主要知识点学习
- 串的基本概念及其抽象数据类型描述
- 串的存储结构
- 串的基本操作实现
- 数组的定义、操作和存储结构
- 矩阵的压缩存储
一、 串
字符串(串): 是由n(n>=0)各字符组成的有限序列
1. 串的抽象数据类型
public interface IString {void clear();//置空boolean isEmpty();//判空int length();//长度char charAt(int index);//获取指定下标的字符IString substring(int begin,int end);//截取子串IString insert(int offset,IString str);//插入IString delete(int begin,int end);//删除IString concat(IString str);//串连接int compareTo(IString str) ;//比较int indexOf(IString str,int begin);//子串定位}
2. 顺序串及其实现
- 存储结构示意图

- 求子串操作
/*** 截取子串** @param begin 开始索引* @param end 结束索引* @return*/@Overridepublic IString substring(int begin, int end) {//1 判断开始截取位置是否合法if (begin < 0)throw new StringIndexOutOfBoundsException("起始位置不能小于0");//2 判断结束截取位置是否合法if (end > this.length)throw new StringIndexOutOfBoundsException("结束位置不能大于串的当前长度: end:" + end + " length:" + length);//3. 开始位置不能大于结束位置if (begin > end)throw new StringIndexOutOfBoundsException("开始位置不能大于结束位置");if (begin == 0 && end == this.length) {return new SeqString(this);} else {//创建截取的字符数组char[] buffer = new char[end - begin];//复制字符for (int i = begin; i < end; i++) {buffer[i] = this.values[i];}return new SeqString(buffer);}}
- 插入操作
public IString insert(int offset, IString str) {//判断偏移量是否合法if (offset < 0 || offset > this.length)throw new StringIndexOutOfBoundsException("插入位置不合法!");//获取插入串的长度int len = str.length();//计算所需的长度int newCount = this.length + len;//如果所需的长度大于串数组的容量if (newCount > this.values.length) {//扩充容量allocate(newCount);}//为插入的串腾出位置(往后移动len个位置)for (int i = this.length - 1; i >= 0; i--) {this.values[len + i] = this.values[i];}//复制for (int i = 0; i < len; i++) {this.values[offset + i] = str.charAt(i);}this.length = newCount;return this;}
- 删除操作
public IString delete(int begin, int end) {//1 判断开始截取位置是否合法if (begin < 0)throw new StringIndexOutOfBoundsException("起始位置不能小于0");//2 判断结束截取位置是否合法if (end > this.length)throw new StringIndexOutOfBoundsException("结束位置不能大于串的当前长度: end:" + end + " length:" + length);//3. 开始位置不能大于结束位置if (begin > end)throw new StringIndexOutOfBoundsException("开始位置不能大于结束位置");for (int i = 0; i < this.length - end; i++) {this.values[begin + i] = this.values[end + i];}this.length = this.length - (end - begin);return this;}
- 模式匹配操作
一、Brute-Force模式匹配算法
- 操作过程示意图(网上搜索所得)
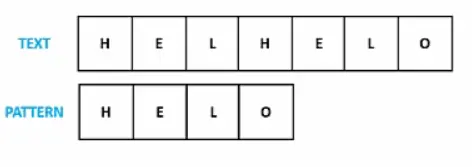
- 代码实现
public int indexOf_BF(SeqString text, SeqString p, int begin) {//判断开始匹配的位置是否合法if (begin < 0 || begin > text.length - 1)throw new StringIndexOutOfBoundsException("判断开始匹配的位置错误: begin=" + begin);//标识主串text中的位置int i = begin;//标识子串p中的位置int j = 0;//主串的长度int textLen = text.length;//子串长度int pLen = p.length;while (i < textLen && j < pLen) {//匹配字符//如果匹配,则继续下一个字符if (text.charAt(i) == p.charAt(j)) {++i;++j;} else {//如果匹配不成功,则退回上次匹配首位的下一位i = i - j + 1;j = 0;}}//如果匹配成功,返回子串序号if (j >= pLen) {return i - pLen;}return -1;}
- 时间复制度分析
二、KMP(Knuth-Morris-Pratt)模式匹配算法
示意图(图来自)

阅读文章
- 说明
- Brute-Force算法无论在哪里失败,每次都从成功匹配的下一个位置开始从新匹配,非常浪费时间, 而KMP算法减少了不必要的回溯,提升了效率。
- 那么现在的问题是,如何利用上次匹配失败的信息,推断出下一次开始匹配的位置?
- 可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)
- 针对搜索词: ABCDABD计算部分匹配表
- 相关公式
- 对应的部分匹配值 = 前缀字符 和 后缀字符 的 最长共有元素的长度
- 对应的部分匹配值 = 前缀字符 和 后缀字符 的 最长共有元素的长度
- 匹配失败移动的距离 = 已匹配的字符数 - 对应的部分匹配值
最长共有元素的长度(对于:ABCDABD)
| 已匹配字符 | 前缀 | 后缀 | 共有长度 |
|---|---|---|---|
| A | NULL | NULL | 0 |
| AB | [A] | [B] | 0 |
| ABC | [A,AB] | [BC,C] | 0 |
| ABCD | [A,AB,ABC] | [BCD,CD,D] | 0 |
| ABCDA | [A,AB,ABC,ABCD] | [BCDA,CDA,DA,A] | 1 {A} |
| ABCDAB | [A,AB,ABC,ABCD,ABCDA] | [BCDAB,CDAB,DAB,AB,B] | 2 {AB} |
| ABCDABD | [A,AB,ABC,ABCD, ABCDA,ABCDAB] |
[BCDABD,CDABD,DABD,ABD,BD,D] | 0 |
- 匹配表 | 搜索词 | A | B | C | D | A | B | D | | —- | —- | —- | —- | —- | —- | —- | —- | | 部分匹配值(Match Value) | 0 | 0 | 0 | 0 | 1 | 2 | 0 | | 移动距离(Move distance) | 1 | 2 | 3 | 4 | 4 | 4 | 7 |
- 部分匹配表的代码实现
- 代码实现
private int[] getNext(SeqString p) {//匹配串的长度int patternLength = p.length;//匹配表;用于匹配过程中,跳过不需要再进行匹配的字符int partial_match[] = new int[patternLength];//部分匹配表中的第一个赋值为0,//因为只有一个已匹配字符,它没有前缀和后缀partial_match[0] = 0;//前后缀共有元素的长度(即前缀字符的最后一个下标)int length = 0;//已匹配字符最后的下标(后缀字符的最后一个下标)int currentIndex = 1;while (currentIndex < patternLength) {if (p.charAt(currentIndex) == p.charAt(length)) {//发现匹配//共有长度加一length = length + 1;//记录跳过字符数partial_match[currentIndex] = length;currentIndex = currentIndex + 1;} else {//没有匹配if (length != 0) {//以AAACAAAA为例子 , 个人理解//假设当前匹配的字符串为 AAAC , 前缀为AAA,AA,A 后缀为 AAC,AC,C//则length = 2 (是当串为AAA时得到的最长前后缀公共字符长度), currentIndex = 3, 所以前缀AAA != AAC//那么length = partial_match[1] = 1, AA != AC//length = partial_match[0] = 0, A!=Clength = partial_match[length - 1];} else {//length ==0 ,表示串AAAC没有最长前后缀公共字符//赋值为0partial_match[currentIndex] = 0;//继续匹配下一个串 AAACAcurrentIndex = currentIndex + 1;}}}return partial_match;}
- KMP算法实现
private int index_KMP(SeqString text, SeqString p) {int textLength = text.length;int patternLength = p.length;//计算部分匹配表int partial_match[] = getNext(p);int currentIndexText = 0;int currentIndexPattern = 0;while (currentIndexText < textLength && currentIndexPattern < patternLength) {if (text.charAt(currentIndexText) == p.charAt(currentIndexPattern)) {//匹配//转到下一个字符currentIndexPattern = currentIndexPattern + 1;currentIndexText = currentIndexText + 1;} else {if (currentIndexPattern != 0) {// if no match and currentIndexPattern is not zero we will// fallback to values in partial match table// for match of largest common proper suffix and prefix// till currentIndexPattern-1currentIndexPattern = partial_match[currentIndexPattern - 1];} else {// if currentIndexPattern is zero// we increment currentIndexText for fresh matchcurrentIndexText = currentIndexText + 1;}}}//判断已匹配串的下标currentIndexPattern 是否大于 模式串的长度if (currentIndexPattern >= patternLength) {//是,则返回匹配模式串的开始位置return currentIndexText - patternLength;}return -1;}
二、数组
1. 概念
- 数组: 是n(n>=1)个具有相同类型的数据元素a0,a1,a2,a3,…,an-1构成的有限序列
- 一维数组:可以看成一个顺序存储结构的线性表
- 二维数组(矩阵):其数据元素为一维数组的线性表


若有收获,就点个赞吧
0 人点赞
