原贴:https://blog.csdn.net/weixin_41779359/article/details/86162674
由于年代久远,代码已经不能使用,目前实现恢复之前功能另加爬取图片地址
登录之后通过浏览器复制cookie
import reimport timeimport requestsfrom urllib import requestimport xlwtfrom lxml import etreedef get_page(url):try:headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36","cookie": "_abtest_userid=32f3b780-d932-42d8-bb4e-c2a4b09d2bae; ibulanguage=CN; ibulocale=zh_cn; cookiePricesDisplayed=CNY; IBU_TRANCE_LOG_P=27275857214; _RF1=222.128.58.224; _RSG=Tfq6O3wWMy2JZGT7K1re29; _RDG=28405636752cde207800d434a21e92c6f4; _RGUID=2f1683a0-d81b-4a5d-90a8-d415077508d3; _ga=GA1.2.1586531925.1613975034; _gid=GA1.2.1164383882.1613975034; Session=SmartLinkCode=csdn&SmartLinkKeyWord=&SmartLinkQuary=_UTF.&SmartLinkHost=link.csdn.net&SmartLinkLanguage=zh; MKT_CKID=1613975034222.o0wmp.s437; MKT_CKID_LMT=1613975034223; MKT_Pagesource=PC; _ctm_t=ctrip; Customer=HAL=ctrip_cn; StartCity_Pkg=PkgStartCity=2; GUID=09031125311912901733; librauuid=5oZmuXbMsAAGCg4L; cticket=163D247556DA45CD15D82927349EEE19E23CB036E730209A59D0D604E3D69074; AHeadUserInfo=VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=1; ticket_ctrip=bJ9RlCHVwlu1ZjyusRi+ypZ7X2r4+yojXN5UTMe2Bf1JKH8i3Drs9Pzu3Z0AIlCxJBdgVTo45f9ZEaRO6asDQ78Hql76TCWs5OAf2oQ328Lso/sAtvnT4OSfHdvLLyBXWl2HYpF5Gnt1c1IQD9AhgqrxC5RmxSfCWuwWVV25lURAvaLBnG9RecjqZK3FDi/WH3p8zJvY7ctaIHyjdYCuzOpiGNEwPi7N2rPl2Zkx/UxubtL5Nmpg8T0pd1QaKBgrpusXeDep2itU5ysDcocu/B/LA7TmK+JPoovNZWC5bi+1NFXVPiWPwg==; DUID=u=54C3F49AA58CC4ACE398230C18CC817FFC6B7346868BC43A98766B342D31186A&v=0; IsNonUser=F; IsPersonalizedLogin=F; UUID=59B664D9059D49D0A748DD0EC78E7926; _bfs=1.9; _bfa=1.1613975030415.2jx4dg.1.1613975030415.1613977027656.2.17; hotelhst=1164390341; _uetsid=87d4286074d611ebb15f89f05388a1db; _uetvid=87d44e7074d611eb987f693b286d26c4; _bfi=p1%3D102002%26p2%3D100101991%26v1%3D17%26v2%3D16; _jzqco=%7C%7C%7C%7C1613975034459%7C1.786017307.1613975034235.1613978187508.1613978198001.1613978187508.1613978198001.0.0.0.14.14; __zpspc=9.2.1613977031.1613978198.7%233%7Clink.csdn.net%7C%7C%7C%7C%23; appFloatCnt=12"}req = request.Request(url=url, headers=headers)rsq = request.urlopen(req)r = rsq.read().decode()# r=requests.get(url,headers=headers)# r.raise_for_status() #这行代码的作用是如果请求失败,那就执行except# r.encoding=r.apparent_encoding #防止出现乱码现象return r #将返回对象的文本作为返回值except Exception as e: #找出失败的原因print(e)basic_url='http://hotels.ctrip.com/hotel/beijing1/p'urls=[basic_url + str(i) for i in range(1,10)] #所有url都urls里。def get_info(page):names = re.findall(r'"name font-bold">(.*?)</span>', page, re.S) # 酒店名称locations = re.findall(r'<span class="position">(.*?)</span>', page, re.S) # 酒店地址for i in range(len(locations)): # 清洗数据if '】' in locations[i]:locations[i] = locations[i].split('】')[1]scores = re.findall(r'"real font-bold">(.*?)</span>', page, re.S) # 酒店评分prices = re.findall(r'"real-price font-bold">(.*?)</span>', page, re.S) # 酒店价格#recommends = re.findall(r'009933.*?>(.*?)</span>用户推荐', page, re.S) # 推荐比例peoples = re.findall(r'class="count"><a>(\d+).*?</a>', page, re.S) # 推荐人数"""strbb = b'bbbbbb'with open("xiecheng".replace('/', '_') + ".html", "wb") as f:# 写文件用bytes而不是str,所以要转码page=bytes(page, encoding = "utf8")f.write(page)with open('xiecheng.html', 'r', encoding='utf-8') as f:content = f.read()"""pattern = re.compile(r'//dimg04.c-ctrip.com/images/.*?.jpg') # 酒店的图片地址imgs = re.findall(pattern,page)for name, location, score, img, people in zip(names, locations, scores, imgs, peoples):data = {} # 将每个酒店的信息保存为字典形式data['name'] = namedata['score'] = score#data['price'] = price# data['recommend_ratio'] = recommenddata['img'] = imgdata['people_num'] = peopledata['location'] = locationprint(data)yield dataif __name__ == '__main__':DATA = [] # 建一个空列表,为了储存所有提取出来的酒店数据for i in range(1, 2):url = basic_url + str(i)page = get_page(url)print('request data from:' + url) # 主要是为了显示进度time.sleep(1) # 每请求一次服务器就暂停50s,请求数据太快会被服务器识别为爬虫datas = get_info(page)for data in datas:DATA.append(data) # 将数据添加到DATA列表里,为下一步保存数据使用f = xlwt.Workbook(encoding='utf-8')sheet01 = f.add_sheet(u'sheet1', cell_overwrite_ok=True)sheet01.write(0, 0, 'name') # 第一行第一列sheet01.write(0, 1, 'score')#sheet01.write(0, 2, 'price')#sheet01.write(0, 3, 'recommand_ratio')sheet01.write(0, 3, 'img')sheet01.write(0, 4, 'people_num')sheet01.write(0, 5, 'location')# 写内容for i in range(len(DATA)):sheet01.write(i + 1, 0, DATA[i]['name'])sheet01.write(i + 1, 1, DATA[i]['score'])#sheet01.write(i + 1, 2, DATA[i]['price'])sheet01.write(i + 1, 3, DATA[i]['img'])sheet01.write(i + 1, 4, DATA[i]['people_num'])sheet01.write(i + 1, 5, DATA[i]['location'])print('$', end='')f.save(u'携程酒店2.xls')
由于携程的反爬机制过于恶心,无法得到价格,甚至浏览器查看页面源代码都没有价格信息,未解决
爬取多页更改爬取的页数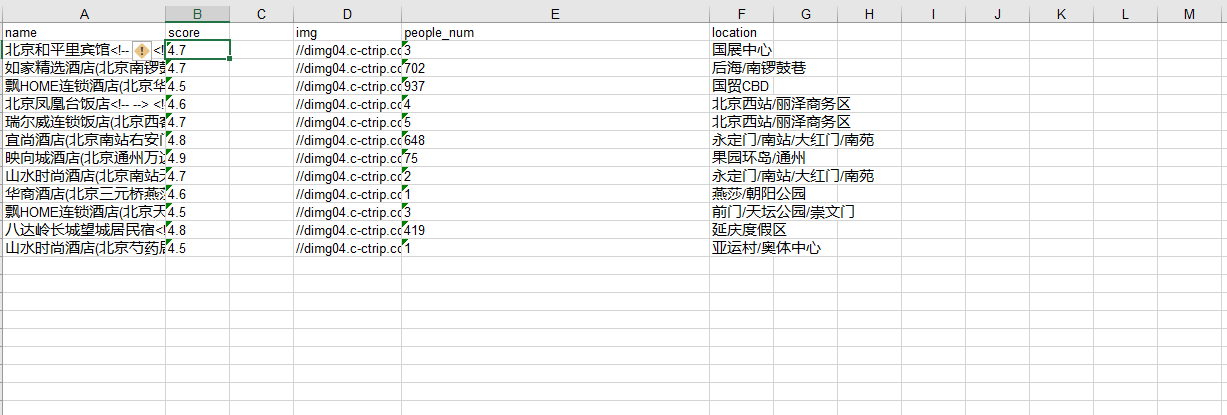
思路:python 如何爬取审查元素中Elements里有的元素,而源代码里没有的标签?
https://blog.csdn.net/weixin_41931602/article/details/81711190

若有收获,就点个赞吧
0 人点赞
