Part 3 —— 索引与慢查询优化、数据库三大范式
一、索引
1、索引与慢查询优化
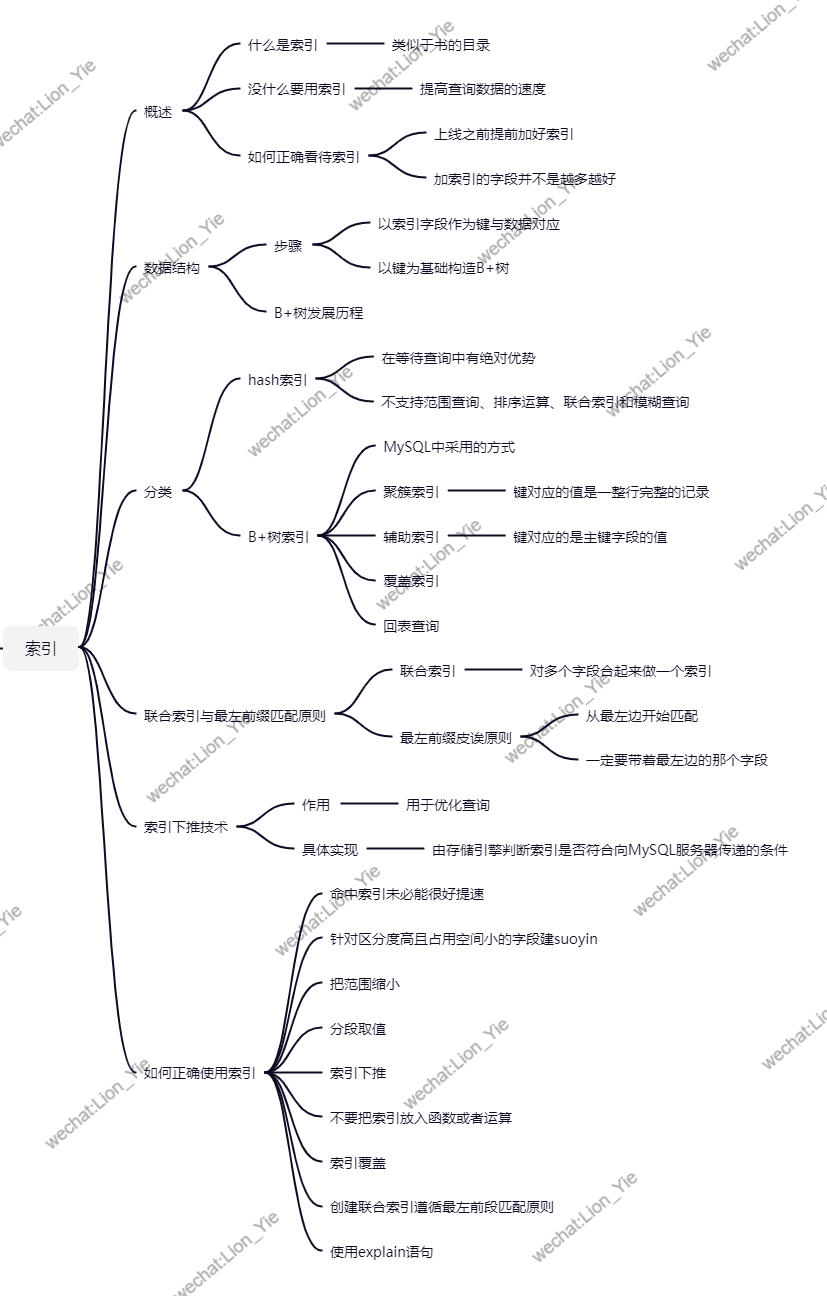
索引:简单的理解为可以帮助你加快数据查询速度的工具也可以把索引比喻成书的目录算法:解决事务的办法入门级算法:二分法二分法前提:数据集必须有序数据结构二叉树(只能分两个叉)b树b+树(叶子节点添加了指针)b*树(枝节点也添加了指针)# 对于精确查找(找某个数据),查找次数看深度,b,b+,b*查找次数没有区别# 添加指针是为了加快范围查询的速度将某个字段添加成索引就相当于依据该字段建立了一颗b+树从而加快查询速度如果某个字段没有添加索引 那么依据该字段查询数据会非常的慢(一行行查找)
2、索引的分类
1.primary key主键索引除了有加速查询的效果之外 还具有一定的约束条件2.unique key唯一键索引 除了有加速查询的效果之外 还具有一定的约束条件3.index key普通索引 只有加速查询的效果 没有额外约束4.# 注意外键不是索引 它仅仅是用来创建表与表之间关系的
3、如何操作索引
创建唯一索引需要提前排查是否有重复数据select count(字段) from t1select count(distinct(字段)) from t1查看当前表内部索引值show index from t1;主键索引alter table t1 add primary key pri_id(id);唯一索引alter table t1 add unique key uni_age(age)普通索引alter table t1 add index idx_name(name)前缀索引(属于普通索引)避免对大列建索引,如果有就使用前缀索引eg:博客内容 百度搜索内容等alter table t1 add index idx_name(name(4))联合索引(属于普通索引)相亲平台 搜索心仪对象的时候# 最左匹配原则gender money height beautifulalter table t1 add index idx_all(name,age,sex)删除索引alter table t1 drop index 索引名(idx_name、idx_all...)
4、explain句式
全表扫描不走索引 一行行查找数据 效率极低 生产环境下尽量不要书写类似SQL索引扫描走索引 加快数据查询 建议书写该类型SQLexplain就是帮助我们查看SQL语句属于那种扫描# 常见的索引扫描类型:1)index2)range3)ref4)eq_ref5)const6)system7)null从上到下,性能从最差到最好,我们认为至少要达到range级别# 不走索引情况(起码记忆四条及以上)1.没有查询条件,或者查询条件没有建立索引2.查询结果集是原表中的大部分数据(25%以上)3.索引本身失效,统计数据不真实4.查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+,-,*等)5.隐式转换导致索引失效eg:字段是字符类型 查询使用整型6.<> ,not in 不走索引单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit、or或in尽量改成union7.like "%_" 百分号在最前面不走8.单独引用联合索引里非第一位置的索引列"""索引的创建会加快数据的查询速度 但是一定程度会拖慢数据的插入和删除速度"""
二、数据库三大范式
三、隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改InnoDB支持所有隔离级别set transaction isolation level 级别1.read uncommitted(未提交读)事务中的修改即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这一现象也称之为"脏读"2.read committed(提交读)大多数数据库系统默认的隔离级别一个事务从开始直到提交之前所作的任何修改对其他事务都是不可见的,这种级别也叫做"不可重复读"3.repeatable read(可重复读) # MySQL默认隔离级别能够解决"脏读"问题,但是无法解决"幻读"所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行,InnoDB和XtraDB通过多版本并发控制(MVCC)及间隙锁策略解决该问题4.serializable(可串行读)强制事务串行执行,很少使用该级别https://www.cnblogs.com/LionYie/p/15569484.html

若有收获,就点个赞吧
0 人点赞
