1.分库分表介绍
1.1 分库分表概
:::tips
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题;
核心操作:
1.将原来独立的数据库拆分成若干数据库组成;
2.将原来的大表(存储近千万数据的表)拆分成若干个小表;
目的:使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
:::
2.分库分表的方式
2.1 垂直分表
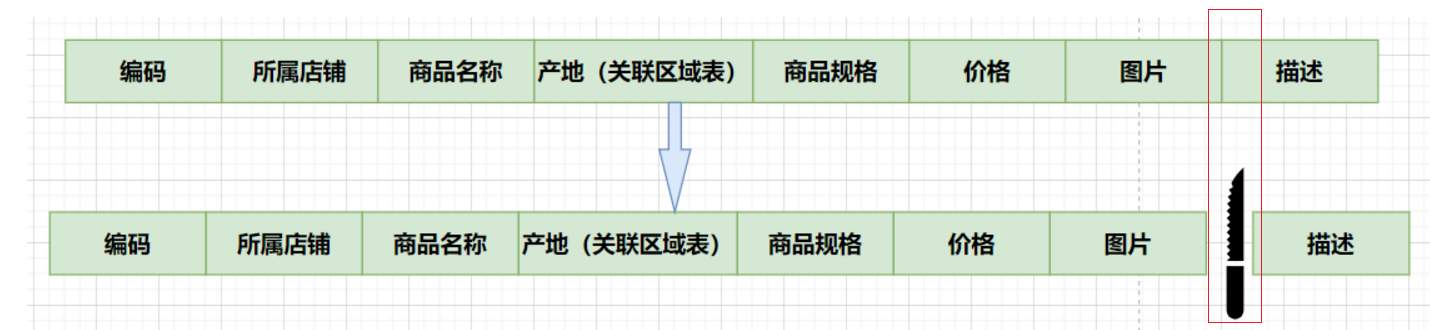
垂直分表优势
:::tips
1.充分发挥热点数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累(冷热数据分离);
2.避免了IO过度争抢并减少锁表的几率,查看商品详情的用户与商品信息浏览互不影响;
:::
垂直分表原则
:::tips
1.把不常用的字段单独放在一张表;(因为数据库加载数据时,会将表整整行的信息加载)
2.把text(大文本存储),blob(图片、视频类存储)等大字段拆分出来放在附表中;(实际开发中尽量避免向mysql数据库中存储大本文)
3.经常组合查询的列放在一张表中(避免多表联查,性能最高);
:::
2.2 垂直分库
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是【专库专用】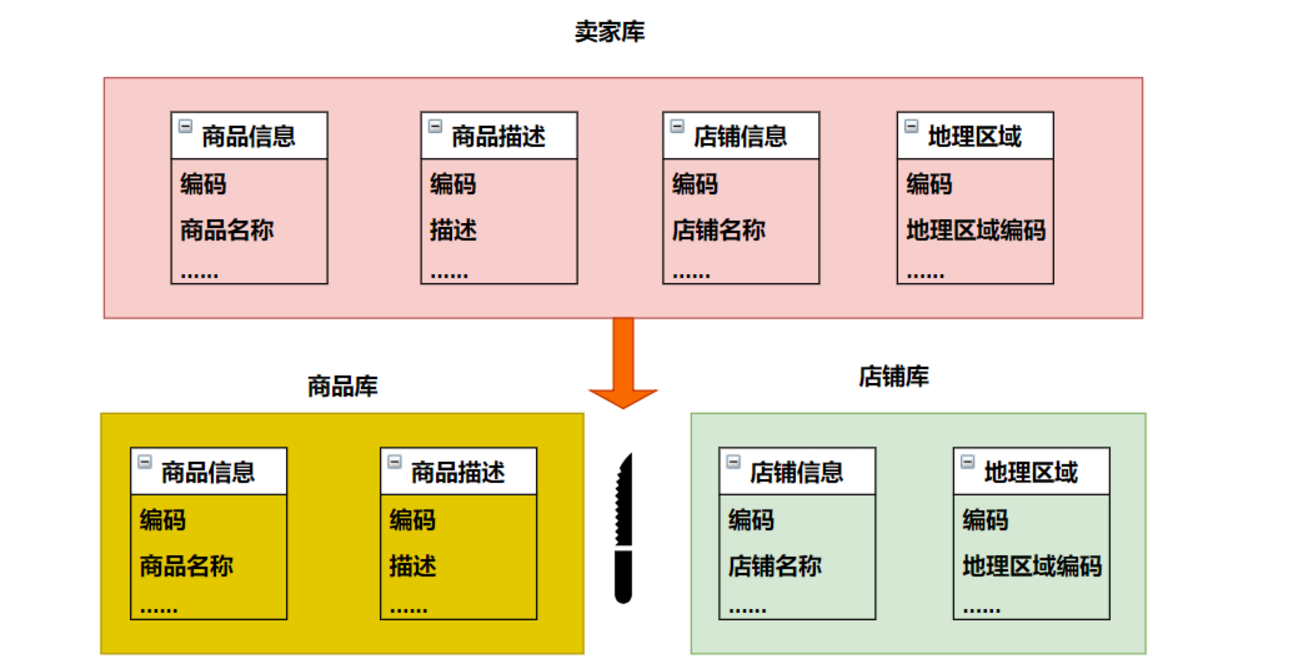
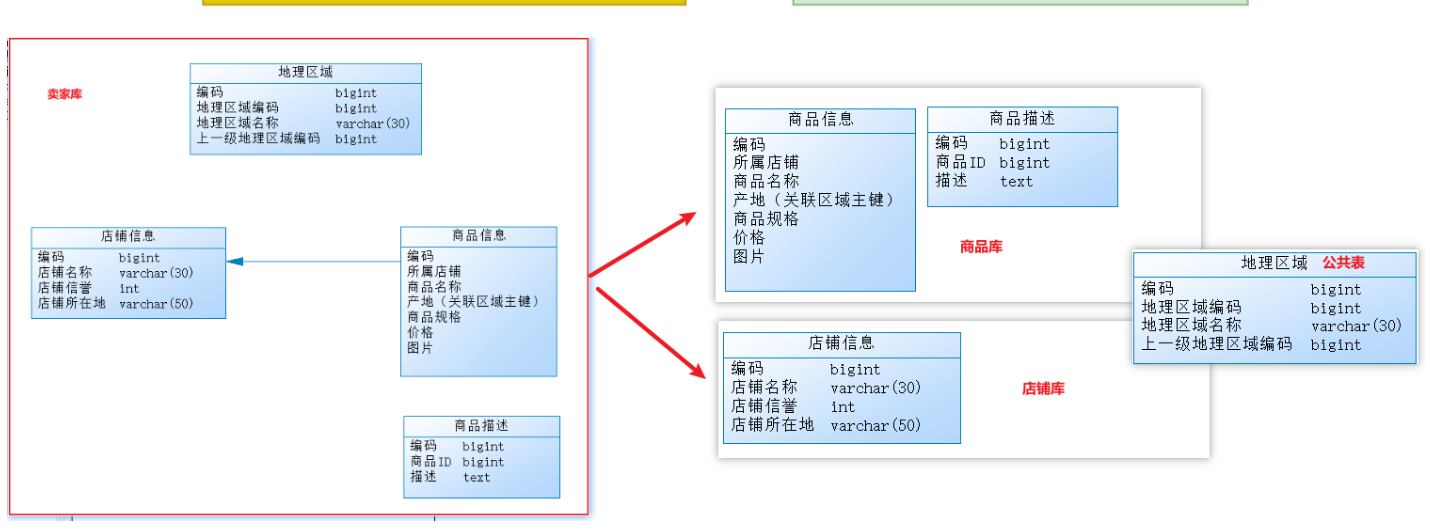
注意事项:
:::tips
由于商品信息与商品描述业务耦合度较高,因此一起被存放在商品库(避免跨库联查);
而店铺信息相对独立,因此单独被存放在店铺库下;
对于地理区域表,因为商品信息和店铺信息都需要,且地理区域是不经常变动的常量表但是会存在与其他表联查的情况,所以可以将它作为公共表分别等量部署到不同的数据库节点下;
以上操作就可以称为垂直分库。
:::
垂直分库优势
- 通过不同表的业务聚合(聚合为库),使得数据库维护更加清晰;
- 能对不同业务的数据进行分级管理、维护、监控、扩展等;
高并发场景下,垂直分库在一定程度上提高了磁盘IO和数据库连接数,并改善了单机硬件资源的瓶颈问题
2.3 水平分表
【1】定义
水平分表就是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中(解决单表数据量大的问题)。
【2】水平分表示例

如果商品ID为双数,将此操作映射至商品信息1表;如果商品ID为单数,将操作映射至商品信息2表。此操作要访问表名称的表达式为商品信息[商品ID%2 + 1];这种操作就叫做:水平分表。
3】水平分表优势
水平分表是在==同一个数据库内==,把同一个表的数据按一定规则拆到多个表中,它带来的提升是:
优化单一表数据量过大而产生的性能问题;
- 避免IO争抢并减少锁表的几率;
整体看,水平分表仅仅解决了单表数据量过大的问题,但是没有解决单库数据量过大的问题
2.4 水平分库
【1】定义
名词解释:水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上(解决单库数据量大的问题)。
【2】示例场景

如果商品ID为双数,将此操作映射至【商品库-1】;如果店铺ID为单数,将操作映射至【商品库-2】;此操作要访问数据库名称的表达式为:商品库_(商品ID%2 + 1);这种操作就叫水平分库。总之,水平分库后,各个库保存的表结构是一致的,但是表中内容不一样;
【3】水平分库优势
:::tips
- 解决了单库大数据,高并发的性能瓶颈问题;
- 提高了系统的稳定性及可用性;
:::
2.5 分库分表小结
分库分表方式:垂直分表、垂直分库、水平分库和水平分表
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
水平分库:可以把一个表的数据(按数据行)分 到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
最佳实践:
一般来说,在系统设计阶段就应该==根据业务耦合松紧==来确定垂直分库,垂直分表方案。当然在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
注意:非必须,不要分库分表(开发和维护成本比较高)3. sharding-jdbc架构
3.1 ShardingSphere简介
:::tips Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈。
组成部分: ==JDBC==、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。
功能特性:它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。 :::
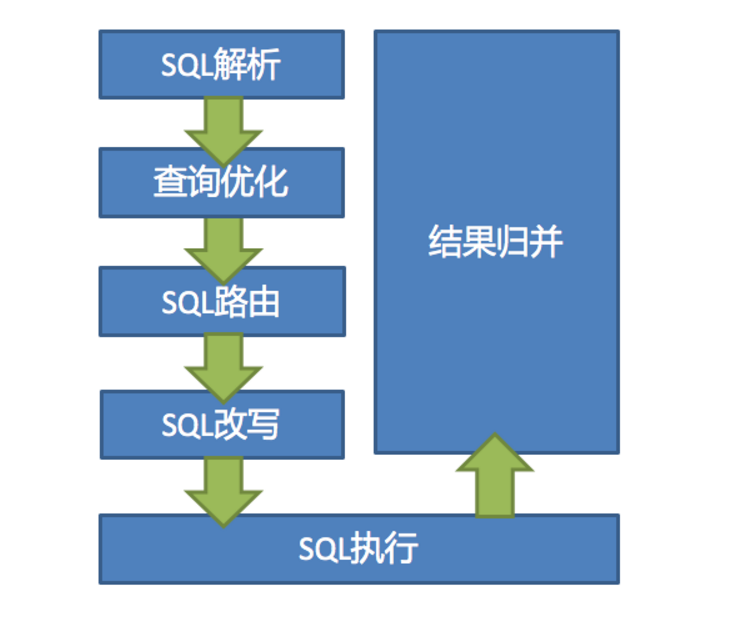
3.2 Sharding-JDBC执行原理
3.3 sharding-jdbc入门
sharding-jdbc实现数据分片有4种策略:
:::tips
1.inline模式-行表达式分片策略(单片键)★
使用最简单,开发成本比较低;
通过groovy表达式来表示分库分表的策略;
eg:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
表达式:db${0..1}.t_order${0..1}
2.standard模式-标准分片策略(单片键)★
自定义复杂的分片策略;
3.complex模式-用于多分片键的复合分片策略(多片键)
4.Hint模式-强制分片策略(强制路由)
不指定片键,通过代码动态指定(使用较少)
:::
# 配置shardingjdbc# 数据源名称,多数据源以逗号分隔(datasource名称不要使用特殊符号)spring.shardingsphere.datasource.names=ds1,ds2# 数据库连接池类名称spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource# 数据库驱动类名spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver# 数据库 url 连接spring.shardingsphere.datasource.ds1.url=jdbc:mysql://192.168.200.130:3306/order_db_1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai# 数据库用户名spring.shardingsphere.datasource.ds1.username=root# 数据库密码spring.shardingsphere.datasource.ds1.password=root#spring.shardingsphere.datasource.ds1.xxx= # 数据库连接池的其它属性# 数据库连接池类名称spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource# 数据库驱动类名spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver# 数据库 url 连接spring.shardingsphere.datasource.ds2.url=jdbc:mysql://192.168.200.130:3306/order_db_2?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai# 数据库用户名spring.shardingsphere.datasource.ds2.username=root# 数据库密码spring.shardingsphere.datasource.ds2.password=root# 配置数据节点:datanode,数据源.表 t_order是逻辑表,属于t_order_1和t_order_2spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{1..2}.t_order_$->{1..2}# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id# 精确分片算法类名称,用于 = 和 IN。该类需实现 PreciseShardingAlgorithm 接口并提供无参数的构造器spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.itheima.algorithm.MyPreciseShardingAlgorithm4Db# 范围分片算法类名称,用于 BETWEEN,可选。该类需实现 RangeShardingAlgorithm 接口并提供无参数的构造器spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=com.itheima.algorithm.MyRangeShardingAlgorithm4Db# 分表策略spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id# 精确分片算法类名称,用于 = 和 IN。该类需实现 PreciseShardingAlgorithm 接口并提供无参数的构造器spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.itheima.algorithm.MyPreciseShardingAlgorithm4Tb# 范围分片算法类名称,用于 BETWEEN,可选。该类需实现 RangeShardingAlgorithm 接口并提供无参数的构造器spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.range-algorithm-class-name=com.itheima.algorithm.MyRangeShardingAlgorithm4Tb# 是否开启 SQL 显示,默认值: falsespring.shardingsphere.props.sql.show=true
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import org.joda.time.DateTime;
import org.joda.time.format.DateTimeFormat;
import java.util.Collection;
import java.util.Date;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
/**
* @author: hanyaning
* @date: 2022/06/13
* @description:
*/
public class CommonShardingAlgorithm4Tb implements PreciseShardingAlgorithm<Date>, RangeShardingAlgorithm<Date> {
/**
* 精准策略
*
* @param tbNames 分表名称集合
* @param preciseShardingValue 分片键数据的封装
* @return 返回具体某一张物理表
*/
@Override
public String doSharding(Collection<String> tbNames, PreciseShardingValue<Date> preciseShardingValue) {
//获取片键值
final Date value = preciseShardingValue.getValue();
//将value转换成字符串
final String yyyyMM = new DateTime(value).toString(DateTimeFormat.forPattern("yyyyMM"));
//从tbNames获取以yyyyMM结尾的数据源
final Optional<String> first = tbNames.stream().filter(tbName -> tbName.endsWith(yyyyMM)).findFirst();
String actul = "";
//数据如果存在
if (first.isPresent()) {
actul = first.get();
}
return actul;
}
/**
* 范围策略
*
* @param tbNames 分表名称集合
* @param rangeShardingValue 封装分偏键范围查询的对象
* 核心做法:就是将日期比较转化成数字比较
* @return 返回具体某一张物理表
*/
@Override
public Collection<String> doSharding(Collection<String> tbNames, RangeShardingValue<Date> rangeShardingValue) {
//获取日期值
final Range<Date> range = rangeShardingValue.getValueRange();
//判断日期范围是否有下限值
if (range.hasLowerBound()) {
//获取日期的下限值
final Date date = range.lowerEndpoint();
//将date数据转换成yyyyMM格式的字符串
final String yyyyMM = new DateTime(date).toString(DateTimeFormat.forPattern("yyyyMM"));
//核心做法:就是将日期比较转化成数字比较 yyyyMM转成数字进行比较
final Integer intDate = Integer.parseInt(yyyyMM);
//从tbNames集合中获取大于等于intDate的表的名称集合
tbNames = tbNames.stream().filter(tbName -> Integer.parseInt(tbName.substring(tbName.lastIndexOf("_") + 1)) >= intDate).collect(Collectors.toList());
}
//判断日期范围是否有上限值
if (range.hasLowerBound()) {
//获取日期的下限值
final Date date = range.upperEndpoint();
//将date数据转换成yyyyMM格式的字符串
final String yyyyMM = new DateTime(date).toString(DateTimeFormat.forPattern("yyyyMM"));
//核心做法:就是将日期比较转化成数字比较 yyyyMM转成数字进行比较
final Integer intDate = Integer.parseInt(yyyyMM);
//从tbNames集合中获取大于等于intDate的表的名称集合
tbNames = tbNames.stream().filter(tbName -> Integer.parseInt(tbName.substring(tbName.lastIndexOf("_") + 1)) <= intDate).collect(Collectors.toList());
}
return tbNames;
}
}
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import org.joda.time.DateTime;
import org.joda.time.format.DateTimeFormat;
import java.text.DateFormat;
import java.util.Collection;
import java.util.Date;
import java.util.Optional;
import java.util.stream.Collectors;
/**
* @author: hanyaning
* @date: 2022/06/13
* @description:
*/
public class CommonShardingAlgorithm4Db implements PreciseShardingAlgorithm<Date>, RangeShardingAlgorithm<Date> {
/**
* 精准策略
* @param dbNames
* @param preciseShardingValue
* @return
*/
@Override
public String doSharding(Collection<String> dbNames, PreciseShardingValue<Date> preciseShardingValue) {
//获取分片值
Date date = preciseShardingValue.getValue();
//获取年份
String year = new DateTime(date).getYear()+"";
//从dbNames集合中查找以year结尾的数据
final Optional<String> first = dbNames.stream().filter(dbName -> dbName.endsWith(year)).findFirst();
String dbActul= "";
//数据源是否存在
if (first.isPresent()){
dbActul=first.get();
}
return dbActul;
}
/**
* 范围策略
* @param dbNames
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> dbNames, RangeShardingValue<Date> rangeShardingValue) {
//获取分片值
final Range<Date> valueRange = rangeShardingValue.getValueRange();
//判断是否有下限值
if (valueRange.hasLowerBound()) {
Date lowerDate = valueRange.lowerEndpoint();
//获取年份 dsNames--> ds_2021 ds_2022 ds_2023
int year = new DateTime(lowerDate).getYear();//2022
dbNames = dbNames.stream().filter(dsName -> Integer.valueOf(dsName.substring(dsName.lastIndexOf("-") + 1)) >= year)
.collect(Collectors.toList());
}
//2.2 判断是否有上限值
if (valueRange.hasUpperBound()) {
Date upperDate = valueRange.upperEndpoint();
int year = new DateTime(upperDate).getYear();
dbNames= dbNames.stream().filter(dsName->Integer.valueOf(dsName.substring(dsName.lastIndexOf("-")+1))<=year)
.collect(Collectors.toList());
}
return dbNames;
}
}

若有收获,就点个赞吧
0 人点赞
