单选题
1/19.
下列关于Spark的描述,错误的是哪一项?
- A.Spark最初由美国加州伯克利大学(UCBerkeley)的AMP实验室于2009年开发
- B.Spark在2014年打破了Hadoop保持的基准排序纪录
- C.Spark用十分之一的计算资源,获得了比Hadoop快3倍的速度
- D.Spark运行模式单一

2/19.
下列关于Spark的描述,错误的是哪一项?
- A.使用DAG执行引擎以支持循环数据流与内存计算析
- B.可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中
- C.支持使用Scala、Java、Python和R语言进行编程,但是不可以通过Spark Shell进行交互式编程
- D.可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中

3/19.
下列关于Scala特性的描述,错误的是哪一项?
- A.Scala语法复杂,但是能提供优雅的API计算
- B.Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统
- C.Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中
- D.Scala是Spark的主要编程语言

4/19.
下列说法哪项有误?
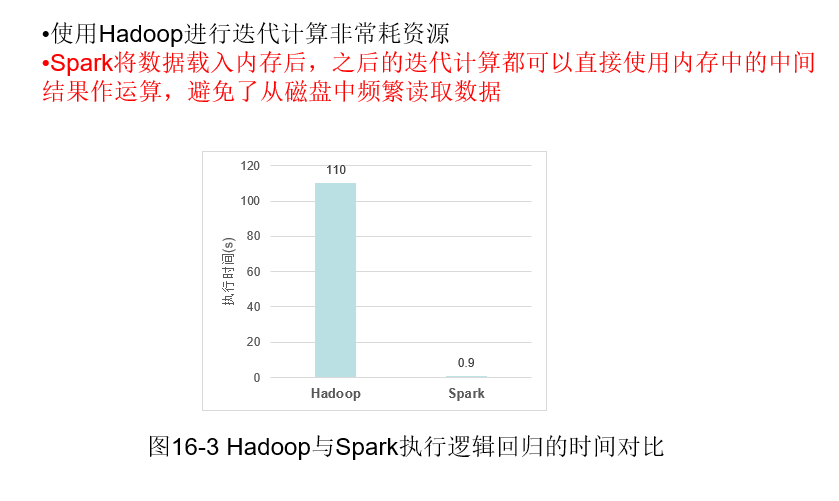
- A.相对于Spark来说,使用Hadoop进行迭代计算非常耗资源
- B.Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据
- C.Hadoop的设计遵循“一个软件栈满足不同应用场景”的理念
- D.Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案

5/19.
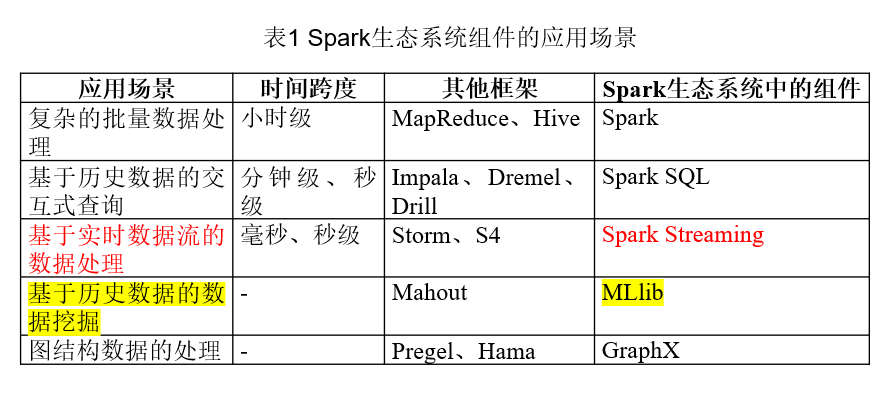
在Spark生态系统组件的应用场景中,下列哪项说法是错误的?
- A.Spark应用在复杂的批量数据处理
- B.Spark SQL是基于历史数据的交互式查询
- C.Spark Streaming是基于历史数据的数据挖掘
- D.GraphX是图结构数据的处理
6/19.
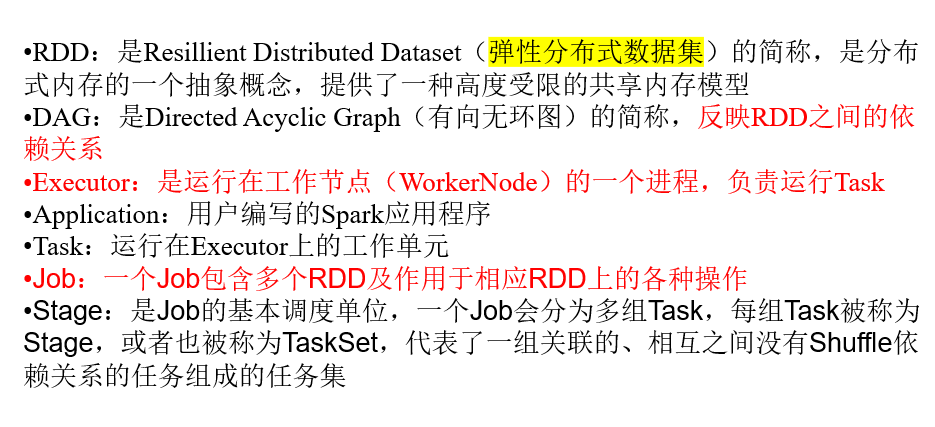
下列说法错误的是?
- A.RDD(Resillient Distributed Dataset)是运行在工作节点(WorkerNode)的一个进程,负责运行Task
- B.Application是用户编写的Spark应用程序
- C.一个Job包含多个RDD及作用于相应RDD上的各种操作
- D.Directed Acyclic Graph反映RDD之间的依赖关系
7/19.
下列关于RDD说法,描述有误的是?
- A.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合
- B.每个RDD可分成多个分区,每个分区就是一个数据集片段
- C.RDD是可以直接修改的
- D.RDD提供了一种高度受限的共享内存模型

8/19.
Spark生态系统组件Spark Streaming的应用场景是?
- A.基于历史数据的数据挖掘 MLlib
- B.图结构数据的处理GraphX
- C.基于历史数据的交互式查询Spark SQL
- D.基于实时数据流的数据处理
9/19.
Spark生态系统组件MLlib的应用场景是?

11/19.
Scala具有以下哪几个主要特点?
- A.Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),提高程序开发效率
- B.Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中
- C.Scala具备强大的并发性,支持函数式编程
- D.Scala可以更好地支持分布式系统

12/19.
下列哪些选项属于Hadoop的缺点?
- A.表达能力有限
- B.磁盘IO开销大
- C.延迟高
- D.在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务

13/19.
下列说法中,哪些选项描述正确?
- A.Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题
- B.Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作
- C.Hadoop MapReduce编程模型比Spark更灵活
- D.Hadoop MapReduce提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高

14/19.
在实际应用中,大数据处理主要包括以下哪三个类型?
- A.复杂的批量数据处理:通常时间跨度在数十分钟到数小时之间
- B.基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间
- C.基于实时数据流的数据处理:通常时间跨度在数十秒到数分钟之间
- D.基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间

15/19.
在实际应用中,当采用多种计算架构来满足不同应用场景需求时,大数据处理难免会带来哪些问题?
- A.不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
- B.不同的软件需要不同的开发和维护团队
- C.需要较高的使用成本
- D.比较难以对同一个集群中的各个系统进行统一的资源协调和分配

16/19.
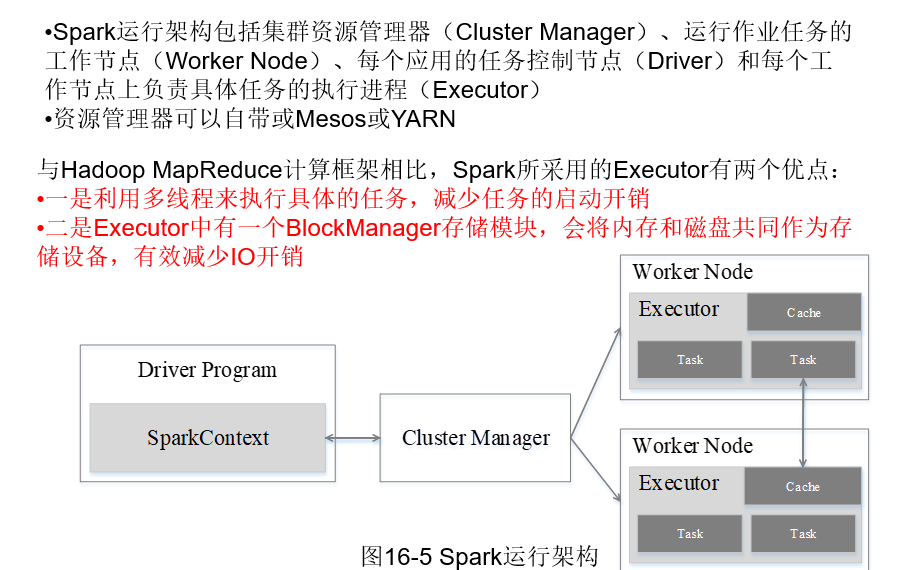
与Hadoop MapReduce计算框架相比,Spark所采用的Executor具有哪些优点?
- A.利用多线程来执行具体的任务,减少任务的启动开销
- B.Executor中有一个BlockManager存储模块,有效减少IO开销
- C.提供了一种高度受限的共享内存模型
- D.不同场景之间输入输出数据能做到无缝共享
17/19.
Spark运行架构具有以下哪些特点?
- A.每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留
- B.Executor进程以多线程的方式运行Task
- C.Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可
- D.Task采用了数据本地性和推测执行等优化机制

18/19.
Spark采用RDD以后能够实现高效计算的原因主要在于?
- A.高效的容错性
- B.中间结果持久化到内存,数据在内存中的多个
- C.存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
- D.采用数据复制实现容错

19/19.
Spark支持哪三种不同类型的部署方式?
- A.Standalone(类似于MapReduce1.0,slot为资源分配单位)
- B.Spark on Mesos(和Spark有血缘关系,更好支持Mesos)
- C.Spark on YARN
- D.Spark on HDFS


若有收获,就点个赞吧
0 人点赞
