3.1 FLUME 事物
Put 事务流程:
do Put: 将此数据写入临时缓冲区putList
do commit: 检查channel内存队列是否足够putList的所有数据发送
do rollback: channel内存空间不足, 回滚数据
Take 事务流程:
do take: 将数据取到临时缓冲区takeList中,并将数据发送到HDFS中
do commit: 如果数据全部发送成功,则清除临时缓冲区takeList
do roolback: 数据发送过程中如果出现异常,临时缓冲区takeList将数据还给channel内存队列。这意味着可能takeList的数据发送一半又重新归还给Channel,会出现数据重复。
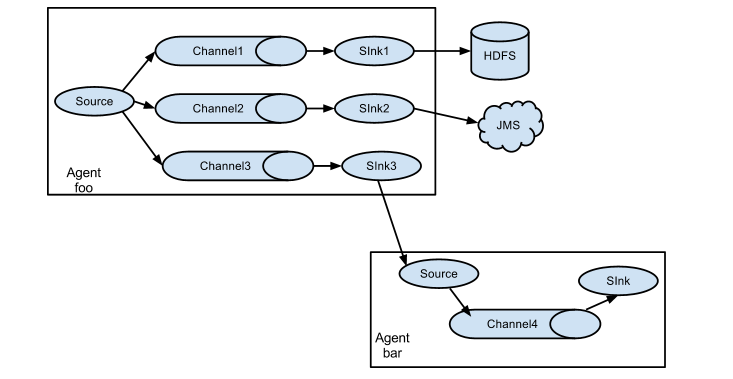
3.2 FLUME AGENT 内部原理
ChannelSelector
ChannelSelector的作用就是选出Event将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
ReplicatingSelector会将同一个Event发往所有的Channel,Multiplexing会根据相应的原则,将不同的Event发往不同的Channel。
SinkProcessor
SinkProcessor共有三种类型,分别是DefaultSinkProcessor、LoadBalancingSinkProcessor(负载均衡)和FailoverSinkProcessor(故障转移)
DefaultSinkProcessor对应的是单个的Sink,LoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink Group,LoadBalancingSinkProcessor可以实现负载均衡的功能,FailoverSinkProcessor可以故障转移,实现高可用。
- Source: 接收数据,将数据封装成event
① channelProcessor : 处理Event
② Interceptor: 拦截器的处理
③ channelSelector:
replicating(复制,给每个channel的数据一样)
multiplexing(多路,根据event的header进行判断决定给到哪个channel)
SinkProcessor: 决定event给哪些个sink
① DefaultSinkProcessor 只支持一个sink
② LoadBalancingSinkProcessor 负载均衡,基于轮询或者随机的规则将event给到sink
③ FailoverSinkProcessor 故障转移,实现高可用.
整体的数据流
Source-> channelProcessor -> [Interceptor -> Interceptor -> Interceptor -> …] -> ChannelSelector -> SinkProcessor -> Sink
3.3 FLUME 拓扑结构
3.3.1

这种模式是将多个flume顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
3.3.2 复制和多路复用
Flume支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink可以选择传送到不同的目的地。
3.3.3负载均衡和故障转移

Flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能。
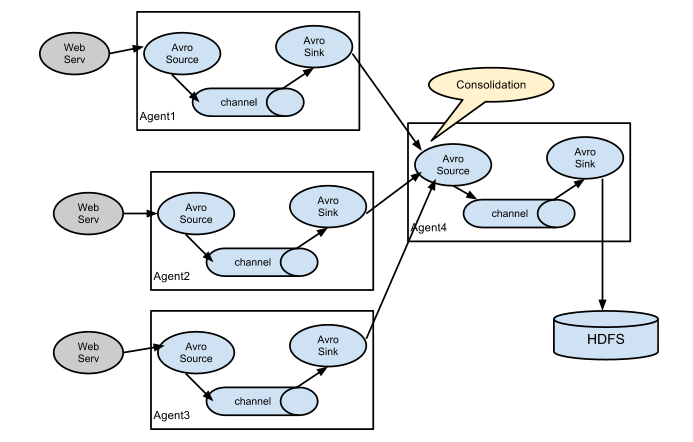
这种模式是我们最常见的,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase等,进行日志分析。
3.4 FLUME 企业开发
3.4.1复制和多路复用
编辑配置文件
# example.conf: A single-node Flume configuration# Name the components on this agenta3.sources = r1a3.sinks = k1a3.channels = c1# Describe/configure the sourcea3.sources = r1a3.sources.r1.type = avroa3.sources.r1.channels = c1a3.sources.r1.bind = 0.0.0.0a3.sources.r1.port = 44444# Describe the sinka3.sinks.k1.type = hdfsa3.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%Sa3.sinks.k1.hdfs.filePrefix = events-a3.sinks.k1.hdfs.round = truea3.sinks.k1.hdfs.roundValue = 10a3.sinks.k1.hdfs.roundUnit = minutea3.sinks.k1.hdfs.fileType = DataStreama3.sinks.k1.hdfs.useLocalTimeStamp = true# Use a channel which buffers events in memorya3.channels.c1.type = memorya3.channels.c1.capacity = 1000a3.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela3.sources.r1.channels = c1a3.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 03-flume-avro-hdfs.conf -n a3 -Dflume.root.logger=INFO,console
# example.conf: A single-node Flume configuration# Name the components on this agenta2.sources = r1a2.sinks = k1a2.channels = c1# Describe/configure the sourcea2.sources = r1a2.sources.r1.type = avroa2.sources.r1.channels = c1a2.sources.r1.bind = 0.0.0.0a2.sources.r1.port = 55555# Describe the sinka2.sinks.k1.type = file_rolla2.sinks.k1.sink.directory = /home/atguigu/flume/file_roll# Use a channel which buffers events in memorya2.channels.c1.type = memorya2.channels.c1.capacity = 1000a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela2.sources.r1.channels = c1a2.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 02-flume-avro-fill-roll.conf -n a2 -Dflume.root.logger=INFO,console
# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1 k2a1.channels = c1 c2# replicating Configurationa1.sources.r1.selector.type = replicatinga1.sources.r1.channels = c1 c2# Describe/configure the sourcea1.sources.r1.type = TAILDIRa1.sources.r1.positionFile = /home/atguigu/flume/taildir/taildir.jsona1.sources.r1.filegroups = f1 f2a1.sources.r1.filegroups.f1 = /home/atguigu/flume/taildir/.*loga1.sources.r1.filegroups.f2 = /home/atguigu/flume/taildir/.*data# Describe the sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop102a1.sinks.k1.port = 44444a1.sinks.k2.type = avroa1.sinks.k2.hostname = hadoop102a1.sinks.k2.port = 55555# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memorya1.channels.c2.capacity = 1000a1.channels.c2.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1 c2a1.sinks.k1.channel = c1a1.sinks.k2.channel = c2
flume-ng agent -c $FLUME_HOME/conf -f 01-flume-taildir-replication.conf -n a1 -Dflume.root.logger=Info,console
3.4.2 负载均衡和故障转移
# example.conf: A single-node Flume configuration# Name the components on this agenta3.sources = r1a3.sinks = k1a3.channels = c1# Describe/configure the sourcea3.sources = r1a3.sources.r1.type = avroa3.sources.r1.channels = c1a3.sources.r1.bind = 0.0.0.0a3.sources.r1.port = 44444# Describe the sinka3.sinks.k1.type = logger# Use a channel which buffers events in memorya3.channels.c1.type = memorya3.channels.c1.capacity = 1000a3.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela3.sources.r1.channels = c1a3.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 03-flume-avro-logger.conf -n a3 -Dflume.root.logger=INFO,console
# example.conf: A single-node Flume configuration# Name the components on this agenta2.sources = r1a2.sinks = k1a2.channels = c1# Describe/configure the sourcea2.sources = r1a2.sources.r1.type = avroa2.sources.r1.channels = c1a2.sources.r1.bind = 0.0.0.0a2.sources.r1.port = 55555# Describe the sinka2.sinks.k1.type = logger# Use a channel which buffers events in memorya2.channels.c1.type = memorya2.channels.c1.capacity = 1000a2.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela2.sources.r1.channels = c1a2.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 02-flume-avro-logger.conf -n a2 -Dflume.root.logger=INFO,console
# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1 k2a1.channels = c1# sink processor k2的优先级大于k1,当k2宕机重启成功后,仍会选择k2进行数据发送a1.sinkgroups = g1a1.sinkgroups.g1.sinks = k1 k2a1.sinkgroups.g1.processor.type = failovera1.sinkgroups.g1.processor.priority.k1 = 5a1.sinkgroups.g1.processor.priority.k2 = 10a1.sinkgroups.g1.processor.type = load_balancea1.sinkgroups.g1.processor.backoff = truea1.sinkgroups.g1.processor.selector = random# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 6666# Describe the sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop102a1.sinks.k1.port = 44444a1.sinks.k2.type = avroa1.sinks.k2.hostname = hadoop102a1.sinks.k2.port = 55555# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1a1.sinks.k2.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 01-flume-netcat-failover.conf -n a1 -Dflume.root.logger=Info,console
3.4.3 FLUME 聚合
# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 44444# Describe the sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop102a1.sinks.k1.port = 55555# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 03-flume-netcat-avro.conf -n a1 -Dflume.root.logger=INFO,console
# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 44444# Describe the sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop102a1.sinks.k1.port = 55555# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -f 02-flume-exec-avro.conf -n a1 -Dflume.root.logger=INFO,console
# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1 r2a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources = r1 r2a1.sources.r1.type = avroa1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 55555a1.sources.r2.type = avroa1.sources.r2.bind = 0.0.0.0a1.sources.r2.port = 44444# Describe the sinka1.sinks.k1.type = logger# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sources.r2.channels = c1a1.sinks.k1.channel = c1
flume-ng agent -c $FLUME_HOME/conf -n a1 -f 01-flume-avro-logger.conf -Dflume.root.logger=INlsFO,console
3.5 自定义 Interceptor
3.5 FLUME 数据流监控
监控Flume写入写出两个事务的触发次数和成功次数

若有收获,就点个赞吧
0 人点赞
