一、并行计算
- 计算机架构(硬件)
- 并行程序设计(软件)
二、并行性
- 指令并行
- 数据并行
第一步,就是把数据依据线程进行划分:不同的数据划分严重影响程序性能,所以针对不同的问题和不同计算机结构,我们要通过和理论和试验共同来决定最终最优的数据划分。
- 块划分,把一整块数据切成小块,每个小块随机的划分给一个线程,每个块的执行顺序随机(关于线程的概念可以去看《深入理解计算机系统》)
- 周期划分,线程按照顺序处理相邻的数据块,每个线程处理多个数据块,比如我们有五个线程,线程1执行块1,线程2执行块2…..线程5执行块5,线程1执行块6
三、计算机架构
佛林分类法Flynn’s Taxonomy,根据指令和数据进入CPU的方式分类,分为以下四类:

- 单指令单数据SISD(传统串行计算机,386)
- 单指令多数据SIMD(并行架构,比如向量机,所有核心指令唯一,但是数据不同,现在CPU基本都有这类的向量指令)
- 多指令单数据MISD(少见,多个指令围殴一个数据)
- 多指令多数据MIMD(并行架构,多核心,多指令,异步处理多个数据流,从而实现空间上的并行,MIMD多数情况下包含SIMD,就是MIMD有很多计算核,计算核支持SIMD)
为了提高并行的计算能力,我们要从架构上实现下面这些性能提升:
延迟是指操作从开始到结束所需要的时间,一般用微秒计算,延迟越低越好。 带宽是单位时间内处理的数据量,一般用MB/s或者GB/s表示。 吞吐量是单位时间内成功处理的运算数量,一般用gflops来表示(10^9 = 十亿次浮点计算, FLOPs),吞吐量和延迟有一定关系,都是反应计算速度的,一个是时间除以运算次数,得到的是单位次数用的时间–延迟,一个是运算次数除以时间,得到的是单位时间执行次数–吞吐量。
- 降低延迟
- 提高带宽
- 提高吞吐量
四、根据内存划分
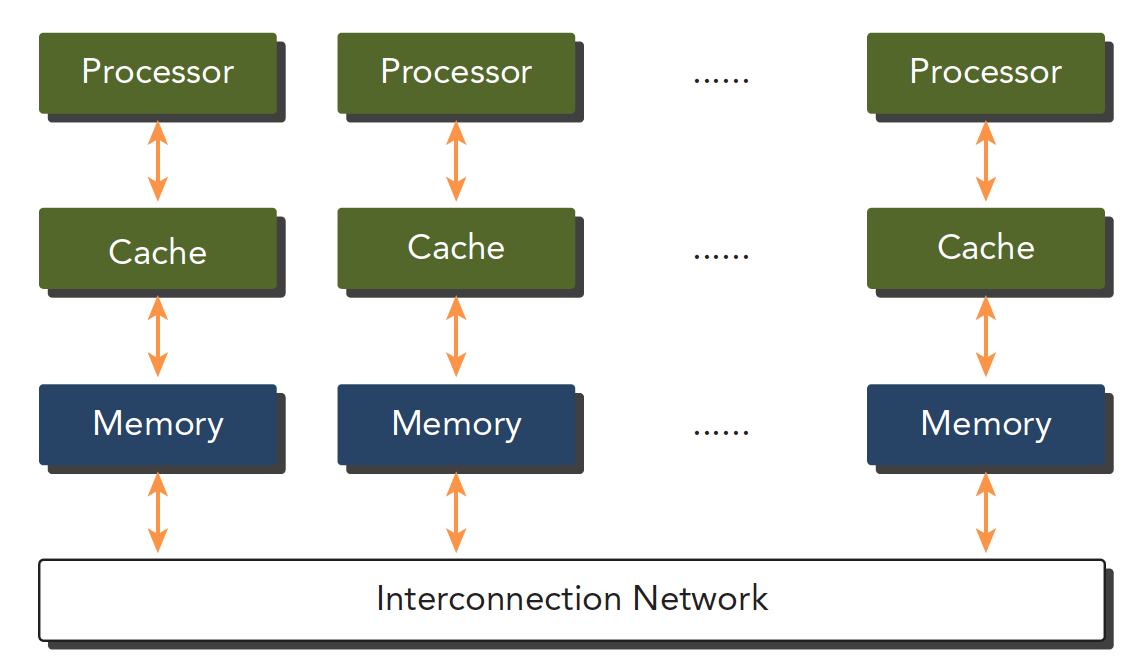
- 分布式内存的多节点系统
- 共享内存的多处理器系统
- 分布式内存的多节点系统: 集群,通过网络互动
- 共享内存的多处理器系统
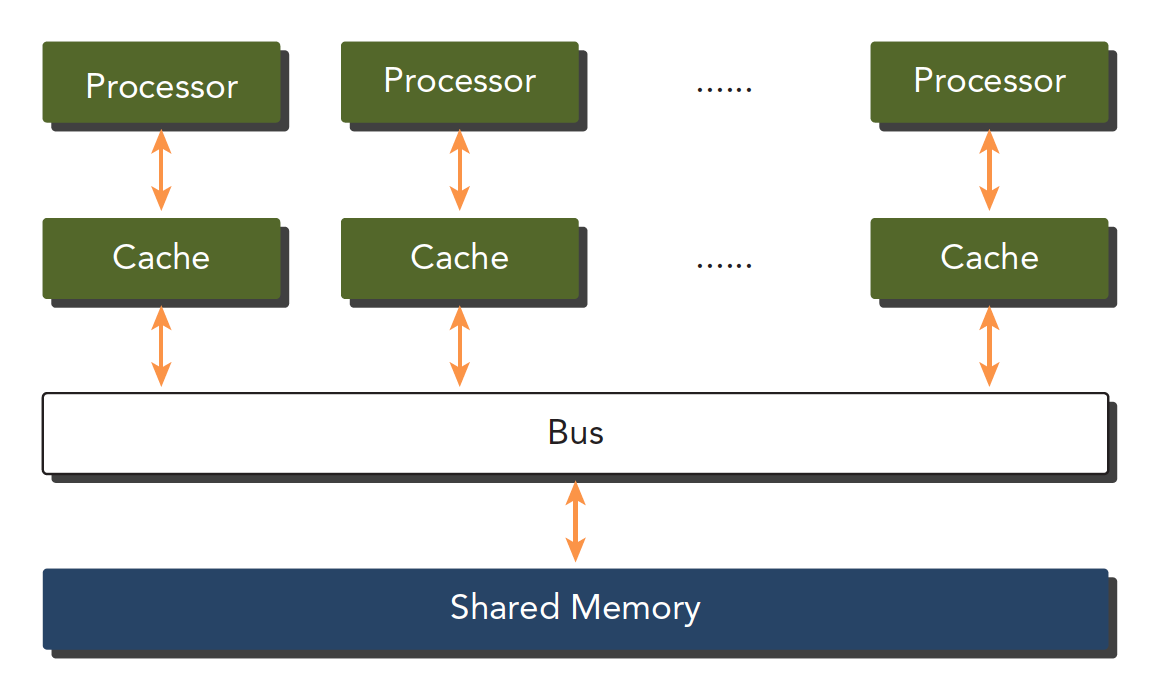
多个处理器可以分多片处理器,和单片多核(众核many-core),也就是有些主板上挂了好多片处理器,也有的是一个主板上就一个处理器,但是这个处理器里面有几百个核。
GPU就属于众核系统。当然现在CPU也都是多核的了,但是他们还是有很大区别的:
- CPU适合执行复杂的逻辑,比如多分支,其核心比较重(复杂)
- GPU适合执行简单的逻辑,大量的数据计算,其吞吐量更高,但是核心比较轻(结构简单)

若有收获,就点个赞吧
0 人点赞
