单选题
1/17.
下列哪个不属于Hadoop的特性?
- A.成本高
- B.高可靠性
- C.高容错性
- D.运行在Linux平台上

2/17.
Hadoop框架中最核心的设计是什么?
- A.为海量数据提供存储的HDFS和对数据进行计算的MapReduce
- B.提供整个HDFS文件系统的NameSpace(命名空间)管理、块管理等所有服务
- C.Hadoop不仅可以运行在企业内部的集群中,也可以运行在云计算环境中
- D.Hadoop被视为事实上的大数据处理标准

3/17.
在一个基本的Hadoop集群中,DataNode主要负责什么?
- A.负责执行由JobTracker指派的任务
- B.协调数据计算任务
- C.负责协调集群中的数据存储
- D.存储被拆分的数据块
4/17.
Hadoop最初是由谁创建的?
- A.Lucene
- B.Doug Cutting
- C.Apache
- D.MapReduce

5/17.
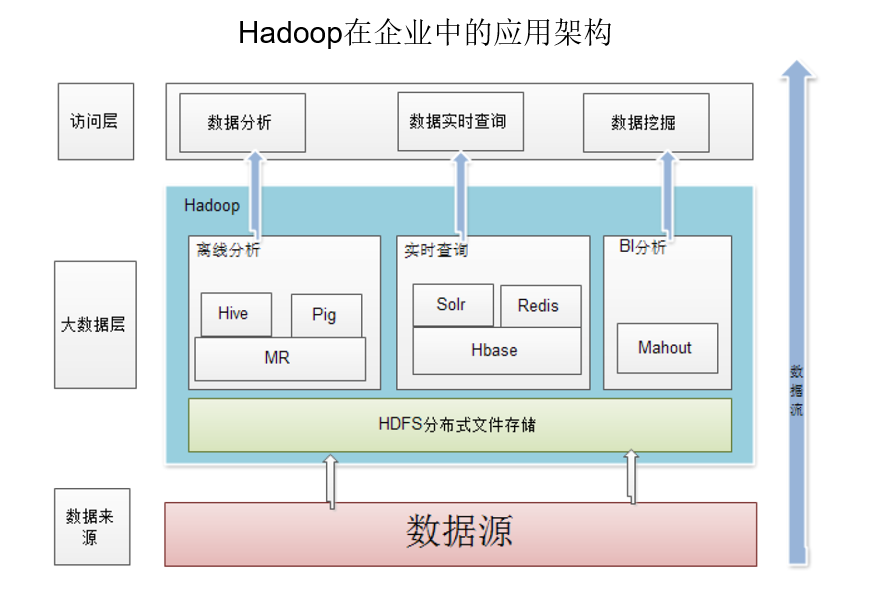
下列哪一个不属于Hadoop的大数据层的功能?
- A.数据挖掘
- B.离线分析
- C.实时计算
- D.BI分析
PS:参考答案勘误
6/17.
在一个基本的Hadoop集群中,SecondaryNameNode主要负责什么?
- A.帮助NameNode收集文件系统运行的状态信息
- B.负责执行由JobTracker指派的任务 TaskTracker
- C.协调数据计算任务 JobTracker
- D.负责协调集群中的数据存储 NameNode
**7/17.
下面哪一项不是Hadoop的特性?
- A.可扩展性高
- B.只支持少数几种编程语言
- C.成本低
- D.能在linux上运行

8/17.
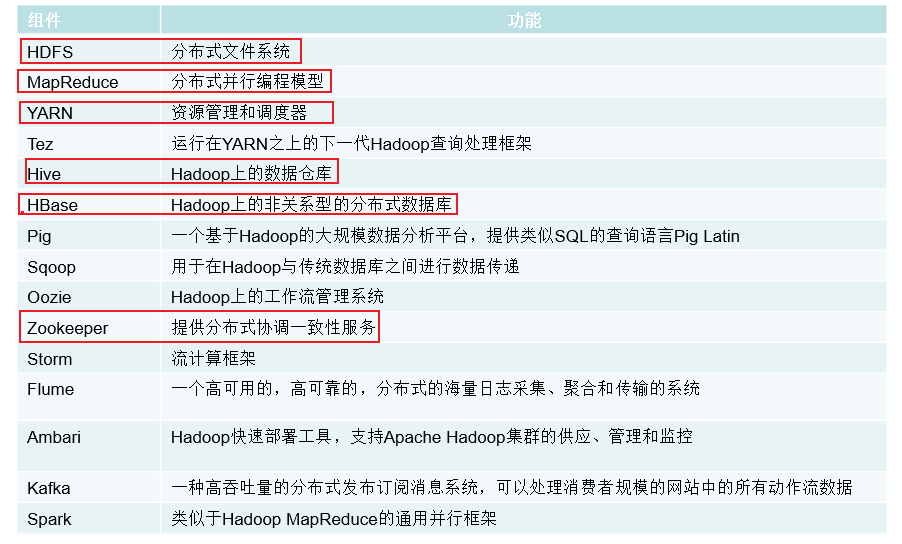
在Hadoop项目结构中,HDFS指的是什么?
- A.分布式文件系统
- B.分布式并行编程模型 MapReduce
- C.资源管理和调度器 YARN
- D.Hadoop上的数据仓库 Hive

9/17.
在Hadoop项目结构中,MapReduce指的是什么?
- A.分布式并行编程模型 MapReduce
- B.流计算框架 Storm
- C.Hadoop上的工作流管理系统 Oozie
- D.提供分布式协调一致性服务 Zookeeper
10/17.
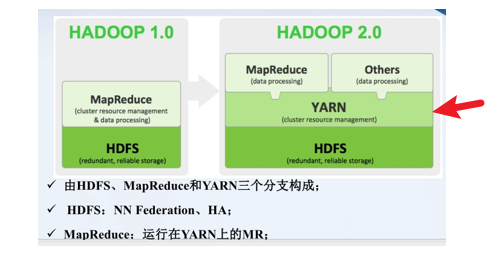
下面哪个不是Hadoop1.0的组件:
- A.HDFS
- B.MapReduce
- C.YARN
- D.NameNode和DataNode
多选题
11/17.
Hadoop的特性包括哪些?
- A.高可扩展性
- B.支持多种编程语言
- C.成本低
- D.运行在Linux平台上

12/17.
下面哪个是Hadoop2.0的组件?
- A.ResourceManager
- B.JobTracker
- C.TaskTracker
- D.NodeManage
PS:未找到解析
13/17.
一个基本的Hadoop集群中的节点主要包括什么?
- A.DataNode:存储被拆分的数据块
- B.JobTracker:协调数据计算任务
- C.TaskTracker:负责执行由JobTracker指派的任务
- D.SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
14/17.
下列关于Hadoop的描述,哪些是正确的?
- A.为用户提供了系统底层细节透明的分布式基础架构
- B.具有很好的跨平台特性
- C.可以部署在廉价的计算机集群中
- D.曾经被公认为行业大数据标准开源软件

15/17.
Hadoop集群的整体性能主要受到什么因素影响?
- A.CPU性能
- B.内存
- C.网络
- D.存储容量
Hadoop集群的整体性能取决于CPU、内存、网络以及存储之间的性能平衡。
16/17.
下列关于Hadoop的描述,哪些是错误的?
- A.只能支持一种编程语言
- B.具有较差的跨平台特性
- C.可以部署在廉价的计算机集群中
- D.曾经被公认为行业大数据标准开源软件


17/17.
下列哪一项不属于Hadoop的特性?
- A.较低可扩展性
- B.只支持java语言
- C.成本低
- D.运行在Linux平台上

总结
•Hadoop框架中最核心的设计是为海量数据提供存储的HDFS和对数据进行计算的MapReduce
•MapReduce的作业主要包括:
(1)从磁盘或从网络读取数据,即IO密集工作;
(2)计算数据,即CPU密集工作
•Hadoop集群的整体性能取决于CPU、内存、网络以及存储之间的性能平衡。因此运营团队在选择机器配置时要针对不同的工作节点选择合适硬件类型
•一个基本的Hadoop集群中的节点主要有
•NameNode:负责协调集群中的数据存储
•DataNode:存储被拆分的数据块
•JobTracker:协调数据计算任务
•TaskTracker:负责执行由JobTracker指派的任务
•SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息

若有收获,就点个赞吧
0 人点赞
