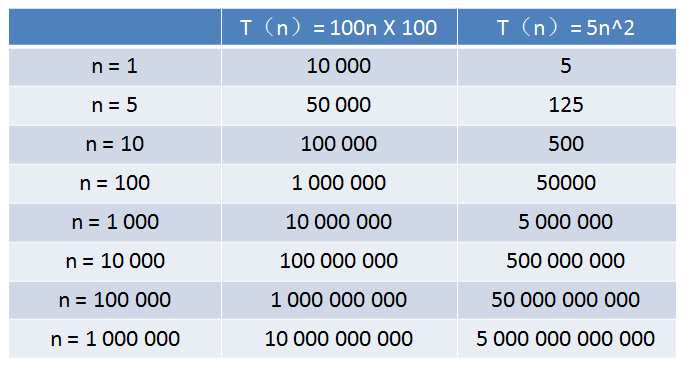
从表格中可以看出,当n的值很小的时候,算法A的运行用时要远大于算法B;当n的值达到1000左右,算法A和算法B的运行时间已经接近;当n的值越来越大,达到十万、百万时,算法A的优势开始显现,算法B则越来越慢,差距越来越明显。
8.应用场景:
红黑树适用于数据量小的场景, 像jdk1.8里的hashMap用的就是红黑树, treeMap也是用的红黑树, 他相比于avl平衡二叉树来说,能更快的达到平衡
而B树B加树之类都是针对磁盘的结构来设计的, 这样读取磁盘中的数据能更快一些, 适用于数据量比较大的场景
9.左旋跟右旋

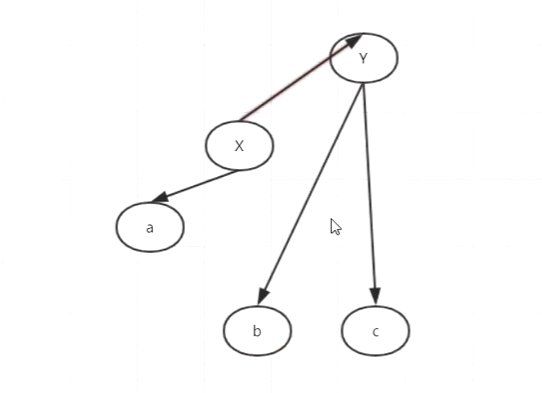

上面的就是左旋
10.B+树比B树牛逼在哪?
B树的树枝节点存的东西太多了 ,既有主键,又有子节点的地址信息,还有除主键外的表数据, 正常硬盘的一个页是4K, innodb引擎一次预加载16K,假如树的层级均为3 , 每一个层级都是访问一次IO, 那么你拿到数据假如说是访问到最底层 那就需要访问3次IO, 三次访问能存储的存储量就是 16K除你每个数据占用的空(主键+子节点地址+除主键外的表信息)的结果的3次方, 存不了太多的数据, 而B+树是 它的树枝节点只保存索引, 这样16K能存的数据就大大的提升,1K是1024个字节,而索引保存占用的地址很小, 相当于10241616*16, 三层就能达到千万级别的存储量,层级少io次数就少, 查的就快
date是很占用空间的
11.为什么数据库用B+树不用B*树
因为b+树就能满足mysql的查询,而B*树是在树枝节点中也连接了相邻的兄弟节点,,随mysql来说没啥用
查找过程是怎样的 内存调用b+树->根据区间定位到索引将索引从硬盘扫描到内存中->然后拿到下一个叶子节点/树枝节点->再去硬盘里捞 这样操作下去

若有收获,就点个赞吧
0 人点赞
