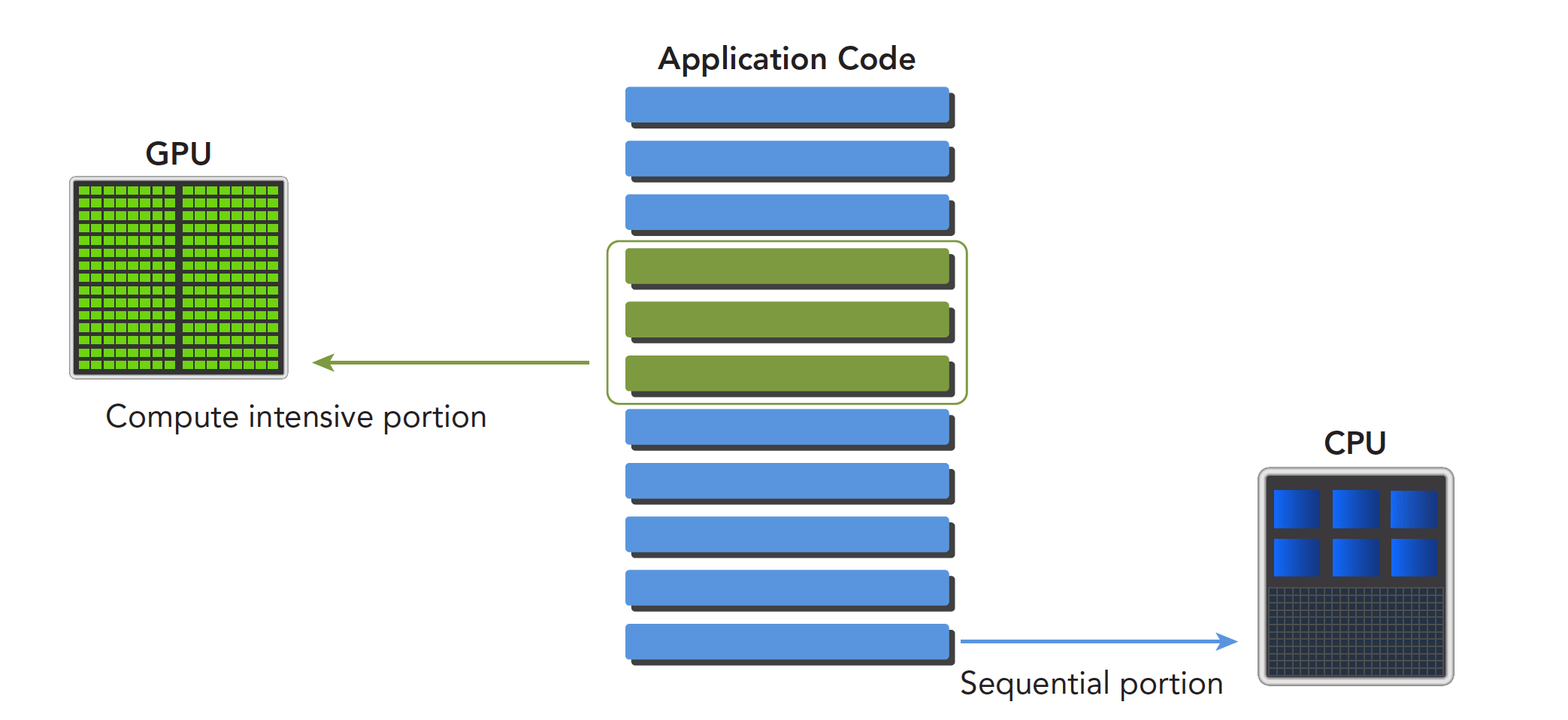
一、异构计算与CUDA
(一)异构计算
GPU本来的任务是做图形计算控制显示器,对用户不可编程 有hacker开始想办法给GPU编程,来帮助他们完成规模较大的运算,于是他们研究着色语言或者图形处理原语来和GPU对话 黄老板发现了这个是个新的功能啊,然后就让人开发了一套平台,CUDA,然后深度学习火了,顺带着,CUDA也火到爆炸x86 CPU+GPU的这种异构应该是最常见的,也有CPU+FPGA,CPU+DSP等各种各样的组合,CPU+GPU在每个笔记本或者台式机上都能找到。当然超级计算机大部分也采用异构计算的方式来提高吞吐量。 异构架构虽然比传统的同构架构运算量更大,但是其应用复杂度更高,因为要在两个设备上进行计算,控制,传输,这些都需要人为干预,而同构的架构下,硬件部分自己完成控制,不需要人为设计
(二)异构架构
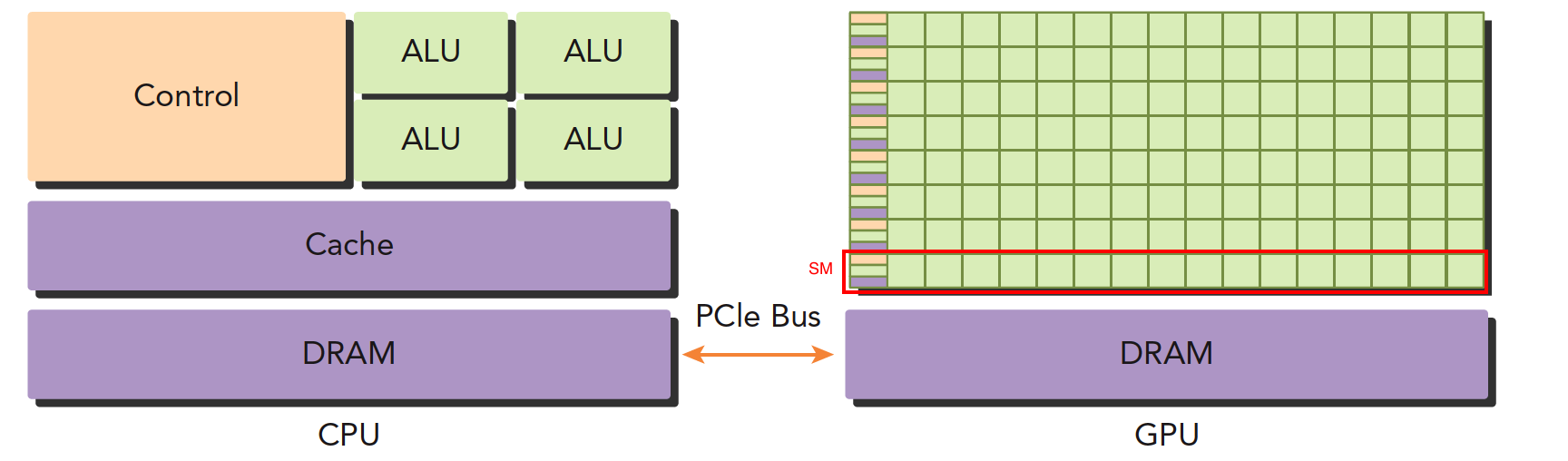
(1)CPU VS GPU
- 左图:一个四核CPU一般有四个ALU,ALU是完成逻辑计算的核心,也是我们平时说四核八核的核,控制单元,缓存也在片上,DRAM是内存,一般不在片上,CPU通过总线访问内存。
- 右图:GPU,绿色小方块是ALU,我们注意红色框内的部分SM,这一组ALU公用一个Control单元和Cache,这个部分相当于一个完整的多核CPU,但是不同的是ALU多了,control部分变小,可见计算能力提升了,控制能力减弱了,所以对于控制(逻辑)复杂的程序,一个GPU的SM是没办法和CPU比较的,但是对了逻辑简单,数据量大的任务,GPU更搞笑,并且,注意,一个GPU有好多个SM,而且越来越多。
低并行逻辑复杂的程序适合用CPU 高并行逻辑简单的大数据计算适合GPU
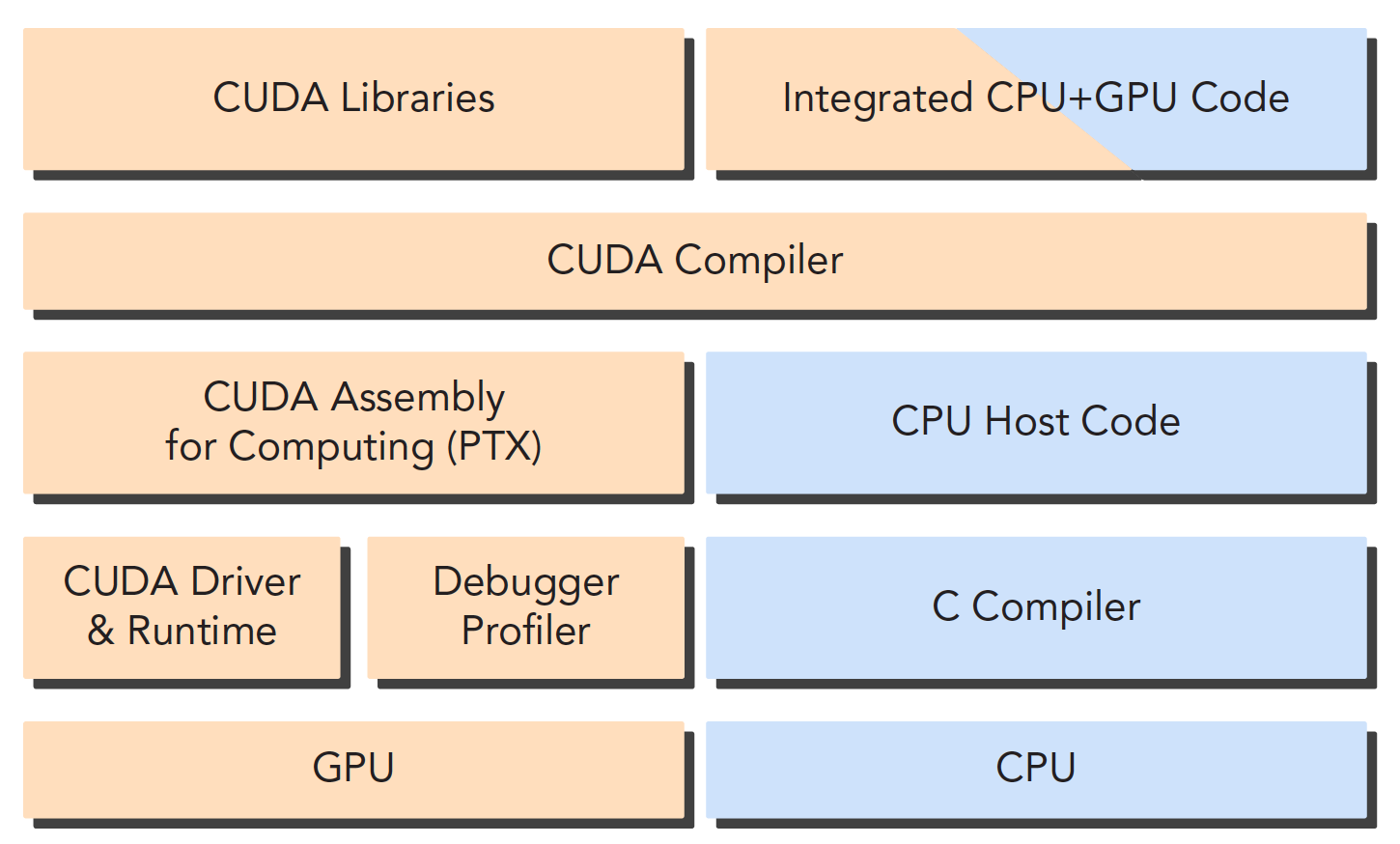
(2)主机代码&&设备代码
CPU和GPU之间通过PCIe总线连接,用于传递指令和数据,这部分也是后面要讨论的性能瓶颈之一。 一个异构应用包含两种以上架构,所以代码也包括不止一部分:- 主机代码
- 设备代码
CUDA nvcc编译器会自动分离你代码里面的不同部分,如图中主机代码用C写成,使用本地的C语言编译器编译,设备端代码,也就是核函数,用CUDA C编写,通过nvcc编译,链接阶段,在内核程序调用或者明显的GPU设备操作时,添加运行时库。
nvcc 是从LLVM开源编译系统为基础开发的。

(3)GPU容量&&性能
1> NVIDIA目前的计算平台(不是架构)
- Tegra 用于嵌入式
- Geforce 打游戏
- Quadro
- Tesla 用于计算
2> 计算能力的种量特征
- CUDA核心数量(越多越好)
- 内存大小(越大越好)
3> 计算能力的性能指标
- 峰值计算能力
- 内存带宽
nvidia自己有一套描述GPU计算能力的代码,其名字就是“计算能力” == 算力,主要区分不同的架构,早其架构的计算能力不一定比新架构的计算能力强
| 计算能力 | 架构名 |
|---|---|
| 1.x | Tesla(Tesla架构,与上面的Tesla平台不同) |
| 2.x | Fermi |
| 3.x | Kepler |
| 4.x | Maxwell |
| 5.x | Pascal |
| 6.x | Volta |
(4)CPU和GPU线程的区别
一个程序可以进行如下分解,串行部分和并行部分CPU和GPU线程的区别:
CPU线程是重量级实体,操作系统交替执行线程,线程上下文切换花销很大
GPU线程是轻量级的,GPU应用一般包含成千上万的线程,多数在排队状态,线程之间切换基本没有开销。
CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU核则是大量线程,最大幅度提高吞吐量
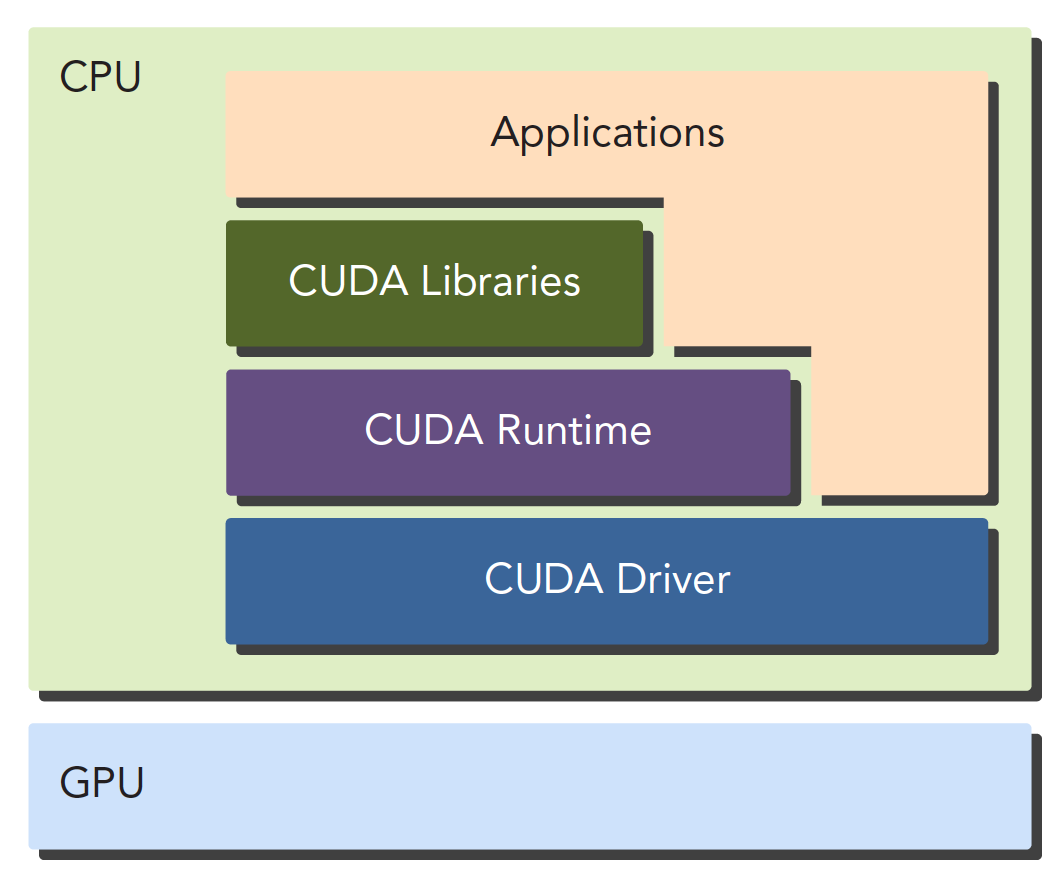
二、CUDA:一种异构计算平台
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持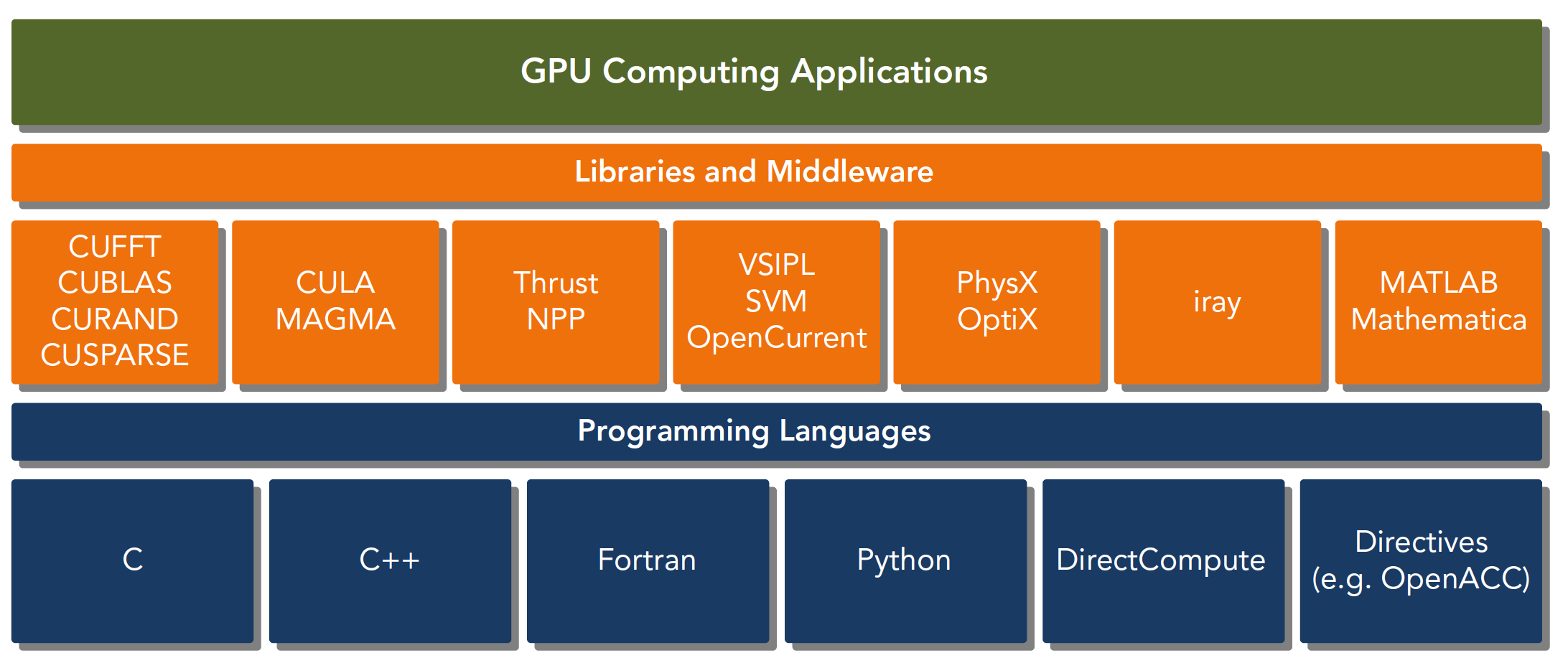
CUDA C 是标准ANSI C语言的扩展,扩展出一些语法和关键字来编写设备端代码,而且CUDA库本身提供了大量API来操作设备完成计算。
对于API也有两种不同的层次,一种相对交高层,一种相对底层。
- CUDA驱动API:低级的API
- CUDA运行时API:高级API使用简单,其实现基于驱动API
三、CUDA:hello world
代码:
include
// 在设备上执行的核函数
global void hello_world(void) { printf(“GPU: Hello world!\n”); } int main(int argc,char **argv) { printf(“CPU: Hello world!\n”); // cuda特有的:对设备进行配置的参数(10次) hello_world<<<1,10>>>(); // 这句话如果没有,则不能正常的运行, // 这句话包含了隐式同步,GPU和CPU执行程序是异步的 // 核函数调用后成立刻会到主机线程继续,而不管GPU端核函数是否执行完毕 // 所以上面的程序就是GPU刚开始执行,CPU已经退出程序了,所以我们要等GPU执行完了,再退出主机线程。 cudaDeviceReset()return 0;
}
运行:
编译
nvcc -o helloworld hello_world.cu
运行
./helloworld
(一)CUDA程序步骤
一般CUDA程序分成下面这些步骤:
- 分配GPU内存
- 拷贝内存到设备
- 调用CUDA内核函数来执行计算
- 把计算完成数据拷贝回主机端
- 内存销毁
(二)写好CUDA
(1) 了解GPU架构,设备局限性影响效率
这个两个性质告诉我们,当一个数据被使用,其附近的数据将会很快被使用,当一个数据刚被使用,则随着时间继续其被再次使用的可能性降低,数据可能被重复使用。
- 空间局部性
- 时间局部性
(2)有两个模型是决定性能
- 内存层次结构
- 线程层次结构
CUDA C写核函数的时候我们只写一小段串行代码,但是这段代码被成千上万的线程执行,所有线程执行的代码都是相同的,CUDA编程模型提供了一个层次化的组织线程,直接影响GPU上的执行顺序。
(3)CUDA抽象了硬件实现
- 线程组的层次结构
- 内存的层次结构
- 障碍同步
线程,内存是主要研究的对象,我们能用到的工具相当丰富,NVIDIA为我们提供了:
Nvidia Nsight集成开发环境
CUDA-GDB 命令行调试器
性能分析可视化工具
CUDA-MEMCHECK工具
GPU设备管理工具

若有收获,就点个赞吧
0 人点赞
