2020/09/30 周三
AMD、UMD、CommonJS、ES Modules的理解
在ES6之前,JS本身没有模块功能,社区出现了 CommonJS 和 AMD 等模块方案,ES6后, JS开始原生支持模块,一般称之为 ES Modules
- CommonJS: 主要用于服务端,是 node 中使用的 require、module.exports。从 Node.js v13.2 版本开始,Node.js 已经默认打开了 ES6 模块支持。但需要采用 .mjs 后缀文件名。如果不希望将后缀名改成.mjs,可以在项目的package.json文件中,指定type字段为module。
- AMD: Asynchronous Module Definition,异步模块定义,主要用于客户端(浏览器),以 RequireJS 为代表 define、require
- UMD: Universal Module Definition,通用模块定义模式,主要用来解决 CommonJS 模式和 AMD 模式代码不能通用的问题,并同时还支持老式的全局变量规范。
- ES Modules 是 ES 标准模块系统,import、export ,可以和 CommonJS混合使用
/** bundle.js UMD webpack打包后的js* 判断define为函数,并且是否存在define.amd,来判断是否为AMD规范,* 判断module是否为一个对象,并且是否存在module.exports来判断是否为CommonJS规范* 如果以上两种都没有,设定为原始的代码规范。*/(function (global, factory) {typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :typeof define === 'function' && define.amd ? define(factory) :(global = global || self, global.myBundle = factory());}(this, (function () { 'use strict';var main = () => {return 'hello world';};return main;})));// index.html<script src="bundle.js"></script><script>console.log(myBundle());</script>
区别:
- CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。CommonJS一旦输出一个值,模块内部的变化就影响不到这个值。ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。
- CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。因为 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
- CommonJS 模块的require()是同步加载模块,ES6 模块的import命令是异步加载,有一个独立的模块依赖的解析阶段。
// CommonJS模块
let { stat, exists, readfile } = require('fs');
// 等同于
let _fs = require('fs');
let stat = _fs.stat;
let exists = _fs.exists;
let readfile = _fs.readfile;
// ES6模块
import { stat, exists, readFile } from 'fs';
参考
Script error产生原因与解决方法、调试技巧
一般为了安全起见,如果当前页面引入了跨域的 js 文件,当这个 js 文件出现错误,监听错误会无法获取对应的行号、message。仅会将 message 设置为 Script error.
本地来做一个试验,重现该问题,用 koa 写两个服务,分别监听 5001/5002端口,同时开启服务
/**
* index_a.js
* index_b.js 代码和下面的基本一致,只是将 5001 改为 5002
*/
const Koa = require('koa')
const app = new Koa()
app.use(require('koa-static')(__dirname + '/public'))
app.listen('5001', () => {
console.log('server listen on 5001 port')
})
public/index.html 测试页面中,我们引入 5001端口的 a.js 或 5002 端口的 a.js,看具体 error 信息
<body>
<button onclick="btnClick()">点击</button>
<script src="http://127.0.0.1:5001/a.js"></script>
<!-- <script src="http://127.0.0.1:5002/a.js"></script> -->
<script>
window.addEventListener('error', e => {
console.log(e, e.message)
})
</script>
</body>
<!--
// a.js代码
function btnClick() {
console.logaaa('aaa') // 故意制造一个错误
}
-- >
访问 [http://127.0.0.1:5001/index.html](http://127.0.0.1:5001/index.html),然后测试不同端口下执行情况,具体如下图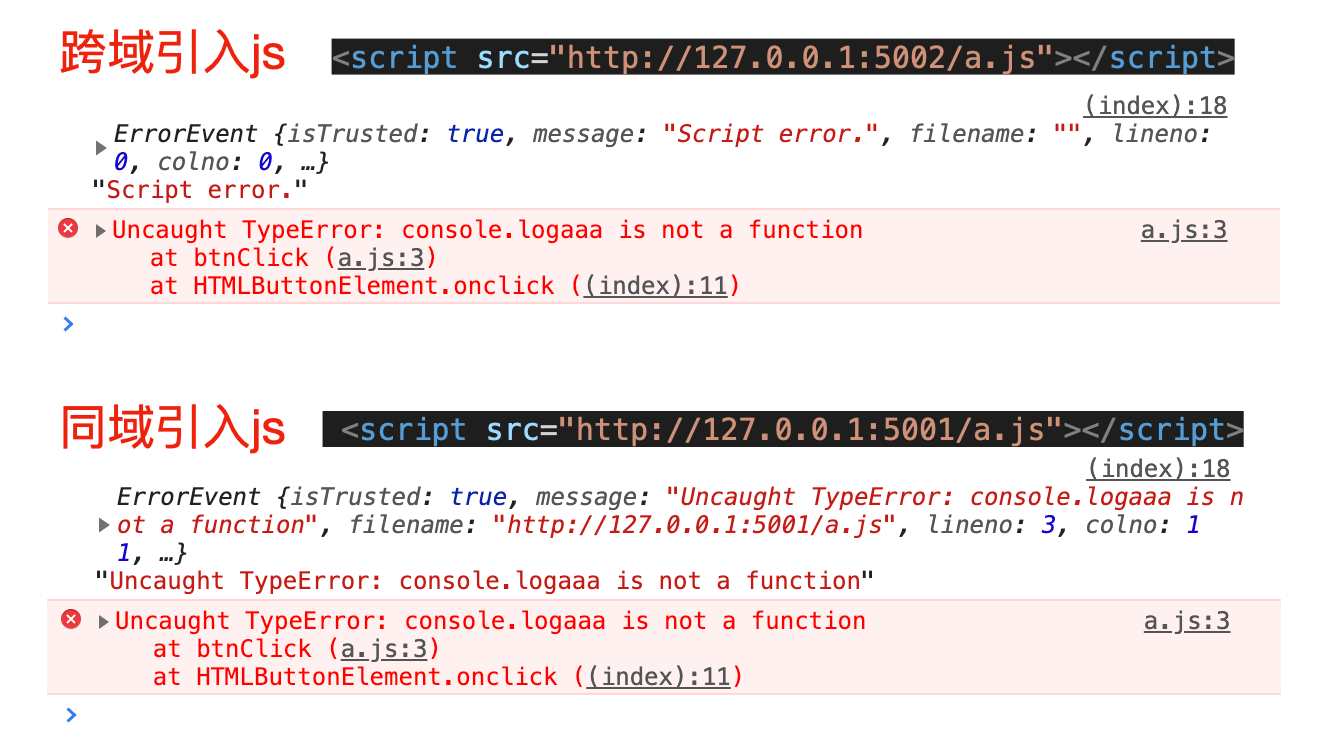
知道问题后,我们可以通过使用同域的方式引入 js。如果一定要使用跨域的,需要设置下面两点
- script引入时加入 crossorigin=”anonymous”,anonymous 即不发送 Cookie 和 HTTP 认证信息
- 服务器对应的js,增加允许跨域
// html里
// <script src="http://127.0.0.1:5002/a.js" crossorigin="anonymous"></script>
// index_b.js 5002端口增加允许跨域
const Koa = require('koa')
const app = new Koa()
// 允许跨域
app.use(async (ctx, next) => {
ctx.set({
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Headers': '*',
'Access-Control-Allow-Methods': '*',
'Access-Control-Allow-Credentials': 'true', // 允许携带cookie
'Access-Control-Max-Age': 3600 // 对于相同的请求,仅在第一次发送options预检请求,之后1小时内不需要预检请求
})
await next()
})
app.use(require('koa-static')(__dirname + '/public'))
app.listen('5002', () => {
console.log('server listen on 5002 port')
})
设置好后,我们再测试就会发现可以正常显示跨域的信息了。如下图,完整demo参见 跨域Script_error测试demo | github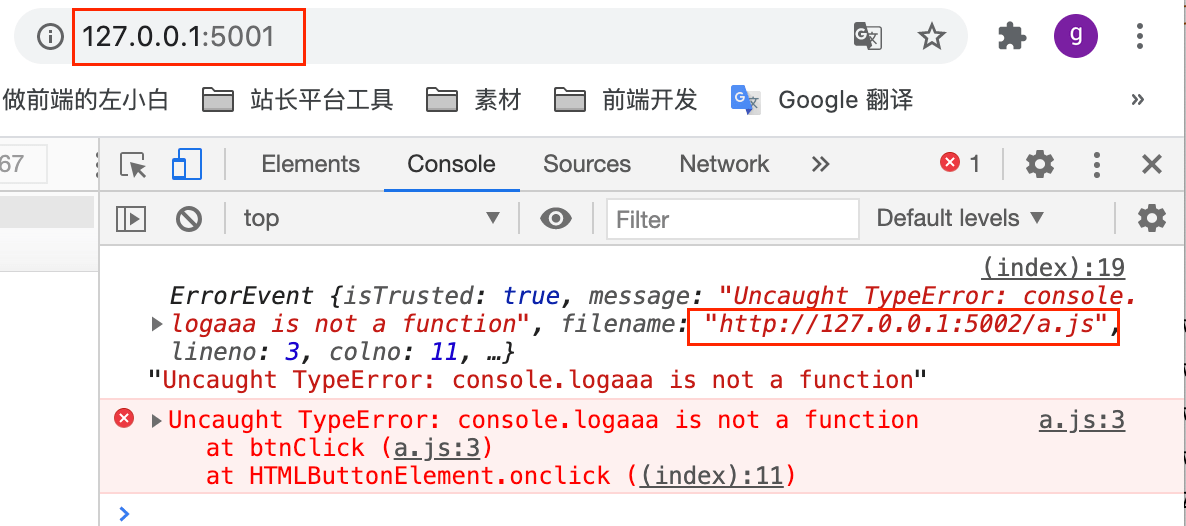
参考:Script error.全面解析 | Fundebug
2020/09/26 周六
为什么会有回流/重排(Reflow)和重绘(Repaint)?怎么避免?
1. 什么是回流或重绘
- 浏览器使用流式布局模型 (Flow Based Layout)
- 浏览器把 HTML 解析成 DOM,把 CSS 解析为 CSDOM,DOM 和 CSDOM 合并就产生了 Render Tree(渲染树)
- 根据Render Tree,计算各个元素在页面中的大小和位置,绘制到页面上。
回流/重排(Reflow):当 Render Tree 中部分或全部元素的尺寸、结构或位置发生改变时,浏览器会重新渲染部分或整个文档的过程就称为Reflow
重绘(RePaint): 当页面中元素样式的改变并不影响它在文档中的位置时,浏览器会重绘该区域,这个过程称为重绘
2. 回流和重绘的比较
DOM、CSS style的改变会照成回流或者重绘,回流比重绘更消耗性能
- 回流:重新布局,会引起元素位置变化的就会reflow,比如修改 DOM 的宽高、字体大小、窗口大小改变、元素位置改变等
- 重绘:重新绘制区域,不改变元素位置,比如修改背景、颜色,visibility等
3. 如何避免回流或重绘
CSS:
- 尽可能在DOM树的最末端改变class
- 避免设置多层内联样式,将动画效果应用到 position 属性为 absolute 或 fixed 的元素上
- 避免使用CSS表达式(例如:calc())
JavaScript
- 避免频繁操作样式、DOM
- 在 documentFragment 或 display 为 none 的元素上进行 dom 操作不会引起回流或重绘
- 对复杂动画,使用绝对定位脱离文档流,避免整体回流
参考:
图片占位、懒加载、预览
使用占位图片有什么好处?
- 用户体验更好,标识此处有图片,但正在加载中的这一个状态,避免弱网或图片较大时,完全不显示的问题
- 不阻塞其他资源加载,更快的整体文档加载速度,不阻塞其他请求。占位图片一般会和图片懒加载一起使用,当滚动到该区域时再加载图片,减少不必要的并发网络请求
- 可以避免回流,让图片加载完成后不改变页面的整体布局,避免回流(重新布局),只需要重绘,注意: 需要占位图片与实际图片宽高不变
怎么实现图片懒加载
这里核心问题是怎么判断图片是否已滚动到当前视口。一般可以通过监听页面滚动事件,实时比较元素的 offsetTop 与页面的 scrollTop。另外还可以通过元素的 getBoundingClientRect() 获取当前元素距离视窗的距离,如果小于 window.innerHeight 就加载,下面来看一个简单的实现
<body>
<div>
<div style="height:50px;">我是占位文本</div>
<img class="lazy-img" data-src="http://zuo11.com/images/blog/c/c_vim.png">
<div style="height:500px;">我是占位文本</div>
<img class="lazy-img" data-src="http://zuo11.com/images/blog/c/c_saolei_3.png">
</div>
<script>
let imgEls = document.querySelectorAll('.lazy-img')
let imgs = []
imgEls.forEach(imgEl => {
imgEl.style.height = '300px'
imgEl.style.width = '300px'
imgEl.src = "placeholder.png"
// 存储信息用于监听滚动后比对
imgs.push({
offsetTop: imgEl.offsetTop,
el: imgEl,
src: imgEl.dataset.src,
isLoad: false
})
})
console.log(imgs)
// 判断滚动位置,显示图片
function showImg() {
console.log('>>>>>>')
imgs.forEach(item => {
// 如果图片未加载
if (!item.isLoad) {
console.log(window.innerHeight, item.src, item.el.getBoundingClientRect())
let elPos = item.el.getBoundingClientRect()
if (elPos.top < window.innerHeight) {
// 如果元素相对顶部的距离 < 视窗高度,加载图片
item.el.src = item.src
item.isLoad = true
}
}
})
}
showImg()
window.onscroll = () => {
showImg()
}
</script>
</body>
图片预览
可以参考Element UI el-image组件实现,Element UI 大图预览 | el-image
参考资料与扩展
Chrome DevTools Network Waterfall各阶段详解
在Chrom调试工具Network tab下,每个请求都有一个Waterfal diagrams(瀑布图),点击具体接口,Timming(时序)位置会有具体描述。它记录了网络请求各个阶段的耗时,可以用于分析页面加载性能。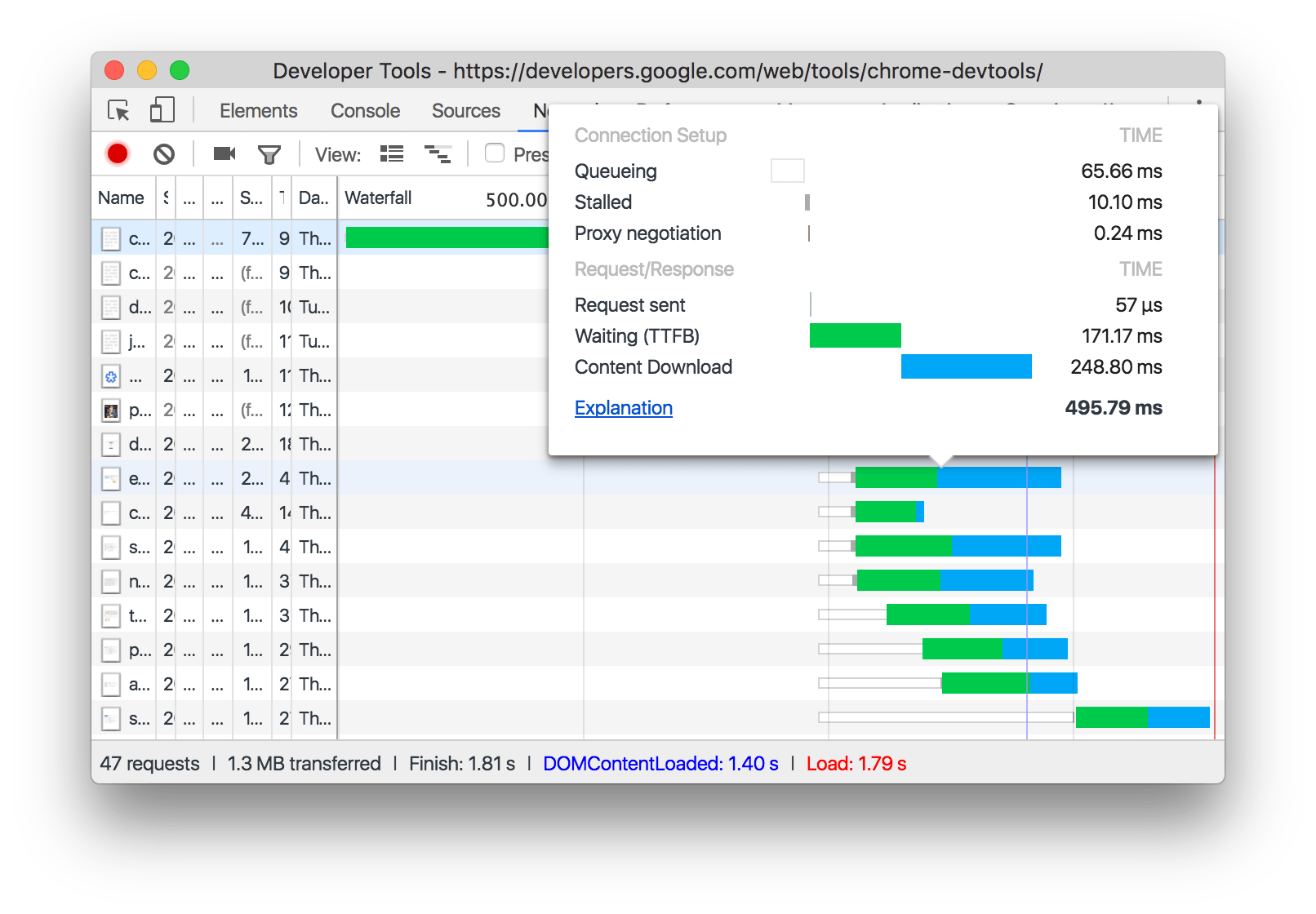
Timing breakdown phases explained(时序分解阶段明细)
Here’s more information about each of the phases you may see in the Timing tab:(下面是在Timing标签页中能看到的各个阶段的更多信息)
1. Resource Scheduling(资源调度)
- Queueing(排队). The browser queues requests when:(浏览器在以下情况会排队请求)
- There are higher priority requests.(有更高优先级的请求)
- There are already six TCP connections open for this origin, which is the limit. Applies to HTTP/1.0 and HTTP/1.1 only. (当前请求的 origin/domain,已经有 6 个 TCP 连接打开,这是限制。仅应用于 HTTP/1.0 and HTTP/1.1)
- The browser is briefly allocating space in the disk cache(浏览器正在磁盘缓存中短暂分配空间)
2. Connecttion Start(连接开始)
- Stalled(停滞/暂缓). The request could be stalled for any of the reasons described in Queueing. (处于排队中描述的任何原因,请求都有可能停滞/暂缓)
- DNS Lookup(DNS查询). The browser is resolving the request’s IP address. (域名解析成IP。在浏览器和服务器进行通信之前, 必须经过DNS查询, 将域名转换成IP地址. 在这个阶段, 你可以处理的东西很少. 但幸运的是, 并非所有的请求都需要经过这一阶段.)
- Initial connection(初始化连接). The browser is establishing a connection, including TCP handshakes/retries and negotiating an SSL.(浏览器正在创建一个连接,包括握手/重试)和 协商SSL。在浏览器发送请求之前, 必须建立TCP连接. 这个过程仅仅发生在瀑布图中的开头几行, 否则这就是性能问题.
- SSL(SSL协商) SSL/TLS Negotiation 如果你的页面是通过SSL/TLS这类安全协议加载资源, 这段时间就是浏览器建立安全连接的过程.
- Proxy negotiation(代理协商). The browser is negotiating the request with a proxy server. (浏览器正在与代理服务器协商请求)
3. Request/Response(请求/响应)
- Request sent(请求发送). The request is being sent. 请求开始发送
- ServiceWorker Preparation(ServiceWorker准备). The browser is starting up the service worker. (浏览器正在启动 Service Worker)
- Request to ServiceWorker(请求到ServiceWorker). The request is being sent to the service worker.(请求被发送到 service worker)
- Waiting (TTFB) 等待. The browser is waiting for the first byte of a response. TTFB stands for Time To First Byte. This timing includes 1 round trip of latency and the time the server took to prepare the response.(浏览器正在等待响应的第一个字节。 TTFB代表到第一个字节的时间。 此时间包括一次往返延迟和服务器准备响应所花费的时间) TTFB 是浏览器请求发送到服务器的时间+服务器处理请求时间+响应报文的第一字节到达浏览器的时间. 我们用这个指标来判断你的web服务器是否性能不够, 或者说你是否需要使用CDN.
- Content Download. The browser is receiving the response. (浏览器正在接收响应),这是浏览器用来下载资源所用的时间. 这段时间越长, 说明资源越大. 理想情况下, 你可以通过控制资源的大小来控制这段时间的长度.
- Receiving Push. The browser is receiving data for this response via HTTP/2 Server Push.(浏览器正在通过HTTP / 2服务器推送接收此响应的数据)
- Reading Push. The browser is reading the local data previously received.(浏览器正在读取先前接收的本地数据。)
参考资料及扩展:
- Timing breakdown phases explained - Network Analysis Reference | Chrome DevTools
- Chrome 开发者工具中文文档
- 教你读懂网络请求的瀑布图
- The SEO Professional’s Guide to Waterfall Diagrams
- 理解 Service Workers
append和appendChild的区别
在JS高程3中,并没有讲到 append,基本都是用的 appendChild,所以有知识盲点,这里对比下 append 和 apendChiild的区别
| 方法 | 所属对象 | 功能 | 返回值 | 兼容性 |
|---|---|---|---|---|
| appendChild | Node | 在元素内容里追加一个 Node 节点 | append的节点 | 基本都兼容 |
| append | ParentNode | 在元素内容里追加一个或多个 Node 节点或 String | undefined | 实验性功能 不支持 IE |
注意,如果 append 或 appendChild 的元素是已经存在的,会移动该元素,如果需要保持原来的不移动,需要先 cloneNode, 下面来看一个例子
<body>
<div id="c1"></div>
<div id="existDiv">我是一段已经存在的dom</div>
<div id="c2"></div>
<div id="c3"></div>
<script>
// 1.测试基本功能:创建节点,并 appendChild 到 c1元素
let p = document.createElement('p')
let text = document.createTextNode('我是一段信息')
p.appendChild(text)
console.log(p, p.__proto__) // HTMLParagraphElement
document.querySelector('#c1').appendChild(p)
// document.querySelector('#c1').appendChild('1212') // Error, Node
// 2.测试 appendChild 一个已存在的节点,移动节点,而不是copy
let existDiv = document.querySelector('#existDiv')
console.log(existDiv, existDiv.__proto__) // HTMLDivElement
console.log('测试appendChild 返回', document.querySelector('#c2').appendChild(existDiv))
// console.log('测试append 返回', document.querySelector('#c2').append(existDiv))
// 4.测试append
let span = document.createElement('span')
// 不要写成链式调用,它返回的是成功appendChild的节点
span.appendChild(document.createTextNode('测试append'))
document.querySelector('#c3').append('<span>abc</span>')
document.querySelector('#c3').append(span, 'a', 'b', '<div>c</div>')
</script>
</body>
执行效果如下图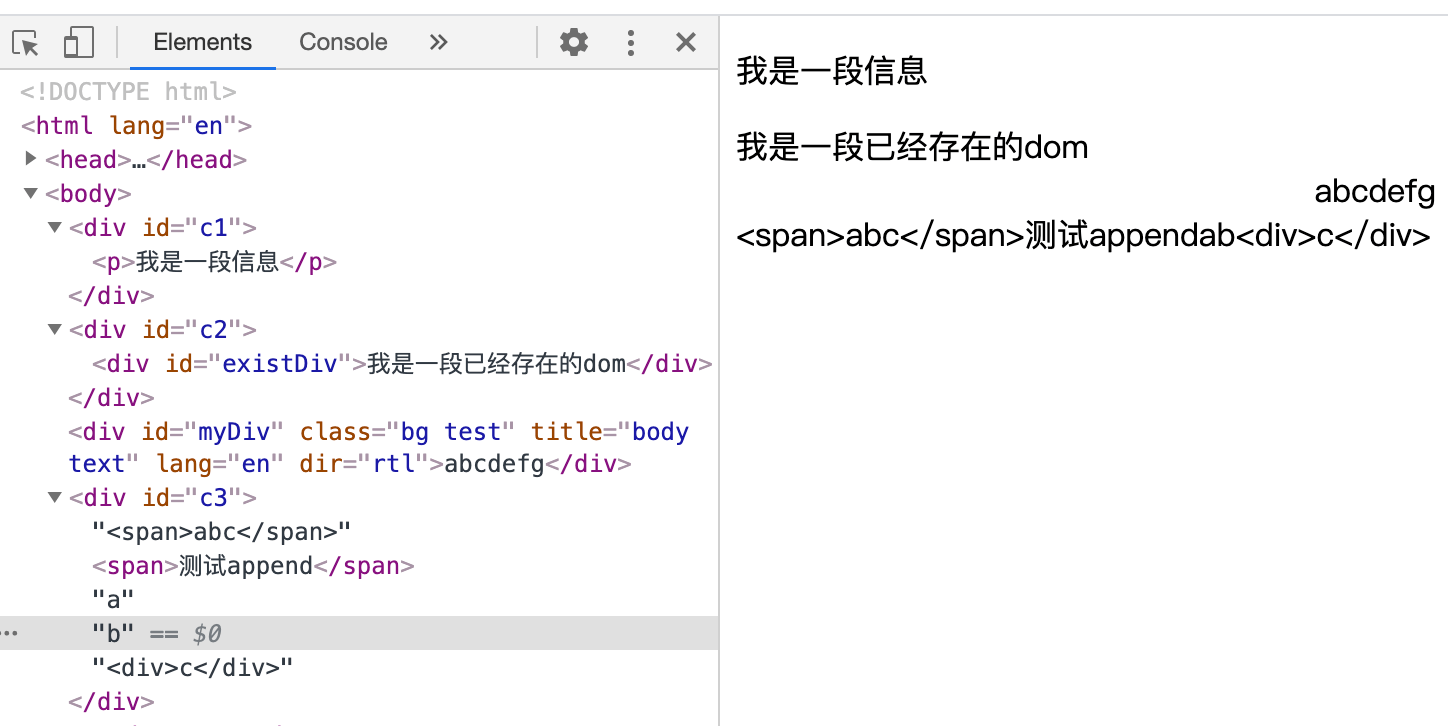
关于Node节点Element元素对象的一些值
<div id="myDiv" class="bg test" title="body text" lang="en" dir="rtl">abcdefg</div>
// 3.测试节点类型、对象信息 HTMLDivElement => HTMLElement => Element => Node
// 参考:DOM https://www.yuque.com/guoqzuo/js_es6/hoglme#6bbee863
var div = document.getElementById("myDiv"); // HTMLDivElement
console.log(div.nodeType) // 1 Node.ELEMENT_NODE
console.log(div.nodeName) // DIV
console.log(div.id); // myDiv
console.log(div.className); // bg test
console.log(div.title); // body text
console.log(div.lang); // en
console.log(div.dir); // rtl
Google Analytics、Google AdSense、Google Search Console分别是干什么的?
在站点管理这一块,Google的工具有好几个,我现在知道的有三个,他们分别对应不同的功能,下面来看看他们的介绍、区别
| 平台 | 功能 |
|---|---|
| Google Search Console 搜索控制台 | 站长工具、sitemap提交,展现量/点击量简单查看,死链提交等 |
| Google Analytics 分析 | 偏数据分析,统计实时用户/累计用户/会话时长/跳出率等,受众群体、流量来源、转化率、页面价值等 |
| Google AdSense 广告联盟 | 用于在自己站点投放 Google 广告,赚取收益 |
百度统计类似 Google Search Console 和 Google Analytics 的结合体,但 Google Analytics 的细分功能更加强大
关于 Google AdSense,有一本书可以参考下:《Google AdSense 实战宝典》
Google AdSense被拒理由网站已下线或无法访问怎么解决
在自己网站的 head 部分加入 AdSense 的校验代码后,会有一段审核的时间。在这个过程中,网站可能会有来自福建龙岩的 203.208.60.* IP段蜘蛛来爬取你的网页。蜘蛛会爬取JS渲染后的效果,可以触发百度统计等js代码。不用屏蔽,这属于 Google 蜘蛛正常爬取,Google Analytics 在计算访客时会忽略这一部分访客信息。
蜘蛛爬完的第二天,就收到了邮件,说审核不通过,看了下原因:”网站已下线或无法访问怎么解决” ,如下图所示。但我的网站是确定可以正常访问的。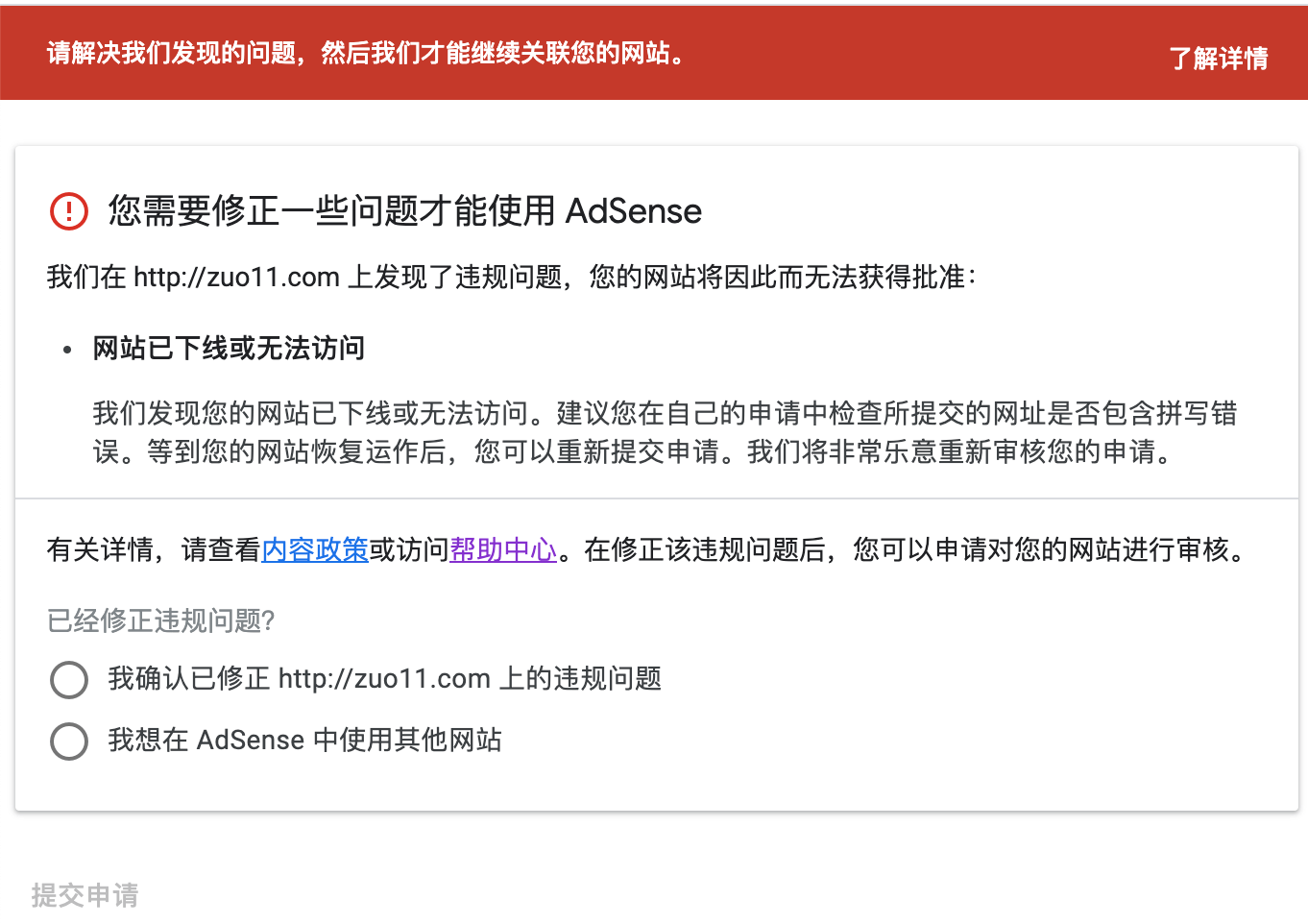
网上查了下,这种情况,需要在域名解析里增加两条解析记录,解析路线设置为境外。然后重新提交审核,等待即可。但我加了解析后,等了一段时间,又是同样的理由被拒绝,于是找到了官方的回复。首页不能重定向,比如 xx.com 不能重定向到 xx.com/home,或者 www.xx.com,再次修改后,重新提交审核,大概5、6天后审核通过。参考 为什么一直提示找不到adsense代码和网站已下线或无法访问? - AdSense Community
| 主机记录 | 记录类型 | 解析路线 | 记录值 | TTL |
|---|---|---|---|---|
| @ | A | 境外 | 服务器IP地址 | 10分钟(默认) |
| www | A | 境外 | 服务器IP地址 | 10分钟(默认) |
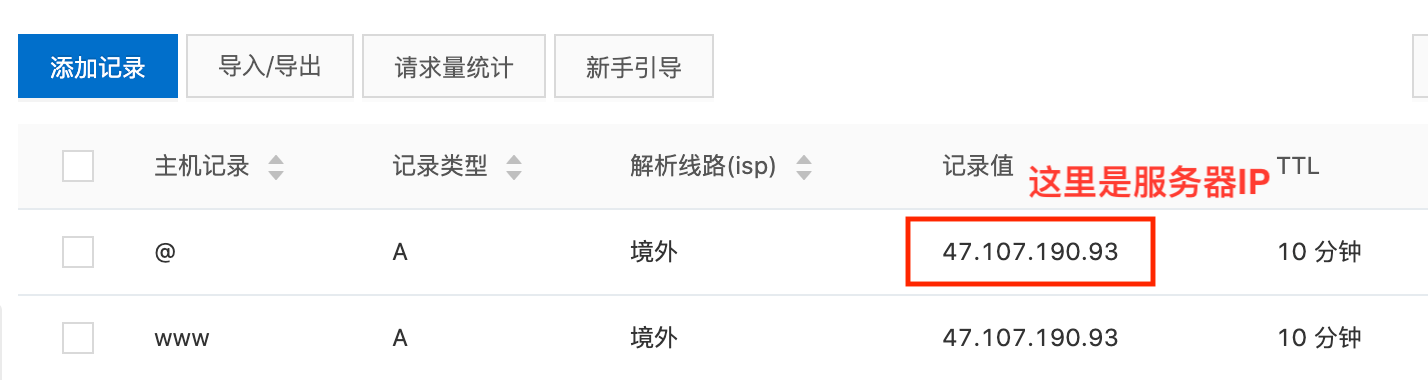
www 和 @ 这样的主机记录是什么意思?
- www:解析后的域名为
www.xx.com。 - @:直接解析主域名 xx.com。
- :泛解析,匹配其他所有域名 .xx.com。
关闭 zuo11.com 到 www.zuo11.com 的重定向,大概是09月27,再次提交后,10月02号收到审核通过邮件。如下图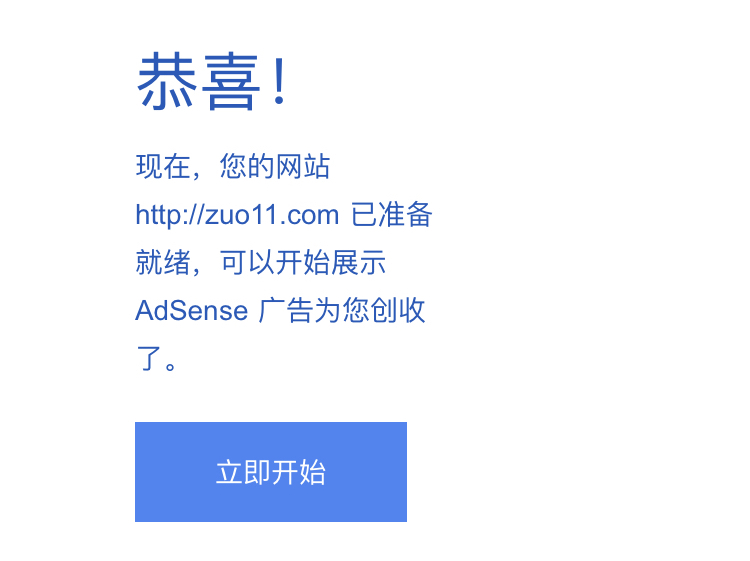
2020/09/25 周五
Final Cut Pro 使用网易见外工作台自动生成字幕(免费)
1.将视频的音频单独导出
在 Final Cut Pro 里导入视频素材,并拖入到时间线中。点击右上角分享按钮,导出 母版文件,一般默认是导出视频和音频。在设置里设置为仅音频,WAV格式。然后下一步,保存 .wav 格式文件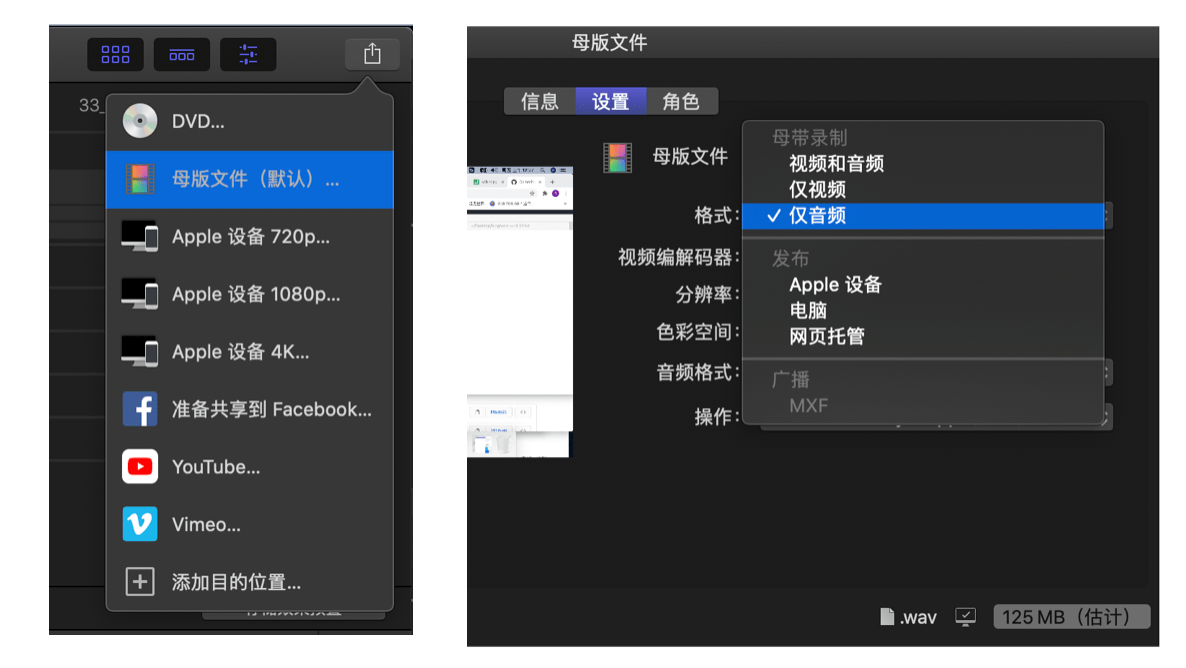
2.在网易见外工作台将音频生成.srt字幕文件
进入 网易见外工作台,如果没注册先注册。登录成功后,新建项目 => 选择语音转写 => 填写信息、上传之前导出的 wav 音频文件,提交后,一般等几分钟就好了(具体等待时间看音频时长)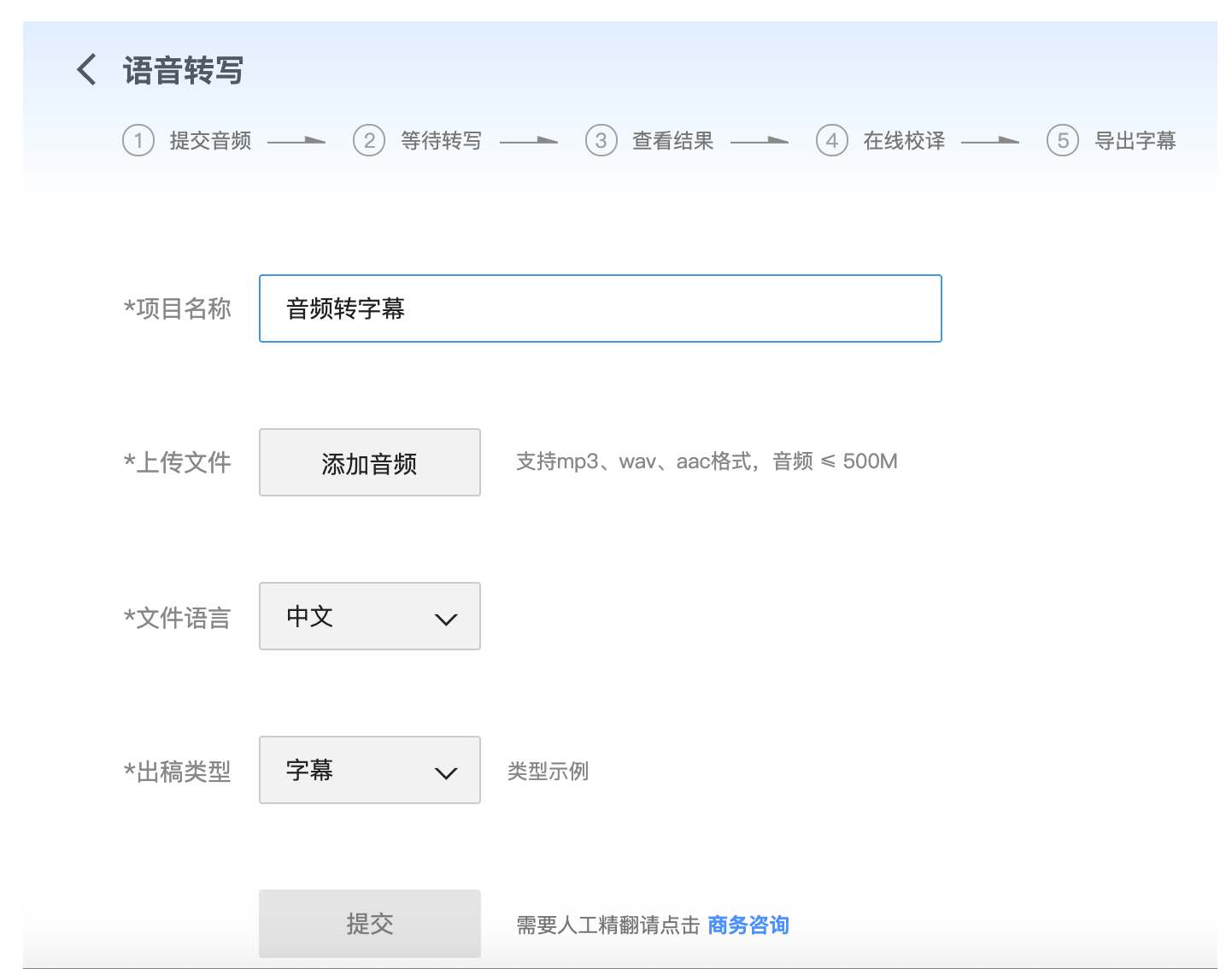
生成好后,点击进入详情页,可对生成的字幕进行修改,修改完成后点击导出,会生成 .srt 字幕文件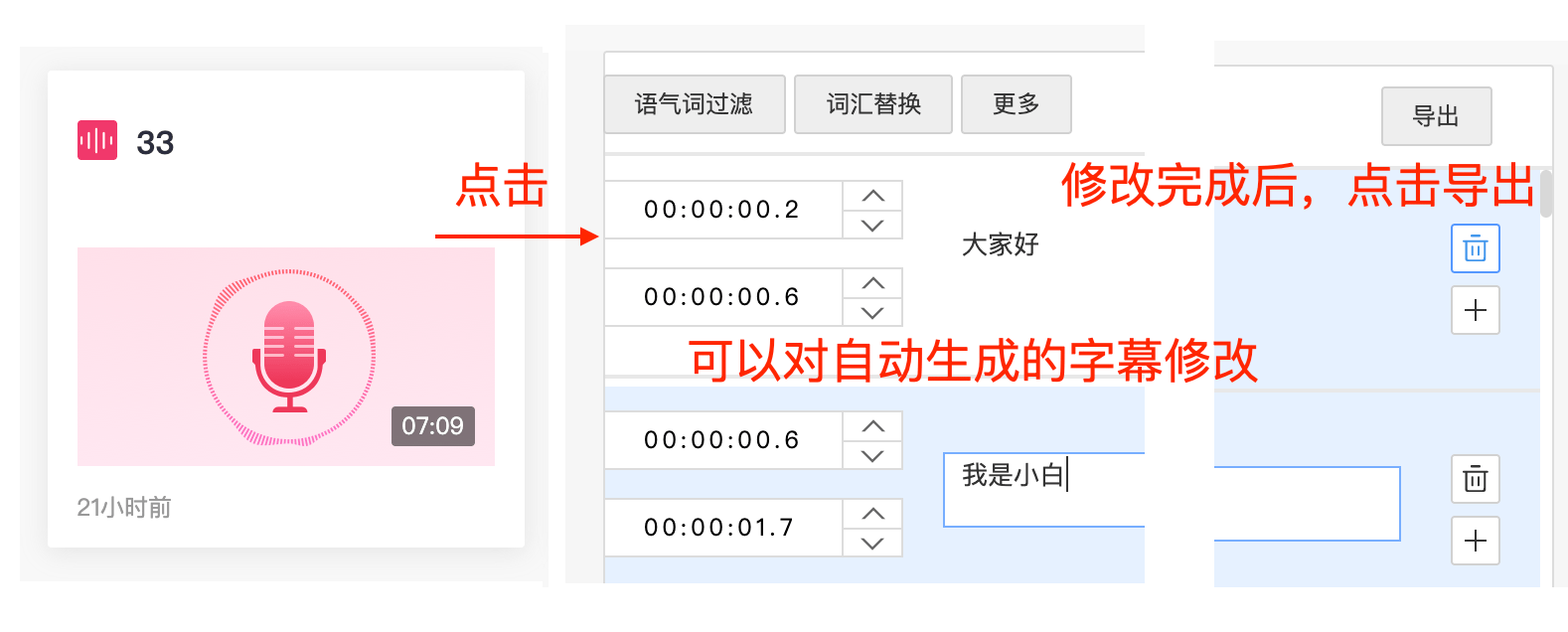
3.将字幕文件导入到Final Cut Pro项目中
点击 Final Cut Pro 顶部 文件 => 导入 => 字幕,选择上一步生成的 .srt 文件即可。注意:如果出现下图中 “字幕文件包含不支持的数据或可能已损坏” 的问题,那么就还需要使用 Aegisub 将字幕文件转一下格式
Aegisub 官网下载很慢,我找的是PC6.com下载的,Aegisub 下载地址 | PC6.com,下载完成后,打开该软件,点击顶部菜单 文件 => 打开字幕,打开后再点击 文件 => 导出,默认文字编码为 UTF-8 => 导出 => fileType 文件类型选择 .srt => 存储
这样转换过的 .srt 文件,再重新导入到 Final Cut Pro,这样就大功告成了。
如果字幕导入进去了,还是看不到字幕,要确保视频显示比例,是否是合适,可能放大了,字幕在最底部,显示区域正好看不到字幕。
4.每次导出时,一定要记得在角色-字幕那里勾选字幕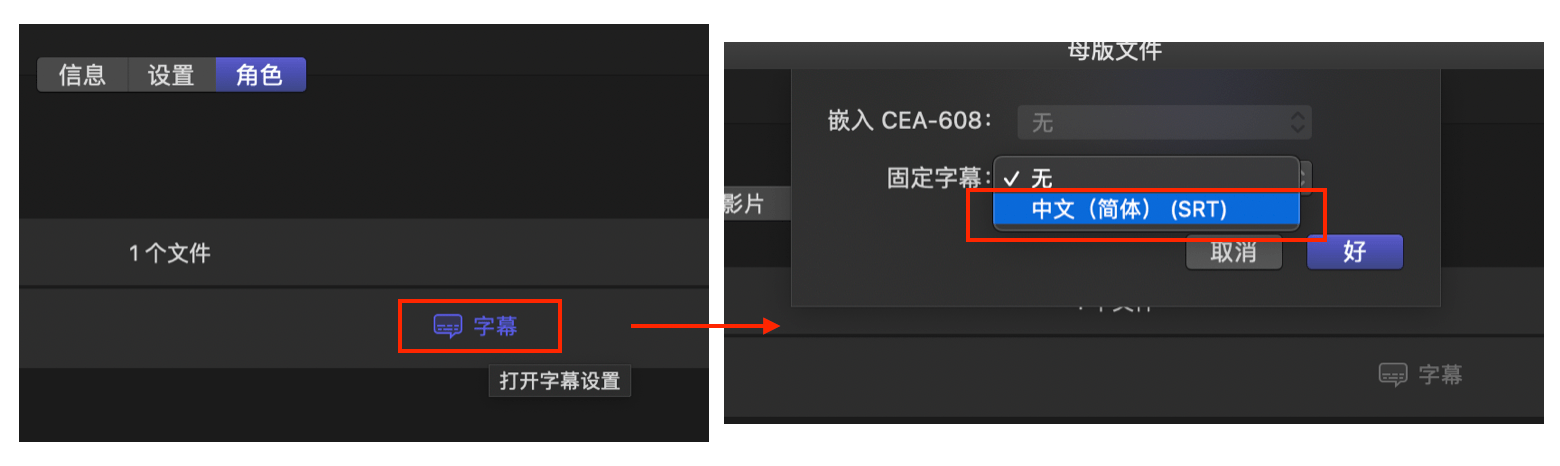
Final Cut Pro 将视频拖到时间线后不是全屏的问题
注意在资源库里点击导入的视频素材,预览时,显示的是视频本身的分辨率。而拖到流水线后,点击流水线上的视频,显示的是当前项目创建时预设的分辨率,如果你视频本身是 2800x_1600 但最开始新建项目,选择的分辨率不是 2800x_1600 就会出现非全屏的情况。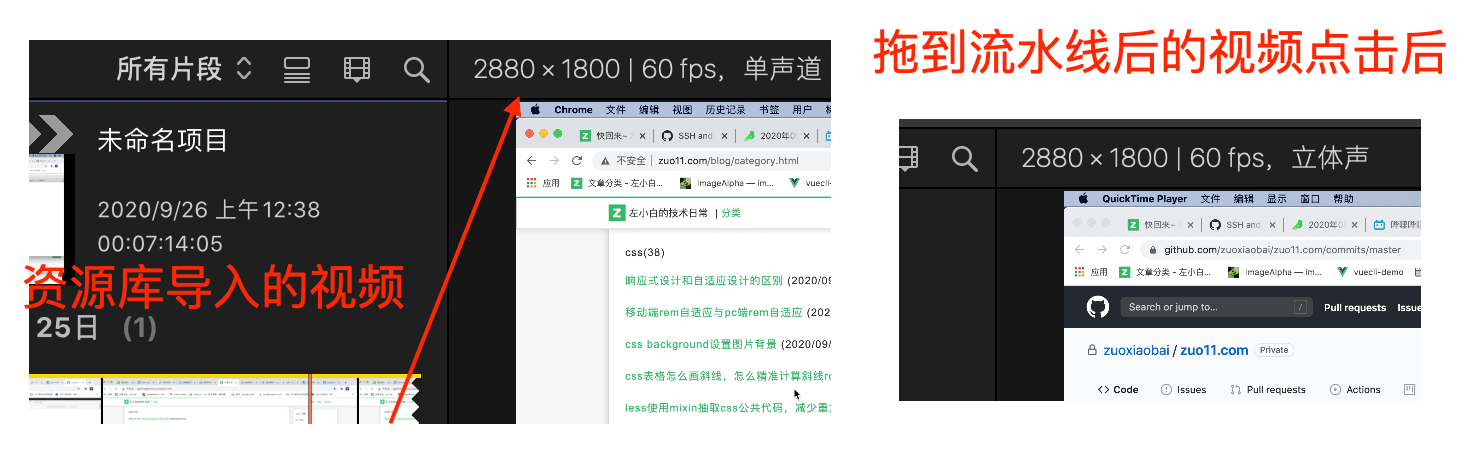
Final Cut Pro 导出7分钟视频就要40多G,视频太大怎么处理
一般用 QuickTimer 录制屏幕后,生成的文件默认视频编解码器为 Apple ProRes 422,导出的视频预计有40多G,我的视频才7分钟,有点恐怖。
一般这种情况,在导出母版文件时,将视频编解码器改为 H.264 即可。预计是4G多,实际导出700多M左右。清晰度给我的感觉是看不出差别。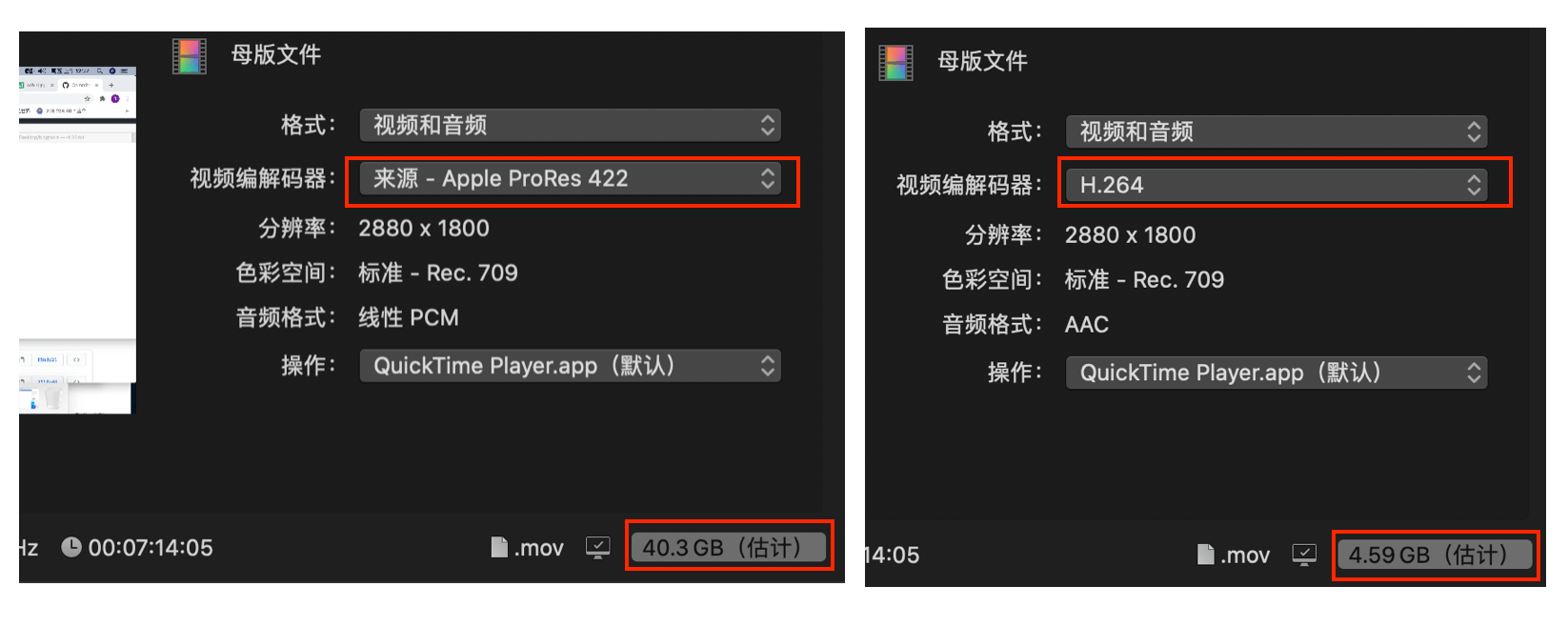
Final Cut Pro 怎么加音效,自带的声音效果变没了怎么处理
在 Final Cut Pro 的左上侧区域是浏览器区域,分别有三个模块:资源库、照片和音频、字幕和发生器
- 资源库用于导入和管理资源。
- 照片和音频用于管理音视频,声音效果里有很多背景音乐,注意:如果这里的声音效果是空的列表,则需要点击左上角的 apple 标志,打开系统偏好设置 => 软件更新 => 升级需要升级的包 => 升级完成后再打开 Final Cut Pro 就能看到音效了
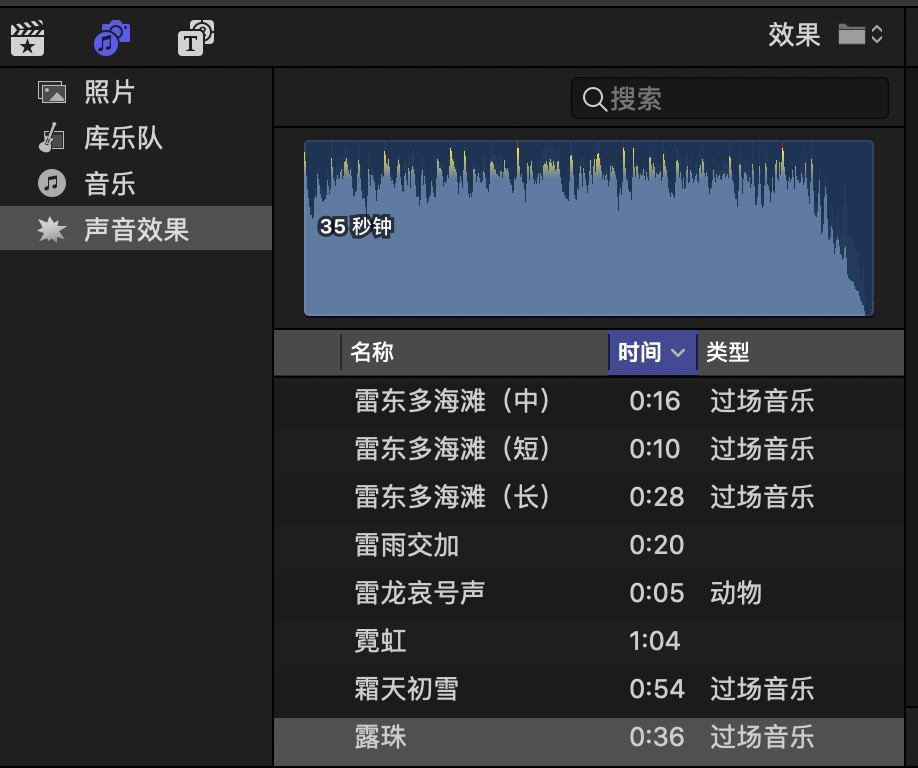
- 字幕用于手动添加各种类别的字幕,发生器用于添加剪短的背景、动画视频片段
使用git ssh方式解决RPC failed; HTTP 413 curl 22 The requested URL returned error: 413
由于改了博客生成系统的生成方式,每个html都改了,导致文件相对较多,也不算大,才 4.57 M, 但 git push 一直push不了,提示如下
error: RPC failed; HTTP 413 curl 22 The requested URL returned error: 413
fatal: the remote end hung up unexpectedly
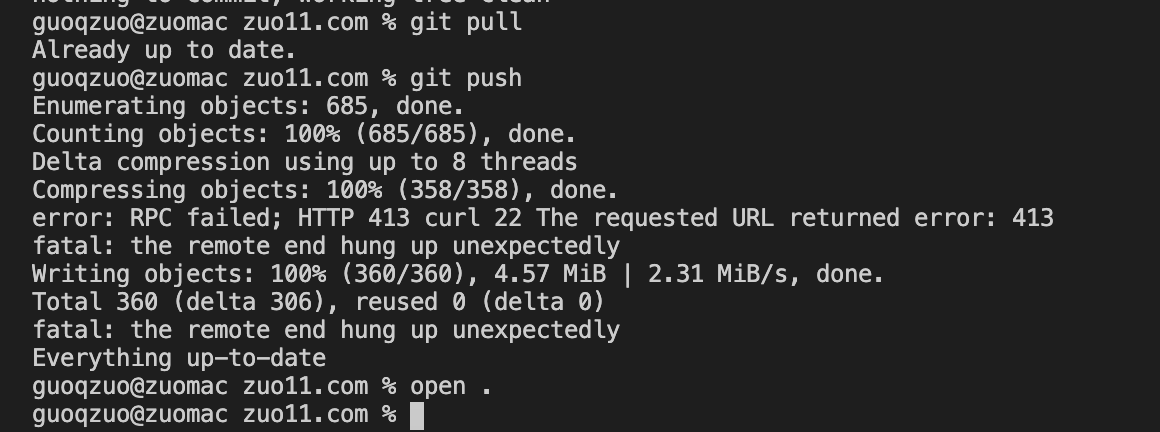
网上查了下,可以改用 ssh 的方式 push 代码,结合之前的经验,大文件 git clone 不下来,可以换 ssh 方式 git clone。这条路应该可行。找了下之前的笔记 使用ssh方式拉取代码的步骤,下面来梳理下整个过程。
1.使用git平台(这里是github)邮箱账号生成公钥和私钥
# 先查看 github 对应的邮箱,user.email 就是git邮箱账号
git config -l
# credential.helper=osxkeychain
# user.name=guoqzuo
# user.email=guoqzuo@gmail.com
# core.quotepath=false
# 开始生成秘钥
ssh-keygen -t rsa -C 'guoqzuo@gmail.com'
# 全部默认、回车,也可以输入密码,我这里输入了密码,后面每次pull, push都需要输入密码。
# Generating public/private rsa key pair.
# Enter file in which to save the key (/Users/guoqzuo/.ssh/id_rsa):
# Enter passphrase (empty for no passphrase):
# Enter same passphrase again:
# Your identification has been saved in /Users/guoqzuo/.ssh/id_rsa.
# Your public key has been saved in /Users/guoqzuo/.ssh/id_rsa.pub.
# 查看公钥内容,copy后到github里设置ssh key
cat ~/.ssh/id_rsa.pub
2.copy公钥,并配置到对应的git平台里(这里是github)
登录 github,在个人设置里找到 ssh key,添加 ssh key,内容为 cat ~/.ssh/id_rsa.pub 后显示的内容
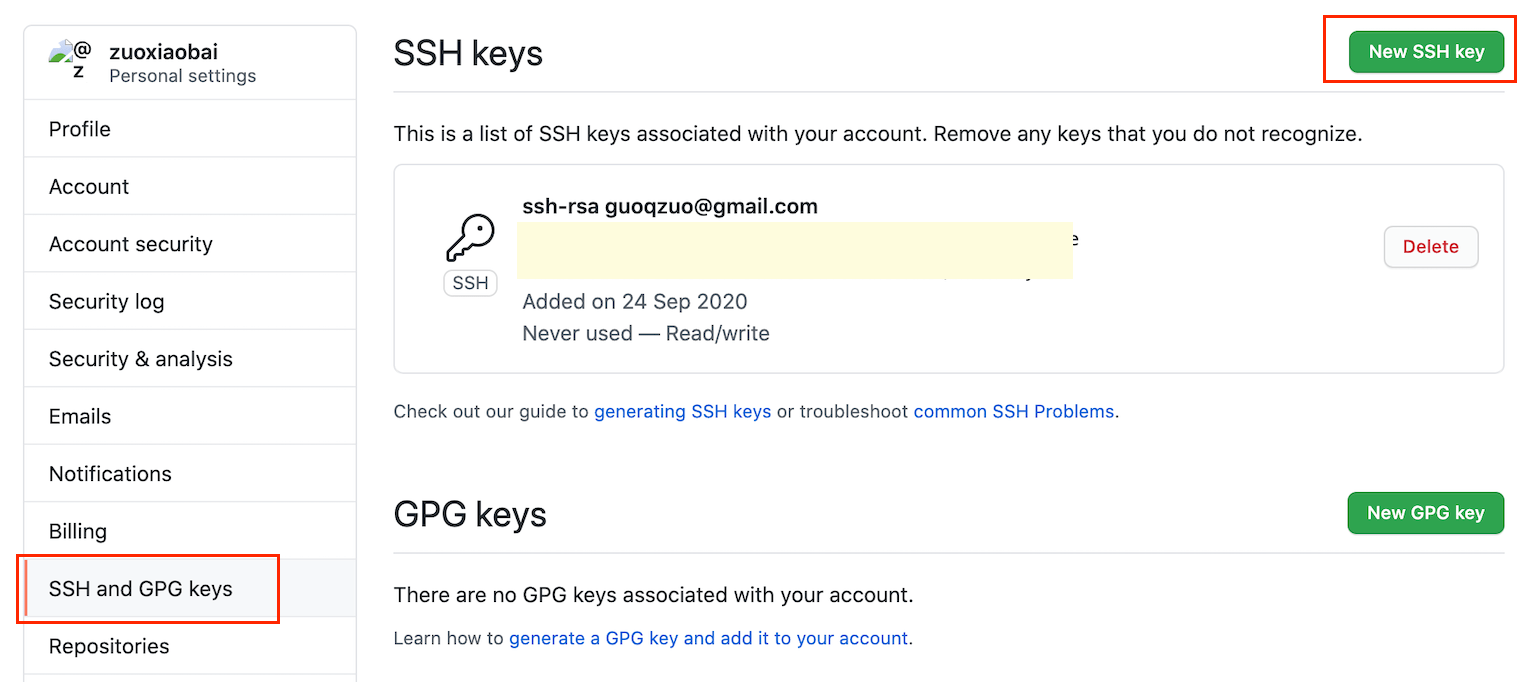
3.测试是否配置成功
使用下面的命令,测试 github ssh key 是否配置成功,如果之前生成 key 时有输入 passphrase,这里就要输入
ssh -T git@github.com
# Enter passphrase for key '/Users/guoqzuo/.ssh/id_rsa':
# Hi zuoxiaobai! You've successfully authenticated, but GitHub does not provide shell access.
4.将仓库http的origin地址,替换为ssh的origin地址
# 查看 remote 地址
git remote -v
# origin https://github.com.cnpmjs.org/zuoxiaobai/zuo11.com (fetch)
# origin https://github.com.cnpmjs.org/zuoxiaobai/zuo11.com (push)
# 设置 remote 地址为对应仓库的 ssh 地址
git remote set-url origin git@github.com:zuoxiaobai/zuo11.com.git
# 查看设置是否生效
git remote -v
# origin git@github.com:zuoxiaobai/zuo11.com.git (fetch)
# origin git@github.com:zuoxiaobai/zuo11.com.git (push)
配置好后,再进行git pull, git push 就可以 push 成功了,虽然也有点慢,但至少不会报错。可以push成功
guoqzuo@zuomac zuo11.com % git pull
Enter passphrase for key '/Users/guoqzuo/.ssh/id_rsa':
Already up to date.
guoqzuo@zuomac zuo11.com % git push
Enter passphrase for key '/Users/guoqzuo/.ssh/id_rsa':
Enumerating objects: 685, done.
Counting objects: 100% (685/685), done.
Delta compression using up to 8 threads
Compressing objects: 100% (358/358), done.
Writing objects: 100% (360/360), 4.57 MiB | 150.00 KiB/s, done.
Total 360 (delta 306), reused 0 (delta 0)
remote: Resolving deltas: 100% (306/306), completed with 296 local objects.
To github.com:zuoxiaobai/zuo11.com.git
85b3d21..bf8eab3 master -> master
guoqzuo@zuomac zuo11.com %
ssh生成rsa key时Enter passphrase加和不加有什么区别
在使用ssh前,需要先生成公共/私有rsa密钥对。(Generating public/private rsa key pair.),一般使用 ssh-keygen -t rsa -C '邮箱@xx.com' 命令,这个时候,会有下面的提示
Enter passphrase (empty for no passphrase):
输入通行码(密码、口令短语),如果不输入,那么就是不使用密码。如果输入了密码,这个有什么用呢?
个人理解这个主要是安全方面的考虑,如果你私钥泄露了,还有一个保护机制。在你每次使用 ssh 做敏感操作时,就会提示你输入密码
比如我们使用 ssh 方式拉取 git 仓库代码,远程 origin 源是 ssh 地址,那么提交代码时,每次 git pull, git push 时都需要输入对应的秘钥。相对会比较麻烦一点。
2020/09/24 周四
xx.github.io打不开的问题
xx.github.io 偶尔会出现打不开的问题,网上查原因是电信运营商 DNS 污染(域名解析不到正确的 IP 地址)
只要本地手动设置 host 即可正常访问,假设我要访问 [https://zuoxiaobai.github.io/fedemo/](https://zuoxiaobai.github.io/fedemo/) 那我手动指定一下这个域名的解析ip即可
# 修改 /etc/hosts
sudo vi /etc/hosts
# 添加如下host记录
185.199.108.153 zuoxiaobai.github.io
# 查看host文件
cat /etc/hosts
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
185.199.108.153 zuoxiaobai.github.io
255.255.255.255 broadcasthost
::1 localhost
保存后,就可以打开 [https://zuoxiaobai.github.io/fedemo/](https://zuoxiaobai.github.io/fedemo/) 了
参考:
js生成二维码怎么实现
QRCode.js是一个生成二维码的js库,使用 HTML5 Canvas将二维码绘制到dom上,不依赖任何库。支持svg绘制方式
QRCode.js is javascript library for making QRCode. QRCode.js supports Cross-browser with HTML5 Canvas and table tag in DOM. QRCode.js has no dependencies.
QRCode.js使用很简单,下面来写一个自动生成二维码的工具,在线示例 在线生成二维码工具
<body>
<div style="margin-bottom:20px;">
<input id="input" type="text">
<button id="btn">生成二维码</button>
</div>
<div id="qrcode"></div>
<!-- 在 https://github.com/davidshimjs/qrcodejs 下载的文件 --->
<script src="./qrcode.min.js"></script>
<script type="text/javascript">
let inputEl = document.getElementById('input')
let btnEl = document.getElementById('btn')
btnEl.onclick = () => {
document.getElementById("qrcode").innerHTML = ''
// new QRCode(document.getElementById("qrcode"), inputEl.value);
let qrcode = new QRCode(document.getElementById("qrcode"), {
text: inputEl.value,
width: 128,
height: 128,
colorDark: "#000000",
colorLight: "#ffffff",
correctLevel: QRCode.CorrectLevel.H
});
// 上面使用清空dom,再重绘,也可以使用内置的方法来重绘
// qrcode.clear(); // clear the code.
// qrcode.makeCode(inputEl.value); // make another code.
}
</script>
</body>
注意:如果输入的是纯文本,那扫描后打开的就是纯文本,如果是 http:// 开头的网址,会直接跳转到对应的 URL
完整demo,参见: 前端生成二维码 | github
参考
什么是e2e test,除了单元测试外还有什么测试?
e2e 是 end to end 的缩写,翻译为端到端测试。单元测试只是整个测试金字塔中的一部分。其他类型的测试还包括 e2e(端到端)测试,快照比对测试等。
- 单元测试:最小巧、最简单、最有用的测试。它们通过隔离单个组件的每一个部分,来在最小工作单元上进行断言。能帮助开发者思考如何设计一个组件或重构一个现有组。通常每次代码发生变化的时候它们都会被运行。
- 快照比对测试:会保存你的 Vue 组件的标记,然后比较每次新生成的测试运行结果。如果有些东西改变了,开发者就会得到通知,并决定这个改变是刻意为之 (组件更新时) 还是意外发生的 (组件行为不正确)。
- e2e(端到端)测试致力于确保组件的一系列交互是正确的。它们是更高级别的测试,例如可能会测试用户是否注册、登录以及更新他们的用户名。这种测试运行起来会比单元测试和快照比对测试慢一些。运行起来会更慢很多。这些测试通常只在部署前运行,来确保系统的每个部分都能够正常的协同工作。
更多测试 Vue 组件细节,可以参考 Edd Yerburgh 的书《Testing Vue.js Applications》,中文翻译版为《Vue.js应用测试》
vue单元测试
在 Vue.js 官网 学习 => CookBook 下有一个 Vue 组件的单元测试 文档。
为什么要测试?组件的单元测试的好处:
- 提供描述组件行为的文档
- 节省手动测试的时间
- 减少研发新特性时产生的 bug
- 改进设计
- 促进重构
- 自动化测试使得大团队中的开发者可以维护复杂的基础代码
Vue Test Utils 是 Vue 组件单元测试的官方库。推荐使用 Jest 或 mocha-webpack
相关参考文档
涉及到状态code相关判断逻辑,建议使用常量
对于一些状态较多的场景,当我们需要进行一些逻辑时,如果我们用状态的code来写判断逻辑。当后端提供的这个状态文案、code变更或调整,改动可能会很麻烦,特别是功能较多时。
对于状态相关的判断逻辑,尽量把状态定义为容易识别的常量。这样状态名或状态code变更后,就不需要做大量修改了。
来看一个实例,假设项目的状态有几种:待审核 0 、待跟进 1、已立项 2、落地成功 3、落地失败 4、 关闭 5 ,有些组件只有待审核可以看到,有些功能只有已立项才能看到
const PROJ_STATUS = {
PENDING_AUDIT: 0,
PENDING_FOLLOW: 1,
ALREADY_SET_UP: 2,
LAND_SUCCESS: 3,
LAND_FAILURE: 4,
CLOSE: 5
}
const PROJ_LABEL_MAP = {
[PROJ_STATUS.PENDING_AUDIT]: '待审核',
[PROJ_STATUS.PENDING_FOLLOW]: '待跟进',
[PROJ_STATUS.ALREADY_SET_UP]: '已立项',
[PROJ_STATUS.LAND_SUCCESS]: '落地成功',
[PROJ_STATUS.LAND_FAILURE]: '落地失败',
[PROJ_STATUS.CLOSE]: '关闭'
}
if (status === PROJ_STATUS.PENDING_AUDIT) {
// xxx
} else if ([PROJ_STATUS.LAND_SUCCESS,PROJ_STATUS.LAND_FAILURE].includes(status)) {
// xxx
}
这样虽然看起来麻烦一点,但不管你状态文案、code怎么变,前端的改动都会很小。项目越大,变动后维护的成本相对会越低
2020/09/21 周一
mac下怎么截取屏幕gif图:Gifox
最开始做gif图是使用QuickTime录制屏幕后,再搜索在线视频转gif图的网站进行转换,比较麻烦。
最近发现一个比较好的软件 Gifox,我使用的是免费版的,有水印,最大长度限制为10s。升级付费的版本可以去水印(watermark),且没有10s限制。它功能强大,录制gif很方便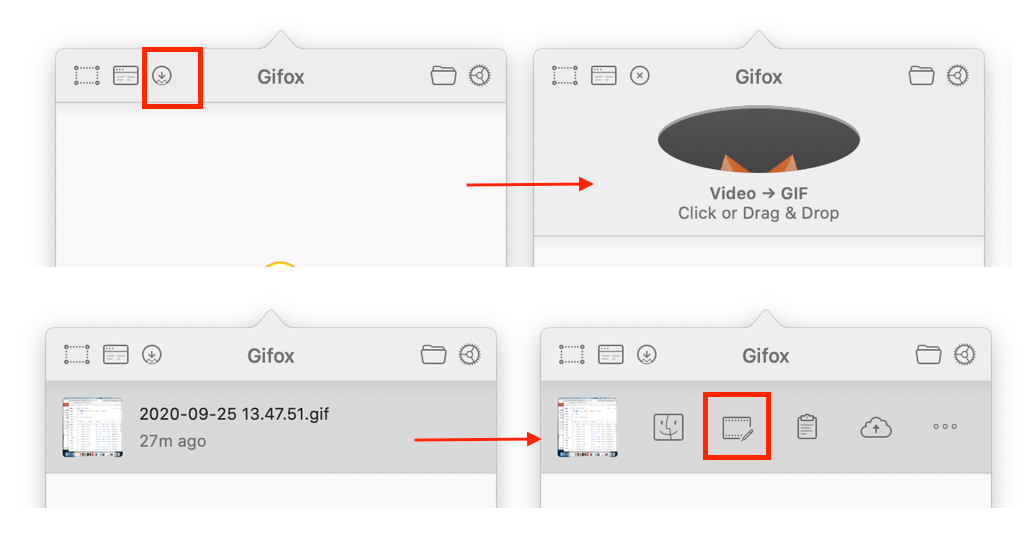
- shift + command + 6 即可录制选中区域进行录制。
- 录制完成后,可以像剪辑视频一样剪辑gif图,操作简单
- 导出时,可以调整参数,压缩文件大小
- 可以直接把QuickTime录制的视频转为gif,并可以剪辑
不全局安装npm包,怎么在项目中执行对应的命令
一般在vue开发中,vue命令可以执行,是因为全局安装了 @vue/cli npm包,那假设你无法使用 npm install -g 全局安装,那怎么在当前项目所在的目录运行命令呢?这里我们使用 zuo-util 这么npm包来介绍3种在项目种运行npm包命令的方法
# 随便创建一个文件夹,并使用terminal进入到该目录,执行 npm init 创建 package.json
npm init
# 输入项目名,英文,这里用 npm_cmd_test,其他全部默认回车
# 运行 zuo 这个命令
zuo
# 找不到这个命令,说明全局没有安装 zsh: command not found: zuo
我们再局部安装下
# 项目里局部安装 zuo-util,非全局安装
npm install zuo-util --save
# 再运行 zuo,还是不行
zuo
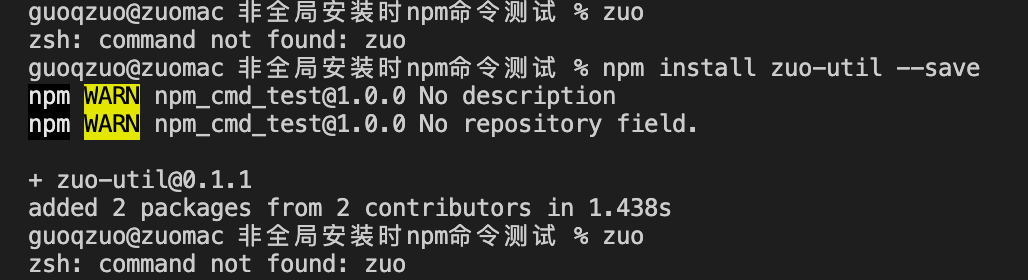
我们可以使用下面三种方法来运行局部安装的npm包对应的命令
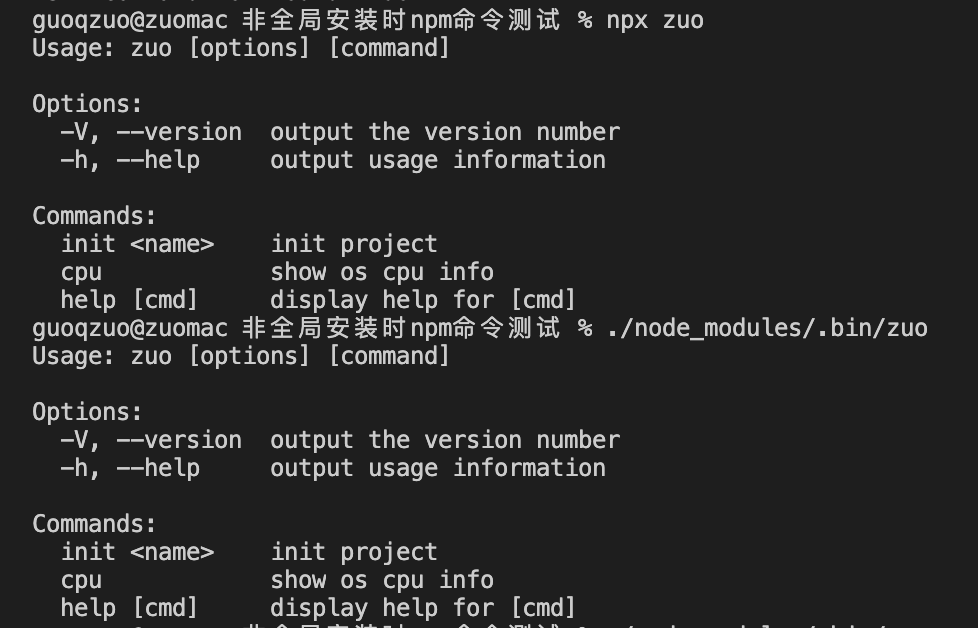
npx 命令
可以使用npx 命令名,执行项目中的,非全局的命令
npx zuo
./node_modules/.bin/命令
一般局部安装的命令都会放到 ./node_modules/.bin/ 目录下,可以通过 . 语法直接运行
./node_modules/.bin/zuo
npm run xxx
在 package.json 里的 scripts 里面,我们可以设置运行的命令
// package.json
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"zuo": "zuo"
},
按照上面的代码设置后,npm run zuo 即可执行当前目录下的zuo命令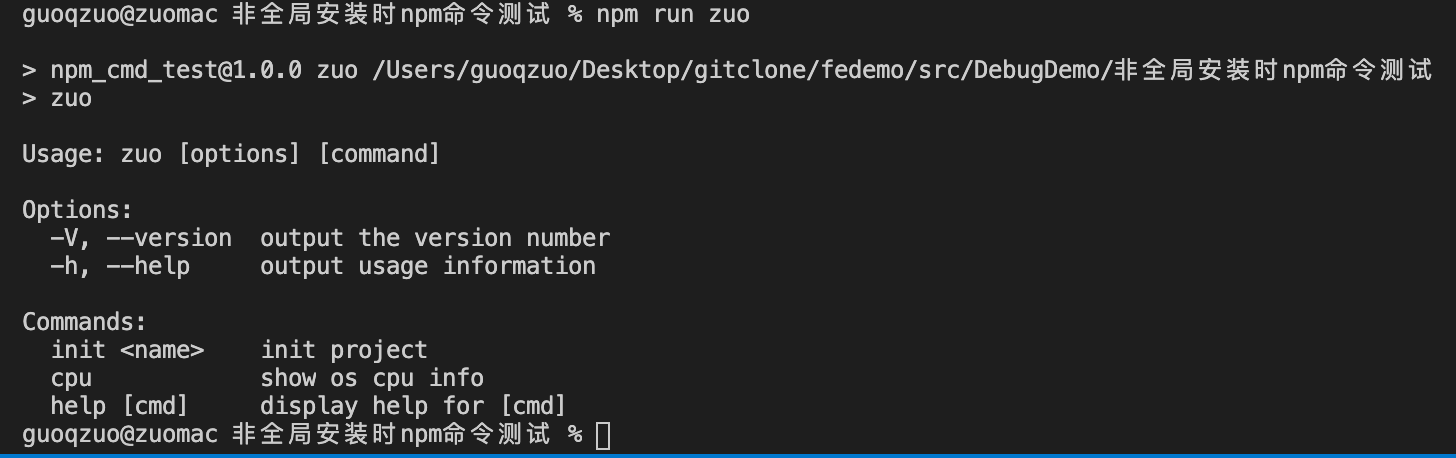
2020/09/13 周日
keep-alive只在跳转到B组件页面时缓存当前路由数据,跳到其他页面不缓存路由数据
一般情况下,我们可以使用路由meta参数里传keepAlive为true或false来对某个路由页面做缓存
<keep-alive>
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<router-view v-if="!$route.meta.keepAlive"></router-view>
假设有A、B、C三个页面组件。B页面只有跳到C页面才缓存数据,跳到其他页面不缓存页面数据
这里 router-view 组件会切换三个组件的显示类似与component is切换组件。我们需要动态的去判断是否缓存B页面组件,可以使用keep-alive的include参数来指定需要缓存的页面组件数据
<!-- 逗号分隔字符串 -->
<keep-alive include="a,b">
<component :is="view"></component>
</keep-alive>
假设B页面组件的name为 ‘PageB’,那么默认情况下include为’PageB’,就表示缓存该页面,如果设置include为’’就是不缓存页面数据,核心问题是怎么动态的改变这个include的值。
我们可以在B页面组件路由离开之前的钩子函数里,来修改这个值,注意,需要单独弄一个变量,使用$route.meta.include参数来修改这个值是没有用的,因为$route.meta这个值并不像data里面的数据是双向绑定的,他在进入页面时就固定了。中间修这个值不会触发template里面的模板重新渲染
来看看具体实例
<!-- index.vue 入口页面 http://localhost:8081/keepAlive/ -->
<template>
<div>
我是主页面
<ul>
<li><router-link to="/keepAlive/a">A组件页面</router-link></li>
<li><router-link to="/keepAlive/b">B组件页面</router-link></li>
<li><router-link to="/keepAlive/c">C组件页面</router-link></li>
</ul>
include{{ include }}
<keep-alive :include="include">
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<router-view v-if="!$route.meta.keepAlive"></router-view>
<!-- 测试 $route.meta 的值是否是双向绑定的 -->
$route.meta.include {{$route.meta.include}}
</div>
</template>
<script>
export default {
data() {
return {
include: "PageB"
};
},
created() {
// 这里修改值后数据,页面的$route.meta.include值并没有刷新,因此不能为了节省变量使用$route.meta来做include的控制
setTimeout(() => {
this.$route.meta.include = "test"
console.log('this.$route.meta.include', 'test')
}, 3000)
}
};
</script>
/keepAlive/a、/keepAlive/c只是单独的页面,没有任何逻辑,只是用来测试跳转。主要逻辑是在/keepAlive/b页面
<template>
<div>
我是B组件页面
<el-input v-model="input" placeholder="请输入B组件内容"></el-input>
<el-radio-group v-model="radio">
<el-radio :label="3">备选项</el-radio>
<el-radio :label="6">备选项</el-radio>
<el-radio :label="9">备选项</el-radio>
</el-radio-group>
</div>
</template>
<script>
export default {
name: "PageB",
data() {
return {
input: "",
radio: ""
};
},
beforeRouteLeave(to, from, next) {
if (to.name === "keepAliveC") {
// 如果跳转的页面C组件,缓存页面数据
this.$parent.include = "PageB";
} else {
// 如果跳转的页面不是C组件,不缓存数据
this.$parent.include = "";
}
next();
}
};
</script>
以上就可以实现我们的目的了,完整demo参见 keepalive测试demo| github
参考:
子组件名称与父组件name相同时死循环的问题
在vue项目中,假设父组件name与子组件名称一致,会造成死循环,出现 Error in nextTick: "RangeError: Maximum call stack size exceeded"的错误,template在编译时,不会去找components引入的组件,而是直接引入自己,形成一个递归组件。要特别注意
<template>
<div>
<p>我是index组件</p>
<test-a></test-a>
</div>
</template>
<script>
export default {
components: {
TestA: () => import("./TestA")
},
// name: "testA",
name: "TestA",
created() {
console.log("index comp created");
}
};
</script>
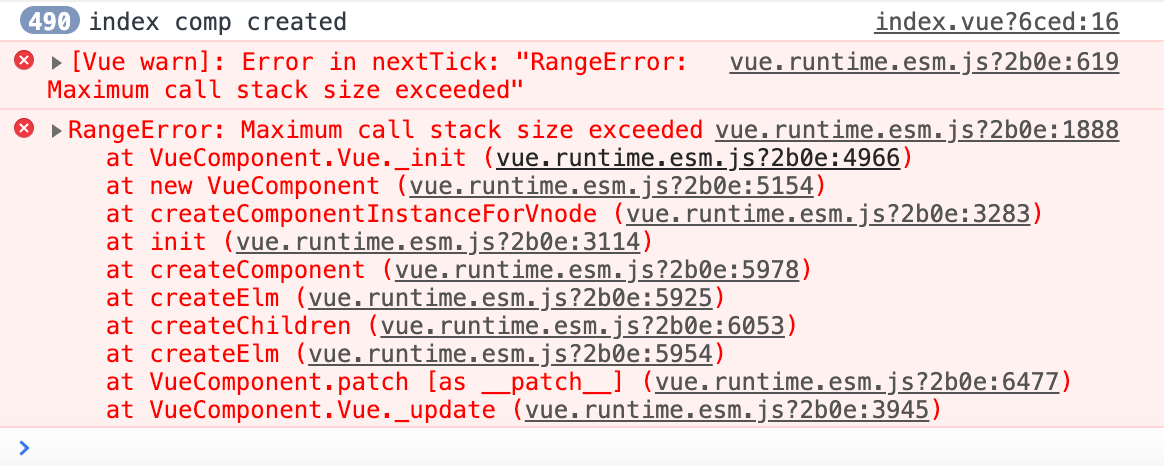
完成demo地址,参考 subcomp_samename demo| github
.eslintignore在不同vscode版本中的差异
.eslintignore文件的作用是,当不想对项目的某个目录进行eslint检查时,可以在这个文件中声明,类似.gitignore文件的效果。
// .eslintignore
mock
上面表示忽略mock文件夹下的代码检查。这样eslint插件就不会显示warning、不会保存后自动fix该文件。在这个文件中去掉mock后,mock下的文件就又可以保存后fix了。
但有一个问题,不同vscode版本的行为可能有差异,有可能把目录加入到了.eslintignore后,保存时还是会fix这个目录下的eslint错误。建议升级到最新版本。
父组件加载子组件时,父子组件钩子顺序
<!-- index.vue -->
<template>
<div>
<comp-a></comp-a>
</div>
</template>
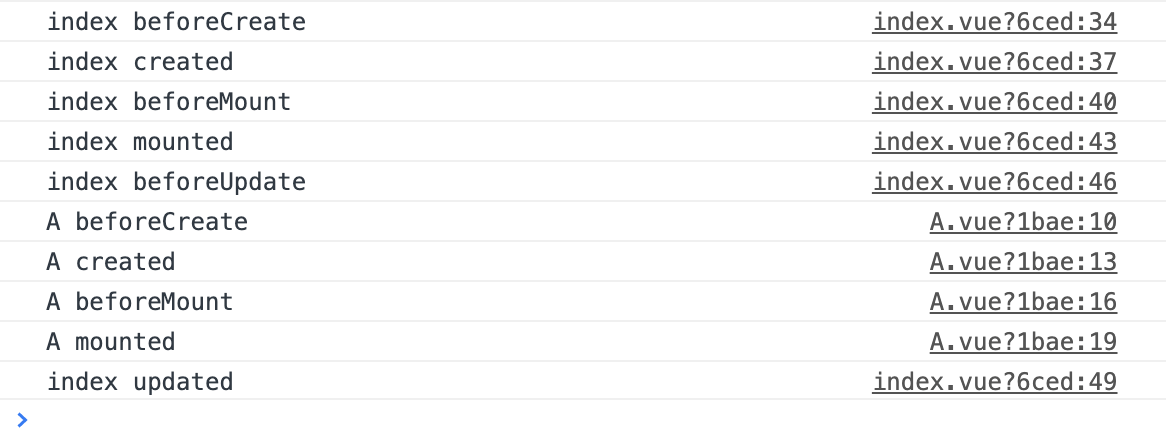
在 index.vue 以及 compA.vue 子组件里面都加了对应的钩子函数console,具体顺序如下,父组件mounted好后,才会create子组件
index beforeCreate
index.vue index created
index.vue index beforeMount
index.vue index mounted
index.vue index beforeUpdate
A.vue A beforeCreate
A.vue A created
A.vue A beforeMount
A.vue A mounted
index.vue index updated
如下图,完整demo参见 父子组件钩子函数demo | github
vue组件的封装性与可操作性:ref拿不到子组件实例以及vuex增加代码复杂度问题
一般在封装vue组件时,怎么把组件封装的更好,更容易维护理解是值得思考的问题
来看一个实际场景:一个组件里有高级查询和列表,他们东西都比较多,需要拆分成两个子组件
<!-- index.vue -->
<project-search></project-search>
<project-list></project-list>
查询的条件参数比较多,假设表单数据变量为 searchForm。
按照封装的完整性原则,自己的组件的数据放到自己的组件中,那么 seachForm 就需要放到 project-search 组件里。
但在index.vue中,我们需要查询列表,依赖searchForm的值,涉及到父组件取子组件的值的问题,一般有四种方法可以选择
- searchForm变量放到父组件,通过props传递到子组件(这样有点违背组件的封装性)
- vuex 个人认为,能不实用vuex的场景,尽量不要使用,除非真的需要使用,他会影响代码的简单性。
- bus 使用 bus 来通信,但和vuex类似,尽量少使用
- 使用ref直接取。但由于副组件加载子组件时,在mounted钩子里 ref 拿对于的子组件可能会拿不到,需要加 setTiemout,也是一种比较怪的操作
对比这几种情况。我一般使用props,把值直接放到index.vue里,再传递给子组件。这样算是比较好理解的一种方法,虽然封装性不强。但涉及到数据需要交互的场景,必须要做一些妥协。
2020/09/12 周六
npm install -g或者npm link需要sudo的问题
在mac下,安装node后,会出现两个命令 npm 和 node,再使用 npm install -g 时,默认需要管理员权限,可以再前面加 sudo 以管理源方式运行即可。
如果在开发 npm 包的时候。如果开发对应的命令程序,测试时需要在当前目录执行 npm link,这里也需要加 sudo。
git status中文乱码怎么解决
git status时,如果中问乱码,可以对git进行一个配置即可 git config --global core.quotepath false
具体效果如下图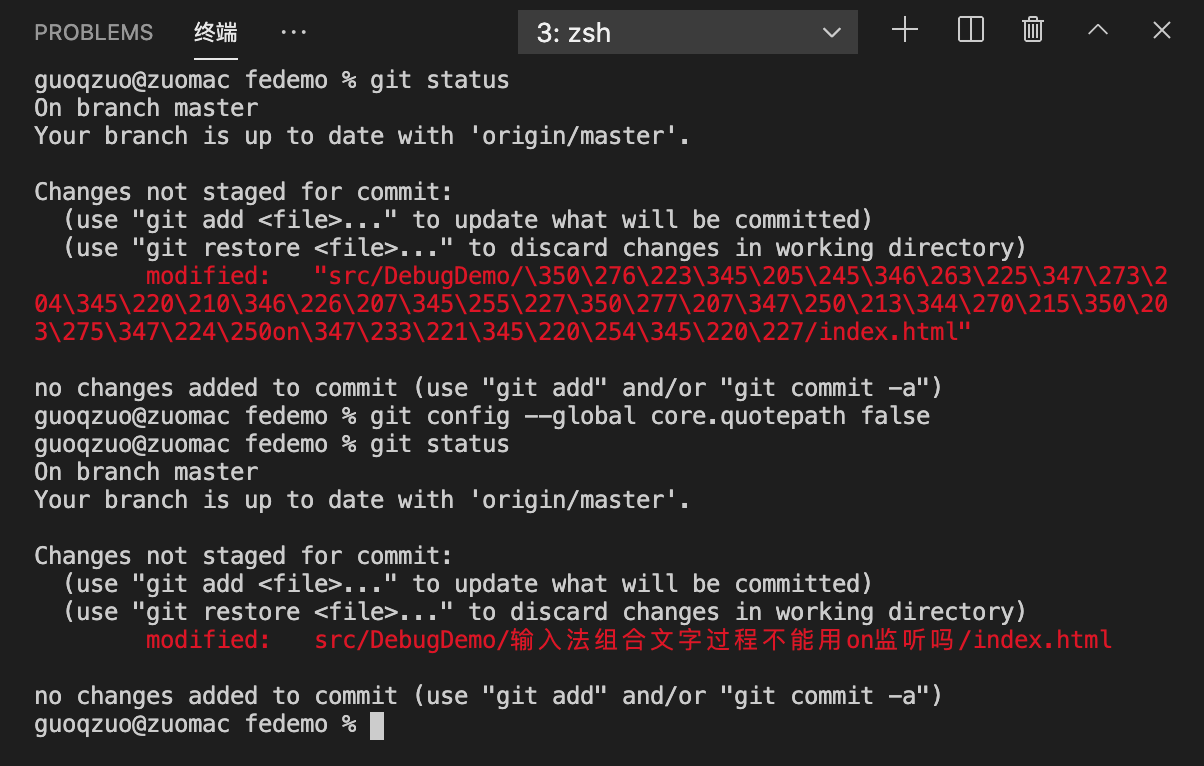
mac安装brew下载慢,安装异常,切换成ruby-china源
mac下使用brew可以很方便的安装svn、nginx等常用的工具。
什么是brew [bruː],它的全称是 Homebrew,The Missing Package Manager for macOS (or Linux)。它可以安装macOS或linux下没有的包(Package)。
一般使用ruby来安装
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
mac自带ruby,但如果直接安装,他会比较慢,直接卡死,安装不上。
这就需要使用国内的 ruby 源了。类似与npm与cnpm的概念,这里使用ruby-china的源,具体参考:RubyGems - Ruby China
# 设置ruby源
gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/
# 查看ruby源
gem sources -l
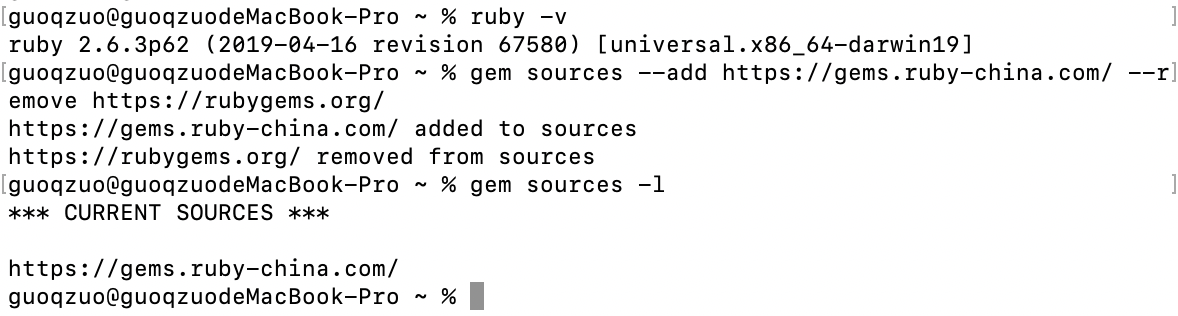
这样,再重新运行安装brew的命令就可以安装成功了,虽然也慢,但至少可以安装成功。安装包就快了。
参考:
mac安装svn,svn: error: The subversion command line tools are no longer provided by Xcode.
在新的macos系统中,xcode不再集成svn,需要自己安装。可以使用 brew install svn 进行安装
mac安装nginx在官网下载与使用brew下载的区别
nginx官网直接下载的包,mac下可以直接进入该目录使用,但没有加到环境变量,不能在Terminal的任何目录下直接使用。

如果使用 brew install nginx 安装,他会直接都安装好,并修改环境变量。可以使用which nginx来看具体的地址
2020/09/02 周三
@guoqzuo/vue-chart实用echarts组件封装
vue中使用echarts可以自己封装一个简单的组件。实现每次更新数据只需要修改options的值即可,并自带loading、暂时数据slot。先来看看使用demo
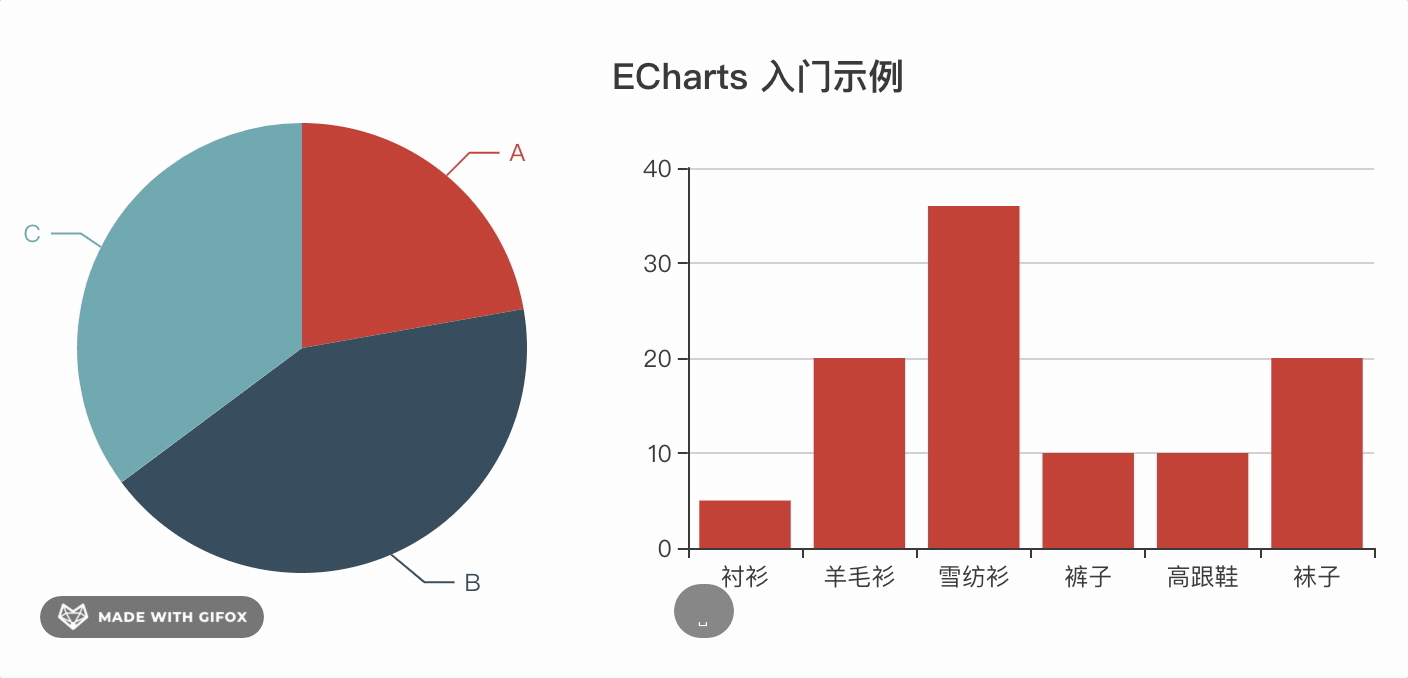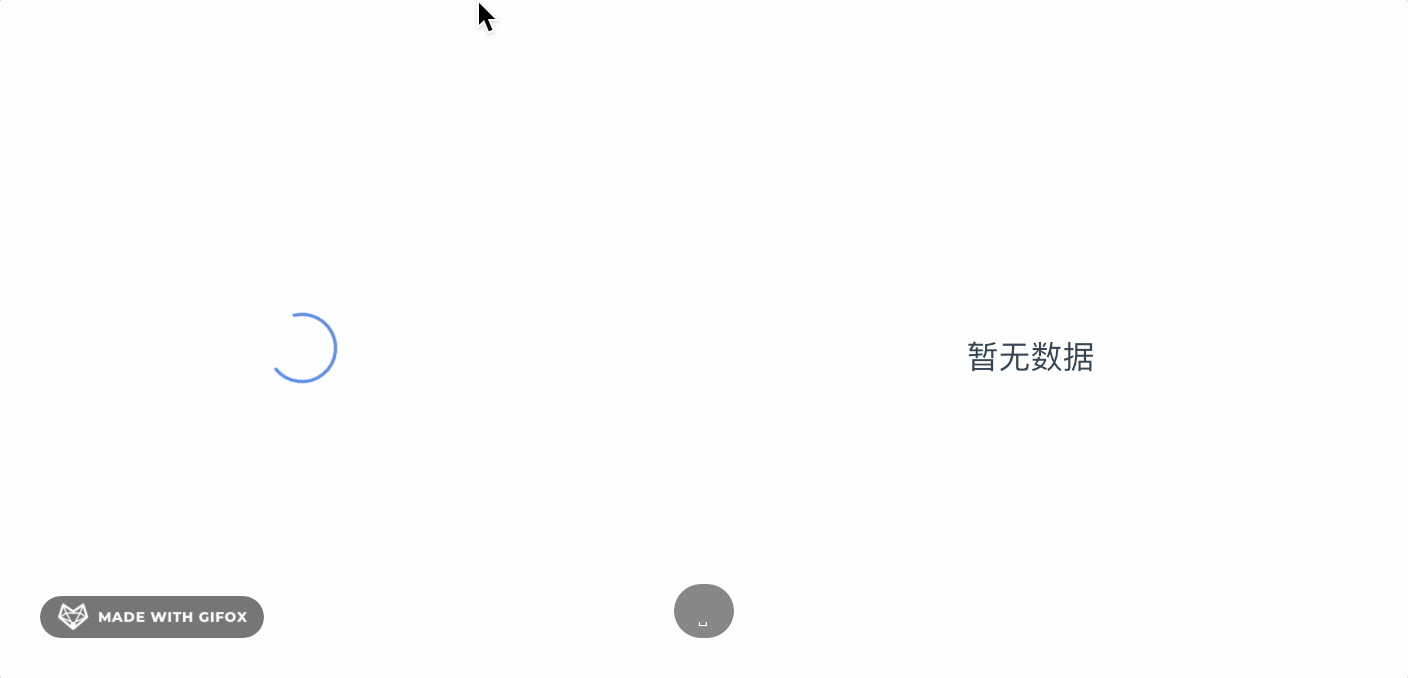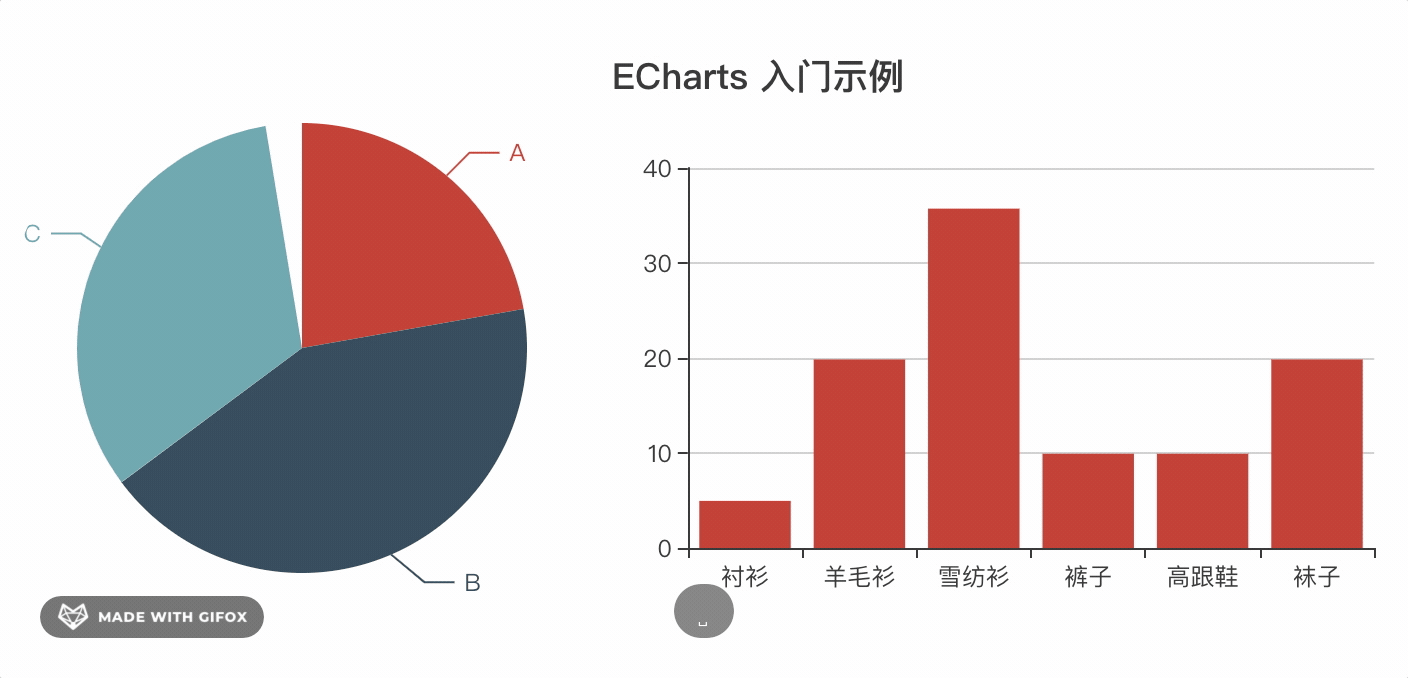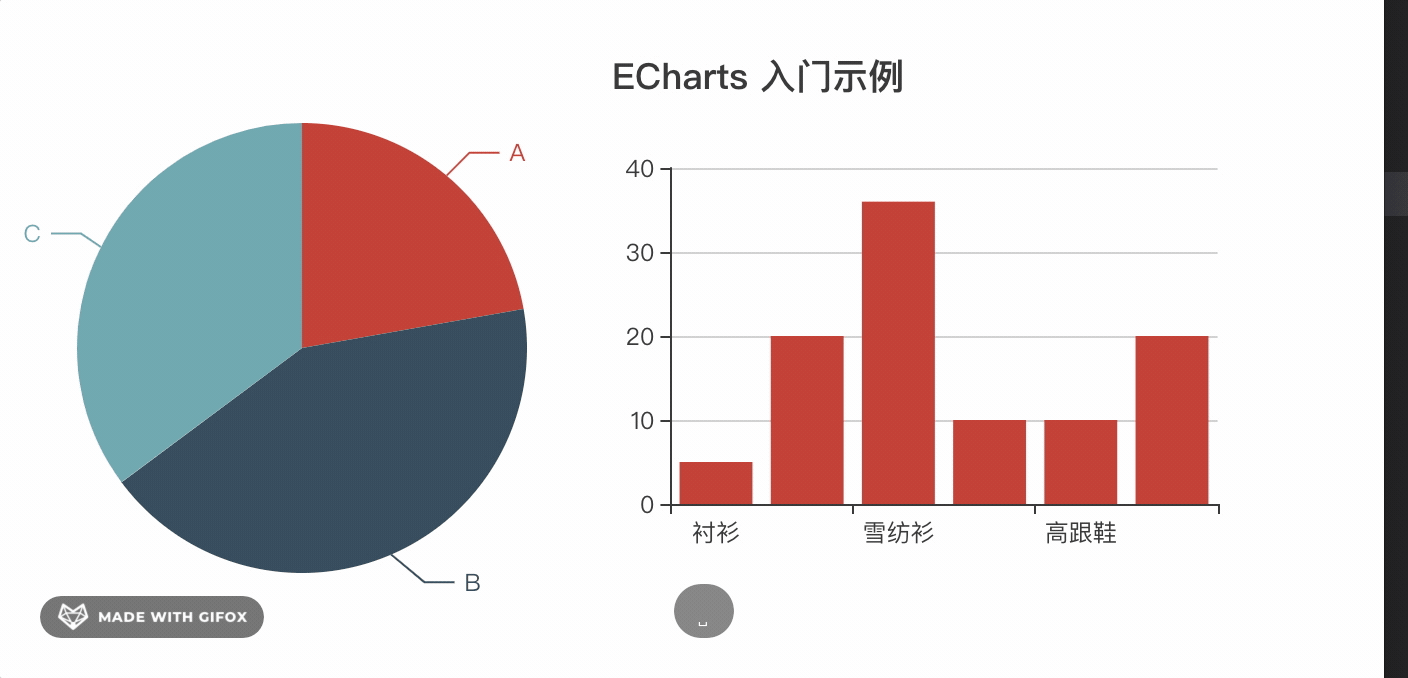
// main.js 全局引入
import VueChart from "@guoqzuo/vue-chart";
Vue.use(VueChart);
然后在任意组件里可以直接使用 z-echart
<!-- 固定宽柱状图,不自动resize -->
<div style="width:300px; height: 300px">
<z-chart :options="bar" :loading="loading" :autoResize="false"> </z-chart>
</div>
<!-- 宽高自适应,resize后自动渲染,当hasData为false时显示暂无数据的slot内容-->
<div style="width: 50%; height: 50vh">
<z-chart :options="pie" :hasData="hasData">
暂无数据
</z-chart>
</div>
来看看z-chart组件的实现细节,这里把echart单独用一个组件处理,在z-echart组件里引入,并加入loading、无数据的slot显示处理
<template>
<!-- z-chart -->
<div class="z-chart-container">
<base-chart
v-if="!loading && hasData"
:options="options"
v-on="$listeners"
v-bind="$attrs"
></base-chart>
<base-loading v-if="loading"></base-loading>
<!-- no data slot -->
<slot v-if="!loading && !hasData"></slot>
</div>
</template>
base-chart代码如下,它主要做了三个操作
- 使用options初始化图表
- 如果是百分比大小的图,resize时,自动重绘
- 使用watch监听options改动,如果有改动为了防止渲染异常,直接dispose销毁echart实例,重新加载
<template>
<!-- base chart -->
<div class="z-chart" ref="z-echart"></div>
</template>
<script>
import echarts from "echarts";
import { addListener, removeListener } from "resize-detector";
import { debounce } from "lodash-es";
export default {
name: "BaseChart",
props: {
options: {
type: Object,
required: false
},
autoResize: {
type: Boolean,
required: false,
default: true
}
},
data() {
return {};
},
created() {
// 监听 options 改动,改动后重绘数据
this.$watch(
"options",
() => {
this.refresh();
},
{ deep: true }
);
},
mounted() {
this.init();
},
beforeDestroy() {
this.destroy();
},
methods: {
init() {
let chart = echarts.init(this.$refs["z-echart"]);
chart.setOption(this.options || {});
this.chart = chart;
// 当元素宽高改变时resize执行重绘
if (this.autoResize) {
this.__resizeHanlder = debounce(
() => {
chart.resize();
},
100,
{ leading: true }
);
addListener(this.$el, this.__resizeHanlder);
}
},
destroy() {
// 销毁实例,防止 柱状图 动态切换到 饼图 时,柱状图部分属性依旧留存的问题
this.chart.dispose();
this.chart = null;
this.autoResize && removeListener(this.$el, this.__resizeHanlder);
},
// 销毁后重绘,用于options变更后刷新图表
refresh() {
this.destroy();
this.init();
}
}
};
</script>
<style lang="less" scoped>
.z-chart {
width: 100%;
height: 100%;
}
</style>
2020/09/01 周二
normalize.css浏览器样式差异抹平
normalize.css A modern alternative to CSS resets 一个用于CSS重置的现代替代方法
主要用于解决不同浏览器默认样式之间的差异
What does it do?
- Preserves useful defaults, unlike many CSS resets. 保留有用的默认样式,重置许多不一样的CSS
- Normalizes styles for a wide range of elements. 为许多各种各样的元素标准化样式
- Corrects bugs and common browser inconsistencies. 修正bug和常见的浏览器不一致样式
- Improves usability with subtle modifications. 通细微的修改提高可用性
- Explains what code does using detailed comments. 使用详细的注释来解释代码的作用
下面来看看 Chrome、Safari、Firefox 三个浏览器之间的差异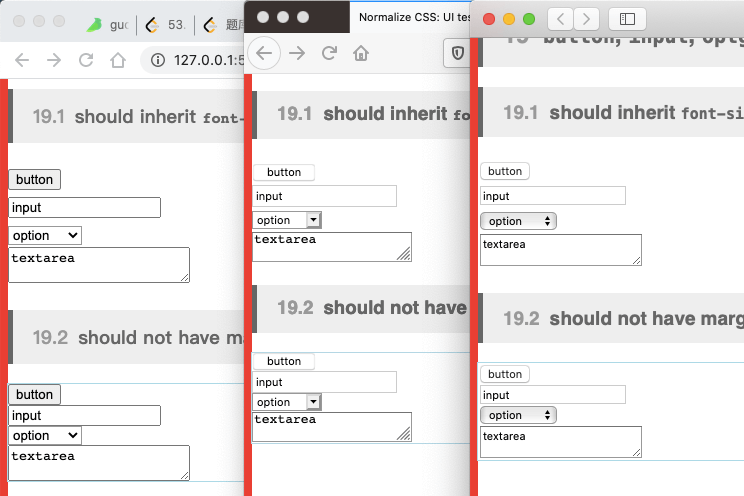
使用 normalize.css 后的效果
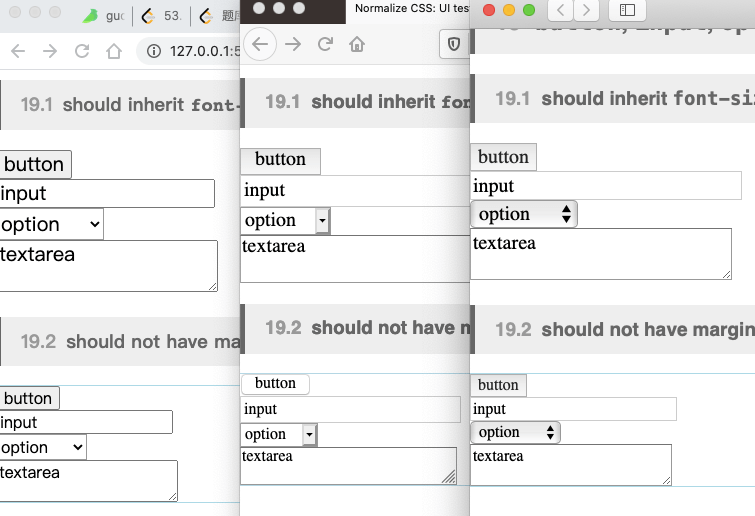
现有的UI框架也抹平了这些差异

若有收获,就点个赞吧
0 人点赞
