效果
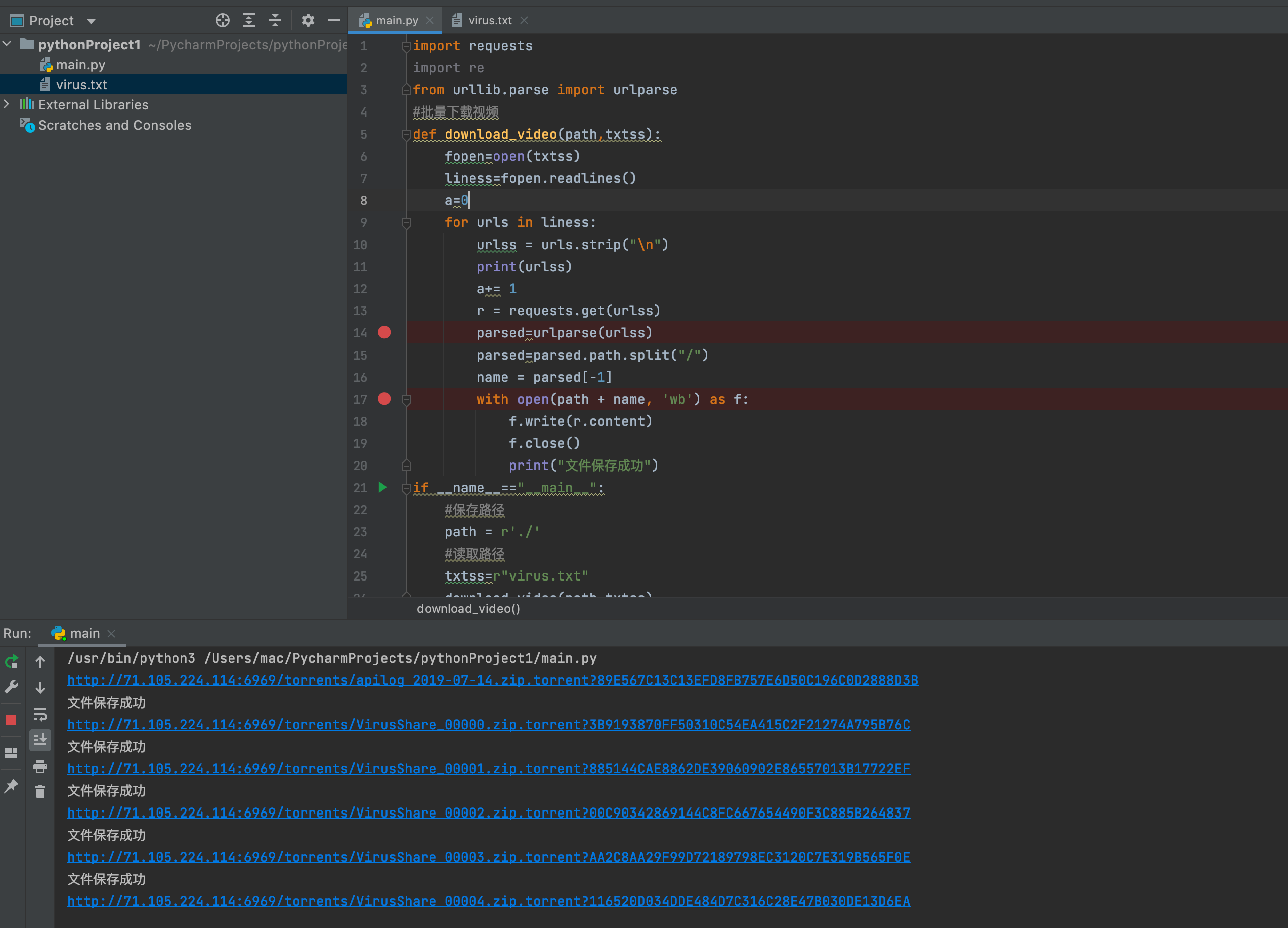
代码
import requestsimport refrom urllib.parse import urlparse#批量下载视频def download_video(path,txtss):fopen=open(txtss)liness=fopen.readlines()a=0for urls in liness:urlss = urls.strip("\n")print(urlss)a+= 1r = requests.get(urlss)parsed=urlparse(urlss)parsed=parsed.path.split("/")name = parsed[-1]with open(path + name, 'wb') as f:f.write(r.content)f.close()print("文件保存成功")if __name__=="__main__":#保存路径path = r'./'#读取路径txtss=r"virus.txt"download_video(path,txtss)
文件

若有收获,就点个赞吧
0 人点赞
