没过几天,小白就完成了博客的开发并将其部署上线。之后的一段时间,小白又使用 Redis 开发了几个程序,用得还算顺手,便没有继续向宋老师请教 Redis 的更多知识。直到一个月后的一天,宋老师偶然访问了小白的博客。
本章将会带领读者继续探索 Redis,了解 Redis 的事务、排序与管道等功能,并且还会详细地介绍如何优化 Redis 的存储空间。
4.1 事务
傍晚时候,忙完了一天的教学工作,宋老师坐在办公室的电脑前开始为明天的课程做准备。尽管有着近5年的教学经验,可是宋老师依然习惯在备课时写一份简单的教案。正在网上查找资料时,在浏览器的历史记录里他突然看到了小白的博客。心想:不知道他的博客怎么样了?
于是宋老师点进了小白的博客,页面刚载入完他就被博客最下面的一行大得夸张的文字吸引了:“Powered by Redis”。宋老师笑了笑,接着就看到了小白博客中最新的一篇文章:
标题:使用 Redis 来存储微博中的用户关系
正文:在微博中,用户之间是“关注”和“被关注”的关系。如果要使用 Redis 存储这样的关系可以使用集合类型。思路是对每个用户使用两个集合类型键,分别名为“user:用户ID:followers”和“user:用户ID:following”,用来存储关注该用户的用户集合和该用户关注的用户集合。
def follow($currentUser, $targetUser)SADD user:$currentUser:following, $targetUserSADD user:$targetUser:followers, $currentUser
如 ID 为1的用户A想关注 ID 为2的用户B,只需要执行 follow(1, 2)即可。然而在实现该功能的时候我发现了一个问题:完成关注操作需要依次执行两条 Redis 命令,如果在第一条命令执行完后因为某种原因导致第二条命令没有执行,就会出现一个奇怪的现象:A查看自己关注的用户列表时会发现其中有B,而B查看关注自己的用户列表时却没有A,换句话说就是,A虽然关注了B,却不是B的粉丝。真糟糕,A和B都会对这个网站失望的!但愿不会出现这种情况。
宋老师看到此处,笑得合不拢嘴,把备课的事抛到了脑后。心想:“看来有必要给小白传授一些进阶的知识。”他给小白写了封电子邮件:其实可以使用 Redis 的事务来解决这一问题。
4.1.1 概述
Redis 中的事务(transaction)是一组命令的集合。事务同命令一样都是 Redis 的最小执行单位,一个事务中的命令要么都执行,要么都不执行。事务的应用非常普遍,如银行转账过程中A给B汇款,首先系统从A的账户中将钱划走,然后向B的账户增加相应的金额。这两个步骤必须属于同一个事务,要么全执行,要么全不执行。否则只执行第一步,钱就凭空消失了,这显然让人无法接受。事务的原理是先将属于一个事务的命令发送给 Redis,然后再让 Redis 依次执行这些命令。例如:
redis> MULTIOKredis> SADD "user:1:following" 2QUEUEDredis> SADD "user:2:followers" 1QUEUEDredis> EXEC1) (integer) 12) (integer) 1
上面的代码演示了事务的使用方式。首先使用 MULTI 命令告诉 Redis:“下面我发给你的命令属于同一个事务,你先不要执行,而是把它们暂时存起来。”Redis回答:“OK。” 而后我们发送了两个 SADD 命令来实现关注和被关注操作,可以看到 Redis 遵守了承诺,没有执行这些命令,而是返回 QUEUED 表示这两条命令已经进入等待执行的事务队列中了。
当把所有要在同一个事务中执行的命令都发给 Redis 后,我们使用 EXEC 命令告诉 Redis 将等待执行的事务队列中的所有命令(即刚才所有返回 QUEUED 的命令)按照发送顺序依次执行。EXEC 命令的返回值就是这些命令的返回值组成的列表,返回值顺序和命令的顺序相同。
Redis 保证一个事务中的所有命令要么都执行,要么都不执行。如果在发送 EXEC 命令前客户端断线了,则 Redis 会清空事务队列,事务中的所有命令都不会执行。而一旦客户端发送了 EXEC 命令,所有的命令就都会被执行,即使此后客户端断线也没关系,因为 Redis 中已经记录了所有要执行的命令。
除此之外,Redis 的事务还能保证一个事务内的命令依次执行而不被其他命令插入。试想客户端A需要执行几条命令,同时客户端B发送了一条命令,如果不使用事务,则客户端B的命令可能会插入到客户端A的几条命令中执行。如果不希望发生这种情况,也可以使用事务。
4.1.2 错误处理
有些读者会有疑问,如果一个事务中的某个命令执行出错,Redis 会怎样处理呢?要回答这个问题,首先需要知道什么原因会导致命令执行出错。
1.语法错误。
语法错误指命令不存在或者命令参数的个数不对。比如:
redis> MULTIOKredis> SET key valueQUEUEDredis> SET key(error) ERR wrong number of arguments for 'set' commandredis> ERRORCOMMAND key(error) ERR unknown command 'ERRORCOMMAND'redis> EXEC(error) EXECABORT Transaction discarded because of previous errors.
跟在 MULTI 命令后执行了3个命令:一个是正确的命令,成功地加入事务队列;其余两个命令都有语法错误。而只要有一个命令有语法错误,执行 EXEC 命令后 Redis 就会直接返回错误,连语法正确的命令也不会执行。
版本差异 Redis 2.6.5 之前的版本会忽略有语法错误的命令,然后执行事务中其他语法正确的命令。就此例而言,SET key value 会被执行,EXEC 命令会返回一个结果:1) OK
2.运行错误。
运行错误指在命令执行时出现的错误,比如使用散列类型的命令操作集合类型的键,这种错误在实际执行之前 Redis 是无法发现的,所以在事务里这样的命令是会被 Redis 接受并执行的。如果事务里的一条命令出现了运行错误,事务里其他的命令依然会继续执行(包括出错命令之后的命令),示例如下:
redis> MULTI OKredis> SET key 1 QUEUEDredis> SADD key 2 QUEUEDredis> SET key 3 QUEUEDredis> EXEC1) OK2) (error) WRONGTYPE Operation against a key holding the wrong kind of value 3) OKredis> GET key"3"
可见虽然 SADD key 2 出现了错误,但是 SET key 3 依然执行了。Redis 的事务没有关系数据库事务提供的回滚(rollback)[1] 功能。为此开发者必须在事务执行出错后自己收拾剩下的摊子(将数据库复原回事务执行前的状态等)。
不过由于 Redis 不支持回滚功能,也使得 Redis 在事务上可以保持简洁和快速。另外回顾刚才提到的会导致事务执行失败的两种错误,其中语法错误完全可以在开发时找出并解决,另外如果能够很好地规划数据库(保证键名规范等)的使用,是不会出现如命令与数据类型不匹配这样的运行错误的。
4.1.3 WATCH 命令介绍
我们已经知道在一个事务中只有当所有命令都依次执行完后才能得到每个结果的返回值,可是有些情况下需要先获得一条命令的返回值,然后再根据这个值执行下一条命令。例如介绍 INCR 命令时曾经说过使用 GET 和 SET命令自己实现 incr 函数会出现竞态条件,伪代码如下:
def incr($key)$value = GET $keyif not $value$value = 0$value = $value + 1SET $key, $valuereturn $value
肯定会有很多读者想到可以用事务来实现 incr 函数以防止竞态条件,可是因为事务中的每个命令的执行结果都是最后一起返回的,所以无法将前一条命令的结果作为下一条命令的参数,即在执行 SET 命令时无法获得GET 命令的返回值,也就无法做到增1的功能了。
为了解决这个问题,我们需要换一种思路。即在 GET 获得键值后保证该键值不被其他客户端修改,直到函数执行完成后才允许其他客户端修改该键键值,这样也可以防止竞态条件。要实现这一思路需要请出事务家族的另一位成员:WATCH。WATCH 命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。监控一直持续到 EXEC 命令(事务中的命令是在 EXEC 之后才执行的,所以在 MULTI 命令后可以修改 WATCH 监控的键值),如:
redis> SET key 1OKredis> WATCH keyOKredis> SET key 2OKredis> MULTIOKredis> SET key 3QUEUEDredis> EXEC(nil)redis> GET key"2"
上例中在执行 WATCH 命令后、事务执行前修改了 key 的值(即 SET key 2),所以最后事务中的命令 SET key 3 没有执行,EXEC 命令返回空结果。 学会了 WATCH 命令就可以通过事务自己实现 incr 函数了,伪代码如下:
def incr($key)WATCH $key$value = GET $keyif not $value$value = 0$value = $value + 1MULTISET $key, $valueresult = EXECreturn result[0]
因为 EXEC 命令返回值是多行字符串类型,所以代码中使用 result[0] 来获得其中第一个结果。
提示 由于 WATCH 命令的作用只是当被监控的键值被修改后阻止之后一个事务的执行, 而不能保证其他客户端不修改这一键值,所以我们需要在 EXEC 执行失败后重新执行整个函数。
执行 EXEC 命令后会取消对所有键的监控,如果不想执行事务中的命令也可以使用 UNWATCH 命令来取消监控。比如,我们要实现 hsetxx 函数,作用与 HSETNX 命令类似,只不过是仅当字段存在时才赋值。为了避免竞态条件我们使用事务来完成这一功能:
def hsetxx($key, $field, $value)WATCH $key$isFieldExists = HEXISTS $key, $fieldif $isFieldExists is 1MULTIHSET $key, $field, $valueEXECelseUNWATCHreturn $isFieldExists
在代码中会判断要赋值的字段是否存在,如果字段不存在的话就不执行事务中的命令, 但需要使用 UNWATCH 命令来保证下一个事务的执行不会受到影响。
4.2 过期时间
转天早上宋老师就收到了小白的回信,内容基本上都是一些表示感谢的话。宋老师又看了一下小白发的那篇文章,发现他已经在文末补充了使用事务来解决竞态条件的方法。宋老师单击了评论链接想发表评论,却看到博客出现了错误“请求超时”(Request timeout)。宋老师疑惑了一下,准备稍后再访问看看,就接着忙别的事情了。 没过一会儿,宋老师就收到了一封小白发来的邮件:
宋老师您好!我的博客最近经常无法访问,我看了日志后发现是因为某个搜索引擎爬虫访问得太频繁,加上本来我的服务器性能就不太好,很容易资源就被占满了。请问有没有方法可以限定每个IP地址每分钟最大的访问次数呢?
宋老师这才明白为什么刚才小白的博客请求超时了,于是放下了手头的事情开始继续给小白介绍 Redis 的更多功能。
4.2.1 命令介绍
在实际的开发中经常会遇到一些有时效的数据,比如限时优惠活动、缓存或验证码等, 过了一定的时间就需要删除这些数据。在关系数据库中一般需要额外的一个字段记录到期时间,然后定期检测删除过期数据。而在Redis 中可以使用 EXPIRE命令设置一个键的过期时间,到时间后 Redis 会自动删除它。
EXPIRE命令的使用方法为:
EXPIRE key seconds
其中 seconds 参数表示键的过期时间,单位是秒。如要想让 session:29e3d 键在15分钟后被删除:
redis> SET session:29e3d uid1314OKredis> EXPIRE session:29e3d 900(integer) 1
EXPIRE命令返回1表示设置成功,返回0则表示键不存在或设置失败。例如:
redis> DEL session:29e3d(integer) 1redis> EXPIRE session:29e3d 900(integer) 0
如果想知道一个键还有多久的时间会被删除,可以使用 TTL 命令。返回值是键的剩余时间(单位是秒):
redis> SET foo barOKredis> EXPIRE foo 20(integer) 1redis> TTL foo (integer)15redis> TTL foo (integer)7redis> TTL foo (integer)–2
可见随着时间的不同,foo 键的过期时间逐渐减少,20 秒后 foo 键会被删除。当键不存在时 TTL 命令会返回 -2。那么没有为键设置过期时间(即永久存在,这是建立一个键后的默认情况)的情况下会返回什么呢?答案是返回 -1:
redis> SET persistKey valueOKredis> TTL persistKey(integer) -1
版本差异 在2.6版中,无论键不存在还是键没有过期时间都会返回 -1,直到2.8版后两种情况才会分别返回 -2 和 -1 两种结果。 如果想取消键的过期时间设置(即将键恢复成永久的),则可以使用 PERSIST 命令。如果过期时间被成功清除则返回1;否则返回0(因为键不存在或键本来就是永久的):
redis> SET foo barOKredis> EXPIRE foo 20(integer) 1redis> PERSIST foo(integer) 1redis> TTL foo (integer)-1除了 PERSIST 命令之外,使用 SET 或 GET SET 命令为键赋值也会同时清除键的过期时间,例如:
redis> EXPIRE foo 20(integer) 1redis> SET foo barOKredis> TTL foo(integer) -1使用EXPIRE命令会重新设置键的过期时间,就像这样:
redis> SET foo barOKredis> EXPIRE foo 20(integer) 1redis> TTL foo(integer) 15redis> EXPIRE foo 20(integer) 1redis> TTL foo(integer) 17其他只对键值进行操作的命令(如 INCR、LPUSH、HSET、ZREM)均不会影响键的过期时间。EXPIRE 命令的seconds 参数必须是整数,所以最小单位是1秒。如果想要更精确的控制键的过期时间应该使用 PEXPIRE 命
位是毫秒,即 PEXPIRE key 1000 与 EXPIRE key 1 等价。对应地可以用 PTTL 命令以毫秒为单位返回键的剩余时间。 提示 如果使用 WATCH 命令监测了一个拥有过期时间的键,该键时间到期自动删除并不会被 WATCH 命令认为该键被改变。
另外还有两个相对不太常用的命令:EXPIREAT 和 PEXPIREAT。
EXPIREAT 命令与 EXPIRE 命令的差别在于前者使用 Unix 时间作为第二个参数表示键的过期时刻。PEXPIREAT 命令与 EXPIREAT 命令的区别是前者的时间单位是毫秒。如:
redis> SET foo barOKredis> EXPIREAT foo 1351858600(integer) 1redis> TTL foo(integer) 142redis> PEXPIREAT foo 1351858700000(integer) 1
4.2.2 实现访问频率限制之一
回到小白的问题,为了减轻服务器的压力,需要限制每个用户(以IP计)一段时间的最大访问量。与时间有关的操作很容易想到 EXPIRE 命令。
例如要限制每分钟每个用户最多只能访问100个页面,思路是对每个用户使用一个名为 rate.limiting:用户IP 的字符串类型键,每次用户访问则使用 INCR 命令递增该键的键值,如果递增后的值是1(第一次访问页面),则同时还要设置该键的过期时间为1分钟。这样每次用户访问页面时都读取该键的键值,如果超过了100就表明该用户的访问频率超过了限制,需要提示用户稍后访问。该键每分钟会自动被删除,所以下一分钟用户的访问次数又会重新计算,也就达到了限制访问频率的目的。
上述流程的伪代码如下:
$isKeyExists = EXISTS rate.limiting:$IPif $isKeyExists is 1$times = INCR rate.limiting:$IPif $times > 100print 访问频率超过了限制,请稍后再试exitelseINCR rate.limiting:$IPEXPIRE $keyName, 60
这段代码存在一个不太明显的问题:假如程序执行完倒数第二行后突然因为某种原因退出了,没能够为该键设置过期时间,那么该键会永久存在,导致使用对应的IP的用户在管理员手动删除该键前最多只能访问100次博客,这是一个很严重的问题。
为了保证建立键和为键设置过期时间一起执行,可以使用上节学习的事务功能,修改后的代码如下:
$isKeyExists = EXISTS rate.limiting:$IPif $isKeyExists is 1$times = INCR rate.limiting:$IPif $times > 100print 访问频率超过了限制,请稍后再试exitelseMULTIINCR rate.limiting:$IPEXPIRE $keyName, 60EXEC
4.2.3 实现访问频率限制之二
事实上,4.2.2节中的代码仍然有个问题:如果一个用户在一分钟的第一秒访问了一次博 客,在同一分钟的最后一秒访问了9次,又在下一分钟的第一秒访问了10次,这样的访问是可以通过现在的访问频率限制的,但实际上该用户在2秒内访问了19次博客,这与每个用户每分钟只能访问10次的限制差距较大。尽管这种情况比较极端,但是在一些场合中还是需要粒度更小的控制方案。如果要精确地保证每分钟最多访问10次,需要记录下用户每次访问的时间。因此对每个用户,我们使用一个列表类型的键来记录他最近10次访问博客的时间。一旦键中的元素超过 10 个,就判断时间最早的元素距现在的时间是否小于1分钟。如果是则表示用户最近1分钟的访问次数超过了10次;如果不是就将现在的时间加入到列表中,同时把最早的元素删除。
上述流程的伪代码如下:
$listLength = LLEN rate.limiting:$IPif $listLength < 10LPUSH rate.limiting:$IP, now()else$time = LINDEX rate.limiting:$IP, -1if now() - $time < 60print 访问频率超过了限制,请稍后再试elseLPUSH rate.limiting:$IP, now()LTRIM rate.limiting:$IP, 0, 9
代码中 now() 的功能是获得当前的 Unix 时间。由于需要记录每次访问的时间,所以当要限制“A时间最多访问B次”时,如果“B”的数值较大,此方法会占用较多的存储空间,实际使用时还需要开发者自己去权衡。除此之外该方法也会出现竞态条件,同样可以通过脚本功能避免,具体在第6章会介绍到。
4.2.4 实现缓存
为了提高网站的负载能力,常常需要将一些访问频率较高但是对 CPU 或 IO 资源消耗较大的操作的结果缓存起来,并希望让这些缓存过一段时间自动过期。比如教务网站要对全校所有学生的各个科目的成绩汇总排名,并在首页上显示前10名的学生姓名,由于计算过程较耗资源,所以可以将结果使用一个 Redis 的字符串键缓存起来。由于学生成绩总在不断地变化,需要每隔两个小时就重新计算一次排名,这可以通过给键设置过期时间的方式实现。每次用户访问首页时程序先查询缓存键是否存在,如果存在则直接使用缓存的值;否则重新计 算排名并将计算结果赋值给该键并同时设置该键的过期时间为两个小时。伪代码如下:
$rank= GET cache:rankif not $rank$rank = 计算排名...MUlTISET cache:rank, $rankEXPIRE cache:rank, 7200EXEC
然而在一些场合中这种方法并不能满足需要。当服务器内存有限时,如果大量地使用缓存键且过期时间设置得过长就会导致 Redis 占满内存;另一方面如果为了防止 Redis 占用内存过大而将缓存键的过期时间设得太短,就可能导致缓存命中率过低并且大量内存白白地闲置。实际开发中会发现很难为缓存键设置合理的过期时间,为此可以限制 Redis 能够使用的最大内存,并让 Redis 按照一定的规则淘汰不需要的缓存键,这种方式在只将 Redis 用作缓存系统时非常实用。
具体的设置方法为:修改配置文件的 maxmemory 参数,限制 Redis 最大可用内存大小 (单位是字节),当超出了这个限制时 Redis 会依据 maxmemory-policy 参数指定的策略来删除不需要的键直到 Redis 占用的内存小于指定内存。
maxmemory-policy 支持的规则如表4-1所示。其中的 LRU(Least Recently Used)算法即“最近最少使用”,其认为最近最少使用的键在未来一段时间内也不会被用到,即当需要空间时这些键是可以被删除的。
表4-1 Redis 支持的淘汰键的规则
如当 maxmemory-policy 设置为 allkeys-lru 时,一旦 Redis 占用的内存超过了限制值,Redis 会不断地删除数据库中最近最少使用的键[2] ,直到占用的内存小于限制值。
4.3排序
午后,宋老师正在批改学生们提交的程序,再过几天就会迎来第一次计算机全市联考。他在每个学生的程序代码末尾都用注释详细地做了批注,严谨的治学态度让他备受学生们的爱戴。
一个电话打来。“小白的?”宋老师拿出手机,“博客最近怎么样了?”未及小白开口,他就抢先问道。
“特别好!现在平均每天都有50多人访问我的博客。不过昨天我收到一个访客的邮件,他向我反映了一个问题:查看一个标签下的文章列表时文章不是按照时间顺序排列的,找起来很麻烦。我看了一下代码,发现程序中是使用 SMEMBERS 命令获取标签下的文章列表,因为集合类型是无序的,所以不能实现按照文章的发布时间排列。我考虑过使用有序集合类型存储标签,但是有序集合类型的集合操作不如集合类型强大。您有什么好方法来解决这个问题吗?
方法有很多,我推荐使用 SORT 命令,你先挂了电话,我写好后发邮件给你吧。
4.3.1 有序集合的集合操作
集合类型提供了强大的集合操作命令,但是如果需要排序就要用到有序集合类型。Redis 的作者在设计 Redis 的命令时考虑到了不同数据类型的使用场景,对于不常用到的或者在不损失过多性能的前提下可以使用现有命令来实现的功能,Redis 就不会单独提供命令来实现。这一原则使得 Redis 在拥有强大功能的同时保持着相对精简的命令。
有序集合常见的使用场景是大数据排序,如游戏的玩家排行榜,所以很少会需要获得键中的全部数据。同样 Redis 认为开发者在做完交集、并集运算后不需要直接获得全部结果,而是会希望将结果存入新的键中以便后续处理。这解释了为什么有序集合只有 ZINTERSTORE 和 ZUNIONSTORE 命令而没有 ZINTER 和 ZUNION 命令。
当然实际使用中确实会遇到像小白那样需要直接获得集合运算结果的情况,除了等待 Redis 加入相关命令,我们还可以使用 MULTI, ZINTERSTORE, ZRANGE, DEL 和 EXEC这 5 个命令自己实现 ZINTER:
MULTIZINTERSTORE tempKey ...ZRANGE tempKey ...DEL tempKeyEXEC
4.3.2 SORT命令
除了使用有序集合外,我们还可以借助 Redis 提供的 SORT 命令来解决小白的问题。 SORT 命令可以对列表类型、集合类型和有序集合类型键进行排序,并且可以完成与关系数据库中的连接查询相类似的任务。小白的博客中标有“ruby ”标签的文章的ID分别是“2”、“6”、“12”和“26”。由于在集合类型中所有元素是无序的,所以使用 SMEMBERS 命令并不能获得有序的结果[3] 。为了能够让博客的标签页面下的文章也能按照发布的时间顺序排列(如果不考虑发布后再修改文章发布时间,就是按照文章ID的顺序排列),可以借助 SORT 命令实现,方法如下所示:
redis> SORT tag:ruby:posts1) "2"2) "6"3) "12"4) "26"
是不是十分简单?除了集合类型,SORT 命令还可以对列表类型和有序集合类型进行排序:
redis> LPUSH mylist 4 2 6 1 3 7(integer) 6redis> SORT mylist1) "1"2) "2"3) "3"4) "4"5) "6"6) "7"
在对有序集合类型排序时会忽略元素的分数,只针对元素自身的值进行排序。比如:
redis> ZADD myzset 50 2 40 3 20 1 60 5(integer) 4redis> SORT myzset1) "1"2) "2"3) "3"4) "5"
除了可以排列数字外,SORT 命令还可以通过 ALPHA 参数实现按照字典顺序排列非数字元素,就像这样:
redis> LPUSH mylistalpha a c e d B C A(integer) 7redis> SORT mylistalpha(error) ERR One or more scores can't be converted into doubleredis> SORT mylistalpha ALPHA1) "A"2) "B"3) "C"4) "a"5) "c"6) "d"7) "e"
从这段示例中可以看到如果没有加 ALPHA 参数的话,SORT 命令会尝试将所有元素转换成双精度浮点数来比较,如果无法转换则会提示错误。回到小白的问题,SORT 命令默认是按照从小到大的顺序排列,而一般博客中显示文章的顺序都是按照时间倒序的,即最新的文章显示在最前面。SORT 命令的 DESC 参数可以实现将元素按照从大到小的顺序排列:
redis> SORT tag:ruby:posts DESC1) "26"2) "12"3) "6"4) "2"
那么如果文章数量过多需要分页显示呢? SORT 命令还支持 LIMIT 参数来返回指定范围的结果。用法和 SQL 语句一样,LIMIT offset count,表示跳过前 offset 个元素并获取之后的 count个元素。SORT 命令的参数可以组合使用,像这样:
redis> SORT tag:ruby:posts DESC LIMIT 1 21) "12"2) "6"
4.3.3 BY参数
很多情况下列表(或集合、有序集合)中存储的元素值代表的是对象的 ID(如标签集合中存储的是文章对象的ID),单纯对这些ID自身排序有时意义并不大。更多的时候我们希望根据 ID 对应的对象的某个属性进行排序。回想3.6节,我们通过使用有序集合键来存储文章 ID 列表,使得小白的博客能够支持修改文章时间,所以文章 ID 的顺序和文章的发布时间的顺序并不完全一致,因此4.3.2节介绍的对文章 ID 本身排序就变得没有意义了。
小白的博客是使用散列类型键存储文章对象的,其中 time 字段存储的就是文章的发布时间。现在我们知道ID 为“2”、“6”、“12”和“26”的四篇文章的 time 字段的值分别为“1352619200”、“1352619600”、“1352620100”和“1352620000”(Unix时间)。如果要按照文章的发布时间递减排列结果应为“12”、“26”、“6”和“2”。为了获得这样的结果,需要使用 SORT命令的另一个强大的参数:BY。
BY 参数的语法:
BY 参考键
其中参考键可以是字符串类型键或者是散列类型键的某个字段(表示为键名->字段名)。如果提供了 BY 参数,SORT 命令将不再依据元素自身的值进行排序,而是对每个元素使用元素的值替换参考键中的第一个“*”并获取其值,然后依据该值对元素排序。就像这样:
redis> SORT tag:ruby:posts BY post:*->time DESC1) "12"2) "26"3) "6"4) "2"
在上例中SORT命令会读取post:2、post:6、post:12、post:26几个散列键中的 time 字段的值并以此决定 tag:ruby:posts 键中各个文章ID的顺序。除了散列类型之外,参考键还可以是字符串类型,比如:
redis> LPUSH sortbylist 2 1 3(integer) 3redis> SET itemscore:1 50 OKredis> SET itemscore:2 100OKredis> SET itemscore:3 -10OKredis> SORT sortbylist BY itemscore:* DESC1) "2"2) "1"3) "3"
当参考键名不包含“*”时(即常量键名,与元素值无关),SORT 命令将不会执行排序操作,因为 Redis 认为这种情况是没有意义的(因为所有要比较的值都一样)。例如:
redis> SORT sortby list BY any text1) "3"2) "1"3) "2"
例子中 any text 是常量键名(甚至 any text 键可以不存在),此时 SORT 的结果与 LRANGE 的结果相同,没有执行排序操作。在不需要排序但需要借助 SORT 命令获得与元素相关联的数据时(见4.3.4节),常量键名是很有用的。
如果几个元素的参考键值相同,则 SORT 命令会再比较元素本身的值来决定元素的顺序。像这样:
redis> LPUSH sortbylist 4(integer) 4redis> SET itemscore:4 50OKredis> SORT sortbylist BY itemscore:* DESC1) "2"2) "4"3) "1"4) "3"
示例中元素”4”的参考键 itemscore:4 的值和元素”1”的参考键 itemscore:1 的值都是50,所以 SORT 命令会再比较”4”和”1”元素本身的大小来决定二者的顺序。
当某个元素的参考键不存在时,会默认参考键的值为0:
redis> LPUSH sortbylist 5(integer) 5redis> SORT sortbylist BY itemscore:* DESC1) "2"2) "4"3) "1"4) "5"5) "3"
上例中”5”排在了”3”的前面,是因为”5”的参考键不存在,所以默认为 0,而”3”的参考键值为 -10。
补充知识 参考键虽然支持散列类型,但是“*”只能在“->”符号前面(即键名部分)才有用,在“->”后(即字段名部分)会被当成字段名本身而不会作为占位符被元素的值替换,即常量键名。但是实际运行时会发现一个有趣的结果:
redis> SORT sortbylist BY somekey->somefield:*1) "1"2) "2"3) "3"4) "4"5) "5"
上面提到了当参考键名是常量键名时 SORT 命令将不会执行排序操作,然而上例中却进行了排序,而且只是对元素本身进行排序。这是因为 Redis 判断参考键名是不是常量键名的方式是判断参考键名中是否包含“”,而 somekey->somefield: 中包含“”所以不是常量键名。所以在排序的时候Redis对每个元素都会读取键 somekey 中的 somefield: 字段(“*”不会被替换),无论能否获得其值,每个元素的参考键值是相同的,所以 Redis 会按照元素本身的 大小排列。
4.3.4 GET参数
现在小白的博客已经可以按照文章的发布顺序获得一个标签下的文章 ID 列表了,接下来要做的事就是对每个ID都使用 HGET 命令获取文章的标题以显示在博客列表页中。有没有觉得很麻烦?不论你的答案如何,都有一种更简单的方式来完成这个操作,那就是借助 SORT 命令的 GET 参数。
GET参数不影响排序,它的作用是使 SORT 命令的返回结果不再是元素自身的值,而是 GET 参数中指定的键值。GET 参数的规则和 BY 参数一样,GET 参数也支持字符串类型和散列类型的键,并使用“*”作为占位符。要实现在排序后直接返回ID对应的文章标题,可以这样写:
redis> SORT tag:ruby:posts BY post:*->time DESC GET post:*->title1) "Windows 8 app designs"2) "RethinkDB - An open-source distributed database built with love"3) "Uses for cURL"4) "The Nature of Ruby"
在一个 SORT 命令中可以有多个 GET 参数(而 BY 参数只能有一个),所以还可以这样用:
redis> SORT tag:ruby:posts BY post:*->time DESGET post:*->titleGET post:*->time1) "Windows 8 app designs"2) "1352620100"3) "RethinkDB - An open-source distributed database built with love"4) "1352620000"5) "Uses for cURL"6) "1352619600"7) "The Nature of Ruby"8) "1352619200"
可见有 N 个 GET 参数,每个元素返回的结果就有 N 行。这时有个问题:如果还需要返回文章 ID 该怎么办?答案是使用 GET #。就像这样:
redis> SORT tag:ruby:posts BY post:*->time DESCGET post:*->titleGET post:*->timeGET #1) "Windows 8 app designs"2) "1352620100"3) "12"4) "RethinkDB - An open-source distributed database built with love"5) "1352620000"6) "26"7) "Uses for cURL"8) "1352619600"9) "6"10) "The Nature of Ruby"11) "1352619200"12) "2"
4.3.5 STORE参数
默认情况下SORT会直接返回排序结果,如果希望保存排序结果,可以使用 STORE 参数。如希望把结果保存到 sort.result 键中:
redis> SORT tag:ruby:posts BY post:*->time DESCGET post:*->titleGET post:*->timeGET #STORE sort.result(integer) 12redis> LRANGE sort.result 0 -11) "Windows 8 app designs"2) "1352620100"3) "12"4) "RethinkDB - An open-source distributed database built with love"5) "1352620000"6) "26"7) "Uses for cURL"8) "1352619600"9) "6"10) "The Nature of Ruby"11) "1352619200"12) "2"
保存后的键的类型为列表类型,如果键已经存在则会覆盖它。加上 STORE 参数后 SORT 命令的返回值为结果的个数。 STORE 参数常用来结合 EXPIRE 命令缓存排序结果,如下面的伪代码:
# 判断是否存在之前排序结果的缓存$isCacheExists = EXISTS cache.sortif $isCacheExists is 1# 如果存在则直接返回return LRANGE cache.sort, 0, -1else# 如果不存在,则使用 SORT命令排序并将结果存入 cache.sort键中作为缓存$sortResult = SORT some.list STORE cache.sort# 设置缓存的过期时间为 10分钟EXPIRE cache.sort, 600# 返回排序结果return $sortResult
4.3.6 性能优化
SORT 是 Redis 中最强大最复杂的命令之一,如果使用不好很容易成为性能瓶颈。SORT 命令的时间复杂度是 O(n+mlog(m)),其中n表示要排序的列表(集合或有序集合)中的元素个数 , m表示要返回的元素个数。当n较大的时候SORT命令的性能相对较低,并且 Redis 在排序前会建立一个长度为n[4]的容器来存储待排序的元素,虽然是一个临时的过程,但如果同时进行较多的大数据量排序操作则会严重影响性能。
所以开发中使用SORT命令时需要注意以下几点。
- 尽可能减少待排序键中元素的数量(使N尽可能小)。
- 使用LIMIT参数只获取需要的数据(使M尽可能小)。
- 如果要排序的数据数量较大,尽可能使用STORE参数将结果缓存。
4.4 消息通知
凭着小白的用心经营,博客的访问量逐渐增多,甚至有了小白自己的粉丝。这不,小白 刚收到一封来自粉丝的邮件,在邮件中那个粉丝强烈建议小白给博客加入邮件订阅功能,这样当小白发布新文章后订阅小白博客的用户就可以收到通知邮件了。在信的末尾,那个粉丝还着重强调了一下:“这个功能对不习惯使用 RSS 的用户很重要,希望能够加上!”
看过信后,小白心想:“是个好建议!不过话说回来,似乎他还没发现其实我的博客连 RSS 功能都没有。”邮件订阅功能太好实现了,无非是在博客首页放一个文本框供访客输入自己的邮箱地址,提交后博客会将该地址存入 Redis 的一个集合类型键中(使用集合类型是为了保证同一邮箱地址不会存储多个)。每当发布新文章时,就向收集到的邮箱地址发送通知邮件。
想的简单,可是做出来后小白却发现了一个问题:输入邮箱地址提交后,页面需要很久时间才能载入完。原来小白为了确保用户没有输入他人的邮箱,在提交之后程序会向用户输入的邮箱发送一封包含确认链接的邮件,只有用户单击这个链接后对应的邮箱地址才会被程序记录。可是由于发送邮件需要连接到一个远程的邮件发送服务器,网络好的情况下也得花上2秒左右的时间,赶上网络不好10秒都未必能发完。所以每次用户提交邮箱后页面都要等待程序发送完邮件才能加载出来,而加载出来的页面上显示的内容只是提示用户查看自己的邮箱单击确认链接。“完全可以等页面加载出来后再发送邮件,这样用户就不需要等了。”小白喃喃道。按照惯例,有问题问宋老师,小白给宋老师发了一封邮件,不久就收到了答复。
4.4.1 任务队列
小白的问题在网站开发中十分常见,当页面需要进行如发送邮件、复杂数据运算等耗时较长的操作时会阻塞页面的渲染。为了避免用户等待太久,应该使用独立的线程来完成这类操作。不过一些编程语言或框架不易实现多线程,这时很容易就会想到通过其他进程来实现。就小白的例子来说,设想有一个进程能够完成发邮件的功能,那么在页面中只需要想办法通知这个进程向指定的地址发送邮件就可以了。
通知的过程可以借助任务队列来实现。任务队列顾名思义,就是“传递任务的队列”。与任务队列进行交互的实体有两类,一类是生产者(producer),另一类是消费者 (consumer)。生产者会将需要处理的任务放入任务队列中,而消费者则不断地从任务队列中读入任务信息并执行。
对于发邮件这个操作来说页面程序就是生产者,而发邮件的进程就是消费者。当需要发送邮件时,页面程序会将收件地址、邮件主题和邮件正文组装成一个任务后存入任务队列 中。同时发邮件的进程会不断检查任务队列,一旦发现有新的任务便会将其从队列中取出并执行。由此实现了进程间的通信。
使用任务队列有如下好处:
- 松耦合
生产者和消费者无需知道彼此的实现细节,只需要约定好任务的描述格式。这使得生产者和消费者可以由不同的团队使用不同的编程语言编写。
易于扩展
消费者可以有多个,而且可以分布在不同的服务器中,如图4-1所示。借此可以轻易地降低单台服务器的负载。
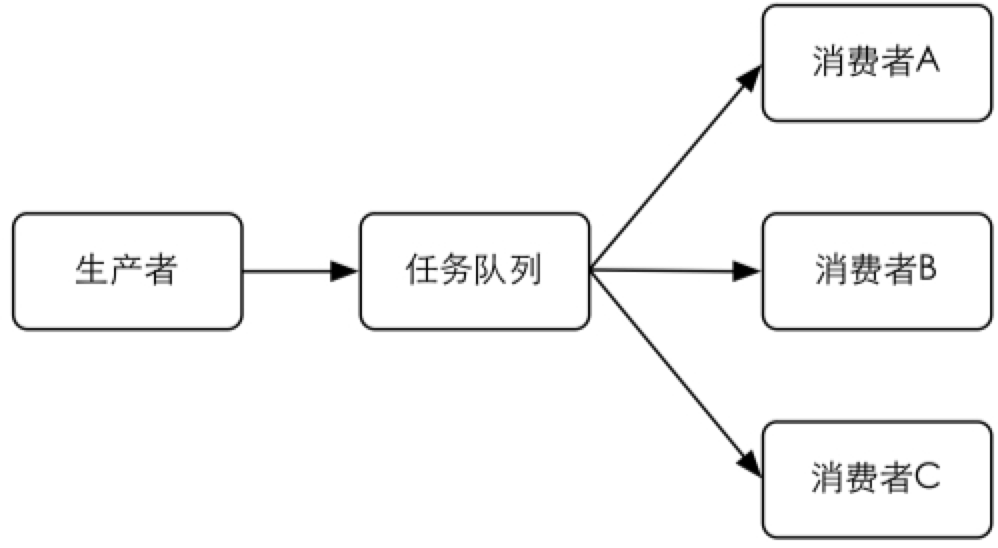
图4-1 可以有多个消费者分配任务队列中的任务4.4.2 使用Redis实现任务队列
说到队列很自然就能想到 Redis 的列表类型,3.4.2节介绍了使用 LPUSH 和 RPOP 命令实现队列的概念。如果要实现任务队列,只需要让生产者将任务使用 LPUSH 命令加入到某个键 中,另一边让消费者不断地使用 RPOP 命令从该键中取出任务即可。
在小白的例子中,完成发邮件的任务需要知道收件地址、邮件主题和邮件正文。所以生产者需要将这3个信息组成对象并序列化成字符串,然后将其加入到任务队列中。而消费者则循环从队列中拉取任务,就像如下伪代码:
# 无限循环读取任务队列中的内容loop$task= RPORqueueif $task# 如果任务队列中有任务则执行它execute($task)else# 如果没有则等待 1 秒以免过于频繁地请求数据 wait 1 second
到此一个使用 Redis 实现的简单的任务队列就写好了。不过还有一点不完美的地方:当任务队列中没有任务时消费者每秒都会调用一次 RPOP 命令查看是否有新任务。如果可以实现一旦有新任务加入任务队列就通知消费者就好了。其实借助 BRPOP 命令就可以实现这样的需求。BRPOP 命令和 RPOP 命令相似,唯一的区别是当列表中没有元素时BRPOP命令会一直阻塞住连接,直到有新元素加入。如上段代码可改写为:
loop# 如果任务队列中没有新任务,BRPOP 命令会一直阻塞,不会执行 execute()。$task= BRPOP queue, 0# 返回值是一个数组(见下介绍),数组第二个元素是我们需要的任务。execute($task[1])
BRPOP命令接收两个参数,第一个是键名,第二个是超时时间,单位是秒。当超过了此时间仍然没有获得新元素的话就会返回 nil。上例中超时时间为”0”,表示不限制等待的时间,即如果没有新元素加入列表就会永远阻塞下去。当获得一个元素后 BRPOP 命令返回两个值,分别是键名和元素值。为了测试 BRPOP 命令,我们可以打开两个 redis-cli 实例,在实例A中使用 BRPOP 后会处于阻塞状态,这时在实例B中向 queue 中加入一个元素,可以看见 A 马上返回了结果,此时再查看 queue 会发现元素已被取走:
redis A> BRPOP queue 0redis B> LPUSH queue task(integer) 1// 在LPUSH命令执行后实例A马上就返回了结果:1) "queue"2) "task"// 同时会发现queue中的元素已经被取走:redis> LLEN queue(integer) 0
除了 BRPOP命令外,Redis 还提供了 BLPOP,和 BRPOP 的区别在与从队列取元素时 BLPOP 会从队列左边取。具体可以参照 LPOP 理解,这里不再赘述。
4.4.3 优先级队列
前面说到了小白博客需要在发布文章的时候向每个订阅者发送邮件,这一步骤同样可以 使用任务队列实现。由于要执行的任务和发送确认邮件一样,所以二者可以共用一个消费者。然而设想这样的情况:假设订阅小白博客的用户有1000人,那么当发布一篇新文章后博 客就会向任务队列中添加1000个发送通知邮件的任务。如果每发一封邮件需要10秒,全部完成这1000个任务就需要近3个小时。
问题来了,假如这期间有新的用户想要订阅小白博客, 当他提交完自己的邮箱并看到网页提示他查收确认邮件时,他并不知道向自己发送确认邮件 的任务被加入到了已经有1000个任务的队列中。要收到确认邮件,他不得不等待近3个小 时。多么糟糕的用户体验!而另一方面发布新文章后通知订阅用户的任务并不是很紧急,大多数用户并不要求有新文章后马上就能收到通知邮件,甚至延迟一天的时间在很多情况下也是可以接受的。
所以可以得出结论当发送确认邮件和发送通知邮件两种任务同时存在时,应该优先执行 前者。为了实现这一目的,我们需要实现一个优先级队列。
BRPOP 命令可以同时接收多个键,其完整的命令格式为:
BLPOP key [key ...] timeout
如 BLPOP queue:1 queue:2 0。意义是同时检测多个键,如果所有键都没有元素则阻塞,如果其中有一个键有元素则会从该键中弹出元素。例如打开两个 redis-cli 实例:
redis A> BLPOP queue:1 queue:2 queue:3 0redis B> LPUSH queue:2 task(integer) 1// 则实例A中会返回:1) "queue:2"2) "task"// 如果多个键都有元素则按照从左到右的顺序取第一个键中的一个元素。我们先在 queue:2 和 queue:3 中各加入一个元素:redis> LPUSH queue:2 task11) (integer) 1redis> LPUSH queue:3 task22) (integer) 1// 然后执行BRPOP命令:redis> BRPOP queue:1 queue:2 queue:3 01) "queue:2"2) "task1"
借此特性可以实现区分优先级的任务队列。我们分别使用 queue:confirmation.email 和 queue:notification.email 两个键存储发送确认邮件和发送通知邮件两种任务,然后将消费者的代码改为:
loop $task=BRPOP queue:confirmation.email, queue:notification.email, 0execute($task[1])
这时一旦发送确认邮件的任务被加入到 queue:confirmation.email 队列中,无论 queue: notification.email 还有多少任务,消费者都会优先完成发送确认邮件的任务。
4.4.4 发布/订阅模式
除了实现任务队列外,Redis 还提供了一组命令可以让开发者实现“发布/订 阅”(publish/subscribe)模式。“发布/订阅”模式同样可以实现进程间的消息传递,其原理是这样的:
“发布/订阅”模式中包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或若干个频道(channel),而发布者可以向指定的频道发送消息,所有订阅此频道的订阅者都会收到此消息。
发布者发布消息的命令是 PUBLISH,用法是:
PUBLISH channel message
如向 channel.1 说一声“hi”:
redis> PUBLISH channel.1 hi(integer) 0
这样消息就发出去了。PUBLISH 命令的返回值表示接收到这条消息的订阅者数量。因为此时没有客户端订阅 channel.1,所以返回 0。发出去的消息不会被持久化,也就是说当有客户端订阅 channel.1 后只能收到后续发布到该频道的消息,之前发送的就收不到了。
订阅频道的命令是 SUBSCRIBE,可以同时订阅多个频道,用法是:
SUBSCRIBE channel [channel ...]
现在新开一个redis-cli 实例 A,用它来订阅 channel.1:
redis A> SUBSCRIBE channel.1Reading messages... (press Ctrl-C to quit)1) "subscribe"2) "channel.1"3) (integer) 1
执行 SUBSCRIBE 命令后客户端会进入订阅状态,处于此状态下客户端不能使用除 SUBSCRIBE、UNSUBSCRIBE、PSUBSCRIBE 和 PUNSUBSCRIBE 这4个属于“发布/订阅”模式 的命令之外的命令(后面3个命令会在下面介绍),否则会报错。
进入订阅状态后客户端可能收到3种类型的回复。每种类型的回复都包含 3 个值,第一个值是消息的类型,根据消息类型的不同,第二、三个值的含义也不同。消息类型可能的取值有以下3个:
- subscribe
表示订阅成功的反馈信息。第二个值是订阅成功的频道名称,第三个值是当前客户端订阅的频道数量。
- message
这个类型的回复是我们最关心的,它表示接收到的消息。第二个值表示产生消息的频道名称,第三个值是消息的内容。
- unsubscribe
表示成功取消订阅某个频道。第二个值是对应的频道名称,第三个值是当前客户端订阅的频道数量,当此值为0时客户端会退出订阅状态,之后就可以执行其他非“发布/订阅”模式的命令了。
上例中当实例A订阅了 channel.1 进入订阅状态后收到了一条 subscribe 类型的回复,这时我们打开另一个 redis-cli 实例B,并向 channel.1 发送一条消息:
redis B> PUBLISH channel.1 hi!(integer) 1
返回值为1表示有一个客户端订阅了channel.1,此时实例A收到了类型为 message 的回复:
1) "message"2) "channel.1"3) "hi!"
使用 UNSUBSCRIBE 命令可以取消订阅指定的频道,用法为 UNSUBSCRIBE [channel [channel …]],如果不指定频道则会取消订阅所有频道[5] 。
4.4.5 按照规则订阅
除了可以使用 SUBSCRIBE 命令订阅指定名称的频道外,还可以使用 PSUBSCRIBE 命令订阅指定的规则。规则支持 glob 风格通配符格式(见3.1节),下面我们新打开一个 redis-cli 实例 C 进行演示:
redis C> PSUBSCRIBE channel.?*Reading messages... (press Ctrl-C to quit)1) "psubscribe"2) "channel.?*"3) (integer) 1
规则 channel.?* 可以匹配 channel.1 和 channel.10,但不会匹配 channel.。这时在实例B中发布消息:
redis B> PUBLISH channel.1 hi!(integer) 2
返回结果为2是因为实例A和实例C两个客户端都订阅了 channel.1 频道。实例C接收到的回复是:
1) "pmessage"2) "channel.?*"3) "channel.1"4) "hi!"
第一个值表示这条消息是通过 PSUBSCRIBE 命令订阅频道而收到的,第二个值表示订阅时使用的通配符,第三个值表示实际收到消息的频道命令,第四个值则是消息内容。
提示 使用 PSUBSCRIBE 命令可以重复订阅一个频道,如某客户端执行了 PSUBSCRIBE channel.? channel.?,这时向 channel.2 发布消息后该客户端会收到两条消息,而同时 PUBLISH命令返回的值也是2而不是1。同样的,如果有另一个客户端执行了 SUBSCRIBE channel.10 和 PSUBSCRIBE channel.? 的话,向 channel.10 发送命令该客户端也会收到两条消息(但是是两种类型:message和pmessage),同时PUBLISH 命令会返回2。
PUNSUBSCRIBE 命令可以退订指定的规则,用法是:
PUNSUBSCRIBE [pattern [pattern ...]]
如果没有参数则会退订所有规则。
注意 使用 PUNSUBSCRIBE 命令只能退订通过 PSUBSCRIBE 命令订阅的规则,不会影响直接通过 SUBSCRIBE 命令订阅的频道;同样 UNSUBSCRIBE 命令也不会影响通过 PSUBSCRIBE 命令订阅的规则。另外容易出错的一点是使用 PUNSUBSCRIBE 命令退订某个规则时不会将其中的通配符展开,而是进行严格的字符串匹配,所以 PUNSUBSCRIBE 无法退订 channel. 规则,而是必须使用 PUNSUBSCRIBE channel.* 才能退订。
4.5管道
客户端和 Redis 使用TCP 协议连接。不论是客户端向 Redis 发送命令还是 Redis 向客户端返回命令的执行结果,都需要经过网络传输,这两个部分的总耗时称为往返时延。根据网络性能不同,往返时延也不同,大致来说到本地回环地址(loop back address)的往返时延在数量级上相当于 Redis 处理一条简单命令(如 LPUSH list 1 2 3)的时间。如果执行较多的命令, 每个命令的往返时延累加起来对性能还是有一定影响的。
在执行多个命令时每条命令都需要等待上一条命令执行完(即收到 Redis 的返回结果)才能执行,即使命令不需要上一条命令的执行结果。如要获得post:1、post:2和post:3这3个键中的title字段,需要执行3条命令,示意图如图4-2所示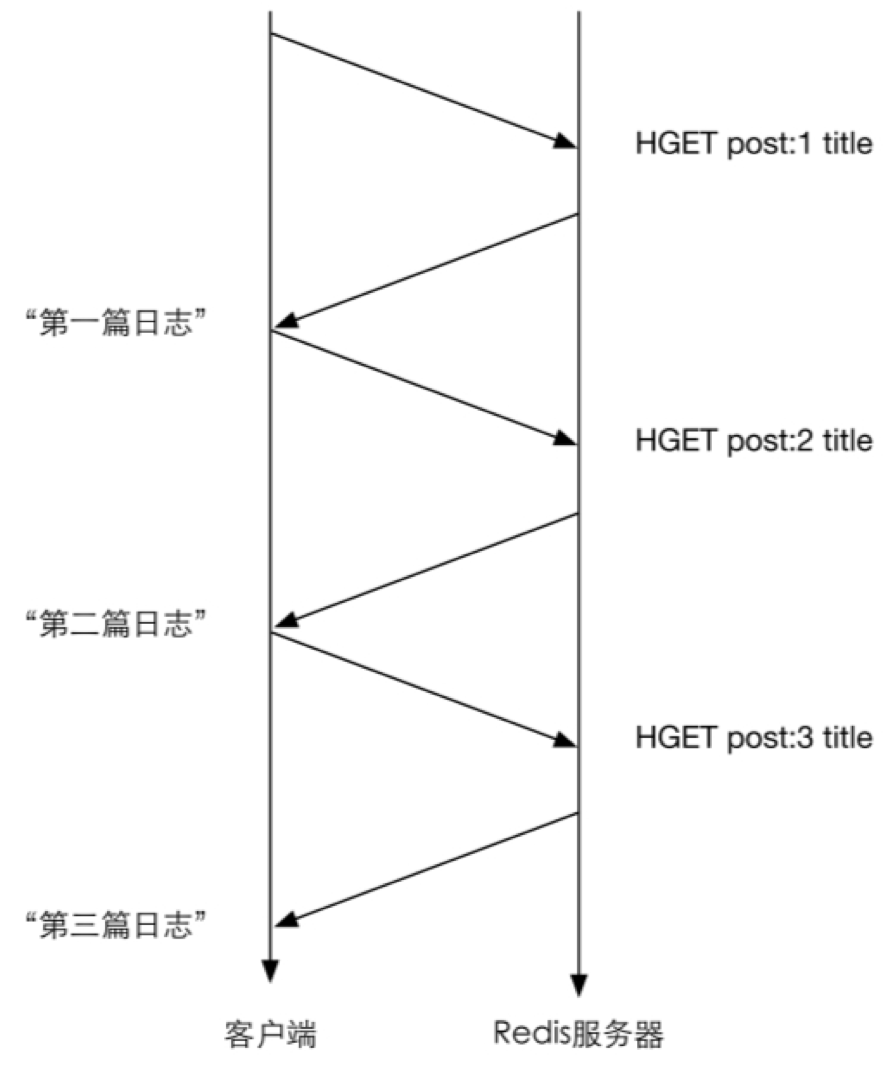
图4-2 不使用管道时的命令执行示意图(纵向表示时间)
Redis 的底层通信协议对管道(pipelining)提供了支持。通过管道可以一次性发送多条命令并在执行完后一次性将结果返回,当一组命令中每条命令都不依赖于之前命令的执行结果时就可以将这组命令一起通过管道发出。管道通过减少客户端与 Redis 的通信次数来实现降低往返时延累计值的目的,如图4-3所示: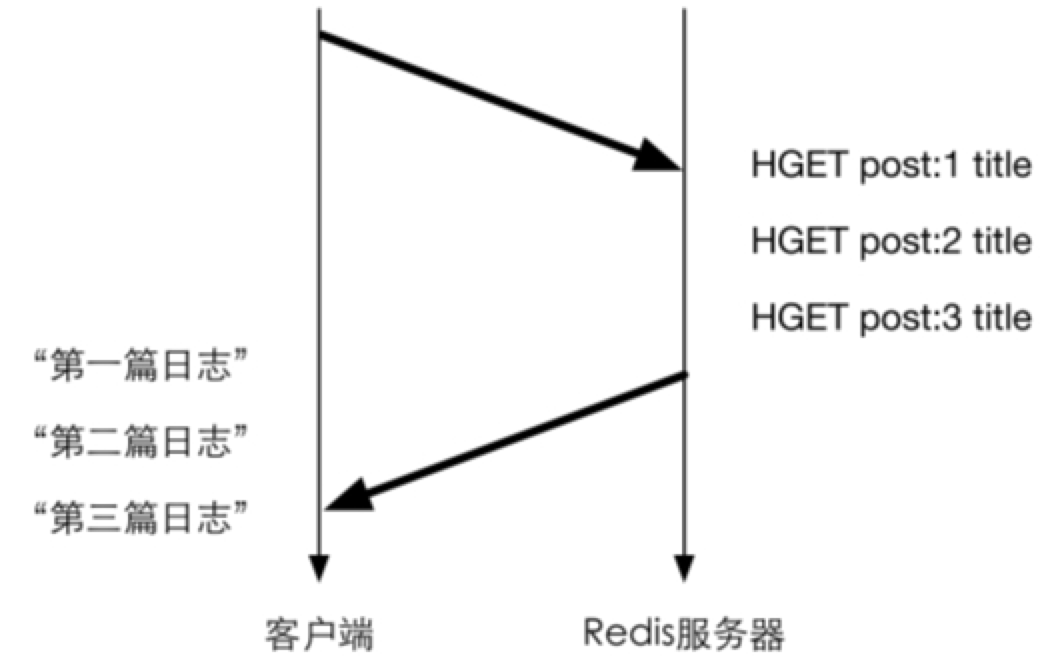
图4-3 使用管道时的命令执行示意图
第5章会结合不同的编程语言介绍如何在开发的时候使用管道技术。
4.6 节省空间
Jim Gray [6] 曾经说过:“内存是新的硬盘,硬盘是新的磁带。”内存的容量越来越大,价格也越来越便宜。2012年年底,亚马逊宣布即将发布一个拥有 240GB 内存的 EC2 实例,如果放到若干年前来看,这个容量就算是对于硬盘来说也是很大的了。即便如此,相比于硬盘而言,内存在今天仍然显得比较昂贵。而 Redis 是一个基于内存的数据库,所有的数据都存储在内存中,所以如何优化存储,减少内存空间占用对成本控制来说是一个非常重要的话题。
4.6.1 精简键名和键值
精简键名和键值是最直观的减少内存占用的方式,如将键名 very.important.person:20 改成 VIP:20。当然精简键名一定要把握好尺度,不能单纯为了节约空间而使用不易理解的键名 (比如将VIP:20修改为V:20,这样既不易维护,还容易造成命名冲突)。又比如一个存储用户性别的字符串类型键的取值是 male 和 female,我们可以将其修改成m和f来为每条记录节约几个字节的空间(更好的方法是使用0和1来表示性别,稍后会详细介绍原因)[7] 。
4.6.2 内部编码优化
有时候仅凭精简键名和键值所减少的空间并不足以满足需求,这时就需要根据 Redis 内部编码规则来节省更多的空间。Redis 为每种数据类型都提供了两种内部编码方式,以散列类型为例,散列类型是通过散列表实现的,这样就可以实现O(1)时间复杂度的查找、赋值操作,然而当键中元素很少的时候,O(1)的操作并不会比O(n)有明显的性能提高,所以这种情况下 Redis 会采用一种更为紧凑但性能稍差(获取元素的时间复杂度为O(n))的内部编码方式。内部编码方式的选择对于开发者来说是透明的,Redis 会根据实际情况自动调整。当键中元素变多时 Redis 会自动将该键的内部编码方式转换成散列表。如果想查看一个键的内部编码方式可以使用 OBJECT ENCODING 命令,例如:
redis> SET foo barOKredis> OBJECT ENCODING foo"raw"
Redis的每个键值都是使用一个 redisObject 结构体保存的,redisObject 的定义如下:
typedef struct redisObject {unsigned ty pe:4;unsigned notused:2; /* Not used */unsigned encoding:4;unsigned lru:22; /* lru time (relative to server.lruclock) */ int refcount;void *ptr;} robj;
其中 type 字段表示的是键值的数据类型,取值可以是如下内容:
#define REDIS_STRING 0#define REDIS_LIST 1#define REDIS_SET 2#define REDIS_ZSET 3#define REDIS_HASH 4
encoding字段表示的就是 Redis 键值的内部编码方式,取值可以是:
#define REDIS_ENCODING_RAW 0 /* Raw representation */#define REDIS_ENCODING_INT 1 /* Encoded as integer */#define REDIS_ENCODING_HT 2 /* Encoded as hash table */#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
各个数据类型可能采用的内部编码方式以及相应的 OBJECT ENCODING 命令执行结果如表4-2所示:
表4-2 每个数据类型都可能采用两种内部编码方式之一来存储
下面针对每种数据类型分别介绍其内部编码规则及优化方式。
1.字符串类型
Redis 使用一个 sdshdr 类型的变量来存储字符串,而 redisObject 的 ptr 字段指向的是该变量的地址。sdshdr 的定义如下:
struct sdshdr {int len;int free;char buf[];};
其中 len 字段表示的是字符串的长度,free 字段表示 buf 中的剩余空间,而 buf 字段存储的才是字符串的内容。所以当执行 SET key foobar 时,存储键值需要占用的空间是:
sizeof(redisObject) + sizeof(sdshdr) + strlen(“foobar”) = 30字节 [8] ,如图4-4所示: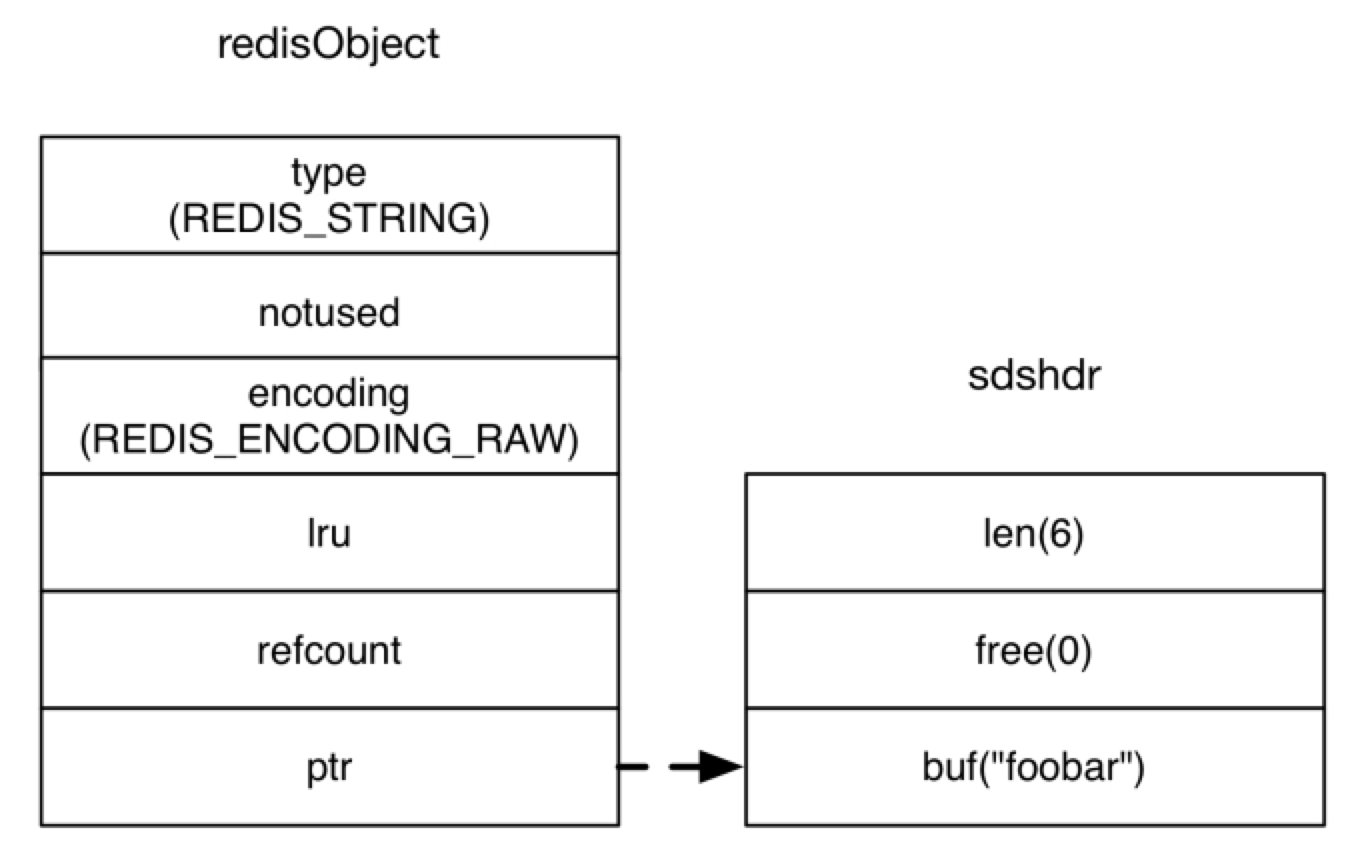
图4-4 字符串键值 “foobar” 使用 RAW 编码时的存储结构
而当键值内容可以用一个64位有符号整数表示时,Redis 会将键值转换成 long 类型来存储。如 SET key 123456,实际占用的空间是 sizeof(redisObject) = 16字节,比存储”foobar”节 省了一半的存储空间,如图4-5所示。
图4-5 字符串键值”123456”的内存结构
redisObject 中的 refcount 字段存储的是该键值被引用数量,即一个键值可以被多个键引用。Redis启动后会预先建立10000个分别存储从0到9999这些数字的 redisObject 类型变量作为共享对象,如果要设置的字符串键值在这10000个数字内(如SET key1 123)则可以直接引用共享对象而不用再建立一个 redisObject 了,也就是说存储键值占用的空间是0字节,如图 4-6所示:
图4-6当执行了SET key1 123和SET key2 123后,key1和key2两个键都直接引用了一 个已经建立好的共享对象,节省了存储空间
由此可见,使用字符串类型键存储对象ID这种小数字是非常节省存储空间的,Redis 只需存储键名和一个对共享对象的引用即可。
提示 当通过配置文件参数 maxmemory 设置了Redis可用的最大空间大小时,Redis不会使用共享对象,因为对于每一个键值都需要使用一个 redisObject 来记录其 LRU 信息。
此外Redis 3.0新加入了 REDIS_ENCODING_EMBSTR 的字符串编码方式,该编码方式与 REDIS_ENCODING_RAW 类似,都是基于 sdshdr 实现的,只不过 sdshdr 的结构体与其对应的分配在同一块连续的内存空间中,如图4-7所示。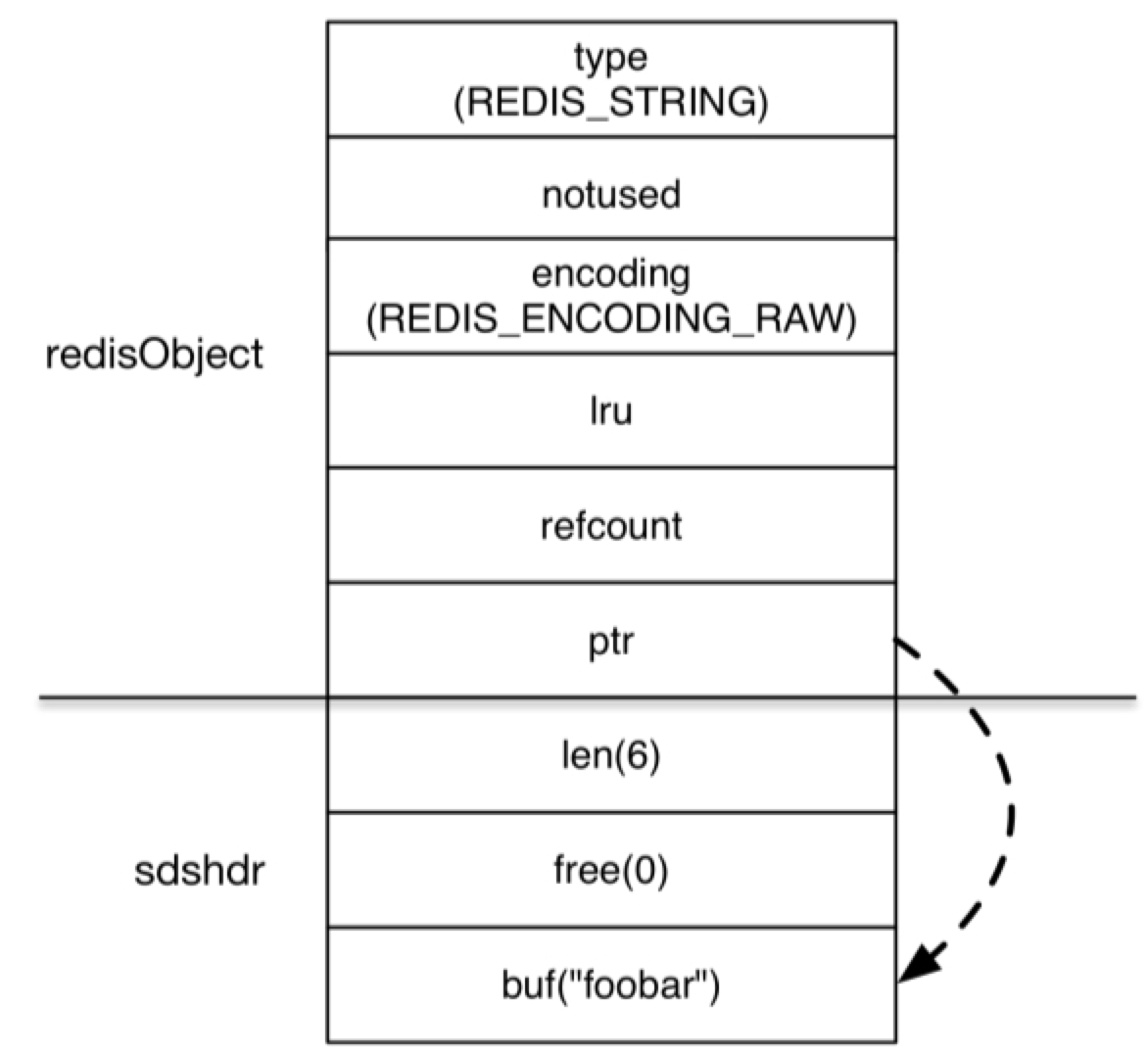
图4-7 字符串键值”foobar”使用 EMBSTR 编码时的存储结构
使用 REDIS_ENCODING_EMBSTR 编码存储字符串后,不论是分配内存还是释放内存,所需要的操作都从两次减少为一次。而且由于内存连续,操作系统缓存可以更好地发挥作用。当键值内容不超过39字节时,Redis 会采用 REDIS_ENCODING_EMBSTR 编码,同时当对使用 REDIS_ENCODING_EMBSTR 编码的键值进行任何修改操作时(如APPEND命令), Redis会将其转换成 REDIS_ENCODING_RAW 编码。
2.散列类型
散列类型的内部编码方式可能是 REDIS_ENCODING_HT 或 REDIS_ENCODING_ZIPLIST[9] 。在配置文件中可以定义使用 REDIS_ENCODING_ZIPLIST 方式编码散列类型的时机:
hash-max-ziplist-entries 512hash-max-ziplist-value 64
当散列类型键的字段个数少于 hash-max-ziplist-entries 参数值且每个字段名和字段值的长度都小于 hash-max-ziplist-value 参数值(单位为字节)时,Redis 就会使用 REDIS_ ENCODING_ZIPLIST 来存储该键,否则就会使用 REDIS_ENCODING_HT。转换过程是透明的,每当键值变更后 Redis 都会自动判断是否满足条件来完成转换。
REDIS_ENCODING_HT 编码即散列表,可以实现O(1)时间复杂度的赋值取值等操作,其字段和字段值都是使用 redisObject 存储的,所以前面讲到的字符串类型键值的优化方法同样适用于散列类型键的字段和字段值。
提示 Redis的键值对存储也是通过散列表实现的,与 REDIS_ENCODING_HT 编码方式类似,但键名并非使用 redisObject 存储,所以键名”123456”并不会比”abcdef”占用更少的空间。之所以不对键名进行优化是因为绝大多数情况下键名都不会是纯数字。
补充知识 Redis 支持多数据库,每个数据库中的数据都是通过结构体 redisDb 存储的。 dict 类型就是散列表结构,expires 存储的是数据的过期时间。当Redis启动时会根据配置文件中 databases参数指定的数量创建若干个 redisDb 类型变量存储不同数据库中的数据。redisDb的定义如下:
typedef struct redisDb {dict *dict; /* The key space for this DB */dict *expires; /* Timeout of keys with a timeout set */dict *blocking_key s; /* Key s with clients waiting for data (BLPOP) */ dict *ready _key s; /* Blocked key s that received a PUSH */dict *watched_key s; /* WATCHED key s for MULTI/EXEC CAS */ int id;} redisDb;
REDIS_ENCODING_ZIPLIST 编码类型是一种紧凑的编码格式,它牺牲了部分读取性能以换取极高的空间利用率,适合在元素较少时使用。该编码类型同样还在列表类型和有序集合类型中使。REDIS_ENCODING_ZIPLIST 编码结构如图 4-8 所示,其中 zlbytes 是 uint32_t 类型,表示整个结构占用的空间。zltail 也是 uint32_t 类型,表示到最后一个元素的偏移,记录 zltail 使得程序可以直接定位到尾部元素而无需遍历整个结构,执行从尾部弹出(对列表类型而言)等操作时速度更快。zllen 是uint16_t类型,存储的是元素的数量。zlend 是一个 单字节标识,标记结构的末尾,值永远是255。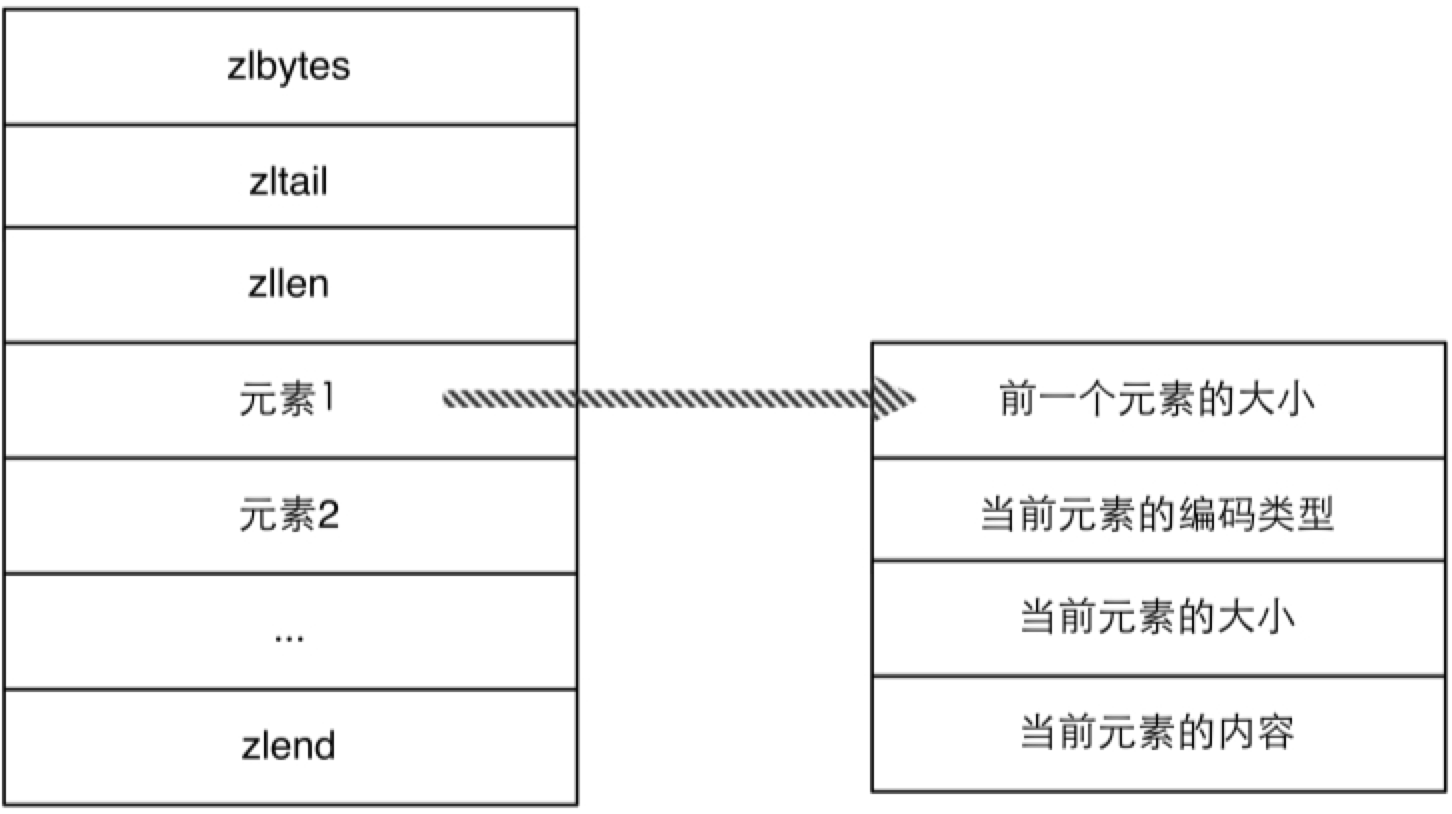
图4-8 REDIS_ENCODING_ZIPLIST编码的内存结构
在 REDIS_ENCODING_ZIPLIST 中每个元素由4个部分组成。第一个部分用来存储前一个元素的大小以实现倒序查找,当前一个元素的大小小于254 字节时第一个部分占用1个字节,否则会占用5个字节。第二、三个部分分别是元素的编码类型和元素的大小,当元素的大小小于或等于63个字节时,元素的编码类型是 ZIP_STR_06B(即0<<6),同时第三个部分用6个二进制位来记录元素的长度,所以第二、三个部分总占用空间是1字节。当元素的大小大于63且小于或等于16383字节时,第二、三个部分总占用空间是2字节。当元素的大小大于16383字节时,第二、三个部分总占用空间是5字节。第四个部分是元素的实际内容,如果元素可以转换成数字的话 Redis 会使用相应的数字类型来存储以节省空间,并用第二、三个部分来表示数字的类型(int16_t、int32_t等)。使用 REDIS_ENCODING_ZIPLIST编码存储散列类型时元素的排列方式是:元素1存储 字段1,元素2存储字段值1,依次类推,如图4-9所示: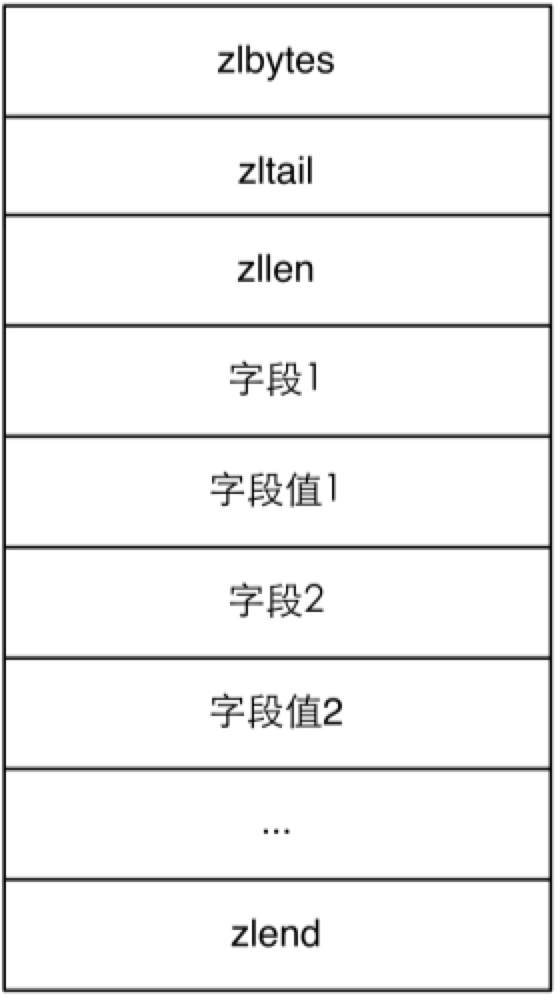
图4-9 使用 REDIS_ENCODING_ZIPLIST编码存储散列类型的内存结构
例如,当执行命令 HSET hkey foo bar 命令后,hkey 键值的内存结构如图4-10所示。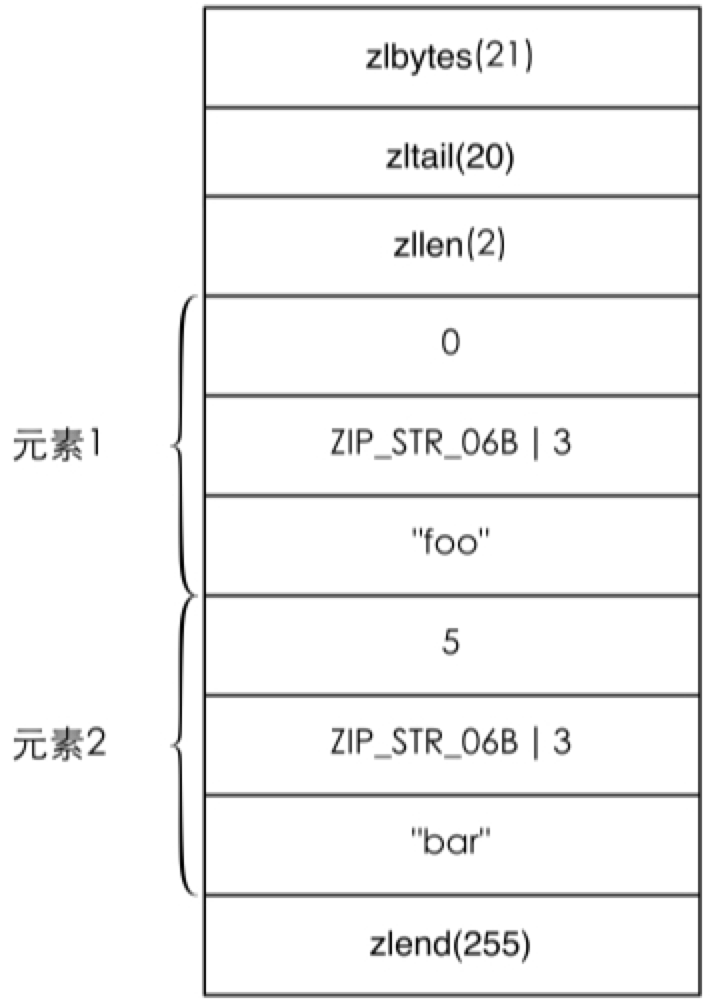
图4-10 hkey键值的内存结构
下次需要执行 HSET hkey foo anothervalue 时 Redis需要从头开始找到值为 foo 的元素(查找时每次都会跳过一个元素以保证只查找字段名),找到后删除其下一个元素,并将新值 anothervalue 插入。删除和插入都需要移动后面的内存数据,而且查找操作也需要遍历才能完成,可想而知当散列键中数据多时性能将很低,所以不宜将 hash-max-ziplist-entries 和 hash- max-ziplist-value 两个参数设置得很大。
3.列表类型
列表类型的内部编码方式可能是 REDIS_ENCODING_LINKEDLIST 或 REDIS ENCODING_ZIPLIST。同样在配置文件中可以定义使用 REDIS_ENCODING_ZIPLIST 方式编码的时机:
list-max-ziplist-entries 512list-max-ziplist-value 64
具体转换方式和散列类型一样,这里不再赘述。 REDIS_ENCODING_LINKEDLIST 编码方式即双向链表,链表中的每个元素是用 redisObject 存储的,所以此种编码方式下元素值的优化方法与字符串类型的键值相同。 而使用 REDIS_ENCODING_ZIPLIST 编码方式时具体的表现和散列类型一样,由于 REDIS_ENCODING_ZIPLIST 编码方式同样支持倒序访问,所以采用此种编码方式时获取两 端的数据依然较快。
Redis最新的开发版本新增了 REDIS_ENCODING_QUICKLIST 编码方式,该编码方式是 REDIS_ENCODING_LINKEDLIST 和 REDIS_ENCODING_ZIPLIST的结合,其原理是将一个长列表分成若干个以链表形式组织的 ziplist,从而达到减少空间占用的同时提升 REDIS_ENCODING_ZIPLIST 编码的性能的效果。
4.集合类型
集合类型的内部编码方式可能是 REDIS_ENCODING_HT 或 REDIS_ENCODING_INTSET。当集合中的所有元素都是整数且元素的个数小于配置文件中的 set-max-intset-entries 参数指定值(默认是512)时 Redis 会使用 REDIS_ENCODING_INTSET 编码存储该集合,否则会使用 REDIS_ENCODING_HT 来存储。 REDIS_ENCODING_INTSET 编码存储结构体 intset 的定义是:
ty pedef struct intset {uint32_t encoding; uint32_t length; int8_t contents[];} intset;
其中 contents 存储的就是集合中的元素值,根据 encoding 的不同,每个元素占用的字节大小不同。默认的encoding 是 INTSET_ENC_INT16 (即2个字节),当新增加的整数元素无法使用 2 个字节表示时,Redis 会将该集合的 encoding 升级为 INTSET_ENC_INT32(即4个字 节)并调整之前所有元素的位置和长度,同样集合的 encoding 还可升级为 INTSET_ENC_INT64(即8个字节)。
REDIS_ENCODING_INTSET 编码以有序的方式存储元素(所以使用 SMEMBERS 命令获得的结果是有序的),使得可以使用二分算法查找元素。然而无论是添加还是删除元素, Redis 都需要调整后面元素的内存位置,所以当集合中的元素太多时性能较差。
当新增加的元素不是整数或集合中的元素数量超过了 set-max-intset-entries 参数指定值时,Redis会自动将该集合的存储结构转换成 REDIS_ENCODING_HT。
注意 当集合的存储结构转换成 REDIS_ENCODING_HT 后,即使将集合中的所有非整数元素删除,Redis也不会自动将存储结构转换回 REDIS_ENCODING_INTSET。因为如果要支持自动回转,就意味着 Redis 在每次删除元素时都需要遍历集合中的键来判断是否可以转换回原来的编码,这会使得删除元素变成了时间复杂度为O(n)的操作。
5.有序集合类型
有序集合类型的内部编码方式可能是 REDIS_ENCODING_SKIPLIST 或 REDIS_ENCODING_ZIPLIST。同样在配置文件中可以定义使用 REDIS_ENCODING_ZIPLIST 方式编码的时机:
zset-max-ziplist-entries 128zset-max-ziplist-value 64
具体规则和散列类型及列表类型一样,不再赘述。 当编码方式是 REDIS_ENCODING_SKIPLIST 时,Redis 使用散列表和跳跃列表(skiplist)两种数据结构来存储有序集合类型键值,其中散列表用来存储元素值与元素分数的映射关系以实现O(1)时间复杂度的 ZSCORE 等命令。跳跃列表用来存储元素的分数及其到元素值的映射以实现排序的功能。Redis 对跳跃列表的实现进行了几点修改,其中包括允许跳跃列表中的元素(即分数)相同,还有为跳跃链表每个节点增加了指向前一个元素的指针以实现倒序查找。
采用此种编码方式时,元素值是使用 redisObject 存储的,所以可以使用字符串类型键值的优化方式优化元素值,而元素的分数是使用 double 类型存储的。
使用 REDIS_ENCODING_ZIPLIST 编码时有序集合存储的方式按照“元素1的值,元素1的分数,元素2的值,元素2的分数”的顺序排列,并且分数是有序的。
注释
[1] 事务回滚是指将一个事务已经完成的对数据库的修改操作撤销。
[2] 事实上 Redis 并不会准确地将整个数据库中最久未被使用的键删除,而是每次从数据库中随机取3个键并删除这3个键中最久未被使用的键。删除过期时间最接近的键的实现方法也是这样。“3”这个数字可以通过 Redis 的配置文件中的 maxmemory-samples 参数设置。
[3] 集合类型经常被用于存储对象的 ID,很多情况下都是整数。所以 Redis 对这种情况进行了特殊的优化,元素的排列是有序的。4.6节会详细介绍具体的原理。
[4] 有一个例外是当键类型为有序集合且参考键为常量键名时容器大小为 m 而不是 n。
[5] 由于 redis-cli 的限制我们无法在其中测试 UNSUBSCRIBE 命令。
[6] JimGray是 1998年的图灵奖得主,在数据库(尤其是事务)方面做出过卓越的贡献。其于2007年独自驾船在海上失踪。
[7] 3.2.4节还介绍过使用字符串类型的位操作来存储性别,更加节约空间。
[8] 本节所说的字节数以64位 Linux 系统为前提。
[9] 在 Redis2.4 及以前的版本中散列类型的键采用 REDIS_ENCODING_HT 或 REDIS_ENCODING_ZIPMAP 的编码方式。

若有收获,就点个赞吧
0 人点赞
